
If you often pay attention to articles about “edge computing”, you will find that it has a brother called “fog computing”. Most published articles explain these two terms in a similar way: they both refer to computing that takes place at the edge of the network, closer to the native data (physical sensing), relative to “cloud computing”.
Previously, most of the internet information processing models we saw were based on the “end-pipe-cloud” model. In the application scene, the “end” is only responsible for collecting data and executing instructions, while the “cloud” is responsible for all data analysis and control logic functions. “Edge computing” or “fog computing” moves some data analysis and control logic functions closer to the application scenario, which is vividly referred to as “ground computing”.
Although overall, the meanings of “edge computing” and “fog computing” are similar, there are still differences.
“Edge computing” originates from the industrial sector and is primarily deployed on terminal devices or network access points. It is now widely used in fields such as industrial IoT (embedded IoT) applications, manufacturing, retail, ATMs, smartphones, and virtual/mixed reality. Edge computing enables devices in industrial production to have near-end decision-making and control capabilities without relying on cloud computing.
“Fog computing”, which evolved from “cloud computing”, refers to deploying (some) functions of cloud computing on devices at the edge of the network, representing localized centralized computing. It is actually an extension of the concept of cloud computing, proposed by Cisco in 2011.
Thus, it is evident that there are indeed some differences between “edge computing” and “fog computing”. Edge computing is mainly at the “end”, referring to electronic terminal devices or sensors; while fog computing is still within the “cloud”, deployed at centralized data collection points within a certain area. For example, in a smart home (WIFI) network, an app performing off-network computing on a mobile phone is edge computing, while a home smart box (smart Wifi gateway) is the main body of fog computing.
Although the two have differences, many industry articles online do not strictly differentiate between them. In fact, due to the wide-ranging application scenarios of IoT, many applications involve computing at both the “end” and the “gateway”. Therefore, in the author’s view, since they are both relative to “cloud computing”, there is no need to distinguish their deployment locations (production devices, sensing devices, gateways/servers), and generally, they are expressed as “edge computing”.

The differences between “edge computing” and “fog computing” have actually given the author an insight: the computing capabilities in IoT have the characteristic of hierarchical deployment. This characteristic differs from the cloud computing deployment model in the internet and can be discussed from two dimensions.
1. Discuss the hierarchical deployment of edge computing with reference to the edge architecture model of IoT
The Edge Computing Consortium (ECC) has defined four domains for edge computing: Device Domain (Perception and Control Layer), Network Domain (Connection and Network Layer), Data Domain (Storage and Service Layer), Application Domain (Business and Intelligence Layer). These four “domains” are the computing objects of edge computing.

1. Device Domain: In this layer, edge computing can directly process perceptual information. For instance, deploying intelligent identification capabilities directly in video and audio collection; or like a mobile phone, converting voice input directly into text output.
2. Network Domain: By deploying computing capabilities, automatic conversion of various network protocols can be achieved, and data formats can be standardized. To address the issue of data heterogeneity in physical networks, edge computing needs to be deployed in the network domain to achieve data format standardization and data transmission standardization (for example, converting all perceptual data into MQTT type data and transmitting it via HTTP). Additionally, edge computing in the network domain can intelligently manage the “fusion network”, ensuring network redundancy, security, and further participation in network optimization efforts.
3. Data Domain: Edge computing makes data management smarter and storage methods more flexible. Firstly, edge computing can analyze the integrity and consistency of data and perform data cleansing to eliminate “dirty” data in the system. Secondly, edge computing can dynamically deploy computing and storage capabilities, as well as system loads. Finally, edge computing can maintain efficient collaboration with cloud computing, reasonably sharing computational tasks.
4. Application Domain: Edge computing provides localized business logic and application intelligence. It enables applications to have flexibility and quick response capabilities, and even when offline (when disconnected from the cloud), it can still independently provide localized application services.
In the areas of IoT that are close to users and application scenarios, edge computing is deployed in the above four domains. It enables devices to have intelligent perception capabilities, adaptive connection strategies, and (digital) deployment strategies, solving data heterogeneity issues in the system, and providing localized business logic and even intelligence.
2. Discuss the hierarchical deployment of edge computing with reference to IoT applications/regions/coverage
From the initial perceptual data to the final cloud intelligence, data will go through multiple aggregations and computations based on application needs. For example, from smart homes to smart cities, massive data aggregation is not achieved in one step. Moreover, each stage of data aggregation has its own independent applications and services, which implies that there is a need for hierarchical deployment of computing.
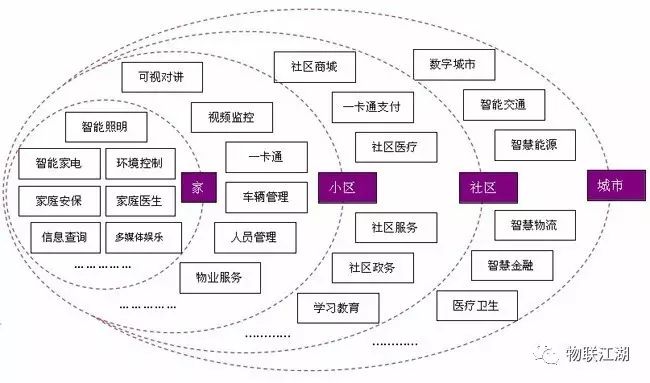
The above illustration shows that smart cities are divided into four “IoT (size) levels”: home, neighborhood, community, and city.
These four “smart” levels each have their own applications and services, with the service range and coverage area gradually expanding from home to city. Some applications at each level are relatively independent and unrelated to upper and lower levels; while others will “upgrade layer by layer”: family doctor (home) -> community healthcare (community) -> healthcare (city).
From the perspective of IoT levels, the relationship between cloud computing and edge computing will be distinguished based on applications:
1. For unique businesses at each level, it is sufficient to independently deploy targeted computing capabilities at the corresponding level (only “cloud computing” is needed).
2. For applications that penetrate (relate to) multiple levels, it is necessary to deploy computing capabilities from top to bottom. The relationship between lower-level computing and upper-level computing is the relationship between edge computing and cloud computing. “Community healthcare-community” is the “cloud” of “family doctor-home”, while it is the “edge” of “healthcare-city”.
3. The relationship between “edge” and “cloud” can be interchanged: for a single application, edge computing may be deployed at the upper level (of the physical network), while cloud computing is deployed at the lower level.
A certain application (for example, community mall) may have the following situation:
A. The core logic and predictive analysis of this application are mainly deployed in the “community” and “neighborhood”, targeting the preferences of local residents for selling consumer goods;
B. This application needs to extract some external data from the “city” level (for example, the average price of goods in the entire city, etc.);
C. This application does not have a large amount of application domain computing requirements at the “city” level.
If so, then the upper-level “city” becomes the “edge” for the lower-level “community” and “neighborhood”. Naturally, the computing capabilities deployed in the “city” level for this application are edge computing.
The author believes that the situation of “relationship interchange” may be more common in the industrial sector. For example, quality management and process management in industrial production.
Quality and process management systems in factories are usually deployed on-site, with a large amount of production data stored in the “edge” of the network. To achieve intelligent production, it is also necessary to extract many external information related to quality and supply chain (user complaints, product/component return information, product lifecycle information, partner quality information, etc.). This information will ultimately be aggregated to the “edge” quality and process management system for quality analysis/prediction through IoT. Clearly, for quality and process management systems, the internet and IoT outside themselves are all edge networks.
In the author’s view, “cloud computing” in industrial production will be more deployed at the edge of IoT, near industrial production sites.
Based on application needs, computing capabilities will be deployed at various (size) levels of IoT. Regardless of which level “computing” is deployed at, if it assumes the main responsibility for on-site command, it belongs to edge computing; if it assumes the main responsibility for big data and intelligent prediction, it belongs to cloud computing.
The flexibility of applications in computing deployment is continuously increasing, and the integration of cloud computing and edge computing will make it increasingly difficult to distinguish between them. When the IoT is filled with ubiquitous and readily available general computing capabilities, “ubiquitous computing” will emerge as a trend.

Deploying simple application logic at the edge of IoT cannot meet the diverse and dynamic application needs of IoT. In areas close to application scenarios, a certain level of intelligence must be deployed to build a robust application ecosystem at the edge of IoT.
Edge computing is essentially “grounded” cloud computing. The most important capability of edge computing is to inherit the intelligence of cloud computing. Given the current technological development trends, it is theoretically possible to achieve this. For a specific application, neural network algorithms (cloud computing) can first undergo “slimming” (simplification) after learning a sufficient number of application scenarios, and then be deployed at the network edge (deploying intelligent edge computing), thus forming edge intelligence. Therefore, even without the support of cloud computing, edge intelligence can realize most of the intelligence of that application scenario.
For example, on May 23, 2017, the artificial intelligence AlphaGo defeated the ninth-dan Go player Ke Jie with a white 1/4 stone. Notably, it was a “single machine” version of AlphaGo that fought that day.
When edge computing becomes edge intelligence, it enables local and edge IoT systems to possess autonomous and self-disciplined behavioral capabilities. Self-sufficient computing power and intelligence will allow IoT applications to operate relatively independently without relying on “cloud computing”.

1. Edge computing has the characteristic of hierarchical (“domain” and “level”) deployment.
On one hand, edge computing is deployed across various domains of the edge architecture model. The deployment of computing capabilities at the physical network edge allows applications in localized IoT (for instance, smart homes) to form an “‘perception’-‘connection’-‘analysis and prediction’-‘control'” information loop, thereby unleashing the informational value of various data.
On the other hand, deploying computing capabilities across different ranges (size levels) of IoT enables developers to construct appropriately sized information loops based on business needs and characteristics; it also allows “vertical” businesses to be interconnected across levels, providing mutual services and achieving value interlinking.
2. The higher value of edge computing is edge intelligence
Edge computing is the on-ground deployment of intelligent cloud computing. Applications in localized IoT achieve information looping and can realize intelligent functions such as information decision-making, behavioral feedback, automatic networking, and load balancing across all domains through edge computing. Even in the absence of cloud computing, applications can operate independently and flexibly, thereby forming an IoT “ecosystem” in a localized range (creating a mechanism for information mutual assistance services among various devices).
Source: IoT Jianghu (ID: iot521)
Network optimization mercenary submission email: [email protected]
Long press the QR code to follow

On the communication road, let’s walk together!