
Director of the Financial Technology Committee of Zhongtai Securities Co., Ltd.
and General Manager of Technology R&D Department, He Bo
Background Analysis
With the rapid development of the financial industry, the demand for business is constantly increasing, and the speed of product iteration is accelerating, leading to larger system scales. The traditional monolithic architecture model can no longer meet the current business development needs of the financial industry, and distributed microservice architecture is increasingly being applied in the financial sector. Compared to traditional software architectures, the more complex deployment structure of microservices faces more threats of failure, and symptoms of microservice system failures are also more diverse. At the same time, due to the financial industry’s involvement in a large number of fund transactions, the systems will cover many complex infrastructures such as multiple data centers, active-active setups, disaster recovery, containers, and virtual machines, making inter-system interactions particularly complex and increasing the uncertainty of system operations.
The existing stability assurance measures focus on how to prevent the introduction of known system defects, lacking means to identify and repair faults that require specific external disturbances to trigger, and can only respond passively when system failures occur, leading to uncontrolled progress and costs in fault response.
Introduction to Chaos Engineering
Chaos engineering is a discipline that conducts experiments on distributed systems, first proposed in August 2008 by Netflix. In 2012, Chaos Monkey was open-sourced in the Simian Army project, making Simian Army the first open-source chaos engineering toolset, laying the foundation for the development of chaos engineering tools. In 2015, Netflix officially released the “Principles of Chaos Engineering,” which mainly introduced the purpose, significance, and methodology of chaos engineering experiments. In 2016, the chaos engineering commercial company Gremlin was established, marking the commercialization of chaos engineering. Since 2019, domestic enterprises have begun to introduce and practice chaos engineering.
Chaos engineering aims to enhance system fault tolerance and build confidence in the system’s ability to withstand unpredictable issues in production environments; it seeks to identify failures before they cause interruptions. By actively injecting disturbances that may trigger failures into the system, it explores the system’s capacity to withstand disturbances, tests system behavior under various pressures, identifies and repairs faults, and avoids severe consequences. Chaos engineering is a complex technical means to improve the resilience of technical architecture, ensuring system availability through experimentation. This empirical validation method can evidently create more resilient systems while allowing us to gain a deeper understanding of various behavioral patterns during system operation, thereby building confidence in operating highly available distributed systems while continuously creating more resilient systems.
Based on this, Zhongtai Securities has launched a pilot application of chaos engineering, selecting the internet finance business system, which has high business demand, as the pilot. By targeting system layer, application layer, and infrastructure layer, they injected business-level and architecture-level faults, successfully identifying issues such as excessive timeout and sub-health nodes, significantly improving the company’s system stability and financial technology level.
Construction Method
Based on the principle of “step-by-step implementation and graded improvement,” the company gradually promotes the implementation of chaos engineering in a “pilot first, then promote; key areas first, then comprehensive” manner. The internet finance business system of Zhongtai Securities consists of three major systems: retail business capability system, financial product system, and comprehensive financial service system, designed to meet the growing investment and financing needs of customers. The architecture of the internet finance system platform is divided into internet access layer, business service layer, basic service layer, and environment deployment layer. The business service layer includes specific businesses such as user center, market center, information center, trading middle office, wealth management middle office, business handling, investment advisory middle office, and value-added tools. The system architecture adopts the Spring Cloud microservice framework, combined with high-performance, low-cost distributed middleware such as caching, distributed storage, search engines, and message queues, as well as basic services provided by data collection, real-time data computation, and log centers to construct the overall architecture of the business system.
As an important business system for the company, the internet finance system needs to meet the high availability standards required by the financial industry, achieving high availability SLA guarantees and multi-region, multi-center high availability support. To further improve the system stability assurance system, Zhongtai Securities decided to explore and practice the stability of the internet finance system based on the principles of chaos engineering.
Currently, we have formulated a construction plan for chaos engineering experiments in the internet finance business line, as detailed below.
1. Construction Plan for Chaos Engineering Simulation Environment
First, it is necessary to build a simulation environment for the internet finance system, which should be constructed 1:1 based on the production environment deployment architecture. The architecture of Zhongtai Securities’ internet system is shown in Figure 1.
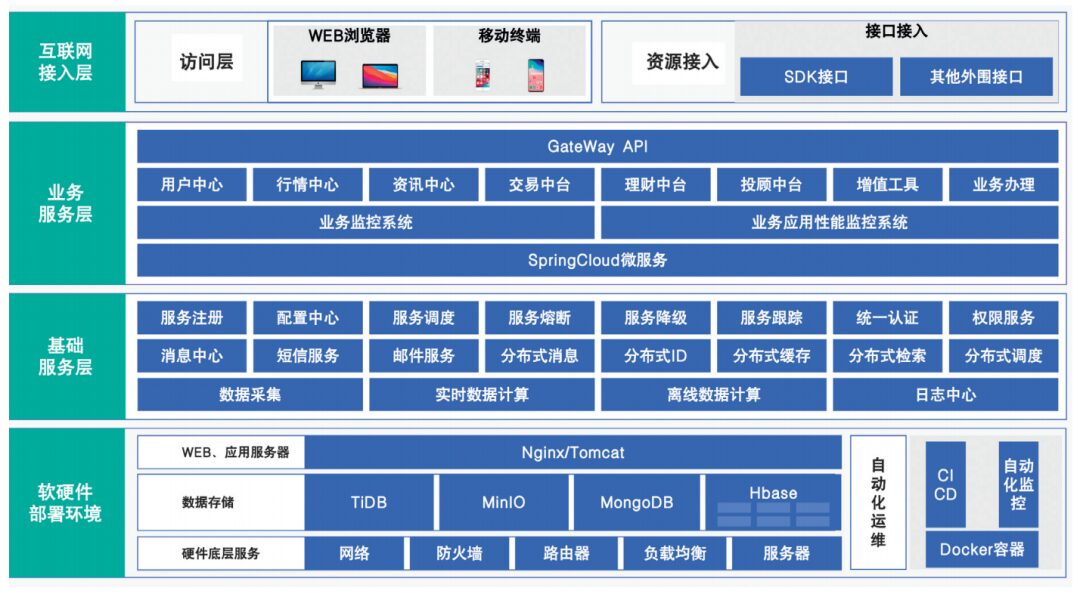
Figure 1 Architecture of Zhongtai Securities Internet System
2. Deployment Plan for Chaos Engineering Monitoring System and Monitoring Indicators
The deployment of the monitoring system is based on a hybrid cloud deployment environment, monitoring business applications, basic services, and infrastructure such as SaaS, PaaS, and IaaS from top to bottom. The main components of the application state monitoring system include: Exporter, Prometheus, Alertmanager, and Grafana. Additionally, to better monitor the application and architecture status during the exercise process, link monitoring and performance monitoring systems have also been introduced. Data collectors from various Exporters will collect monitoring indicator data for server basic resources, database cluster monitoring indicators, middleware cluster monitoring indicators, application service monitoring indicators, etc. The specifics include the following:
(1) Business applications: mainly include service availability monitoring (whether services and ports exist, whether they are deadlocked) and application performance monitoring (application processing capabilities, such as transaction volume, success rate, failure rate, response rate, and time taken).
(2) Basic service layer: includes performance indicators of various middleware, Docker containers, and cloud-native platforms.
(3) Infrastructure layer: monitors the performance of basic resources, including CPU (CPU usage rate, per-core usage rate, CPU load), memory (application memory, overall memory, etc.), disk IO (read/write speed, IOPS, average wait time, average service delay, etc.), network IO (traffic, packet count, error packets, packet loss), connections (number of TCP connections in various states, etc.).
3. Construction Plan for Chaos Engineering Platform
The chaos engineering platform is generally divided into five layers: upper-layer business, platform modules, task scheduling, lower-layer capabilities, and infrastructure. The bottom layer consists of the infrastructure deployed by the company, including containers, virtual machines, physical machines, and other non-standard servers. Ultimately, the chaos engineering fault injection medium will be installed on these infrastructures to implement various fault injections.
The platform should mainly include functions such as environment management, application management, probe management, exercise planning, observability of exercises, risk scenario libraries, and exercise report notifications (as shown in Figure 2).
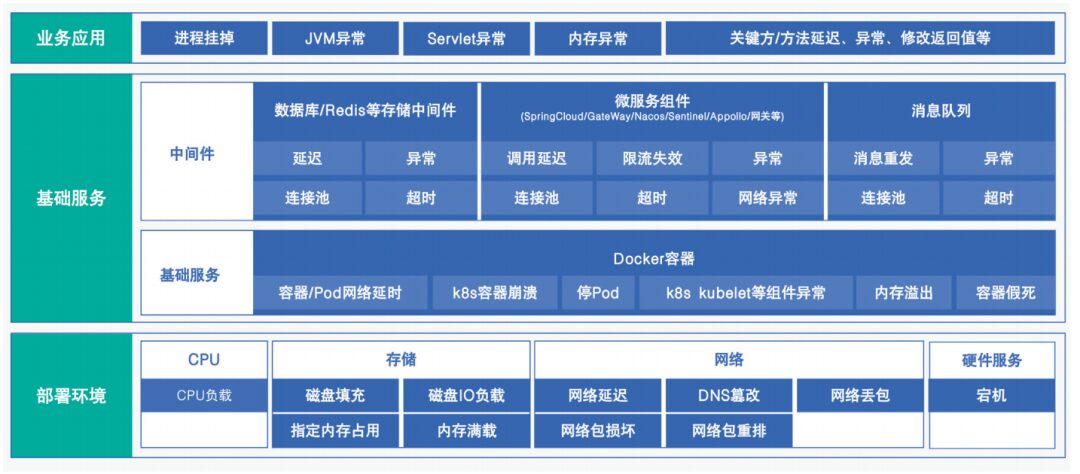
Figure 2 Exercise Indicator System
(1) Environment management: supports installation on virtual machines, physical machines, or cloud servers; supports cluster mode deployment, including virtual machine clusters and container clusters; supports cloud-native deployment, including cloud servers in cross-cloud and internal multi-cloud configurations; supports server types such as ARM/X86 server architectures; supports Linux operating systems.
(2) Application management: supports integration with Nacos and Zookeeper registration centers to achieve automatic application awareness; supports port matching, automatically matching instances perceived by probes based on configured application ports; supports manual configuration of IP and port numbers.
(3) Probe management: install probes on the tested cluster or machine to receive commands sent by the chaos engineering platform server for fault injection.
(4) Exercise planning: the built-in exercise process is fault injection → duration → recovery. Exercises can be organized by customizing configurations for nodes, with the ability to add, edit, or delete nodes. It supports serial and parallel scene orchestration; supports process reuse; each node supports retrying, skipping, and termination.
(5) Observability of exercises: can be integrated with third-party monitoring tools to achieve observability of exercise indicators.
(6) Risk scenario library: supports custom configuration of scenario library classifications, such as basic resource scenario library, traffic overload scenario library, etc.; supports setting specific expert scenarios, including basic information, configuration parameters, configuration processes, and observation indicators.
(7) Exercise reports: supports custom configuration of exercise reports, including filtering by exercise time, exercise type, application, instance, etc.
4. Standardization and Automation of Chaos Engineering Experiments
By abstracting the common steps of project exercises, standardization of specific scenario exercise processes can be achieved, which is beneficial for accumulating standardized exercise scenarios and fault handling processes, empowering other businesses to conduct experiments quickly and reducing exercise costs. At the same time, the automation of chaos engineering covers a wider range of experimental sets.
Practice System and Experience
Through the implementation of this chaos engineering system, Zhongtai Securities has built a chaos engineering system capable of conducting exercises in a hybrid cloud environment (as shown in Figure 3). It has achieved refined management of reliability testing and established a continuous improvement mechanism based on monthly cycles for training, communication, and summarization.
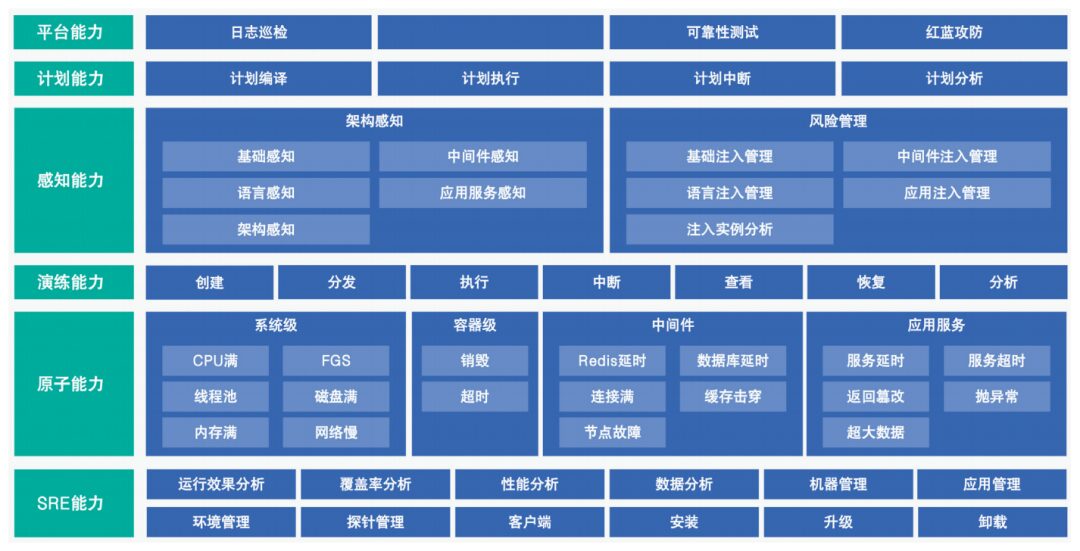
Figure 3 Exercise Platform Capability Construction
This practice involved simulating call delays, service unavailability, full machine resources, etc., to observe whether the nodes or instances experiencing failures were automatically isolated or taken offline, whether traffic scheduling was correct, and whether contingency plans were effective, while also observing whether the overall QPS or RT of the system was affected. Additionally, to better observe the exercise process, establishing an observability system is also very important.
Through a layered monitoring system, rapid response and notification of alarms during the exercise process can be achieved, helping participants quickly locate faults. Based on the improvement of exercise capabilities and the observability system, the range of fault nodes is gradually increased to verify whether upstream service flow limiting, degradation, and circuit breaking are effective. Ultimately, the fault nodes increase to the point of request service timeouts, estimating the system’s fault tolerance threshold, and measuring the system’s fault tolerance capability; simulating upper-layer resource loads to verify the effectiveness of the scheduling system; simulating the unavailability of dependent distributed storage to verify the system’s fault tolerance capability; simulating the unavailability of scheduling nodes to test whether scheduling tasks automatically migrate to available nodes; simulating primary and backup node failures to test whether primary and backup switching is normal; validating whether monitoring indicators are accurate, whether monitoring dimensions are complete, whether alarm thresholds are reasonable, whether alarms are prompt, and whether the recipients of alarms are correct; checking whether notification channels are available, etc., to improve the accuracy and timeliness of monitoring alarms; through fault assaults, randomly injecting faults into the system to examine the emergency response capabilities of relevant personnel and whether the problem reporting and handling processes are reasonable, achieving a battle-tested approach to training personnel in locating and resolving issues.
In terms of team building, Zhongtai Securities has prioritized forming a management team led by reliability testing leaders from various departments and personnel responsible for maintaining the fault exercise platform, responsible for organizing tool promotion, test design, and implementation work, and has formed a special implementation team involving application architects, testers, developers, and operations personnel for specific implementations. To ensure the better advancement of the practice system, a red-blue attack-defense system has been introduced, and a GameDay culture has been established among teams (as shown in Figure 4).
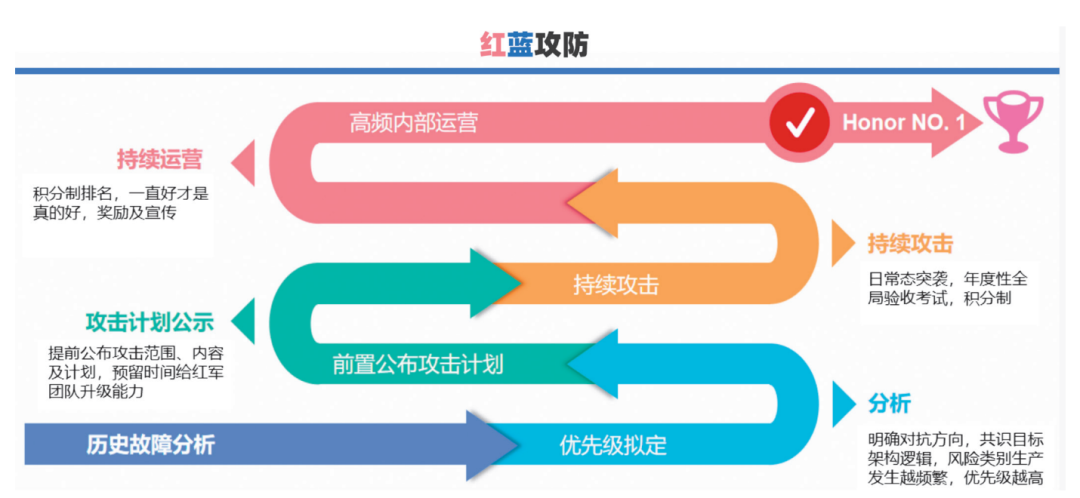
Figure 4 GameDay Culture
During the exercises, the red and blue teams confront each other, conducting real-world network confrontations using simulated network environments while ensuring normal business operations and promptly addressing real architectural vulnerabilities, testing and improving capabilities for detecting security threats, emergency response capabilities, and security protection capabilities. Compared to traditional penetration testing, the main difference in red-blue confrontation is the introduction of dynamic responses from the defending side. In this confrontation, both attack and defense capabilities gradually improve, with the red attacking side attempting internal network penetration using various vulnerabilities while the defending side must have comprehensive security protection capabilities to prevent any opportunities for the enemy. Through practical attack-defense exercises, the actual protective capabilities of important business systems can be effectively verified, security vulnerabilities can be identified, experiences and lessons can be summarized, ultimately improving security protection capabilities.
In specific team practices, application architects are responsible for formulating reliability testing exercise plans based on the high availability architecture characteristics of application systems; testers are responsible for implementing specific tasks according to the exercise plans and conducting system fault tolerance result analysis through monitoring indicators; developers and operations personnel are responsible for problem analysis and emergency response after faults occur. Through the division of labor and collaboration between specialized management and specific implementation teams, the quality of reliability testing work promotion has been effectively ensured. In terms of training, focused training on the characteristics and usage of fault exercise tools is conducted; in terms of communication, regular reliability testing communication meetings are held; in terms of summarization, excellent experiences are continuously refined and solidified into a high availability expert database, and tools or management processes are optimized to prevent the recurrence of issues.
Practice Summary