


Chaos Engineering Is Not a Cutting-Edge Technology
Seeing this, some may be confused; chaos engineering has been popular for a long time, yet it turns out to be old technology.
Yes, that’s absolutely right; it’s all existing technology.
In fact, I want to emphasize:
The most advanced aspect of chaos engineering is its bold, forward-thinking system thinking and safe, controlled experimental methodology.
You may not believe it and might even ask:
Isn’t the core of chaos engineering fault injection? Shouldn’t the most advanced aspect be fault injection?
In recent years, the value of chaos engineering in the field of system stability/reliability has begun to receive increasing attention from quality personnel. Essentially, chaos engineering is not a brand-new cutting-edge technology. If we delve into every aspect of chaos engineering, we will find that the technologies and methods it encompasses have long existed.
Netflix first practiced chaos engineering ten years ago by releasing Chaos Monkey, which is closely related to its foresight in cloud adoption.
The agility and ease of use brought by the cloud, along with the rapid development of large-scale distributed systems, are fundamentally changing the entire software engineering landscape. Agile development and DevOps practices have accelerated new product development and release, while the confidence in production is gradually declining: even if all individual services in a distributed system are running normally, the interactions between these services can lead to unpredictable results.
Chaos engineering arises in response to these challenges, aiming to establish the ability and confidence of systems to withstand uncontrolled conditions in production environments. Chaos engineering does not replace existing testing methods but complements them.
Fault Injection Is Not Everything
Let’s look at a graph you are familiar with.

In August 2008, a failure of Netflix’s primary database led to three days of downtime, interrupting DVD rental services and affecting a large number of users across multiple countries. Subsequently, Netflix engineers began searching for alternative architectures and, starting in 2011, gradually migrated the system to AWS, running a new distributed architecture based on microservices.
This architecture eliminates single points of failure but also introduces new types of complexity that require more reliable and fault-tolerant systems. Netflix engineers created Chaos Monkey, which randomly terminates EC2 instances running in the production environment. Engineers can quickly assess whether the services they are building are robust enough to tolerate unexpected failures.
In fact, this story lacks a key element: chaos engineering guru Adrian Cockcroft specifically thanked the disaster master Jesse Robbins on Twitter earlier this year, stating that without Robbins’ invention of GameDay, there would be no Netflix’s Chaos Monkey.
-
[Click to Read] Chaos Guru Episode One – Adrian Cockcroft -
[Click to Read] Chaos Guru Episode Two – Jesse Robbins
Nearly 20 years ago, Jesse actively promoted the practice of GameDay in the community, while Netflix actively implemented it, ultimately discovering chaos engineering, a new technological method that could automate, rapidly scale, and solidify GameDay.
Subsequently, Netflix open-sourced the astonishing Simian Army. By 2017, in the newly released Chaos Monkey V2 version, the fault injection scenarios were severely curtailed, and it was tightly integrated with Netflix’s own continuous release tool, Spinnaker.
-
[Click to Read] Netflix ChAP: The First Chaos Experiment Platform in History
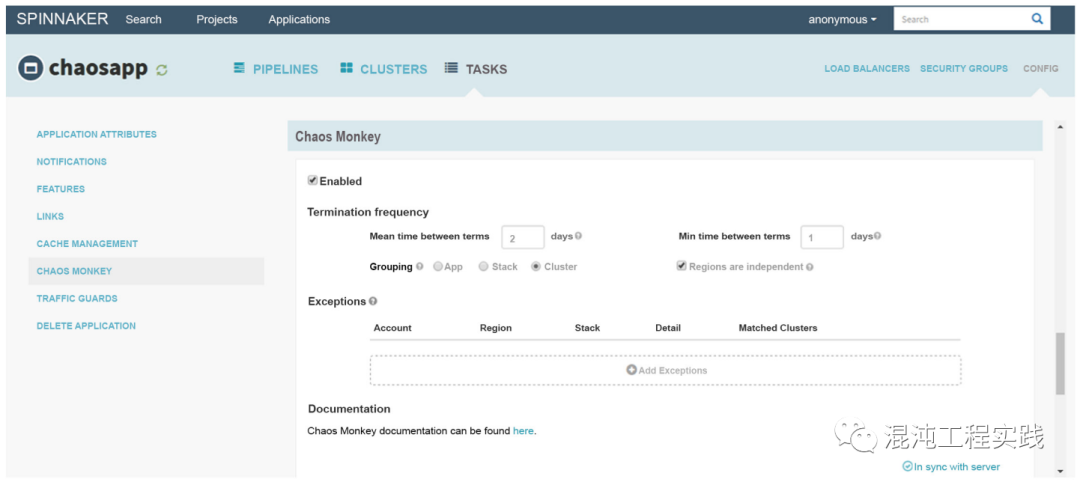
First Question: What Signal Does This Convey?
Fault injection is merely a means; it is no longer everything in chaos engineering. More scenarios do not equate to better resilience.
Thus, this leads to a deepening direction for chaos engineering: the effectiveness of fault injection and experimental scenarios. For example, Lineage-driven Fault Injection (LDFI) is a top-down approach aimed at identifying combinations of smaller injected faults to trigger large-scale cascading failures in the system.
-
[Click to Read] Netflix: Training a Smarter Chaos Monkey
Second Question: Why is the New Version of Chaos Monkey Tightly Integrated with CD Tools?
Let’s look at the second graph:
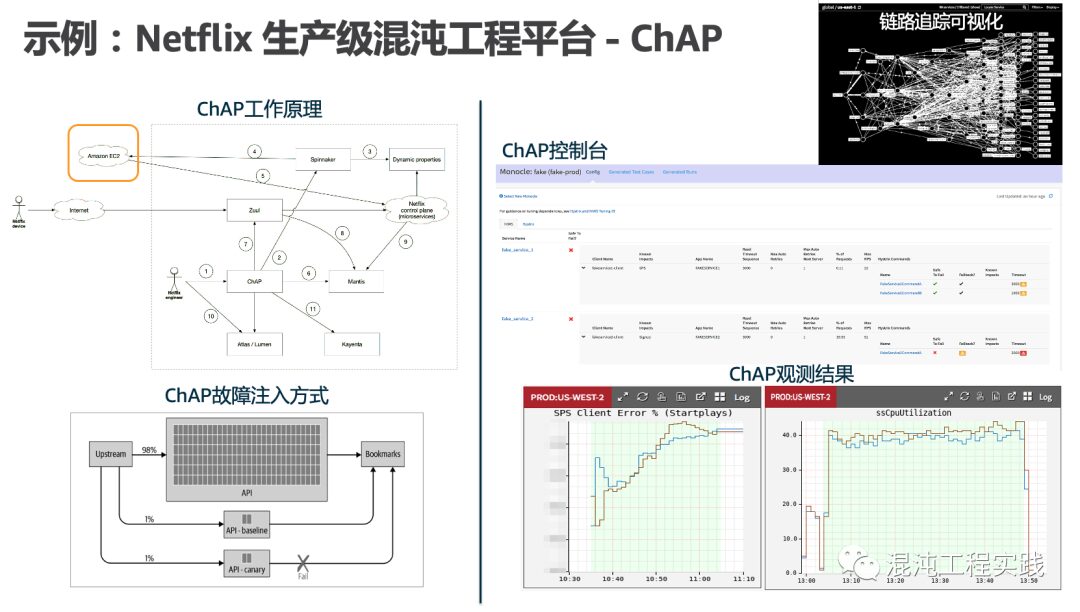
Netflix’s chaos engineering leverages existing tools, including:
-
FIT for fault injection -
Spinnaker for configuring baselines and gray clusters -
Zuul for managing user traffic routing to baselines or gray environments -
Atlas and Mantis for observability during experiments, with Mantis being a low-latency stream processing system -
Lumen for dashboarding metric data -
Automated gray analysis system (Kayenta) -
Monocle for automatically discovering service dependencies and generating experiments
By conducting actively controlled fault injection tests in a production gray environment (2% of production traffic), steady-state 1:1 observational analyses are performed to detect potential system risk points in advance.
Third Question: What Does Good Chaos Practice Look Like?
-
[Click to Read] Netflix: Training a Smarter Chaos Monkey
-
[Click to Read] Cascading Failure Research: The Core Mission of Chaos Engineering
-
[Click to Read] Chaos Engineering Foundation: Gray Practices of Two Giants
-
[Click to Read] Netflix Textbook: Anti-Fragile Chaos Engineering Practices
-
[Click to Read] Netflix Textbook: From Aggressive to Creepy
-
[Click to Read] Netflix Textbook: Anti-Fragile Chaos Engineering Practices
-
[Click to Read] [Classic Review] Netflix ChAP: The First Chaos Experiment Platform in History
-
[Click to Read] Netflix Simian Army | IDCF
-
[Click to Read] Netflix Chaos Engineering Series – Core Practices
-
[Click to Read] Netflix Chaos Engineering Series – Introduction
Awe of Production
You may also ask: Isn’t it widely promoted to conduct experiments in production? Why has it changed to gray environments?
The gray environment in production also receives production user traffic, but relative to the total traffic, its proportion is small, generally less than 5%.
You might ask: Isn’t smaller safer, but not necessarily better? We will answer this question later.
I believe many of you have this concern:
Conducting experiments in production is too scary; one mishap could cost you your job!
This is also a key reason why many teams are afraid to apply chaos engineering. Therefore, they tend to conduct fault injection tests in non-production environments (testing, pre-production, etc.).
But in reality, the results are not good. Why?
The Mission of Exploration
Because complex distributed systems are difficult to simulate production conditions in a different environment, chaos testing ultimately becomes just a general test, merely verifying whether the system can function normally in known fault scenarios.
At this point, you might ask: Isn’t this chaos engineering?
NO! If that’s all chaos engineering is, you underestimate it!
If it’s just writing test cases based on steady-state hypotheses and then using fault injection tools for experiments, finally validating the results, I must say this is merely the tip of the iceberg of chaos engineering.
The mission of chaos engineering is to explore problems, not just to validate them.
At this point, someone might counter: Can’t pre-production explore problems?
This is a very strong counter! This leads to an interesting question:
Why Explore in Production?
Testing in Production has been quite popular in the testing field for a while, and there have been many discussions and explanations on this issue. Let’s briefly review.
-
[Click to Read] Are You Crazy to Test in Production?
Pre-production != Production
Most companies view pre-production as a miniature version of production. In this case, pre-production must be kept as “synchronized” with production as possible. However, the development and maintenance of any system are constrained by people, time, and money, which makes it impossible for pre-production to be completely consistent with production.
This is not to say that maintaining a pre-production environment is entirely useless; rather, our reliance on it far exceeds what is necessary.
Data Differences
Production data must be regularly desensitized and synchronized to pre-production. This data may contain any personal identifiable information (PII) that complies with standards such as GDPR, PCI, HIPAA, etc.
Other Differences
The size of application clusters in pre-production (and sometimes it’s not even a real cluster, but a single machine masquerading as a cluster).
The configuration options in pre-production often differ from those in production, such as the number of open file descriptors, the number of connections to the database, the size of thread pools, the number of Kafka partitions, etc.
Lack of monitoring for the pre-production environment. Even if monitoring exists, the metrics may not be entirely accurate due to the differences in the monitoring environments compared to production.
Of course, none of the above differences are meant to oppose the existence of pre-production environments but to avoid falling into this anti-pattern.
When we need to invest a lot of time and money to achieve equality between environments, this attempt is almost delusional as production constantly changes.
The Scientific Nature of Exploration
After all this discussion, you might still ask: Where does the exploratory nature of chaos engineering manifest?
-
[Click to Read] Chaos Engineering = Observability + Exploratory Testing? -
[Click to Read] Literacy Article: Introduction to Exploratory Testing
Clinical Controlled Trials
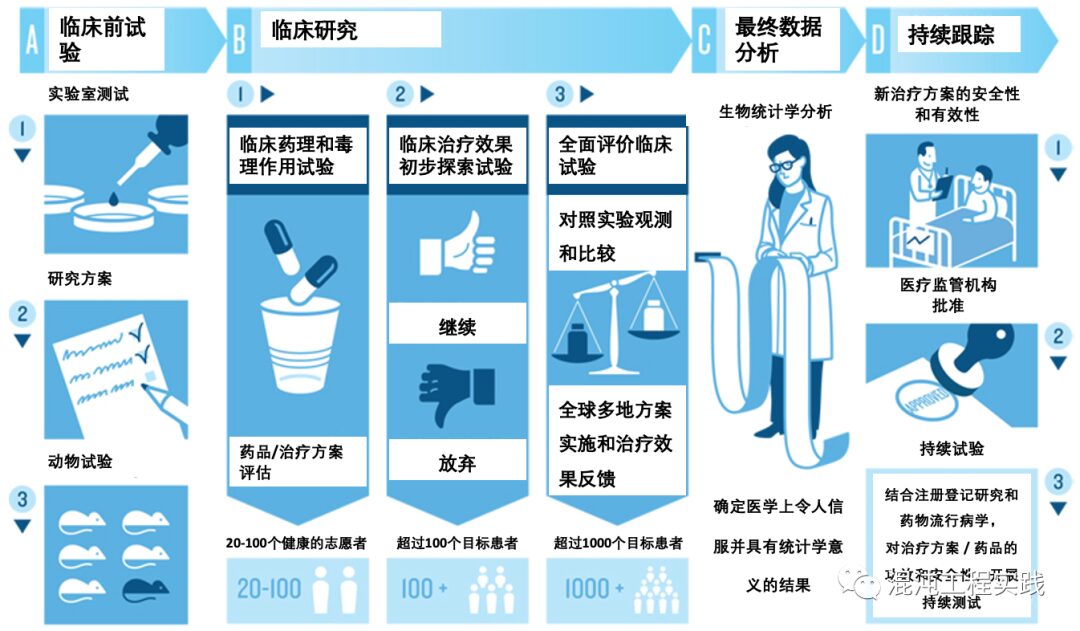
The scientific nature of chaos engineering exploration is borrowed from resilience engineering and clinical controlled trials.
The following graph describes the various aspects of clinical controlled trials in detail. We can use this as a comparison, treating chaos engineering scenarios as a new drug.
-
Click to Read: The Chernobyl Disaster as a Severe Failure in Chaos Experimentation
Pre-clinical Trials
Pre-clinical trials require laboratory pharmaceutical testing, the formulation of research protocols, pharmacological and efficacy tests in animal subjects, and obtaining safety evaluations.
For new fault injection scenarios, we need to conduct white-box analysis of the architecture of the injection target, develop specific fault injection plans, and first conduct tests in non-production environments to determine the impact range of the scenario and obtain safety evaluations.
Clinical Research
-
Phase I and II clinical trials are recommended to be completed in non-production.
-
Phase III and IV clinical trials are recommended to be conducted in production.
Phase I and II Clinical Trials: Explosion Radius Studies
| Trial Phase | Description of Trial Content |
| Phase I | Clinical pharmacology and toxicology trials for healthy volunteers to determine the recommended safe dosage. |
| Phase II | Preliminary exploratory trials of clinical treatment effects on small sample patients, observing the therapeutic effects and adverse reactions of the new drug, ultimately deciding on GO or NO-GO. |
From the perspective of chaos engineering, the explosion radius of this trial is clarified by gradually increasing the “dose” (load testing). At the same time, controlled experiments in non-production are utilized to ensure that the entire chaos engineering toolchain functions correctly.
The fault injection mechanism of Chaos Monkey and the Simian Army is merely a low-level random destruction behavior.
Previously mentioned Netflix internal system Monocle is an intelligent detector that identifies possible weaknesses in services through service dependency analysis.
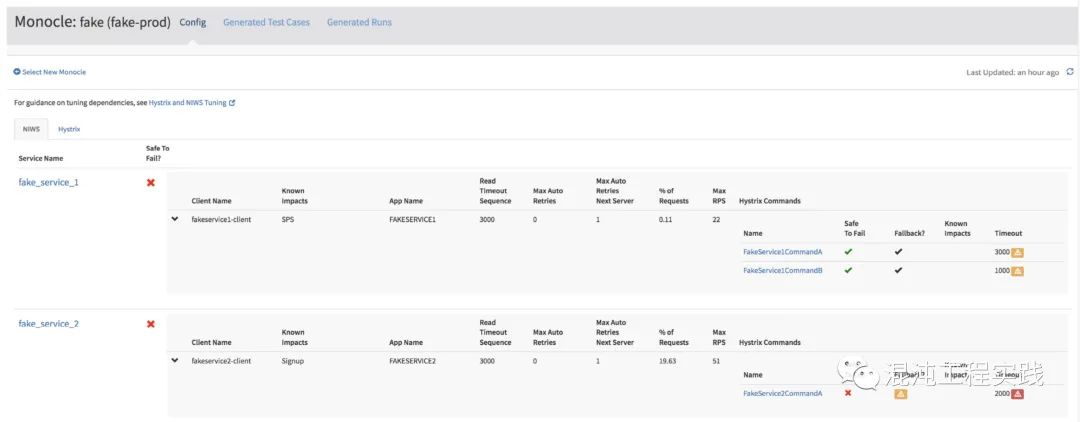
The yellow and red icons in the above image highlight a warning: Hystrix command timeout does not match RPC client, meaning the timeout (1000ms) is less than the RPC client’s maximum timeout (4000ms). This implies that Hystrix will give up waiting for RPC, posing a potential risk. Monocle will then automatically generate this experiment for RPC clients and Hystrix command dependencies.
Hystrix is an open-source latency and fault tolerance library that helps control service interactions by adding wait times and fault tolerance logic, aiming to isolate access points to dependent systems, services, and third-party libraries, thus stopping cascading failures and improving overall system resilience. It is no longer maintained, and the official recommendation is:
-
https://github.com/resilience4j/resilience4j
Phase III and IV Clinical Trials: Production Controlled Experiments
| Trial Phase | Description of Trial Content |
| Phase III | Comprehensive evaluation clinical trials conducted on a larger scale of patients through expanded multi-center clinical trials to avoid statistical errors. This is the verification stage of therapeutic effects and is crucial in determining the success of drug development. |
| Phase IV | Clinical monitoring trials post-drug launch, surveying the clinical effects and side effects of the drug on patients. Regulatory authorities can quickly recall the drug or withdraw it from the market. |
Previously, we mentioned that Netflix uses ChAP to invoke Spinnaker to launch production gray environments, with no more than 5% of production traffic being introduced into it for chaos engineering trials.
At that time, some asked: Isn’t smaller better?
The answer is no.
The smaller the proportion of production traffic introduced into the gray environment, the larger the statistical error, which is likely to become noise in the experiment. Therefore, a trade-off is needed.
Gray production traffic control: Too large, explosion radius increases; too small, statistical error increases.
-
[Click to Read] Chaos Engineering Foundation: Gray Practices of Two Giants -
[Click to Read] Gray Hole: Zero Risk Chaos Engineering Experiment
An important issue mentioned in Phase IV is that “regulatory authorities can quickly recall the drug or withdraw it from the market.” From the perspective of chaos engineering, this is the “One-Click Shutdown of Production Experiment.”
Initially, Netflix used observability tools (Atlas) to monitor production SPS metrics, and once deviations occurred, the experiment would automatically stop. However, they later found that Atlas’ metric data generation had a 5-minute delay, which was unacceptable for the “One-Click Shutdown of Production Experiment.” Therefore, they developed a low-latency stream processing system (Mantis) to capture SPS almost in real-time, ensuring that any deviations would immediately halt the experiment.
Conclusion
Today, we have picked and chosen, rambling through a brainstorming session on chaos engineering. The following statements serve as a summary of this article. Each statement can be further researched in practice in the future.
-
The most advanced aspect of chaos engineering is its bold, forward-thinking philosophical concepts and safe, controlled methodologies. -
Fault injection is merely a means; it is no longer everything in chaos engineering. More scenarios do not equate to better resilience. -
Netflix adopts actively controlled fault injection tests, conducting steady-state 1:1 observational analyses in production gray environments (<5% of production traffic) to detect potential system risk points in advance. -
If it’s merely about writing test cases based on steady-state hypotheses, then using fault injection tools for experiments and verifying results, this is merely the tip of the iceberg of chaos engineering. -
The mission of chaos engineering is to explore problems, not just to validate them. -
When we need to invest a lot of time and money to achieve equality between pre-production and production, this attempt is almost delusional as production continuously changes. -
The fault injection mechanisms of Chaos Monkey and the Simian Army are merely low-level random destruction behaviors. -
Gray production traffic control: Too large, explosion radius increases; too small, statistical error increases. -
Another important issue is that in Phase IV, it mentions that “regulatory authorities can quickly recall the drug or withdraw it from the market.” From the perspective of chaos engineering, this is the “One-Click Shutdown of Production Experiment.”

Welcome to follow the Chaos Engineering Practice public account!