In today’s society, internet applications are becoming increasingly widespread, with a growing number of users. As people’s reliance on internet services increases, so do their expectations for service availability and experience. So how can we ensure that services consistently provide users with stable, uninterrupted, and reliable service during operation?
For instance, if a financial product encounters a problem, it can result in significant losses. It is well known that the system architecture and service logic of financial products are quite complex, which leads everyone to think of testing engineers first. They validate service stability through unit testing, integration testing, performance testing, and so on. However, even with these measures, it is still far from sufficient, as errors can occur at any time and in any form, especially in distributed systems. This is where Chaos Engineering needs to be introduced.
2. Introduction to Chaos Engineering
Chaos Engineering is a methodology for proactively identifying vulnerabilities in systems by conducting experiments on system infrastructure, initially proposed by Netflix and related teams. It aims to detect failures before they cause interruptions, essentially ‘killing failures in the cradle’. By intentionally inducing failures, testing the system’s behavior under various pressures, identifying and fixing failure issues, we can avoid severe consequences. In 2012, Netflix open-sourced Chaos Monkey. Today, many companies (including Google, Amazon, IBM, Nike, etc.) adopt some form of Chaos Engineering to enhance the reliability of modern architectures.
Difference Between Chaos Engineering and Fault Testing
-
Chaos Engineering is a practice for generating new information, while fault testing is a specific method for testing a situation.
-
Fault testing implements injection experiments and verifies expectations in specific scenarios, while Chaos Engineering experiments validate through more scenarios around a ‘steady state’.
-
Chaos Engineering recommends conducting experiments in production environments.
Chaos Engineering is very suitable for exposing unknown weaknesses in production systems, but if it is determined that Chaos Engineering experiments will lead to severe problems in the system, then running the experiment is meaningless.
Currently, domestic practices in related companies tend to lean towards fault testing, that is, implementing fault injection experiments in specific scenarios and verifying whether expectations are met. The risks of this type of testing are relatively controllable, but the downside is that it does not explore more scenarios through fault injection experiments, exposing more potential issues, and the testing results are heavily dependent on the experience of the implementer. Of course, we believe that this is a stage that must be passed on the road to achieving the goals of Chaos Engineering.
The expectations and verifications of fault testing differ from the behaviors defined by Chaos Engineering’s steady state, with the fundamental reason for the differences being the different organizational forms. In 2014, the Netflix team created a new role called Chaos Engineer and began promoting it within the engineering community. However, most domestic enterprises currently do not have a dedicated position to implement Chaos Engineering, leading to differences in project goals, business scenarios, personnel structures, and implementation methods, which result in a non-standard definition of steady state behavior. Of course, we currently do not have Chaos Engineers. Therefore, based on different definition standards, organizational forms, and stages, our introduction and use of Chaos Engineering experiments are also more inclined towards fault testing.
3. Principles of Chaos Engineering
The following principles describe the ideal way to apply Chaos Engineering, which should be followed during the experimental process. The degree of alignment with these principles can enhance our confidence in large-scale distributed systems.
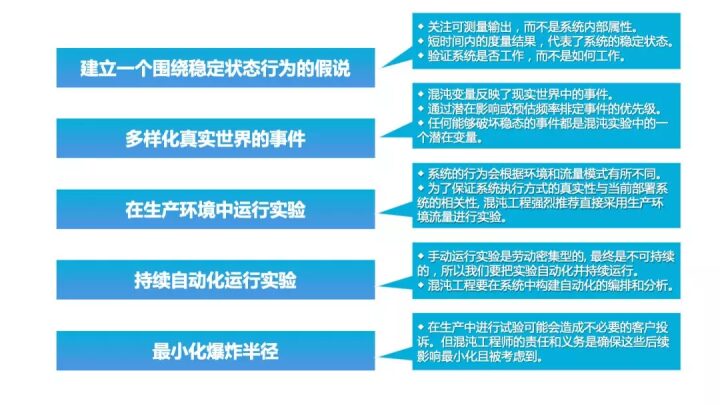
Build Hypotheses Around Steady State Behavior
Focus on measurable output results of the system, rather than internal attributes of the system. Measure output results in a short time and use this as a representation of the system’s steady state. Overall system data throughput, error rates, and latency percentages can all serve as key indicators of steady state behavior. By focusing on various system behavior patterns during experiments, Chaos Engineering can verify whether the system operates normally—without needing to try to decipher how it works.
Diversify Real-world Events
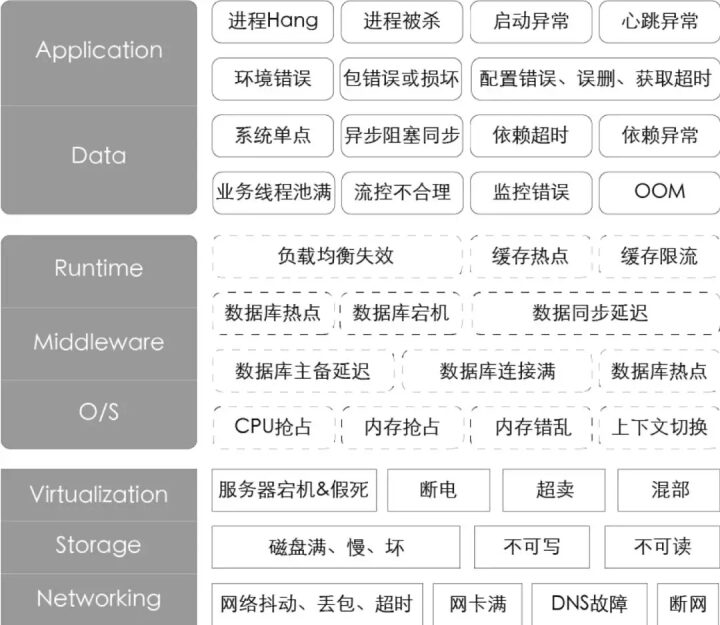
Chaos variables should directly reflect various real-world events. We should consider various or related faults, and any event that could lead to a steady state interruption should be viewed as a potential variable in chaos experiments. Due to diverse business models and highly complex system architectures, there can be many types of faults; prior analyses have prioritized P1 and P2 faults, drawing fault profiles from the perspectives of IaaS, PaaS, and SaaS layers, as shown in the following figure.
Run Experiments in Production Environment
From a functional fault testing perspective, implementing fault injection in a non-production environment can meet expectations, so the earliest strong and weak dependency tests were completed in daily environments. However, because system behavior may differ based on the environment and traffic patterns, to ensure the authenticity of system execution and its relevance to the currently deployed system, the recommended implementation method is still in the production environment. However, many enterprises have not yet conducted experiments in production environments.
Continuously Automate Experimental Operations
Use fault injection platformization to replace manual experiments, automatically build orchestration and analysis.
Minimize Explosion Radius
Chaos Engineering recommends conducting experiments in online environments, but there is a possibility that it could lead to system anomalies or even exacerbated anomalies. From an implementation perspective, it is best to effectively reduce the impact of anomalies through technical means, such as effectively stopping injections based on system steady state indicators, throttling, traffic switching, and data isolation, all of which are means to reduce business impact.
4. Building a Fault Injection Platform
-
Provide a diversified, visual operation automated fault injection platform.
-
Serve as a unified entry point for various drills, fault testing, and verification.
-
Accumulate various experimental schemes and establish a baseline for system robustness evaluation.
-
Help the business discover more unknown issues affecting stability.
-
Verify the effectiveness and completeness of business alerts.
-
Validate whether the business’s fault contingency plans are effective.
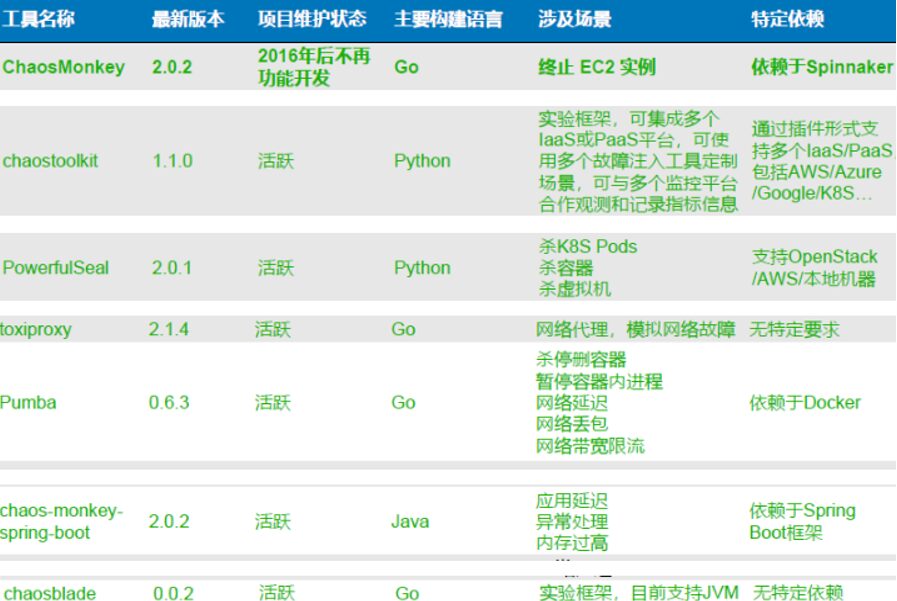
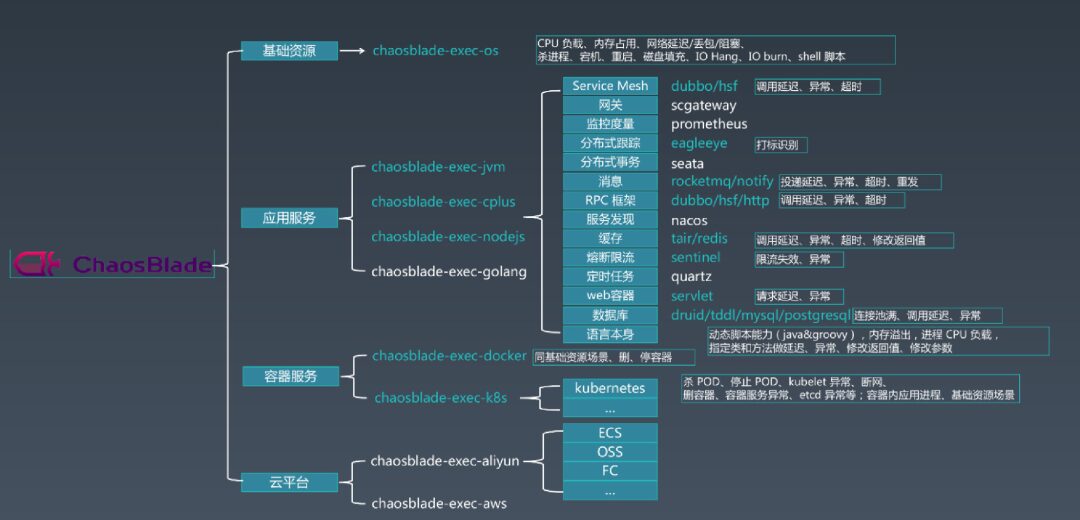
Currently, there are many diverse tools in the industry for simulating faults, each with its strengths and weaknesses in supported functions and scenarios. Comparatively, chaosblade supports a rich set of functions and scenarios, and its community is quite active. After fully validating most injection functions, we chose it as the core module for underlying injection.
The scenarios supported by chaosblade can be referenced in the documentation:
https://chaosblade-io.gitbook.io/chaosblade-help-zh-cn/
The entire fault injection process is divided into four stages:
The platform construction approach is still centered around the four main processes. The platform modules are categorized as shown in the figure below:
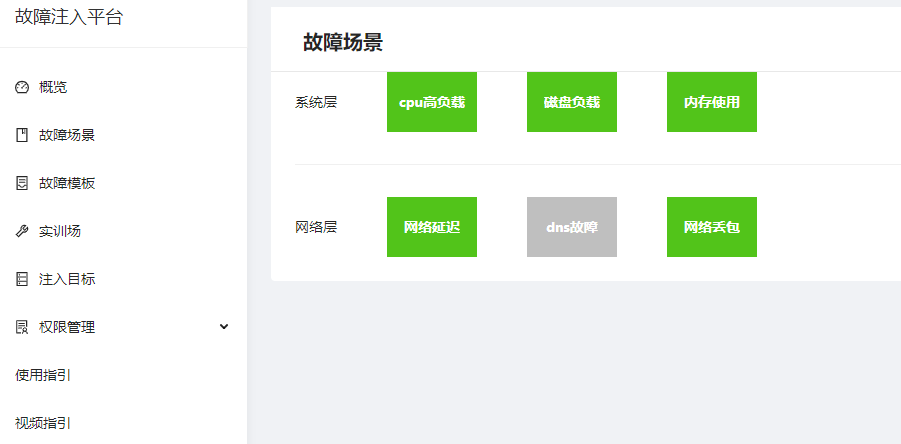
Currently, the injection scenarios supported by the platform include system layer and network layer types, mainly comprising network delay, packet loss, CPU saturation, memory saturation, and disk IO saturation scenarios. These scenarios are hot-pluggable integrated into the platform, allowing for flexible adjustments and expansions of scenarios.
For practical drills, we selected a relatively stable business A (Business A is a multi-node task scheduling and target fetching service) and conducted experiments in the testing environment of Business A, while the business side was eager to see if such a stable system had any more defects.
The entire process overview is as follows:
-
Define and measure the system’s ‘steady state’, precisely defining metrics.
-
-
Continuously import online traffic into the testing environment.
-
Simulate real-world events that may occur.
-
Prove or refute hypotheses.
-
Summarize and provide feedback for optimization.
When the business task system is running, the following indicators can represent the system’s steady state.
-
Overall CPS of the cluster service.
-
Task submission response latency.
-
Task submission success rate.
-
Task parsing failure rate.
-
Target acquisition success rate.
-
Data consistency and integrity.
Hypothesize that certain nodes may experience task submission response latency during performance or network-related issues, without affecting the steady state.
Hypothesize that node outages do not affect the steady state (this will not be introduced here).
Traffic replication and testing environment import will not be introduced here.
Use system layer + network layer random injection scenarios for simulation.
The following table shows the configuration of fault scenarios in the fault injection platform.
|
|
|
|
|
|
|
|
Memory consumption reaches 90%
|
|
|
|
|
|
|
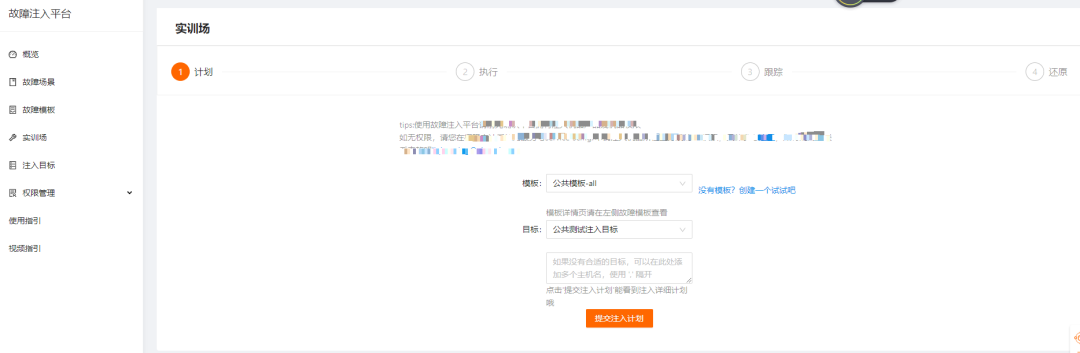
In the platform, we select the system scenario fault template and injection target (in a single injection task, a single machine can only inject one scenario, with scenarios and machines chosen randomly).
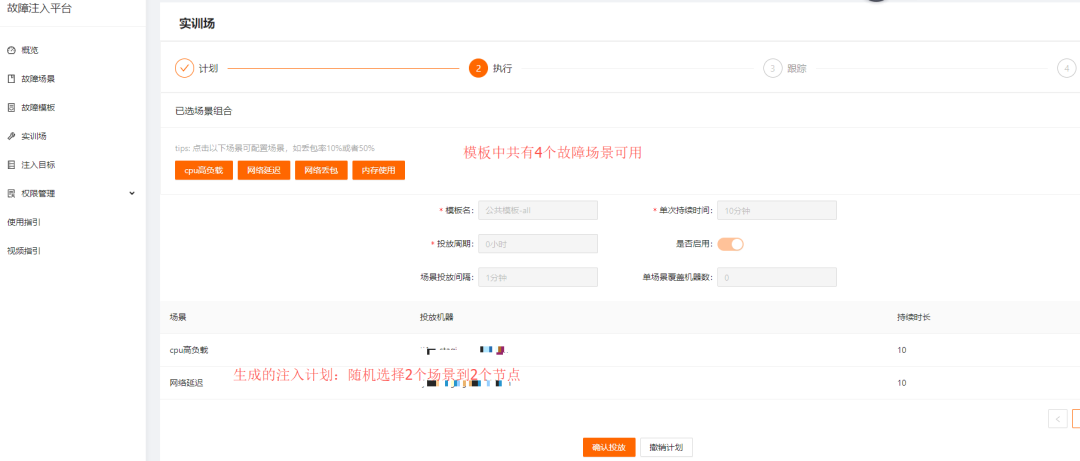
By selecting the injection template and target, an injection plan is generated, as shown in the figure below:
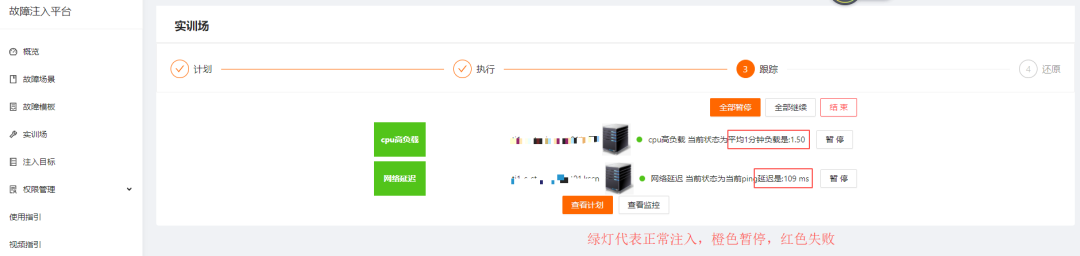
Execute the injection, as shown in the figure below; during the injection process, the operator can end and pause the injection task at any time.
Manually pause the designated target; clicking continue will resume injection.
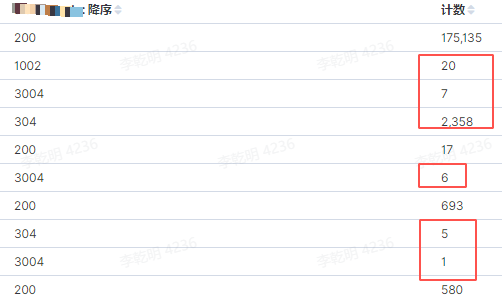
In the overall observation, the following issues were discovered:
-
Service CPS dropped sharply.
-
Successful task submissions experienced a significant increase in failure rates.
-
User task submissions encountered varying degrees of delay.
-
Associated service processes exited abnormally.
-
Monitoring was not granular; it could detect increases in CPS and failure rates, but pinpointing issues was difficult.
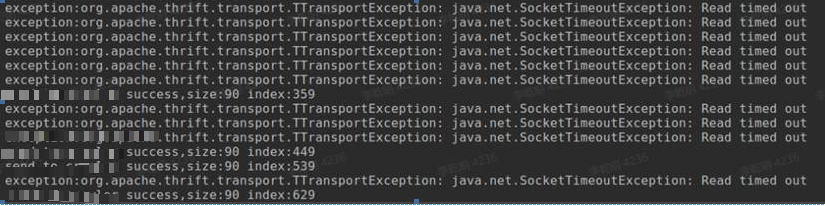
It was found that the overall service CPS had dropped sharply, indicating a severe decline in the service’s processing capacity.
The increase in the number of failed task executions indicates that tasks were submitted, but the service did not complete them as expected.
User submission delays and timeouts increased.
End the entire injection task.
After the injection task ended, all business indicators gradually returned to normal.
Prove or Refute Hypotheses
-
Hypothesis: Certain nodes may experience task submission response delays during performance or network-related issues, without affecting steady state.
-
Prove: Task submission response delays were present, indirectly indicating a decline in CPS.
-
Refute: Discovered unexpected increases in task execution failures and associated process abnormal exits, along with issues of missing and non-granular monitoring.
Add a summary and feedback from this injection:
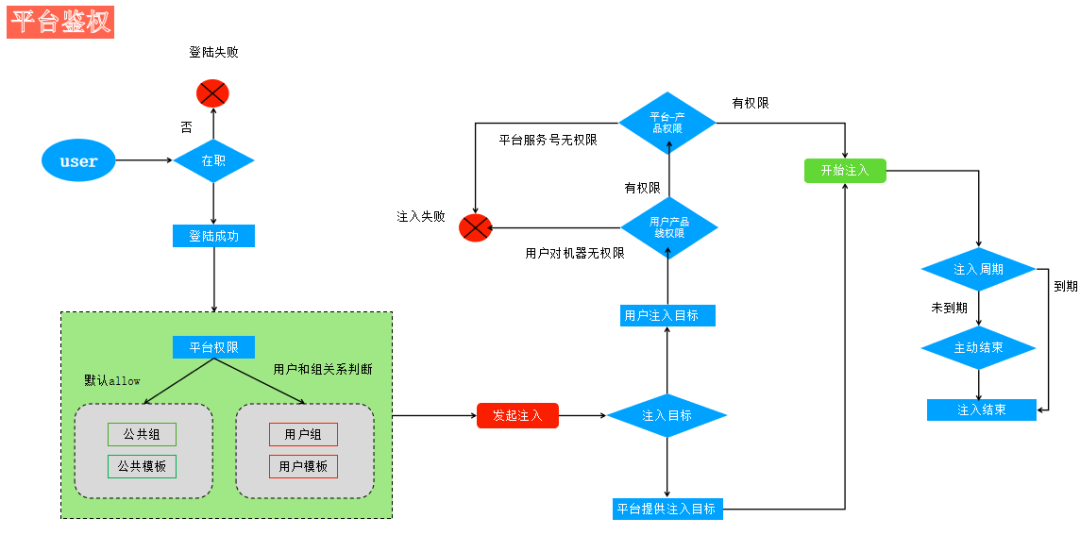
1. Can any user inject into any machine?
The platform currently involves multiple dimensions of permissions: user employment status, platform user permissions, user and machine permissions, and platform and machine permissions.
2. If the target machine becomes saturated or experiences severe packet loss due to injection, how can SRE colleagues log in?
Answer: The system will whitelist the target machine during injection; for example, scenarios involving packet loss or network interruptions may prevent other users from logging in, but our task machine will not be affected. For saturation injections, we will control the saturation level to avoid making the machine completely inoperable. There are also personalized parameter configurations that users can adjust within set limits.
3. Can the platform automatically determine when to stop injection? If not, will the injection continue indefinitely if the user forgets to manually stop it?
Answer: Currently, it cannot automatically determine when to stop injection. If the manual stop operation is forgotten, users will have a set duration for the injection task when selecting the injection template or configuring the injection plan; if this time is exceeded, the injection task will automatically end.
Gradually improve the fault scenarios drawn from the perspectives of IaaS, PaaS, and SaaS layers mentioned in this article.
Combine SLO, degradation, and traffic scheduling to minimize the explosion radius and prepare for online injection experiments.
Proactively detect and draw the topology of traffic and service call relationships.