1. Difference Between URL and URI
The full name of URI: Uniform Resource Identifier.
The full name of URL: Universal Resource Locator.
URL is a subset of URI, meaning that every URL is a URI, but not every URI is a URL.
The address we enter in the browser is a URL/URI. The URL specifies the access method, including the access protocol (http/https), access path (starting from the root directory), and resource name. Through the URL link, resources can be found on the Internet.
Generally, we can refer to a webpage link as both a URL and a URI.
Hypertext: hypertext, the webpage opened by the browser is parsed from hypertext, and its webpage code is HTML code, which contains a series of tags. After the browser parses the tags, it forms the webpage we see, and the source code of the webpage HTML is hypertext.
3. Difference Between HTTP and HTTPS
1. The full name of HTTP: Hyper Text Transfer Protocol, in Chinese: 超文本传输协议. The HTTP protocol is used for transferring hypertext data from the network to the local browser, ensuring efficient and accurate transmission of hypertext documents. HTTP is a specification jointly developed by the World Wide Web Consortium and the Internet Engineering Task Force (IETF).
2. The full name of HTTPS: Hyper Text Transfer Protocol Secure Socket Layer, is an HTTP channel with security as the goal. Simply put, it is the secure version of HTTP, which adds an SSL layer to HTTP, abbreviated as HTTPS.
The security basis of HTTPS is SSL, so the content transmitted through it is encrypted with SSL. Its main functions can be divided into two types:
First: Establishing a secure channel for information to ensure the safety of data transmission;
Second: Confirming the authenticity of the website. Any website using HTTPS can check the real information after certification by clicking the lock icon in the browser’s address bar, and can also be queried through the security seal issued by a CA institution.
After entering a URL in the browser, the browser sends a request to the server where the website is located. The website server receives the request, processes and parses it, then returns the corresponding response back to the browser, which contains the source code content of the page. The browser then parses it and presents the webpage.
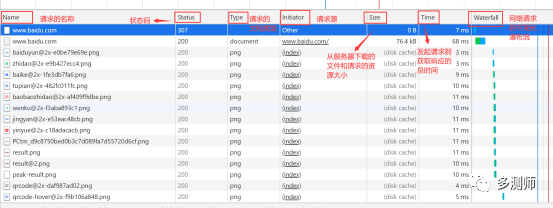
By pressing F12, you can view the process of sending requests and responses (taking Baidu as an example, as shown in the figure below)
The first column Name: The name of the request. Generally, the last part of the URL is used as the name.
The second column Status: The status code of the response. Here, 200 indicates a normal response. Through the status code, we can determine whether a normal response was received after sending the request.
The third column Type: The type of requested document. Here, document indicates that we requested an HTML document, which contains some HTML code.
The fourth column Initiator: The request, used to mark which object or process initiated the request.
The fifth column Size: The size of the file downloaded from the server and the requested resource. If the resource is obtained from the cache, this column will show “from cache”.
The sixth column Time: The total time taken from initiating the request to obtaining the response.
The seventh column Waterfall: A visual waterfall of network requests.
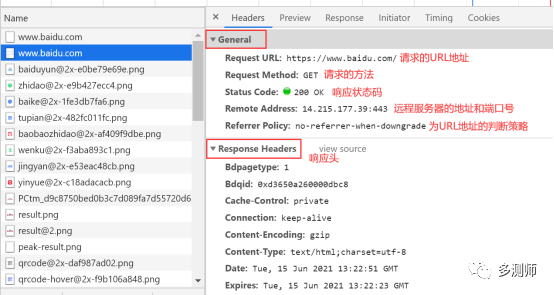
Clicking on a URL can see more detailed information, as shown in the figure below
A request consists of four parts: Request Method, Request URL, Request Header, and Request Body.
Common request methods: POST and GET requests
In a GET request, parameters are included in the URL, and data can also be seen in the URL, while in a POST request, the URL does not contain this data; data is transmitted in form format and included in the request body.
A GET request can submit a maximum of 1024 bytes of data, while POST has no limit.
Generally, when logging in, user and password need to be submitted, which contains sensitive information. If a GET request is used, the password will be exposed in the URL, causing password leakage. Therefore, it is best to use the POST request method for login, and for uploading files, due to the larger size, the POST request method will also be used.
It is the Uniform Resource Locator (URL), which uniquely determines the resource we want to request.
The request header is used to indicate additional information that the server needs. Important information includes Cookie, Referer, User-Agent, etc.
Accept: The request header field used to specify what types of information the client can accept.
Accept-Language: Specifies the language types that the client can accept.
Accept-Encoding: Specifies the content encoding that the client accepts.
Host: Used to specify the IP address and port number of the host of the requested resource, which is the location of the original server or gateway of the requested URL.
Cookie: Also commonly used in plural form as Cookies, this is data stored locally by the website to track sessions and identify users. The Cookies contain information that identifies the session corresponding to our server. Each time the browser requests a page from that site, it adds the Cookies to the request header and sends it to the server, which identifies us through the Cookies and returns the current status to the page.
Referer: This content is used to identify which page the request came from, and the server can obtain this information and respond accordingly.
User-Agent: Abbreviated as UA, it is a special string that allows the server to identify the operating system and version, as well as the browser version information used by the client.
Content-Type: Also known as Internet Media Type or MIME type, it is used to represent the media type information in the request, such as: text/html represents HTML format, image/gif represents GIF image, application/json represents JSON type.
The request body generally carries the data of the form in a POST request, while for a GET request, the request body is empty.
For example: Content-Type is application/x-www-form-urlencoded, indicating the form data format; application/json indicates serialized JSON format data; multipart/form-data indicates form file upload; text/xml represents XML data.
The response is returned from the server to the client and can be divided into three parts: Response Status Code, Response Headers, and Response Body.
Status Code: Indicates the response status of the server. 200 indicates that the server responded normally, 404 means the page was not found, and 500 indicates an internal server error.
1xx Informational: These status codes indicate temporary responses. The client should be prepared to receive one or more 1xx responses before receiving a regular response.
2xx Success: These status codes indicate that the server successfully accepted the client’s request.
3xx Redirection: The client browser must take additional actions to fulfill the request.
4xx Client Error: An error occurred, indicating that there seems to be a problem with the client.
5xx Server Error: The server cannot complete the request due to an error.
Response Headers: Contain the server’s response information to the request, such as: Content-Type, Server, Set-Cookie, etc.
Date: Indicates the time the response was generated.
Last-Modified: Specifies the last modification time of the resource.
Content-Encoding: Specifies the content encoding of the response.
Server: Server information.
Content-Type: Document type.
Set-Cookie: Sets Cookies. The Set-Cookie in the response header tells the browser to store this content in Cookies, which will be sent with the next request.
Expires: Specifies the expiration time of the response, allowing the proxy server or browser to update the loaded content in the cache.
Response Body: The main data of the response is contained in the response body.
For more information on testing technology, please follow: http://www.duoceshi.cn/ Shenzhen Duoceshi Information Technology Co., Ltd.