
Source: Xiaomi Technology Author: Li Qianming – Big Data SRE
1. Background

2. Introduction to Chaos Engineering

-
Chaos Engineering is a practice that generates new information, whereas fault testing is a specific method to test a situation. -
Fault testing implements injection experiments and verifies expectations in specific scenarios, while chaos engineering experiments validate around a “steady state” through more scenarios. -
Chaos Engineering recommends conducting experiments in production environments.
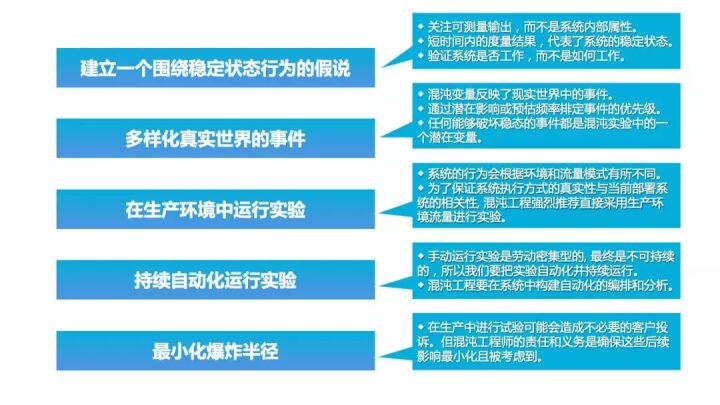
3. Principles of Chaos Engineering

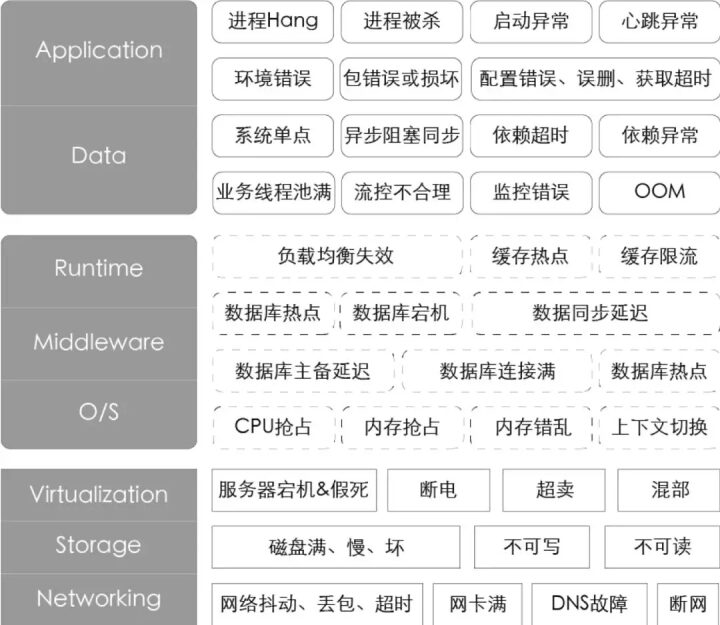
4. Building a Fault Injection Platform

-
Provide a diversified, visual operation automated fault injection platform. -
Serve as a unified entry point for various drills and fault tests and verifications. -
Accumulate and solidify various experimental plans, establishing a baseline for system robustness assessment.
-
Help the business discover more unknown issues affecting business stability. -
Verify the effectiveness and completeness of business alerts. -
Validate whether business contingency plans are effective.
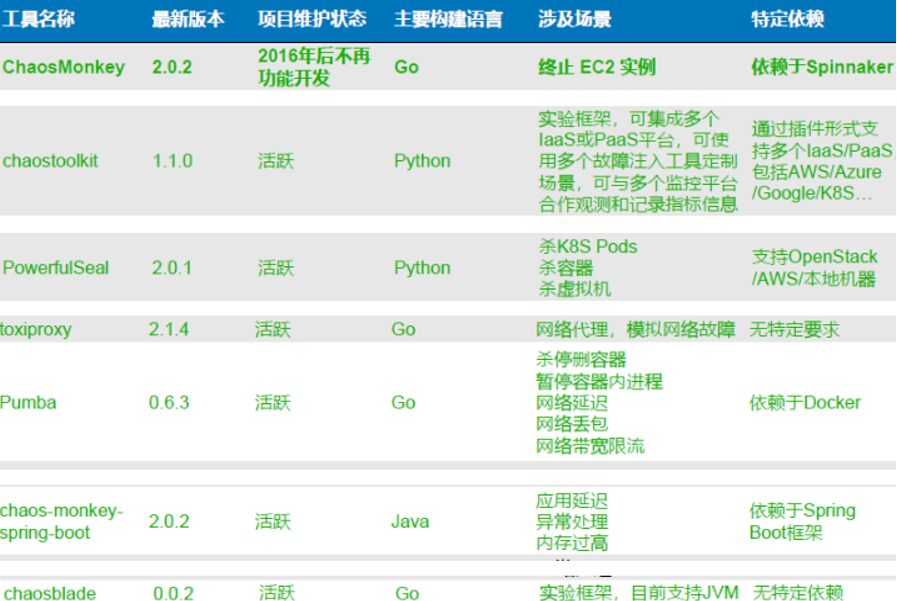
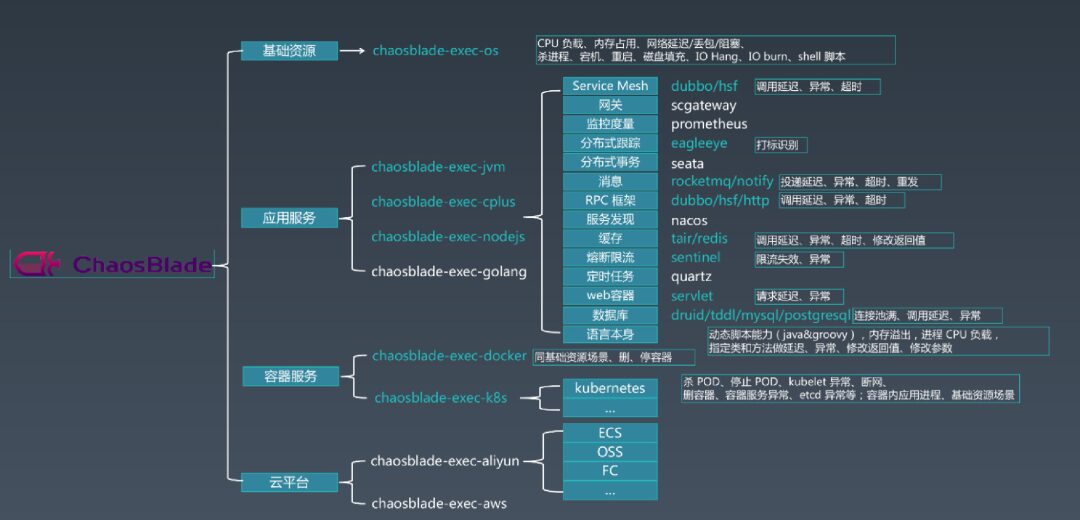
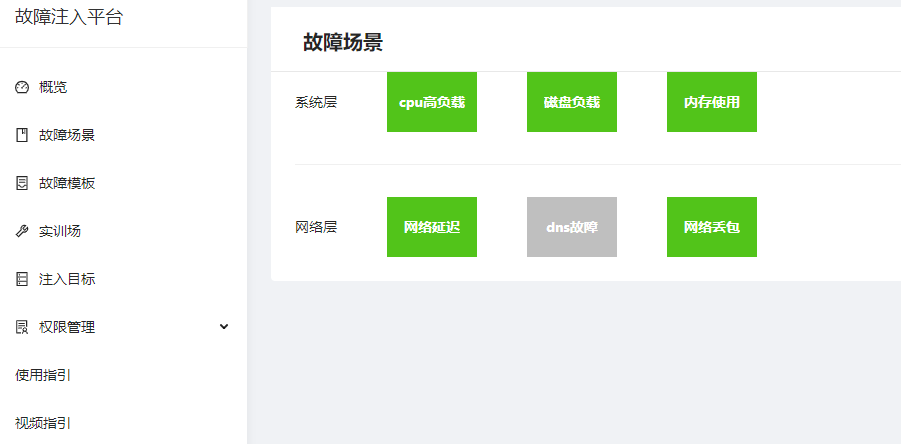

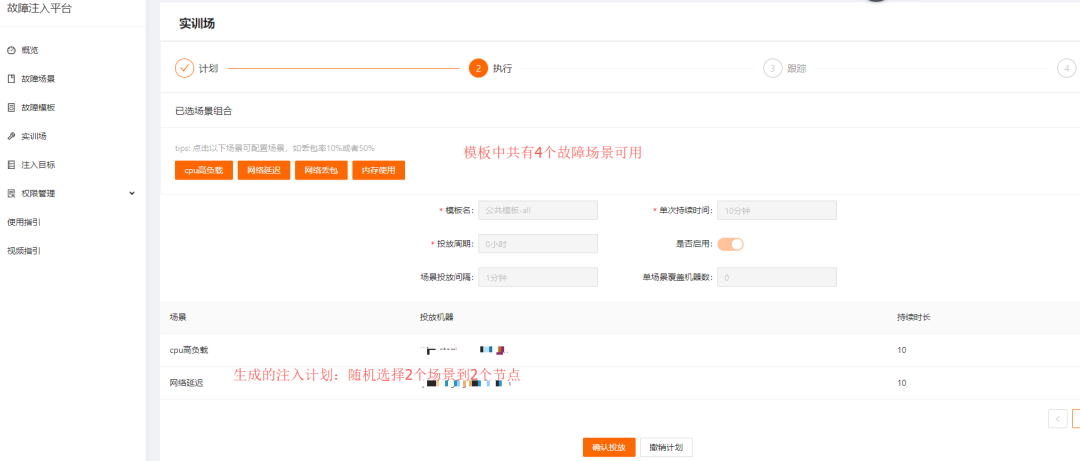
5. Practical Drills

-
Define and measure the system’s “steady state”, accurately define indicators. -
Create hypotheses. -
Continuously import online traffic into the testing environment. -
Simulate possible real-world events. -
Prove or disprove the hypotheses. -
Summarize and optimize feedback issues.
-
Overall CPS of the cluster service. -
Task submission response delay. -
Task submission success rate. -
Task parsing failure rate. -
Target acquisition success rate. -
Data consistency and integrity.
| Injection Function Name | Description |
|---|---|
| CPU Injection | Load reaches 90% |
| Memory Injection | Memory consumption reaches 90% |
| Network Packet Loss | Packet loss rate 30% |
| Network Latency | Increase by 100ms |
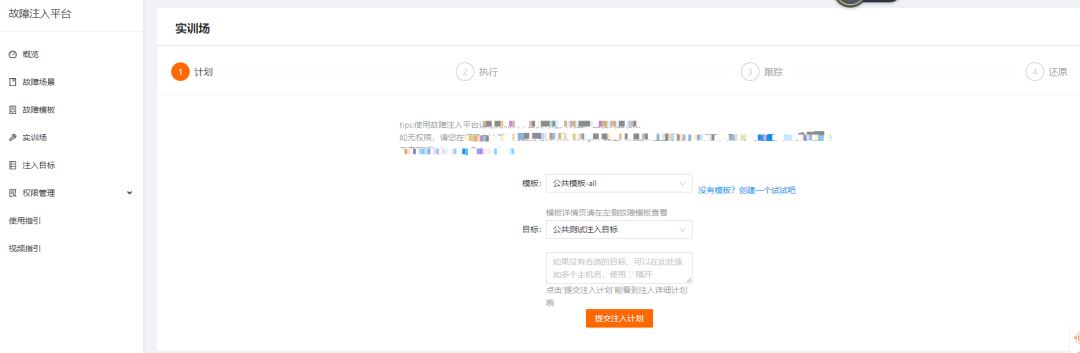
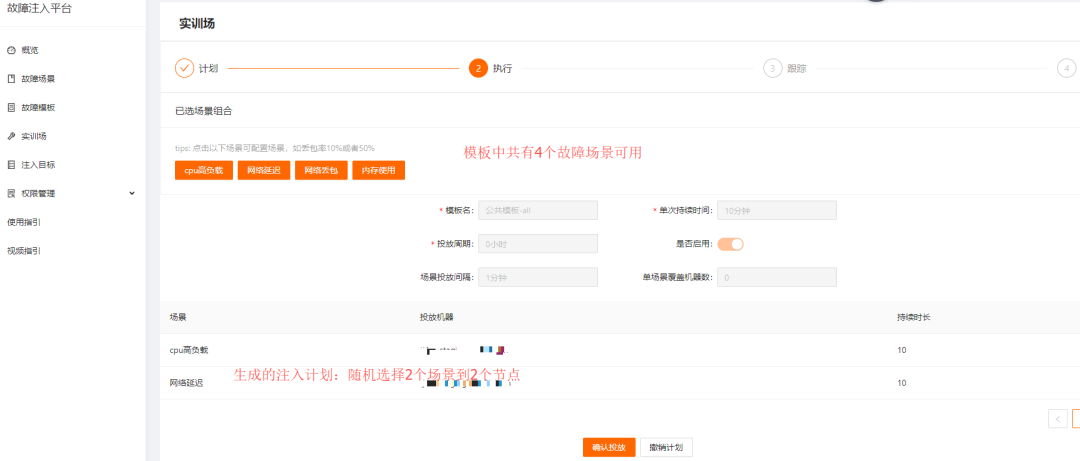
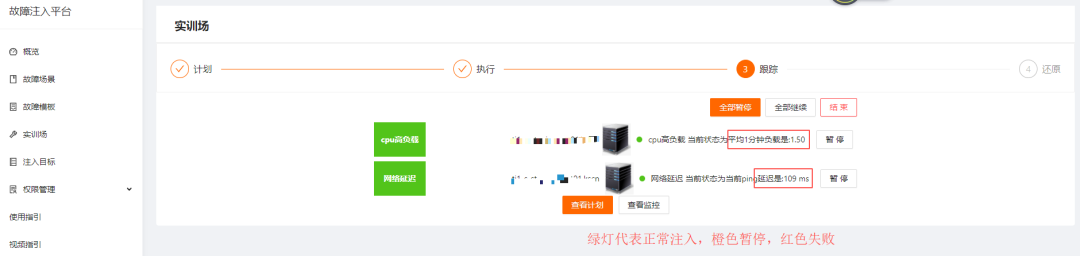

-
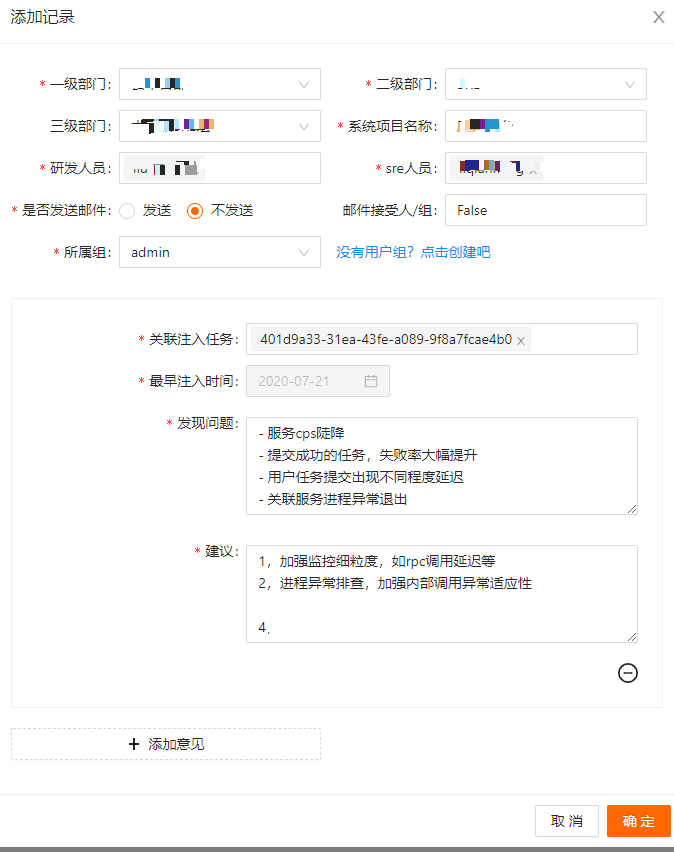
Service CPS dropped sharply. -
Successful task submissions had a significant increase in failure rate. -
User task submissions experienced varying degrees of delay. -
Associated service processes exited abnormally. -
Monitoring is not granular; it can detect increases in CPS and failure rates, but locating the issues is difficult.

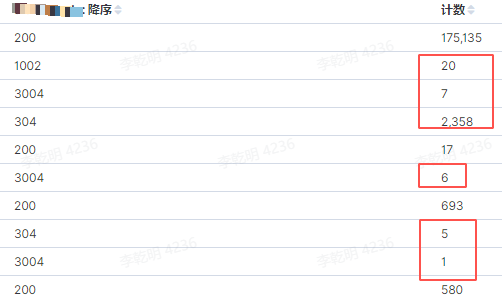
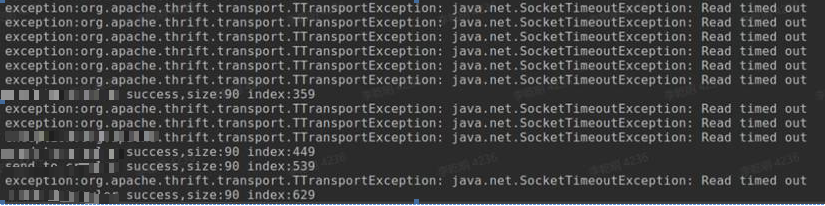
-
Hypothesis: Certain nodes may experience task submission response delays when performance or network-related issues exist, without affecting the steady state. -
Prove: There are task submission response delays, indirectly indicating a decrease in CPS. -
Disprove: Discovered unexpected increases in task execution failures and abnormal exits of associated processes, as well as issues with monitoring granularity and lack of detail.
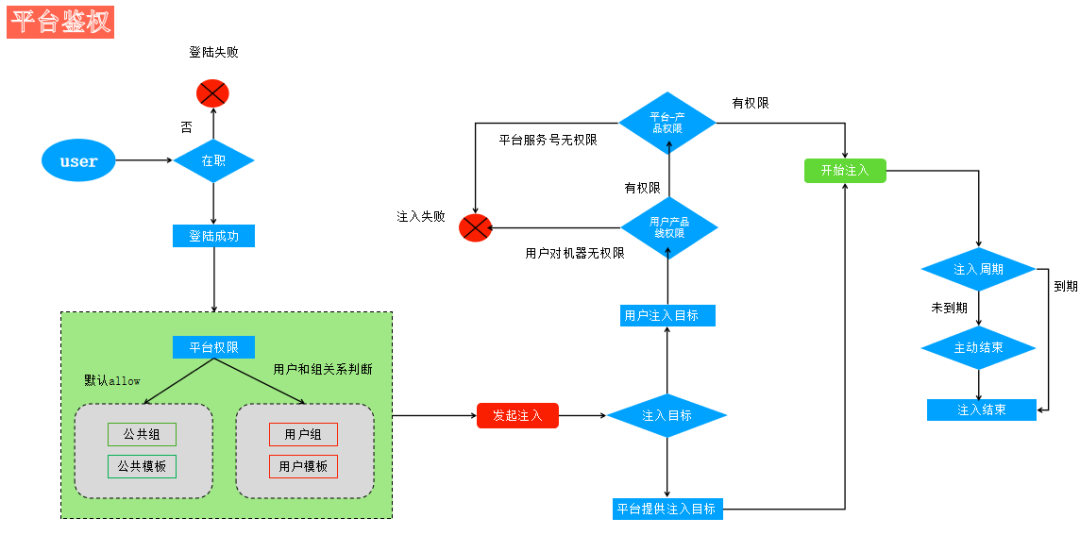
6. Other Issues

7. Future Planning

-
Gradually improve the fault scenarios depicted in the fault portraits drawn from the perspectives of IaaS, PaaS, and SaaS layers mentioned in this article. -
Combine SLO, degradation, and traffic scheduling to minimize the explosion radius and prepare for online injection experiments. -
Be able to actively probe and map the topology of traffic and service call relationships.

