
Future丨Intelligence丨Nutrition丨Energy
Let reading become a habit, let the soul have warmth
An Overview of Fault Injection

1. Introduction to Fault Injection
In the field of computer science, Fault Injection is a controlled method of injecting faults into computer systems to simulate their responses under real fault conditions. It is widely used in software testing, fault tolerance algorithm evaluation, and system reliability assessment.
A typical fault injection process is illustrated in Figure 1: the Load Generator produces tasks that drive the target system, the Injector generates and injects faults into the target system, the Monitor observes the output of the target system and analyzes the results, and the Controller coordinates the work of the three. When the Injector does not inject faults into the target system, the operation and output of the target system are referred to as a Golden Run. When the Injector injects faults into the target system, the operation and output are referred to as a Faulty Run. Typically, each run of the target system will involve only one fault injection, with the Monitor comparing and analyzing the Golden Run and the Faulty Run. Through a large number of fault injection experiments and statistical analysis of the results, effective testing of computer systems can be achieved, along with evaluation of software fault tolerance algorithms and system reliability.
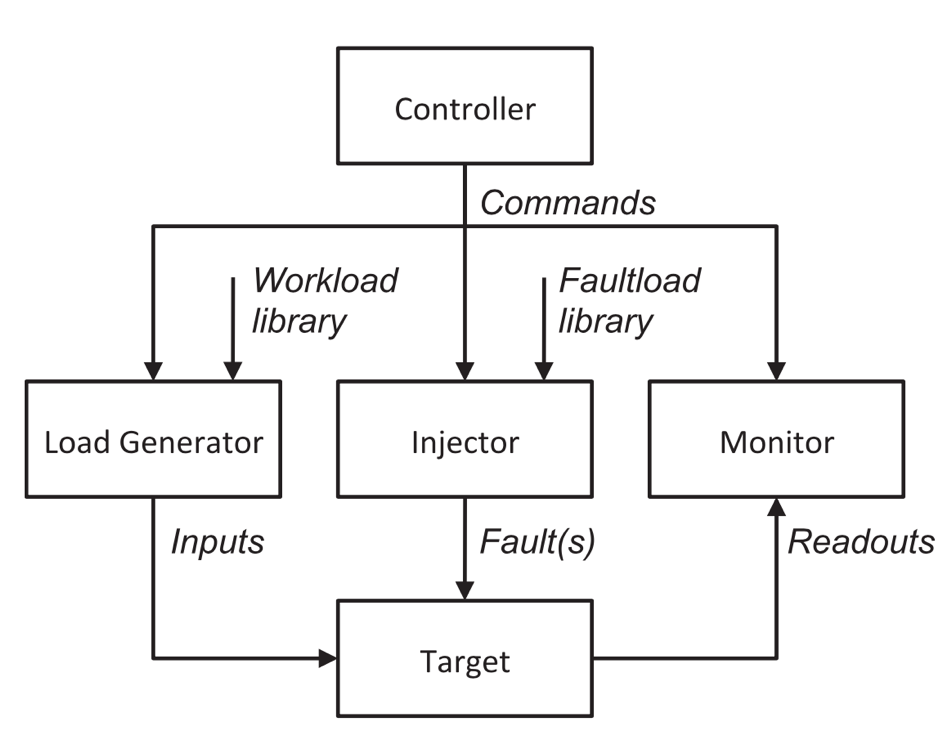
Figure 1: Concept and Process of Fault Injection [1]
2. Terminology of Fault Injection
In fault injection, there are three important concepts: Fault, Error, and Failure [2]. Failure refers to the state where the behavior of the computer system deviates from its normal behavior as perceived externally (mainly referring to user-perceived output). Error refers to the state where the behavior and state of the computer system deviate from normal conditions when viewed internally. Fault is the root cause that leads to errors and failures.
The relationship among the three is illustrated in Figure 2: once a fault is activated, it becomes an error, and if the error cannot be tolerated or corrected by the computer system, it will lead to system failure. In the computer world, faults can fundamentally be divided into two categories: software faults and hardware faults. Software faults refer to defects in software products such as operating systems, middleware, and application software, while hardware faults refer to anomalies in hardware components of the computer system such as CPU, memory, and network. Hardware faults are usually further divided into transient hardware faults (also known as Soft Errors) and permanent faults. Transient hardware faults are typically caused by strong electromagnetic interference or intense radiation and were recognized and emphasized in the 1970s [3].
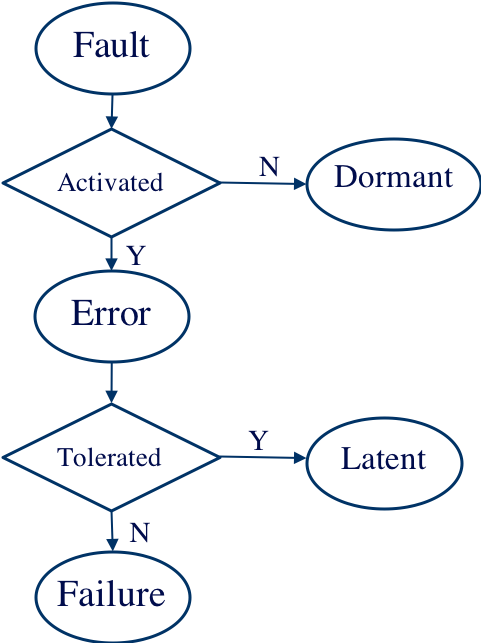
Figure 2: Fault, Error, and Failure
3. Fault Injection Methods
When discussing fault injection methods, two concepts cannot be overlooked: Fault Model and Failure Model, which are core components of fault injection.
-
Fault Model: The fault model primarily answers three questions regarding the fault injection method: what type of fault to inject, where to inject the fault, and when to inject the fault. Fault types fundamentally fall into software faults and hardware faults, but a fault model needs to specify the fault types more concretely, such as null pointer exceptions in software defects, single-byte flip faults in CPU instructions, and multi-byte flip faults in memory data, etc. The injection location needs to be clearly defined, such as where to inject a null pointer exception in the program, which instruction or byte of which type of CPU instruction to flip, etc. The injection time must also be specified, indicating when the fault is injected and whether it is injected multiple times.
-
Failure Model: The failure model is used to define and describe the execution results of the target system after fault injection, thereby analyzing the system behavior and state resulting from the fault. Typically, the execution results of the target system are summarized into four categories: Benign, Crash, Data Corruption, and Hang, but depending on specific analysis requirements, these four outcomes can be further refined based on the exception messages printed by the system. Among them, Benign indicates that the system ultimately produces normal output, Crash indicates that the system did not complete the workload and terminated prematurely, Data Corruption indicates that the system completed the workload but produced incorrect output, and Hang indicates that the system is suspended.
Overview of Fault Injection Methods: Fault injection methods can be categorized based on their implementation means into Hardware Implemented Fault Injection and Software Implemented Fault Injection (SWIFI).
-
Hardware Implemented Fault Injection typically simulates real environmental hardware faults through radiation or electromagnetic environments. However, due to the high financial and time costs of hardware fault injection [4] and its poor controllability, it has a very high threshold, with only a few laboratories having complete hardware fault injection environments.
-
Software Implemented Fault Injection simulates hardware or software faults at the software level and injects them into the target system. Due to its lower implementation cost and stronger controllability, it has attracted significant attention in academia in recent years. Although software implemented fault injection methods can simulate both hardware and software faults, recent academic focus has primarily been on using software methods to inject transient hardware faults, such as injecting byte flip faults into CPU instructions of supercomputing programs or injecting one or more bytes of memory pollution into scientific computing programs. Software implemented fault injection can also be divided into compile-time fault injection and runtime fault injection based on the timing of the fault injection, and can be categorized into application layer fault injection, operating system layer fault injection, and middleware/link library layer fault injection based on the software stack hierarchy.
4. Conclusion
This article provides an overview of the concept and process of fault injection, briefly explaining the classification of different fault injection methods as well as the fault and failure models of fault injection methods. In subsequent articles, we will provide a more detailed introduction to fault injection methods in conjunction with related work.

References
[1] Hsueh, Mei-Chen, Timothy K. Tsai, and Ravishankar K. Iyer. “Fault injection techniques and tools.” Computer 30.4 (1997): 75-82.
[2] Avizienis, Algirdas, et al. “Basic concepts and taxonomy of dependable and secure computing.” IEEE transactions on dependable and secure computing 1.1 (2004): 11-33.
[3] Binder, Daniel, Edward C. Smith, and A. B. Holman. “Satellite anomalies from galactic cosmic rays.” IEEE Transactions on Nuclear Science 22.6 (1975): 2675-2680.
[4] Karlsson, Johan, et al. “Application of three physical fault injection techniques to the experimental assessment of the MARS architecture.” Dependable Computing and Fault Tolerant Systems 10 (1998): 267-288.
Author Introduction and Previous Articles
Yang Yong, Software Engineering Major
PhD Student, Fourth Year
Research Direction:Distributed Tracing
-
Introduction to Service Dependency Discovery
-
Encryption, Hashing, Digital Signatures, CA Certificates, and Encrypted Transmission
-
Introduction to Distributed Tracing Systems
-
Discussion on Blockchain
-
Tag Recommendation in Software Communities
-
Introduction to Ceph Distributed Storage System
For reprints, please contact:



Long press to recognize the QR code to follow us
Time and tide wait for no man