By / China International Capital Corporation Information Technology Department Zhang Jing, Zhang Li, Lu Fei, Shi Peixuan
The rapid development of financial technology has led China International Capital Corporation (CICC) to adapt accordingly, gradually moving its business systems to the cloud. However, moving to the cloud has increased the complexity of IT infrastructure and business systems, intertwining unpredictable user behaviors and events, which raises higher demands for the reliability of system and application architecture. To address this, CICC has built an application resilience management chaos engineering platform called Wukong based on the principles of chaos engineering and the characteristics of the Cang Qiong cloud environment. This platform conducts chaos experiments in the cloud environment and regular fault drills, actively fixing issues discovered through chaos experiments, steadily enhancing the system’s immunity to failures in the cloud environment, and achieving intrinsic stability and security of cloud systems.

China International Capital Corporation
Information Technology Department Zhang Jing
New Situation: Uncertainty Brought by the “Digital Financial Era”
In the era of Internet finance, financial products and service models are continuously innovating, and transaction volumes have surged significantly. Facing the new development situation of Internet finance, the disadvantages of traditional monolithic IT architectures have become increasingly apparent. To achieve digital transformation goals, the industry widely applies new technologies such as cloud computing and distributed systems to build distributed architectures and operational systems to support the rapid development of financial business.
1. Increased Stability Requirements for Transaction Systems. Modern securities trading activities are frequent, with high transaction concurrency, significant capital involvement, and concentrated trading periods, which require extremely high processing timeliness. Therefore, securities companies have very strict requirements for the availability and response rates of trading systems. To maintain customer satisfaction at an acceptable level, the operations and maintenance team must strictly adhere to regulatory requirements and fully monitor the operational status of business applications to respond to various anomalies or interruptions.
2. Enhanced IT Application Capabilities Required.Innovative developments in digital technologies represented by artificial intelligence, blockchain, cloud computing, and big data have introduced new industry elements, service formats, and business models to the securities industry, while also putting new pressure on operations and maintenance teams. In response, the operations and maintenance team must continuously learn new knowledge, master new skills, and face new scenarios, constantly conducting various validations, upgrades, and migrations to avoid operational errors that could lead to abnormal external services of the system.
3. Heightened Regulatory Requirements.The securities industry in China is currently in a phase of digital transformation, facing significant opportunities for development. Securities companies need to continuously provide diversified and differentiated financial products to cope with intensifying competition. The industry is transforming the entire process of investment, trading, and risk control through digital technology, shifting the focus of IT investment to strengthening the deep application of modern technology in areas such as investment, consulting, products, compliance, risk control, and credit. Comprehensive digitization of business means more application systems need to be invested in, creating more complex data logic and maintaining higher system security and stability requirements. In response, operations and maintenance teams must adopt updated operational philosophies, increase IT investments, and build new operational capabilities to meet the challenges brought about by digital transformation.
CICC’s application resilience management chaos engineering platform, Wukong, achieves intrinsic stability in cloud systems, effectively helping to solve problems such as difficulty in locating the root causes of production incidents, insufficient coverage of non-functional testing, unpredictable risks in the vertical structure of business systems, challenges in validating emergency capabilities, and doubts about the availability of global business networks.
New Direction: Construction of the “Wukong” Application Resilience Management Chaos Engineering Platform
CICC’s application resilience management chaos engineering platform adopts containerized packaging, forming code and component reuse based on containers, improving overall development levels and simplifying platform maintenance. The platform is divided into multiple system services (microservices), mainly including data end, service end, NoSQL end, data end, Agent end, configuration end, application end, collection end, authentication end, registration end, gateway end, client end, etc.
Referring to the standards in the China Academy of Information and Communications Technology’s “Guidelines for Building Stability in Distributed Systems” and “Tiered Capability Requirements for Chaos Engineering Platforms,” and based on the requirements of the “Three-Year Plan for Enhancing Network and Information Security in Securities Companies (2023-2025),” CICC actively employs chaos engineering to carry out and implement work. The application resilience management chaos engineering platform built is based on a four-layer design, as shown in Figure 1.
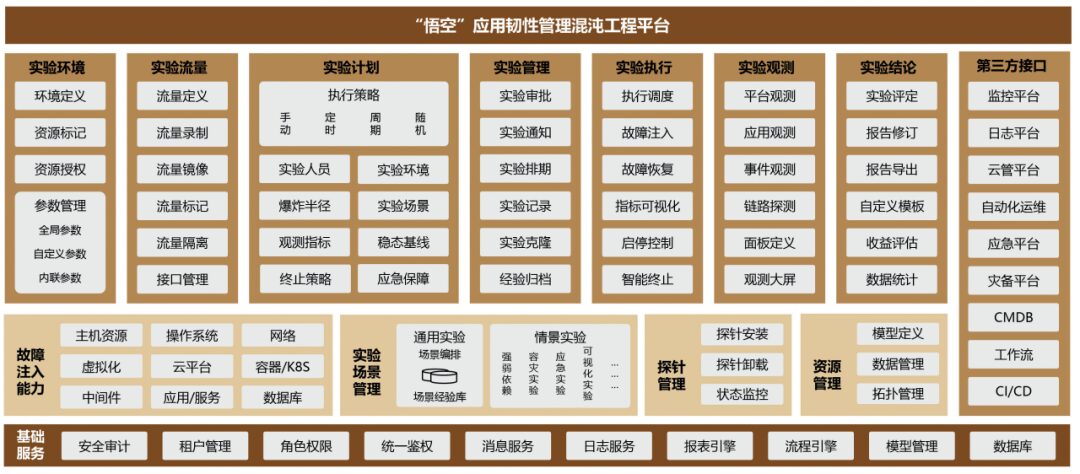
Figure 1: Architecture of the “Wukong” Application Resilience Management Chaos Engineering Platform
Basic Service Layer: Supported by the infrastructure and hardware resources of IDC and Cang Qiong Cloud; extracting a series of public business capabilities to form the architectural base of the chaos engineering management platform, providing unified authentication, multi-tenancy, authorization mechanisms, security audits, and a series of service centers and other general capabilities.
Core Service Layer: Centered on fault injection capabilities, forming the core service layer of the platform, which includes core atomic fault injection capabilities, experimental scenario management, experimental probe management, and experimental resource management. The platform is based on multiple coexisting architectures, compatible with virtual machines, containers, physical machines, and self-controlled servers, achieving unified packaging, focusing on the content of fault implementation while ignoring underlying differences.
Experimental Management Layer: Includes experimental management, experimental observation, and traffic management, supporting the large-scale and standardized promotion of chaos engineering, enhancing the value of the chaos engineering platform. Experimental management includes management of experimental plans, experimental environments, experimental results, etc.; the experimental observation part provides visualization of the entire process of chaos experiments; traffic management supports traffic injection of chaos engineering in various environments.
Third-Party Integration Layer: The application resilience management chaos engineering platform provides various standard open interfaces, planning to integrate with CMDB, Cang Qiong Cloud management platform, monitoring platform, CI/CD, and other internal systems, currently mainly applied in the operations and maintenance system.
New Exploration: Achieving Intrinsic Stability of Cloud Systems Through Chaos Engineering
CICC uses Cang Qiong Cloud as the experimental object for chaos engineering, conducting chaos experiments from the dimensions of application vertical structure and lifecycle. Cang Qiong Cloud is a globally deployed cloud platform, as shown in Figure 2, managing domestic and international infrastructure resources, mainly involving computing power, storage, networks, databases, middleware, etc., providing the full-stack infrastructure capabilities required for business cloud migration to data centers in Beijing, Shanghai, Shenzhen, Hong Kong, and other locations.
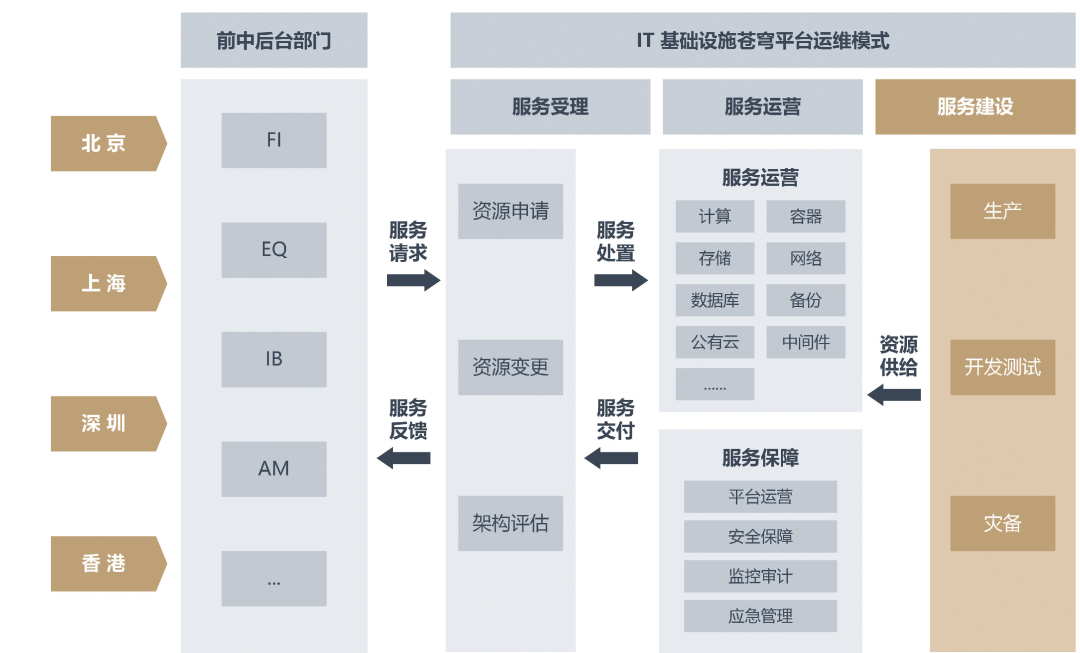
Figure 2: CICC Cang Qiong Architecture Diagram
Through the construction of Cang Qiong Cloud, CICC has fully realized the process-oriented management of cloud resources, ensuring T+0 delivery of resources through automation, greatly enhancing the launch speed of both cloud-native and traditional projects. Cang Qiong Cloud provides infrastructure resources for departmental business systems, effectively supporting agile delivery and stable operation of business systems.
1. Practical Scenario: Comprehensive Assessment of Business System Vertical Structure.The stability of business systems providing services externally depends on stable hosts and network devices, host systems, Cang Qiong Cloud foundations, cloud resource pools, instances, and cloud services. Moving applications to the cloud raises higher stability requirements; any component anomaly poses a risk to the stable operation of business systems and can even have significant impacts.
CICC, based on the Wukong platform, starts from the business system and conducts layered analysis through the vertical structure, performing chaos experiments on ARM and x86 device layers, operating system layers, cloud foundations and resource layers, cloud service instance layers, and cloud service combination layers for comprehensive assessments. As shown in Figure 3-a, the business system vertical assessment module analyzes both the physical architecture and technical architecture of the business system throughout the entire process, from experimental design, steady-state index definition, experimental environment preparation, experimental implementation, to experimental report confirmation, strictly controlling experimental details to ensure experimental quality.
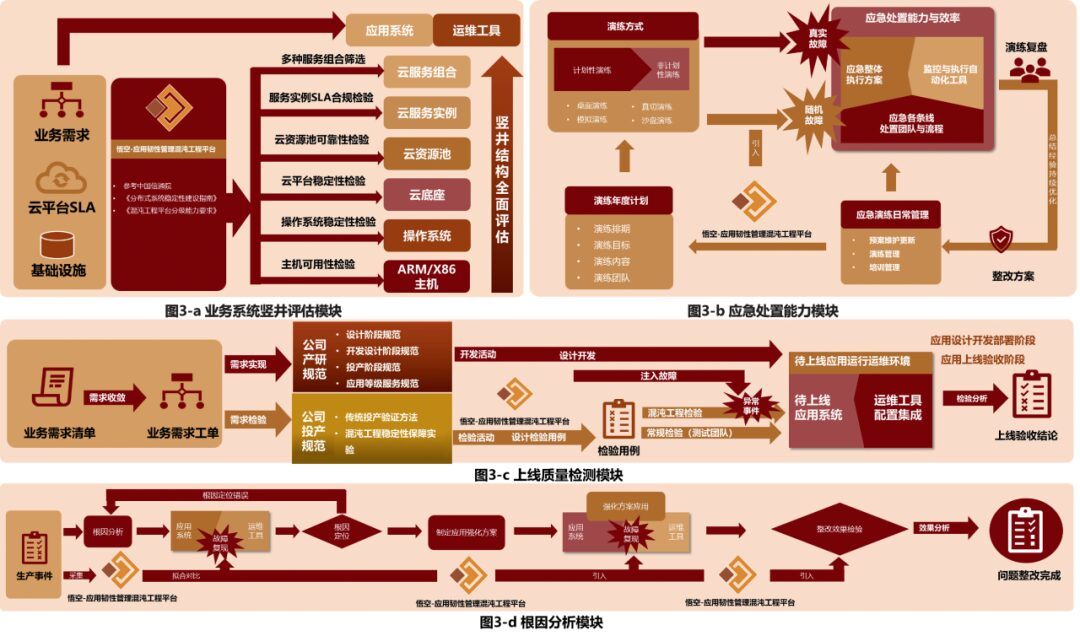
Figure 3: Chaos Experiment Practical Scenario Diagram
2. Practical Scenario: Emergency Drill for Real Events to Test Emergency Response Capabilities.Based on the preset fault scenarios in the emergency drill plan, chaos engineering automatically injects real faults during drills to test the monitoring system’s detection capabilities. At the same time, the emergency team responds quickly, completing emergency response according to the emergency plan, testing the emergency team’s handling capabilities and the availability of the plan, as shown in Figure 3-b for the emergency response capability module.
Each business platform can customize drill plans, relying on the chaos engineering platform for both planned and unplanned drills to test the emergency response capabilities and problem detection capabilities of development and operations teams, validate the overall execution plans for emergencies, and the coverage of monitoring, verifying the emergency response processes of various teams. Additionally, based on the scenario design of the chaos engineering platform, regular emergency drill plans can be scheduled to automate the drill cycle, recording the application operational status during the drill process and generating summary reports to form a positive feedback mechanism.
3. Practical Scenario: Quality Inspection of Business System Launch.From the perspective of business requirements, business launch activities based on the CI/CD pipeline are divided into development and inspection phases. Developers complete the application design and development process in accordance with CICC’s development specifications, while inspectors use traditional inspection and chaos engineering quality inspection methods to design inspection cases for functional and non-functional validation, allowing the application to enter the pre-launch stage.
Chaos engineering’s non-functional inspection activities design chaos experiments based on the system’s deployment architecture, as shown in Figure 3-c for the launch quality inspection module. Before the business system launch in the CI/CD pipeline, a chaos engineering quality inspection node is added, where the chaos engineering platform detects pending tasks in the CI/CD. The chaos experiment determines fault factors and detection content for each component of the system to be launched, completing non-functional testing such as high availability, elasticity, and self-healing, and evaluating the application to be launched, issuing stability reports, highlighting risk points, and providing optimization suggestions to achieve quality inspection before launch.
4. Practical Scenario: Fault Reproduction to Assist in Locating Root Causes and Optimizing Emergency Plans.When real fault production events occur, the operations and maintenance team prioritizes quickly restoring business. However, handling production events with the goal of rapid recovery can make it difficult to locate the root causes of many event issues. By integrating the chaos engineering platform with monitoring systems and automated operations systems, root cause analysis can be conducted after fault handling is completed, as shown in Figure 3-d for the root cause analysis module.
Root cause analysis uses the fault injection capabilities of the chaos experiment platform, reproducing production faults in a test environment to provide the environment and possibilities for locating the root causes of production faults. The operations and maintenance team submits problem tickets and designs chaos experiments based on observed phenomena. By controlling the minimum explosion radius and conducting repeated experiments, the problem range is gradually narrowed to confirm the issue, designing repair and reinforcement plans and confirming whether the problem resolution is complete through chaos experiments, thus addressing root causes and enabling rapid verification of similar issues in the production environment, improving application stability.
New Experience: Gaining Insights from Chaos Engineering Practices
Through various scenario-based experiments on the chaos engineering platform, CICC’s chaos engineering project team has gained rich experiences.
Enhancing Team Confidence in Stability: By defining chaos experiments through FMEA (Failure Mode and Effects Analysis), identifying fault severity based on dimensions such as severity and frequency, and verifying the stability of business systems in ARM and x86 hybrid architectures based on FMEA recommendations.
Assisting in Locating Root Causes for Production Fault Reproduction: Using cosine similarity algorithms to compare the similarity between original indicator images and reproduced indicator images, determining the relevance of fault reproduction experiments to faults occurring in the production environment while limiting the explosion radius of fault reproduction experiments to ensure that reproduction calculations are not affected by other factors, completing root cause positioning for production fault reproduction.
Practical Emergency Validation of Emergency Response Capabilities: Based on the fault injection capabilities of chaos engineering, inducing system anomalies to verify the effectiveness and accuracy of the monitoring alarm platform in fault collection, generating real event alarms, validating the emergency team’s response capabilities and the execution effectiveness of the plan, effectively improving emergency work efficiency and identifying hidden dangers in emergency work.
Quality Gate for Launch, Effectively Enhancing System Availability: Integrating into the CI/CD pipeline, adding quality inspection nodes during testing and production phases, batch automating the execution of required fault scenarios for inspection, identifying quality risks during the production phase, and effectively reducing events caused by non-functional issues after system launch.
Validating the Availability of Business System Vertical Structures: The availability of business systems is a comprehensive value of availability from physical devices to applications. Any component failure at each level can have unpredictable impacts on the availability of business systems. Through comprehensive assessments of the vertical structure of business systems, the degree and scope of fault impacts on business systems are transformed from unknown to known.
Global Business Availability Verification: The availability of global businesses mainly relies on the interconnection of networks among multiple IDCs globally, making network availability a key factor for IDC availability and business availability. By detecting risks such as network high availability, latency, and flash interruptions, configuration adjustments and repairs are made for identified issues, enhancing network availability.
Through the summary of practical explorations, CICC’s chaos engineering project successfully received the second “Excellent Case of Stable and Secure Operation of Cloud Systems” award from the China Academy of Information and Communications Technology Stability Assurance Laboratory, providing valuable experience references for the industry’s chaos engineering applications.
Looking Ahead: Expanding the Scope of Chaos Engineering Practices
Currently, application system architecture is transitioning from monolithic applications to cloud-native applications, and traditional operations and maintenance face challenges from two different system architectures, requiring different approaches to complete increasingly heavy operational work. Continuously verifying the effectiveness of stability assurance plans through the chaos engineering platform allows most threats and risks to be mitigated through the system’s own capabilities, thereby reducing maintenance pressure during system operation and enhancing the system’s continuous service delivery capabilities, ensuring the sustained operation of business activities is a practical method.
At present, the system analysis and scenario design before chaos experiments require a high level of professional knowledge, necessitating the participation of specialized chaos experiment experts. In the future, CICC’s chaos engineering plan aims to provide built-in experimental scenario templates for different components and services, offering health check services for application operators to facilitate the large-scale promotion and use of chaos engineering.
(This article was published in the “Financial Electronics” March 2024 issue)









New Media Center
Director / Kuang Yuan
Editor / Yao Liangyu Fu Tiantian Zhang Jun Tai Siqi
