Article Summary
1. Background and Challenges
– High-resolution images enhance neural network performance but increase computational complexity.
– Traditional CNNs struggle to leverage activation sparsity for practical acceleration.
– Window-based ViTs like Swin Transformer provide new opportunities for activation sparsity.
2. SparseViT Method
– Achieves computational acceleration through window-level activation pruning, reducing latency by 50% at 60% sparsity.
– Proposes sparse-aware adaptation and evolutionary search algorithms to find optimal inter-layer sparsity configurations.
– Modifies FFN and LN layers for window-level execution, simplifying sparse mask mapping.
3. Experiments and Results
– In monocular 3D object detection, 2D instance segmentation, and 2D semantic segmentation tasks, SparseViT achieves 1.5×, 1.4×, and 1.3× acceleration respectively, with negligible accuracy loss.
– Compared different resolutions and width pruning strategies, SparseViT achieves lower latency while maintaining high accuracy.
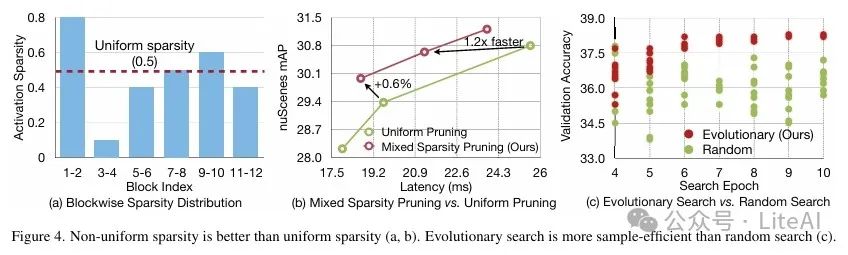
4. Analysis and Validation
– Window pruning is more effective than token pruning, with lower computational cost and higher accuracy.
– Pruning from high-resolution inputs is more effective than starting from low resolution.
– Non-uniform sparse configurations outperform uniform sparse configurations, and evolutionary search is more efficient than random search.
5. Conclusion and Outlook
– SparseViT achieves efficient high-resolution visual task processing through activation sparsity.
– Future research can continue to explore activation pruning while maintaining high-resolution information.

Article link: https://arxiv.org/pdf/2303.17605
Project link: https://github.com/mit-han-lab/sparsevit

TL;DR
Article Method
SparseViT is an efficient window-based visual Transformer (ViT) method that reduces computational complexity through activation sparsity while maintaining high-resolution visual information.
1. Background and Motivation:
– High-resolution images provide richer visual information, but computational complexity also increases.
– Traditional convolutional neural networks (CNNs) struggle to leverage activation sparsity for practical acceleration.
– Window-based ViTs like Swin Transformer provide new opportunities for activation sparsity.
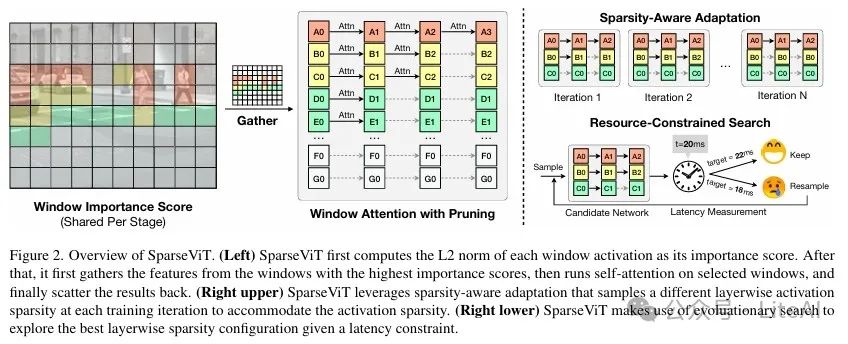
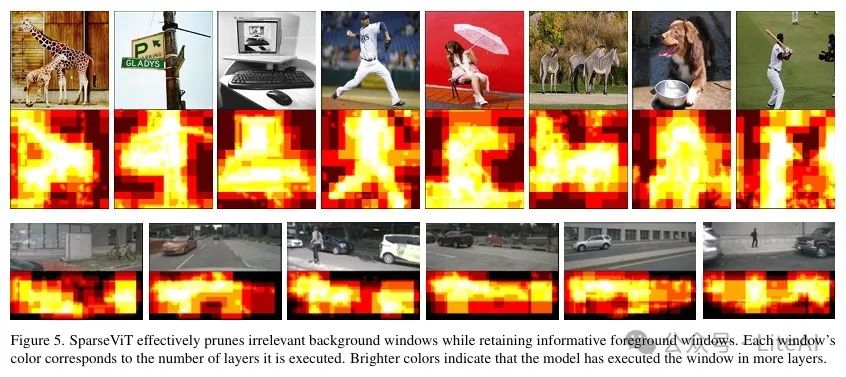
2. Window-Level Activation Pruning:
– SparseViT reduces computation through window-level activation pruning. Specifically, it assesses the importance of each window based on the L2 norm of window activations.
– For a given activation sparsity ratio, the model only processes the windows with the highest importance scores, ignoring others.
– The pruned window features are duplicated to reduce information loss, which is particularly important for dense prediction tasks (such as object detection and semantic segmentation).
3. Window-Level Execution:
– The original Swin Transformer applies multi-head self-attention (MHSA) at the window level, while the feed-forward network (FFN) and layer normalization (LN) are applied across the entire feature map.
– SparseViT changes all operations to be executed at the window level, simplifying the pruning process.
4. Sparse-Aware Adaptation:
– To efficiently evaluate model accuracy under different sparsity configurations, SparseViT proposes a sparse-aware adaptation method.
– During training, the model randomly samples different inter-layer activation sparsity and updates model parameters accordingly.
– This method avoids the high cost of retraining the model for each candidate configuration.
5. Resource-Constrained Search:
– SparseViT uses evolutionary algorithms to search for optimal inter-layer sparsity configurations under resource constraints.
– The search space includes the sparsity ratio for each Swin block, ranging from 0% to 80%.
– The evolutionary algorithm optimizes the sparsity configuration through selection, mutation, and crossover operations.
Experimental Results
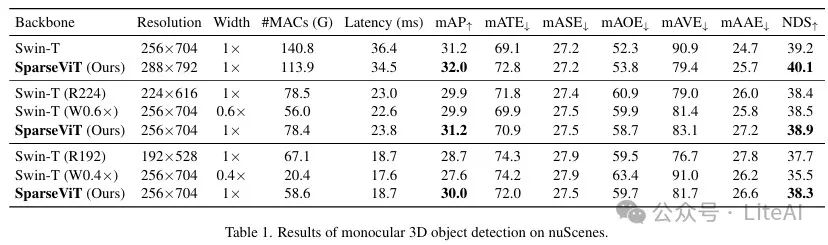
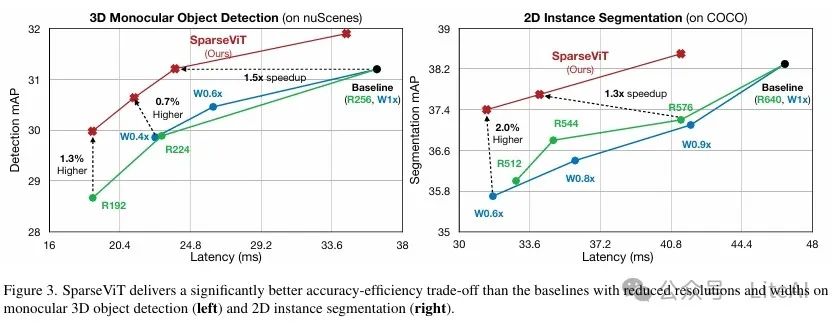
1. Monocular 3D Object Detection:
– Dataset: nuScenes
– Model and Baseline: Using BEVDet as the base model, with the baseline model being Swin-T.
– Results:
– SparseViT achieves the same accuracy as Swin-T at a resolution of 256×704, but with #MACs reduced by 1.8 times and latency reduced by 1.5 times.
– Compared to the baseline at 192×528 resolution, SparseViT achieves 30.0 mAP and 38.3 NDS under a 50% latency budget, which is 1.3 mAP and 0.6 NDS higher than the baseline.
– Compared to the width-reduced baseline, SparseViT outperforms the 0.6× width baseline by 1.3 mAP and the 0.4× width baseline by 2.4 mAP at similar latencies.
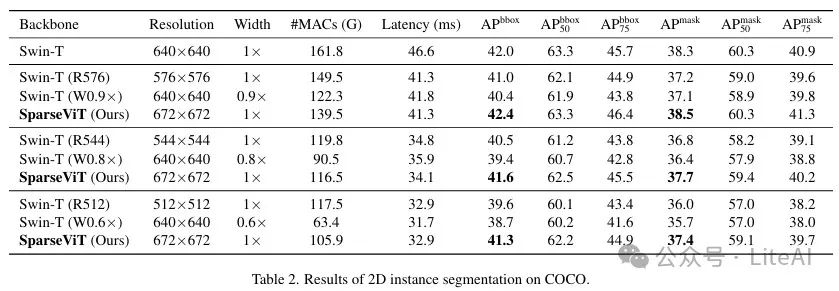
2. 2D Instance Segmentation:
– Dataset: COCO
– Model and Baseline: Using Mask R-CNN as the base model, with the baseline model being Swin-T.
– Results:
– SparseViT achieves higher accuracy than the baseline at a resolution of 672×672, while #MACs are reduced by 1.2 times.
– At similar accuracy, SparseViT is 1.4 times faster than the baseline, with #MACs reduced by 1.4 times.
– With accuracy similar to the baseline at 90% resolution, SparseViT is 1.3 times faster, with #MACs reduced by 1.4 times.
– Despite using a 30% larger resolution, SparseViT is more efficient at 512×512 resolution, with significant accuracy improvement (+1.7 APbbox and +1.4 APmask).
3. 2D Semantic Segmentation:
– Dataset: Cityscapes
– Model and Baseline: Using Mask2Former as the base model, with the baseline model being Swin-L.
– Results:
– SparseViT achieves similar segmentation accuracy as the baseline at a resolution of 1024×2048 while achieving 1.3 times acceleration.
Final Thoughts
Scan to add me, or add WeChat (ID: LiteAI01), for technical, career, and professional planning discussions. Please note “Research Direction + School/Region + Name”