This article is from the public account: Jin Qiu Ji, reproduced for academic/technical sharing. If there is any infringement, please contact us to delete the article.
Original link: https://mp.weixin.qq.com/s/xHXmf3yXFwFs5Jqk2vIJVw
As agents are deployed into deeper waters, the tasks they face increasingly demand deep reasoning and multi-step interactions, making single-agent architectures often inadequate. Multi-Agent systems are gaining attention for their potential to handle complex tasks. By collaborating multiple agents, we hope to break through the limitations of single models and achieve stronger AI capabilities.
However, beneath this promising vision, practice often encounters difficulties such as inefficient collaboration and results deviating from expectations. What forms do these failures take? More importantly, how can we analyze existing multi-agent architectures to build more reliable and effective agent teams?
This article aims to answer these critical questions. We will combine the findings from the studies “Why Do Multi-Agent LLM Systems Fail?” and “Balancing Autonomy and Alignment: A Multi-Dimensional Taxonomy for Autonomous LLM-powered Multi-Agent Architectures” to illustrate the 14 failure modes of multi-agent architectures and introduce a multi-dimensional architectural classification framework for systematically analyzing and evaluating multi-agent systems.
We believe that while agents currently face many challenges in deployment, these issues can be alleviated with improvements in model capabilities and reinforcement learning. Listing these potential failure causes is based on our firm belief that these identified problems can be resolved.
01
Analysis of Failure Modes in Multi-Agent Systems
To understand why multi-agent systems fail, a study from Berkeley (https://arxiv.org/abs/2503.13657) conducted an in-depth empirical analysis of popular multi-agent frameworks:
The researchers selected five commonly used multi-agent systems and designed over 150 tasks to test their performance, with six experts meticulously annotating the execution process. Through this large-scale, multi-scenario analysis, they identified 14 unique failure modes and further distilled a failure mode classification system applicable to various systems (Multi-Agent System Failure Taxonomy, MASFT).
This classification organizes fine-grained failure modes into three high-level categories, each corresponding to a major source of problems. Below, we introduce these failure modes by category, summarizing their manifestations and causes, and citing specific cases from the research to illustrate.
Specification and System Design Failures
These failures stem from defects at the system design level, including misunderstandings of task requirements, poor session management, or unclear/ignored definitions of agent roles and responsibilities. In simple terms, the system fails to execute what it is supposed to do—this could be due to flaws in the task description or constraints, or the system not acting according to user requirements.
| Failure Mode | Brief Description |
| 1.1 Violation of Task Specifications | Failure to adhere to task goals or constraints, resulting in outcomes that do not meet requirements. |
| 1.2 Violation of Role Specifications | Failure to act according to assigned role responsibilities, leading to decision conflicts or workflow disruptions. |
| 1.3 Step Repetition | Repeated execution of completed steps, causing redundant operations and dialogues, wasting resources or delaying progress. |
| 1.4 Loss of Dialogue History | Ignoring or losing recent communication content, reverting to outdated states, leading to subsequent decision deviations or redundant work. |
| 1.5 Unrecognized Termination Conditions | Unclear when to stop, leading to meaningless subsequent operations or loops, unable to timely end tasks. |
A common issue in multi-agent systems is misunderstanding or violating user task instructions. Sometimes, the instructions provided by users are incomplete or ambiguous, causing agents to have conflicting interpretations; but even when the instructions are clear, the system may deviate due to poor internal alignment.
The research found a typical failure mode is violation of task specifications, where the final output of the system does not meet the initial requirements. For example, in the testing of the ChatDev system, the user requested to develop a two-player game using chess notation (such as “Ke8”, “Qd4”) as input.
However, the game generated by ChatDev required input of the starting and ending coordinates of the pieces (in the format of (x1,y1),(x2,y2)), completely deviating from the input format specified by the user. Despite the user’s clear requirements, the system failed to comply, resulting in an unsatisfactory output.
Another related failure mode is non-compliance with role specifications. Multi-agent systems typically assign specific responsibilities to different agents, but during execution, sometimes an agent may “overstep” or exceed its authority, disrupting the assumed role division.
In the case of ChatDev, the CPO (Chief Product Officer) Agent, originally responsible for product conception, sometimes overstepped its authority to make decisions that only the CEO could make—such as determining the product vision and making final decisions independently. This behavior is akin to the CPO acting as the CEO, violating the predetermined role responsibilities.
This failure indicates that even if roles are well designed, the system may not ensure that each agent performs its duties during operation.
The causes of such task/design-level failures can be summarized as:unclear specifications or missing constraints (the system does not know the precise requirements, or there is no mechanism to enforce compliance with the requirements).
When the system lacks alignment mechanisms to ensure the boundaries of agent behavior, the strong autonomy of agents may lead them off track. Without human supervision, once misunderstandings occur, timely corrections become difficult.
Inter-Agent Misalignment
These failures arise from poor communication and collaboration between agents, including inefficient communication, lack of information sharing, behavioral conflicts, or gradually deviating from the initial task goals after multiple interactions. Here, “misalignment” specifically refers to agents failing to align with each other (not being on the same page), rather than alignment with human users.
| Failure Mode | Brief Description |
| 2.1 Dialogue Reset | Unnecessarily restarting the dialogue, losing established context or progress. |
| 2.2 Failure to Seek Clarification | When faced with unclear information, agents do not proactively ask others for clarification, continuing to operate based on incomplete understanding. |
| 2.3 Task Deviation | Gradually deviating from the initial goal as interactions progress, shifting to irrelevant topics or processes. |
| 2.4 Concealing Key Information | Agents with important information fail to share it with the team, leading to incorrect decisions or actions by other agents. |
| 2.5 Ignoring Others’ Inputs | Failing to seriously consider or adopt feedback from other agents, resulting in viable information not being utilized. |
| 2.6 Inconsistency Between Reasoning and Action | Conflicts between reasoning and execution, where the thought process seems reasonable but the operational direction is incorrect, ultimately distorting the output results. |
Multi-agent systems often experience inefficient dialogue or “chit-chat” situations: multiple agents engage in back-and-forth conversations for many rounds without substantial progress, wasting computational resources and time.
Researchers provided an example from ChatDev: in a task requiring the creation of a Wordle-like word game, the Programmer Agent repeatedly discussed with several other roles (CTO, CCO, etc.) for seven rounds but failed to effectively update the initially generated code.
As a result, the final game produced was barely playable, very rudimentary (only supporting five simple words), and had poor replayability. A lot of additional dialogue did not genuinely improve the quality of the outcome, but rather wasted resources—a typical failure mode of excessive talking without action. This indicates that if the collaboration mechanism among agents is poor, they may fall into a quagmire of lengthy discussions without taking action.
Another failure mode in this category is lack of information sharing or communication between agents. Sometimes one agent possesses key information but fails to convey it to other agents who need it; or an agent does not understand what others are saying but does not proactively seek clarification. This can lead to severe deviations in team collaboration.
The research provided a thought-provoking example: in a phonebook query task, the supervisor Agent asked the phone Agent to log into the phone application interface using a username and password. The phone Agent checked the documentation and found that the correct username should be the phone number rather than the email, but it did not clearly explain this to the supervisor and still attempted to log in using the incorrect email as the username, resulting in an “invalid credentials” error.
The supervisor Agent also did not inquire about the username format issue, merely retrying. After several rounds of back-and-forth, the task was marked as failed, with the root cause being the lack of effective communication: one agent knew the username was wrong but did not clarify, while the other, not understanding, did not ask.
This case illustrates the asymmetry of context and knowledge between agents: when there is no mechanism to ensure timely information sharing and clarification of doubts, multi-agents can easily operate independently, leading to collaboration failures.

Ultimately, issues of inter-agent inconsistency stem from insufficient collaboration protocols and interaction methods. If the system does not have well-designed communication protocols (e.g., what to do when disagreements or confusion arise), agents lack the means to coordinate actions.
Inefficient communication often means there are no clear decision-making or synchronization mechanisms—everyone may be politely repeating information without anyone pushing the process; while information omissions indicate a lack of checks and confirmations—one agent makes a key discovery but fails to reach a consensus within the team.
Task Verification and Termination Issues
These failures are closely related to when and how to end tasks, including premature termination of execution or lack of sufficient result verification mechanisms, leading to the system lacking assurance of the correctness and completeness of its decisions and outputs. In other words, these issues either involve stopping when they should not or failing to stop when they should, or providing final outputs without proper checks.
| Failure Mode | Brief Description |
| 3.1 Premature Termination | Ending before necessary information exchange is completed or goals are met, resulting in incomplete outcomes or leaving potential issues. |
| 3.2 Missing or Incomplete Verification | Lack of verification mechanisms, or only superficial checks, making it difficult to timely identify potential errors and vulnerabilities. |
| 3.3 Incorrect Verification | Although verification steps are set, the verification methods are flawed, failing to effectively identify or correct obvious issues. |
Some multi-agent systems are designed without dedicated result verification steps, or even if a verifier agent is introduced, it may be ineffective.
For example, ChatDev introduced a “verifier” agent to review code outputs, but the research found its verification method to be very superficial: it merely checked whether the code could compile without actually running the program or verifying functional requirements. In the aforementioned chess game case, the verifier agent did not check for compliance with game rules, resulting in low-level errors such as “accepting illegal move inputs” going undetected.
On the other hand, premature termination of tasks can occur when agents mistakenly believe a task is complete or unachievable, then stop seeking solutions too early.
Statistics and Analysis of Failure Modes
Notably, the research statistics show that the three major categories of failure modes were almost all involved in the analyzed multi-agent systems and were relatively evenly distributed. In other words, no single type of error dominated; issues from each category were common.
Specifically, task design issues accounted for approximately 37.2%, poor agent collaboration accounted for 31.4%, and verification and termination issues also accounted for 31.4%.
This emphasizes a fact: multi-agent systems are products of multi-faceted complexity, and weak links can appear at different levels. Designers cannot focus solely on one aspect (e.g., only preventing AI from making incorrect statements while ignoring that they may not stop), but must consider comprehensively.

The research also found that failure modes are not independent of each other—often one problem triggers a chain reaction involving multiple categories.
For example, ambiguity in specifications (category 1) may lead to agents discussing repeatedly without results (category 2), ultimately resulting in verification being superficial due to lack of clear standards (category 3).
Conversely, poor communication between agents (category 2) may cause certain requirements to be overlooked, leading to verification being unable to capture them because there is no understanding of what to verify (categories 1/3 intertwined).
These phenomena indicate that when diagnosing and solving problems, a holistic view of system behavior is necessary, rather than treating symptoms in isolation.
Finally, the authors emphasize that many failures stem from architectural and organizational defects, rather than simply blaming the limitations of the LLM model itself. Of course, large language models sometimes hallucinate or make mistakes, but researchers speculate that even if the underlying LLM becomes more powerful, these multi-agent failure modes may still exist.
Because if the organizational structure is unreasonable, “no matter how smart individuals are, they will cause problems when placed in it.” They cite organizational theory’s viewpoint: even a team composed of smart people can experience catastrophic failures if the organizational structure has systemic flaws. Therefore, improving the performance of multi-agent systems cannot solely rely on waiting for better foundational models; design-level optimizations are equally critical.
Intervention Experiments and Insights
In response to the identified failure modes, researchers also conducted beneficial attempts to test whether some intuitive improvements could reduce failures. They selected two specific multi-agent systems (AG2 and ChatDev) for case studies and attempted two types of best-effort interventions:
Improving Task and Role Specifications:
By providing clearer task descriptions and role specifications through more refined prompt engineering, they hoped to reduce errors caused by misunderstandings. For example, clearly listing what each agent should and should not do in the prompt increases the certainty of instructions.
Adjusting System Topology
Changing the original single-round or hierarchical (DAG) multi-stage process to a new topology that allows for cyclic feedback between roles, so that important nodes can iterate repeatedly after receiving review or correction suggestions until all issues are confirmed to be properly resolved before termination.
Specifically, in the original implementation of ChatDev, interactions between roles were mostly akin to a top-down assembly line (or with few feedback branches), and once they passed the “designated few steps,” they were assumed to be complete, potentially leading to “ending without adequate verification.” In the new method, the team introduced repeatable review and improvement stages.
Only when the CTO (or a peer-level technical leader) confirms that all reviews and tests have passed will the system truly enter a completion state. If any defects are found during this period, it will return to the previous stage for repair, forming a closed loop.
These interventions did indeed yield some effects. For example, after interventions on ChatDev, the task completion rate increased by about 14%. However, overall, most of the originally identified failure situations still occurred, and some tasks remained unsuccessful.
Moreover, even with this 14% improvement, the absolute performance of ChatDev and AG2 was still low, insufficient to handle real complex applications. This result indicates that simple prompt improvements and process optimizations can only address a small portion of the problems and cannot fundamentally eliminate the inherent defects of multi-agent systems.
To truly significantly enhance reliability, deeper, systemic changes may be required. The next paper we introduce attempts to deconstruct multi-agent systems from the perspectives of agent autonomy and alignment, proposing a comprehensive analytical framework to diagnose agent systems.
02
Structural Map Provided by the Classification Framework
The popular Manus team proposed the core idea of “Less structure, more intelligence,” advocating for reducing structured constraints on AI and relying more on the model’s own intelligence and evolutionary capabilities rather than on complex processes pre-set by humans.
An interesting observation is that they found traditional browsers, as single-user interaction interfaces, often experience conflicts in human-machine control—AI intervention may frequently interrupt users, affecting their experience.
From this, they proposed an enlightening idea: “AI should have its own independent cloud browser.” This idea touches on a core issue in current AI research: agent autonomy and alignment.
How to grant AI agents higher autonomy while ensuring their behavior aligns with human intentions and values? This is precisely the question we will delve into next.
Thorsten Händler proposed a multi-dimensional classification framework (https://arxiv.org/abs/2310.03659) to depict how such systems architecturally balance “autonomy” and “alignment.”
Although this article was published in 2023, some conclusions may be outdated, but this classification framework actually provides a comprehensive “checklist” for agent architecture. When designing new multi-agent systems, we can refer to these dimensions to think about and organize the architecture, ensuring that key elements are fully considered, thus increasing the likelihood of building robust and efficient systems.
Research Methodology
Händler first established autonomy and alignment as the two core analytical dimensions and defined three levels (L0 to L2) for each dimension to represent different degrees of autonomous decision-making capability or adherence to human intentions.
Next, four key architectural viewpoints (task management G, agent composition A, multi-agent collaboration M, context interaction C) were introduced to analyze the internal workings of multi-agent systems. For more precise assessments, these four viewpoints were further refined into 12 specific architectural aspects (such as task decomposition, communication protocol management, etc.).
The core step of the research is to apply the three levels of autonomy and alignment to the 12 architectural aspects based on detailed definitions, rating each aspect individually. Ultimately, through the multi-dimensional evaluation results of these specific aspects, the research can conduct in-depth analysis and classification of the architectural characteristics and balancing strategies of different systems.
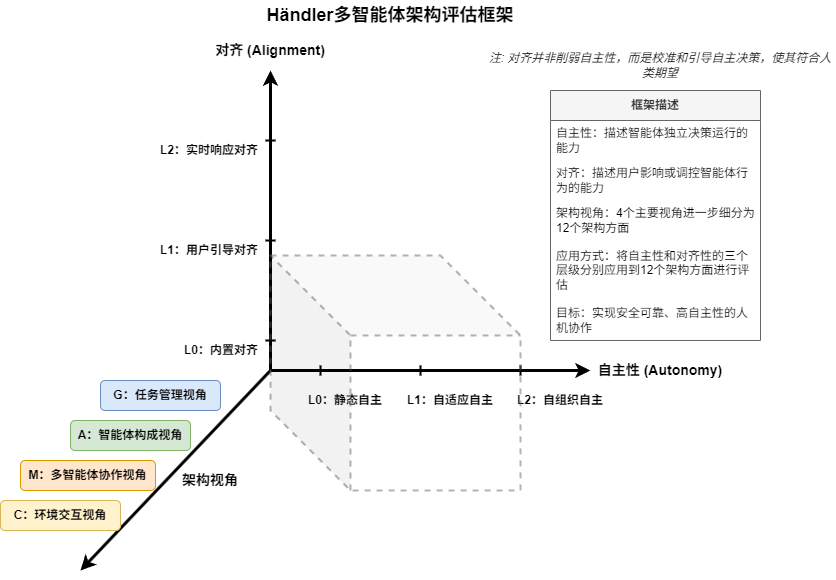
Specifically, the framework can be understood as a three-dimensional coordinate system, where:
-
The autonomy dimension (X-axis) divides the levels of autonomous decision-making of agents;
-
The alignment dimension (Y-axis) divides the levels of human user influence on system behavior;
-
The architectural viewpoint dimension (Z-axis) encompasses the four key perspectives of system architecture.
By combining these three dimensions, the researchers constructed a classification matrix for analyzing and comparing the architectural characteristics of different multi-agent systems.
Levels of Autonomy
Autonomy describes the ability of agents to operate independently in decision-making, divided into three levels:
-
L0: Static Autonomy – Completely reliant on preset rules, fixed behavior, and no flexibility.
-
L1: Adaptive Autonomy – Can adjust behavior within a preset framework to meet demands.
-
L2: Self-Organizing Autonomy – The highest level, capable of actively learning, adjusting in real-time, and even modifying its own processes to dynamically adapt to the environment.
Levels of Alignment
Alignment describes the degree to which users influence or regulate agent behavior, also divided into three levels:
-
L0: Built-in Alignment – The alignment mechanism is fixed by the designer, and users cannot change it during operation.
-
L1: User-Guided Alignment – Users can set parameters or preferences before operation to guide agent behavior.
-
L2: Real-Time Responsive Alignment – The system can accept user feedback during operation and adjust instantly, achieving dynamic human-machine collaboration.
In this framework, autonomy and alignment are complementary. Alignment does not aim to weaken autonomy but to calibrate and guide autonomous decision-making to better align with human expectations, with the goal of achieving safe, reliable, and highly autonomous human-machine collaboration.
The third dimension is the architectural viewpoint. The research draws on the “4+1 view model” from software architecture, selecting four perspectives closely related to LLM multi-agent systems:
-
Task Management View (Functional View): How the system decomposes, executes, and integrates tasks to achieve goals.
-
Agent Composition View (Development View): The types, roles, organization, and memory mechanisms of agents within the system.
-
Multi-Agent Collaboration View (Process View): The interaction methods, communication protocols, and collaboration patterns among agents.
-
Context Interaction View (Physical View): How the system interacts with external tools, data, and models.
These four architectural viewpoints are refined into 12 specific aspects, serving as the basic units for assessing autonomy and alignment.
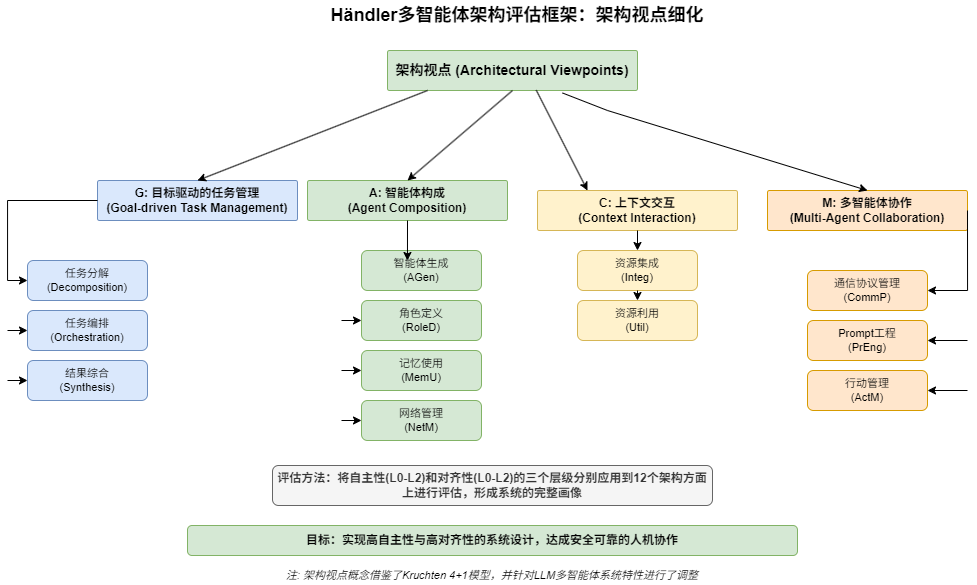
Overall, these four perspectives cover the main aspects of multi-agent systems from requirements to implementation, from internal to external. The classification framework maps different levels of autonomy and alignment to the specific architectural elements under these perspectives, allowing for detailed assessment of a system’s balance between autonomous decision-making and human control in each aspect.
For example, under the “task management” perspective, we can assess whether the system autonomously completes task decomposition (L2) or relies on fixed templates (L0), and whether user intervention is allowed in result integration (L1 or L2 alignment), etc. In this way, each system can draw a radar chart of “autonomy-alignment,” showing its configuration across various aspects.
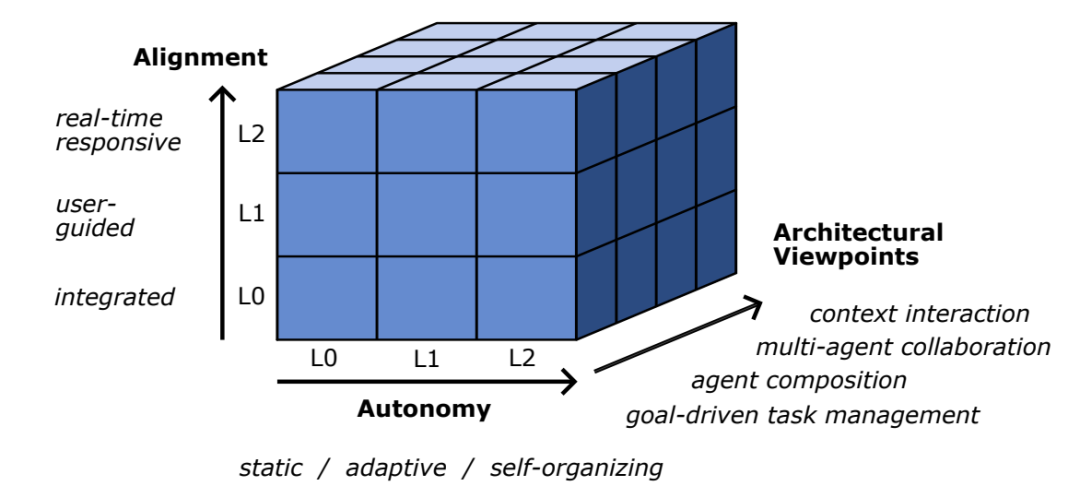
Händler also detailed the L0, L1, L2 level standards for autonomy and alignment concerning the 12 architectural aspects in the appendix for your reference.
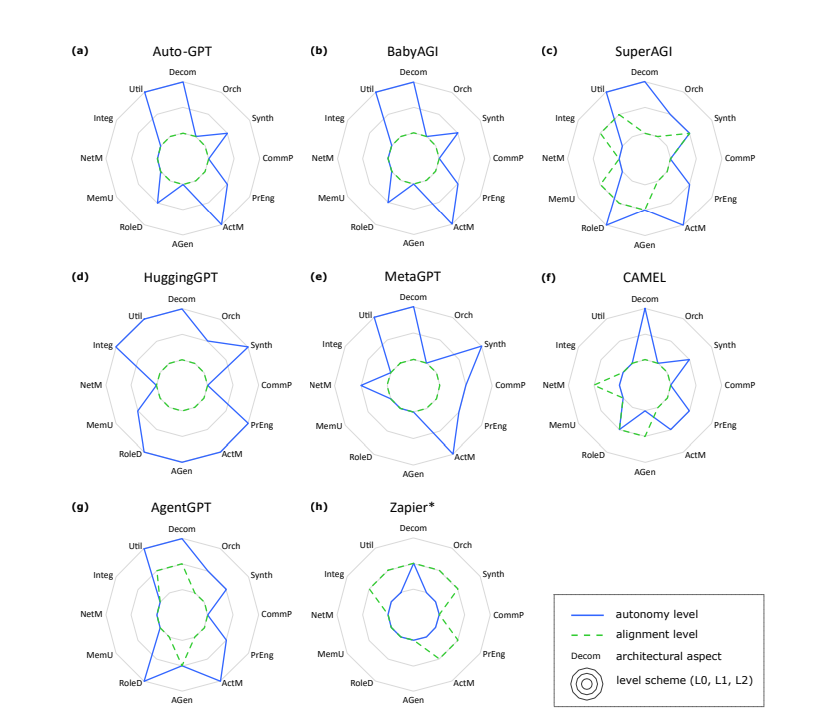
The researchers applied this framework to empirically evaluate representative systems such as Auto-GPT, BabyAGI, HuggingGPT, and MetaGPT. By analyzing the autonomy (AU) and alignment (AL) configurations of each system across the 12 architectural aspects, the research summarized several mainstream design patterns or categories of multi-agent systems.
For example, general systems emphasizing universal automation but rigid interactions (Auto-GPT, BabyAGI, SuperAGI, AgentGPT), centrally controlled systems relying on a central “brain” for coordination (HuggingGPT), and role-based intelligent agent systems simulating team collaboration and role-playing capabilities (MetaGPT, CAMEL).
These analyses reveal common characteristics and potential limitations in current system designs, particularly the generally insufficient real-time user participation (low alignment levels) and the phenomenon of “uneven” autonomy levels across different architectural aspects (some aspects highly autonomous, while others are very constrained).
03
Appendix
Table G: Level Standards for Goal-driven Task Management(Covers aspects: Task Decomposition, Task Orchestration, Result Integration)
| Level | Autonomy Standards | Alignment Standards |
| L0 | Static: Task management activities (decomposition, distribution, orchestration, integration) follow scripted processes and automated mechanisms, based on predefined rules and options. Includes strict processes or execution chains without variants. | Integrated: Information and constraints regarding task management mechanisms (such as decomposition depth, consensus options) are embedded in the system design, and users cannot change them. |
| L1 | Adaptive: The system provides predefined but adaptable procedures. LLM agents have some autonomy to adjust task management processes (such as managing decomposition, distribution, and integration decisions) within a given framework. May reuse patterns or prepared mechanisms. | User-Guided: Users can configure information and constraints related to task management before operation. |
| L2 | Self-Organizing: LLM agents can architect and implement their strategies to deconstruct and solve problems. May utilize advanced general frameworks, but agents can effectively self-organize all stages of task management. | Real-Time Responsive: Information and constraints related to task management can be adjusted during operation, responding to user feedback or changes. |
Table M: Level Standards for Multi-Agent Collaboration(Covers aspects: Communication Protocol Management, Prompt Engineering, Action Management)
| Level | Autonomy Standards | Alignment Standards |
| L0 | Static: Collaborative actions and interactions follow a fixed script or rule set. Communication protocols, prompt usage/enhancements, and action management are predefined and not dynamically adjusted. Agents collaborate based on strictly established, non-adjustable guidelines. Very little variability in the collaboration process. | Integrated: Information and constraints regarding collaboration mechanisms/patterns, prompt templates/enhancements, and action execution preferences are embedded in the system design. |
| L1 | Adaptive: Collaboration aspects (protocols, templates, action management) have adaptability based on predefined mechanisms. LLM agents can autonomously choose and adjust these mechanisms according to situational needs. May reuse prepared mechanisms or patterns. | User-Guided: Users can configure information and constraints related to collaboration before operation. |
| L2 | Self-Organizing: Agents can independently formulate their collaboration strategies. Depending on the goals and task complexity, they proactively plan and execute the most suitable collaboration strategies. Can self-organize collaboration protocols, prompt engineering mechanisms, and negotiate action execution. | Real-Time Responsive: Information and constraints related to collaboration can be adjusted in real-time during operation. |
Table A: Level Standards for Agent Composition(Covers aspects: Agent Generation, Role Definition, Memory Usage, Network Management)
| Level | Autonomy Standards | Alignment Standards |
| L0 | Static: The composition and structure of agents are predefined and rule-driven. Rules govern the creation of agents, type selection, role and capability definitions. Memory usage and network relationships follow predefined mechanisms. | Integrated: Information and constraints regarding agent creation, types, roles, capabilities, interrelations, and network structures are deeply embedded in the system design. |
| L1 | Adaptive: Allows for some flexibility within a predefined structure. LLM agents can adjust their composition and structure (such as replicating instances, modifying capabilities/roles/memory attributes, modifying/extending relationships). | User-Guided: Users can configure information and constraints related to agent composition before operation. |
| L2 | Self-Organizing: Agents can autonomously define and generate types and establish collaborative networks. The drive comes from a profound understanding of situational needs and nuances. They dynamically compose and organize based on real-time demands, not adhering to predefined types/roles/relationships. | Real-Time Responsive: Information and constraints related to agent composition can be dynamically adjusted during system operation. |
Table C: Level Standards for Context Interaction(Covers aspects: Resource Integration, Resource Utilization)
| Level | Autonomy Standards | Alignment Standards |
| L0 | Static: Context resources (data, tools, models) are strictly integrated based on the system’s initial design. Utilization is organized by predefined rules and patterns. Includes cases where resources are unavailable. | Integrated: Information and constraints regarding resource integration and application (such as which resources to use, how to integrate them, usage restrictions) are built into the system design. |
| L1 | Adaptive: Some resources are pre-integrated, and the system provides adaptive mechanisms for agents to integrate missing resources (such as prepared API access). Agents flexibly decide how to utilize and combine provided resources based on predefined mechanisms. | User-Guided: Users can modify information and constraints related to resource integration and application before operation. |
| L2 | Self-Organizing: Agents have the autonomy to interact with a diverse pool of contextual resources. They can discerningly select, integrate, and utilize these resources based on goals and challenges. | Real-Time Responsive: Information and constraints related to resource integration and application can be adjusted in real-time. |
END
Click the card below to follow us immediately