Editorial Note: NPU Will Be the Main Driver of AI PCs(TechInsights Analyst, October 15, 2024)PC OEMs and chip suppliers are counting on consumer interest in artificial intelligence (AI) to drive growth in PC shipments, a growth that has not been seen in years. The rise of AI in recent years has prompted the emergence of a new type of dedicated computing hardware designed specifically to accelerate AI tasks: the Neural Processing Unit (NPU). Like its more mature predecessor, the GPU, the NPU provides a dedicated hardware platform optimized to efficiently execute certain types of computations.To support AI PCs, processor vendors have been adding integrated NPUs to their heterogeneous PC processors. Intel, AMD, and Qualcomm have all launched products that meet Microsoft’s requirements, with integrated NPUs providing at least 400 TOPS (trillions of operations per second) to support the Copilot+ AI assistant. AI PCs and integrated NPUs are still in their early stages; machine learning workloads (such as image classification and object detection) and deep learning activities (such as computer vision and natural language processing) are currently utilizing NPUs, GPUs, and CPUs in roughly equal proportions. However, this relative balance is expected to change rapidly. With further innovations and increasing familiarity among software developers, MPR anticipates that NPUs will take on the majority of AI workloads in AI PCs.A Path Everyone Will FollowOf course, CPUs have been around since the dawn of the computer age in the 1950s and 1960s. They have evolved from executing (relatively) basic computations to faster, more complex architectures capable of handling a variety of instructions and operations that support modern computers, including PCs, servers, smartphones, tablets, gaming consoles, and a wide range of other electronic products from TVs to home appliances, wearables, and IoT devices.Historically, CPUs have been the workhorses of computing, handling a variety of general tasks. However, a new type of processor emerged in the 1990s: the GPU. Initially designed for 3D graphics in video games, GPUs quickly demonstrated their strength in parallel processing of large datasets. While discrete GPUs remain popular among enthusiasts, integrated GPUs have become a standard feature in high-end microprocessors. These integrated GPUs provide hundreds or thousands of arithmetic logic units for parallel processing, enabling them to excel at graphics rendering and other computation-intensive tasks. In recent years, GPUs have played a critical role in the AI revolution, providing the necessary parallel processing power for training and deploying deep learning models.The development of NPUs (also known as AI accelerators) has followed a similar trajectory to that of GPUs. However, while discrete GPUs were already mature before the advent of integrated GPUs, the development of discrete and integrated NPUs has been more closely intertwined. Although often referred to as GPUs, NVIDIA launched what can be considered the first discrete NPU, the V100, in 2017, which was the flagship product of the Volta architecture and the first to introduce dedicated Tensor Cores to accelerate machine learning and deep learning tasks (see MPR report June 2017, “Nvidia’s Volta Upgrades HPC, Model Training”). That same year, Apple introduced what is considered the first integrated NPU, the neural engine in the A11 Bionic SoC of the iPhone 8, 8 Plus, and X models (see MPR report January 2018, “Neural Engine Accelerates Mobile AI”). Integrated NPUs did not appear in PCs until Apple’s M1 in 2020 (see MPR report March 2022, “M1 Ultra Has 20 CPU Cores”).NPUs have a dedicated architecture tailored for AI workloads. Like GPUs, NPUs feature dedicated Multiply-Accumulate (MAC) units that excel at the simple yet numerous calculations found in AI algorithms. Similar to GPUs, NPUs typically arrange MAC units into MAC arrays to better match the matrix structures of large neural networks. For example, the integrated NPU in Intel’s Lunar Lake processor has 12,000 MAC units. Additionally, most NPUs also include other AI-specific hardware, such as acceleration for small data types (e.g., FP8 and INT4) and activation functions like ReLU, sigmoid, and tanh.Advanced Processors Increasing Integrated NPUsApple, Qualcomm, Huawei, and other smartphone SoC providers have integrated NPUs into their products for several generations. Shortly after Apple released the A11 Bionic, Qualcomm introduced the Hexagon digital signal processor (DSP) with AI capabilities in its Snapdragon 835 processor. Both Apple and Qualcomm eventually released Arm PC processor versions based on smartphone SoCs, establishing a foothold for NPUs in the PC market. In 2023, AMD and Intel launched their first x86 PC processors with integrated NPUs, Phoenix (see MPR report January 2023, “AMD Phoenix Brings AI to Laptops”) and Meteor Lake (see MPR report February 2024, “Meteor Lake Boosts Graphics Performance”).For smartphones, the main appeal of NPUs lies in their advantages in form factor and performance per watt. As AI becomes increasingly prevalent, the demand for features such as image recognition, natural language processing, and machine learning is also rising. NPUs are designed to handle many of these tasks in a more energy-efficient manner than traditional CPUs, thereby reducing the power consumption of battery-powered systems. Integrating NPUs into SoCs also helps lower the overall cost of devices.In high-end PC processors, competition for dominance among integrated NPUs is unfolding, especially in Windows PCs. To ensure that Copilot+ branded PCs can efficiently handle AI-intensive tasks for its Copilot AI assistant locally and in real-time, Microsoft set a minimum requirement for integrated NPUs earlier this year, mandating at least 40 TOPS. Following this, Qualcomm, AMD, and Intel all launched processors exceeding that threshold. Qualcomm was the first to introduce the Snapdragon X Elite and Snapdragon X Plus processors, with NPUs capable of achieving 45 TOPS (see MPR report June 2024, “New Surface Launch Helps and Hinders Windows on Arm”). Shortly thereafter, AMD and Intel followed suit with Strix Point (see MPR report June 2024, “Ryzen AI 300 Leads in PC TOPS”) and Lunar Lake (see MPR report July 2024, “Lunar Lake Brings Huge Efficiency Gains”). The entire PC ecosystem is highly dependent on the success of AI PCs; the Copilot+ brand is considered crucial for the success of PCs launched before the holidays.The Evolution of DSPsAll NPUs focus on accelerating neural network computations. However, specific designs and implementations can vary significantly based on the company, target applications, and desired performance characteristics.Many of today’s NPUs are essentially evolved versions of DSPs, which have architectures specifically designed for handling computation-intensive tasks. DSPs traditionally offer high programmability and energy efficiency. They also support vector operations, making them well-suited for the heavy matrix multiplications required for neural network inference. However, while matrices can be decomposed into vectors for processing, NPUs typically have matrix units that are more optimized for AI operations (e.g., 2D MAC arrays). As shown in Figure 1, Intel’s NPU typically includes one or more small DSPs to handle vector operations, while matrix operations are offloaded to larger MAC arrays, which perform most of the processing.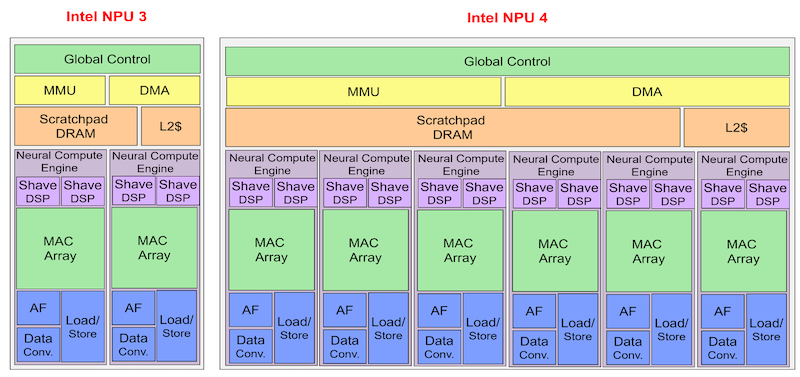 Figure 1 Evolution of Intel’s NPU(AF = Activation Function. Structurally, Intel’s NPU4 in the Lunar Lake processor (right) is essentially an enlarged version of the previous generation NPU3 (left).)The XDNA 2 NPU integrated into AMD’s Strix Point processor represents the evolution of the Xilinx XDNA AI engine, which itself evolved from Xilinx DSPs, sharing many core functionalities, instruction sets, and underlying architectures with them. Qualcomm’s Arm-based Hexagon NPU has undergone a more direct evolution from the company’s Hexagon DSP, which has been continuously optimized over time as smartphones have added more image editing tools (especially AI-based tools).Intel’s NPU 4 was first integrated into the company’s Lunar Lake processor, evolving from technology acquired from Movidius in 2016, a fabless semiconductor company that had been established for eight years and was a leader in mobile vision processing. NPU 4 developed from the first generation of Movidius IP that supported neural network hardware acceleration (see MPR report December 2018, “Intel Wins Myriad Customers”), namely the Myriad X Vision Processing Unit (VPU). The VPU is a DSP optimized for computer vision applications.Preparing for Long-Term DevelopmentThe rise of hardware accelerators is undeniable. Notably, MPR predicted the accelerated shift to integrated NPUs in PCs three years ago (see MPR report January 2022, “Annual Review: PC Processors Adopt Hybrid CPUs”). So far, NPUs have solidified their position as essential components of modern computing infrastructure alongside CPUs and GPUs. Their ability to significantly accelerate AI workloads, which undoubtedly is the most transformative and far-reaching force shaping technology today, will increasingly be integrated into more PCs (and many other devices). As AI continues to evolve, the demand for more powerful and efficient NPUs will only increase, driving further innovation and advancement in NPU technology.While NPUs excel at accelerating matrix multiplications, the cornerstone of large language models (LLMs), they will not completely replace CPUs and GPUs for all AI workloads. Fundamentally, LLM training and inference require a combination of CPU-intensive tasks (such as loading and quantization) and NPU-intensive tasks (such as token generation). LLM performance is influenced not only by NPU capabilities; it also depends on CPU performance, the speed of loading the LLM, and DRAM bandwidth. The process involves three main stages: load, prefill, and token. The load stage involves loading the LLM into memory (including the model’s weights, biases, and other parameters) and performing quantization, which heavily relies on I/O operations and CPU activity, and is significantly dependent on CPU performance and disk speed. In the prefill stage, the LLM analyzes user prompts to generate initial output tokens, which heavily relies on the NPU or AI accelerator. Subsequent tokens are generated in the token stage to optimize the model, which depends on NPU performance but primarily relies on DRAM bandwidth, as the model needs to load the entire weight set of the LLM. Optimizing LLM performance requires careful consideration of all these factors.A collaborative approach that leverages the strengths of each major processing component is still needed. NPUs optimized for matrix multiplication are essential for tasks such as natural language processing and repetitive background tasks. GPUs with parallel processing capabilities will continue to play a role in lightweight inference tasks in graphics and computer vision. Meanwhile, CPUs will continue to handle sequential processing tasks such as data preprocessing and algorithm development. This collaboration ensures the most efficient and effective execution of various AI applications.NPUs Will Handle Most AI on PCsOne of the biggest obstacles to the wider use of dedicated NPUs is that they are too new, and few Windows applications are optimized for them. As developers become more familiar with dedicated NPUs and their capabilities, Microsoft and Windows processor vendors hope they can leverage them more, especially for AI assistants running locally rather than in the cloud, which has advantages in speed (lower latency) and data privacy. For example, AMD stated earlier this year that it expects over 150 software vendors’ products to be able to leverage the NPUs integrated into its Ryzen AI products by the end of this year. To facilitate this shift, both Intel and AMD are actively providing enhanced tools and runtime libraries for developers to optimize and deploy AI inference capabilities.In May, Intel announced internal research findings indicating that independent software vendors (ISVs) are executing AI workloads on PCs using a combination of multiple engines (NPU, GPU, and CPU). Intel stated that ISVs plan to write about 30% of AI workloads to run on NPUs by 2025, up from 25% this year. The percentage of AI workloads written for CPUs is expected to decrease from about 35% this year to about 30% next year, while the percentage of AI workloads written for GPUs is expected to remain at about 40% over the next two years.MPR believes that the current balance is largely a legacy issue; PCs have only recently added NPUs, and most PCs (even new ones) do not have them. With only a small fraction of PCs equipped with NPUs, much of the AI has ended up concentrated on GPUs. As NPUs become more widely deployed and more software is written to leverage them, the balance will shift, and more AI workloads will move to the most optimized computing elements to handle them effectively. Looking ahead, MPR anticipates that most AI-related workloads running on PCs will shift to NPUs, leaving only a small portion on GPUs, while CPUs will continue to handle lightweight AI tasks that are not worth offloading. In the long run, MPR expects the segmentation of AI-related workloads on PCs to evolve.Learn More:* Want to learn about the new NPU IP for TinyML? Check out the Ceva NPU Core for TinyML workloads.* Curious about SoCs for edge AI? Check out the new Versal AI Edge adaptive SoC that will enhance scalar computing.* Want to learn more about the rise of AI PCs? Check out the insights: “Apple Intelligence” aims to reclaim AI leadership at WWDC 2024.
Figure 1 Evolution of Intel’s NPU(AF = Activation Function. Structurally, Intel’s NPU4 in the Lunar Lake processor (right) is essentially an enlarged version of the previous generation NPU3 (left).)The XDNA 2 NPU integrated into AMD’s Strix Point processor represents the evolution of the Xilinx XDNA AI engine, which itself evolved from Xilinx DSPs, sharing many core functionalities, instruction sets, and underlying architectures with them. Qualcomm’s Arm-based Hexagon NPU has undergone a more direct evolution from the company’s Hexagon DSP, which has been continuously optimized over time as smartphones have added more image editing tools (especially AI-based tools).Intel’s NPU 4 was first integrated into the company’s Lunar Lake processor, evolving from technology acquired from Movidius in 2016, a fabless semiconductor company that had been established for eight years and was a leader in mobile vision processing. NPU 4 developed from the first generation of Movidius IP that supported neural network hardware acceleration (see MPR report December 2018, “Intel Wins Myriad Customers”), namely the Myriad X Vision Processing Unit (VPU). The VPU is a DSP optimized for computer vision applications.Preparing for Long-Term DevelopmentThe rise of hardware accelerators is undeniable. Notably, MPR predicted the accelerated shift to integrated NPUs in PCs three years ago (see MPR report January 2022, “Annual Review: PC Processors Adopt Hybrid CPUs”). So far, NPUs have solidified their position as essential components of modern computing infrastructure alongside CPUs and GPUs. Their ability to significantly accelerate AI workloads, which undoubtedly is the most transformative and far-reaching force shaping technology today, will increasingly be integrated into more PCs (and many other devices). As AI continues to evolve, the demand for more powerful and efficient NPUs will only increase, driving further innovation and advancement in NPU technology.While NPUs excel at accelerating matrix multiplications, the cornerstone of large language models (LLMs), they will not completely replace CPUs and GPUs for all AI workloads. Fundamentally, LLM training and inference require a combination of CPU-intensive tasks (such as loading and quantization) and NPU-intensive tasks (such as token generation). LLM performance is influenced not only by NPU capabilities; it also depends on CPU performance, the speed of loading the LLM, and DRAM bandwidth. The process involves three main stages: load, prefill, and token. The load stage involves loading the LLM into memory (including the model’s weights, biases, and other parameters) and performing quantization, which heavily relies on I/O operations and CPU activity, and is significantly dependent on CPU performance and disk speed. In the prefill stage, the LLM analyzes user prompts to generate initial output tokens, which heavily relies on the NPU or AI accelerator. Subsequent tokens are generated in the token stage to optimize the model, which depends on NPU performance but primarily relies on DRAM bandwidth, as the model needs to load the entire weight set of the LLM. Optimizing LLM performance requires careful consideration of all these factors.A collaborative approach that leverages the strengths of each major processing component is still needed. NPUs optimized for matrix multiplication are essential for tasks such as natural language processing and repetitive background tasks. GPUs with parallel processing capabilities will continue to play a role in lightweight inference tasks in graphics and computer vision. Meanwhile, CPUs will continue to handle sequential processing tasks such as data preprocessing and algorithm development. This collaboration ensures the most efficient and effective execution of various AI applications.NPUs Will Handle Most AI on PCsOne of the biggest obstacles to the wider use of dedicated NPUs is that they are too new, and few Windows applications are optimized for them. As developers become more familiar with dedicated NPUs and their capabilities, Microsoft and Windows processor vendors hope they can leverage them more, especially for AI assistants running locally rather than in the cloud, which has advantages in speed (lower latency) and data privacy. For example, AMD stated earlier this year that it expects over 150 software vendors’ products to be able to leverage the NPUs integrated into its Ryzen AI products by the end of this year. To facilitate this shift, both Intel and AMD are actively providing enhanced tools and runtime libraries for developers to optimize and deploy AI inference capabilities.In May, Intel announced internal research findings indicating that independent software vendors (ISVs) are executing AI workloads on PCs using a combination of multiple engines (NPU, GPU, and CPU). Intel stated that ISVs plan to write about 30% of AI workloads to run on NPUs by 2025, up from 25% this year. The percentage of AI workloads written for CPUs is expected to decrease from about 35% this year to about 30% next year, while the percentage of AI workloads written for GPUs is expected to remain at about 40% over the next two years.MPR believes that the current balance is largely a legacy issue; PCs have only recently added NPUs, and most PCs (even new ones) do not have them. With only a small fraction of PCs equipped with NPUs, much of the AI has ended up concentrated on GPUs. As NPUs become more widely deployed and more software is written to leverage them, the balance will shift, and more AI workloads will move to the most optimized computing elements to handle them effectively. Looking ahead, MPR anticipates that most AI-related workloads running on PCs will shift to NPUs, leaving only a small portion on GPUs, while CPUs will continue to handle lightweight AI tasks that are not worth offloading. In the long run, MPR expects the segmentation of AI-related workloads on PCs to evolve.Learn More:* Want to learn about the new NPU IP for TinyML? Check out the Ceva NPU Core for TinyML workloads.* Curious about SoCs for edge AI? Check out the new Versal AI Edge adaptive SoC that will enhance scalar computing.* Want to learn more about the rise of AI PCs? Check out the insights: “Apple Intelligence” aims to reclaim AI leadership at WWDC 2024.