New Intelligence Source Compilation
Source: deepmind.com; arXiv.org
Translator: Wenqiang
【New Intelligence Source Guide】DeepMind today published an official blog introducing their two latest papers, claiming that both have shown promising results in understanding the challenge of “relation reasoning”. One is the Visual Interaction Network (VIN), which can predict the positions of various objects in a visual scene for the next several hundred steps, while the other is a modular, relation reasoning-capable deep neural network architecture (RN) that can be “plug-and-play” to enhance the relation reasoning capabilities of other deep neural network structures (like CNN). The overall reasoning accuracy of RN has reached 95.5% in test results on the CLEVR dataset proposed by Fei-Fei Li et al., surpassing human levels.

First, let’s look at the “Visual Interaction Network” (VIN).
DeepMind’s official blog states that a key factor in understanding relation reasoning is predicting what happens in a real scene in the future.
With just a glance, humans can infer the positions of objects for the next few seconds, minutes, or even longer, and can predict what happens next.
For example, when kicking a ball against a wall, the brain can predict where the ball will hit the wall and the subsequent trajectories of both the ball and the wall: the ball will bounce based on its angle of incidence and speed, while the wall will remain stationary.
These predictions, although simple, are guided by a complex cognitive system.
As a result, DeepMind’s researchers developed the “Visual Interaction Network” (VIN), which can simply simulate the brain’s inference system.
VIN can infer the positions of multiple objects based on several frames of continuous video.
This differs from generative models, which produce results that are visually “imagined”; VIN infers based on the basic relationships between objects.

The left shows the ground truth, and the right shows VIN’s predictions. Over approximately 150 frames of video, VIN provided an extremely close simulation, and the subsequent predictions appeared reasonable to the naked eye. Source: deepmind.com
VIN consists of two main mechanisms: a visual module and a physical reasoning module. Together, these two modules can process a visual scene and predict what will happen to each different object under real physical laws.
DeepMind researchers tested VIN in various environments, including bouncing billiards, spring-connected bodies, and planetary gravity systems. The results showed that VIN could accurately predict what would happen to objects in the future hundreds of steps.
-
Paper: Visual Interaction Network

The authors wrote in the abstract that with just a glance, humans can make a variety of predictions about the future states of different physical systems. On the other hand, modern methods from engineering, robotics, and graphics are often limited to narrow domains and require direct measurement of the underlying state.
We propose the Visual Interaction Network (VIN), a general model for learning the dynamic mechanisms of physical systems from raw visual observations.
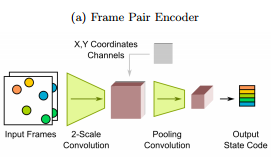
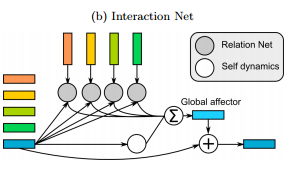
VIN consists of a perception front-end based on convolutional neural networks (a, see above) and a dynamic predictor based on interaction networks (b, see below). Through joint training, the perception front-end learns to parse dynamic visual scenes into a set of special object representations. The dynamic predictor learns to advance these states by calculating interactions and mechanical relationships between objects, thereby producing predictions of physical trajectories of arbitrary lengths.
The authors found that with only 6 frames of input video, VIN can generate accurate prediction trajectories for hundreds of time steps in various physical systems.
VIN can also be applied in scenarios where objects are not visible, thereby predicting the future states of invisible objects based on visible ones, implicitly inferring the mass of unknown objects. The research results indicate that the object representations introduced by the perception module and the prediction module based on object dynamic mechanisms can make accurate dynamic predictions. This work opens up new opportunities for model-based decision-making and planning based on raw sensory observations in complex physical environments.
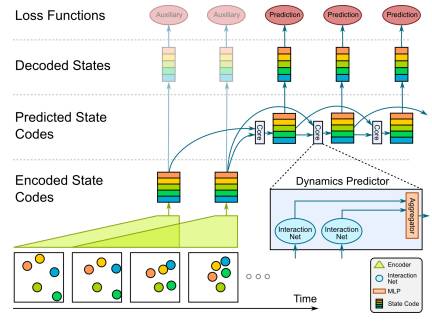
Diagram of VIN architecture
Next, let’s look at “Simple Neural Network Module for Relation Reasoning”.

The authors wrote in the abstract that relation reasoning is a core component of general intelligent behavior, but previous studies have shown that neural networks struggle to learn to perform relation reasoning. In this paper, we describe how to use Relation Networks (RN) as simple plug-and-play modules to fundamentally solve the problem of relying on relation reasoning.
We tested the RN-enhanced network on three tasks:
-
Using the challenging CLEVR dataset to answer visual questions, achieving the current best results and surpassing human levels;
-
Using the bAbI task for text-based question answering;
-
Complex reasoning about dynamic physical systems.
Then, we specifically organized a dataset similar to CLEVR called Sort-of-CLEVR, and demonstrated that convolutional neural networks lack the general capability to solve relation problems, but can gain relation reasoning capabilities after using RN enhancement.
Our work illustrates how deep learning architectures equipped with RN modules can implicitly discover and learn to reason about entities and their relationships.
Three different standard tests showed that the relation reasoning capabilities of the CLEVR dataset surpass human levels.
Task One: Sort-of-CLEVR Dataset
To explore our hypothesis that RN architectures are better at general relation reasoning than more standard neural network architectures, we constructed a dataset similar to CLEVR called “Sort-of-CLEVR”.
The main feature of the Sort-of-CLEVR dataset is the distinction between relevant and irrelevant questions. This dataset consists of 2D color images and questions and answers related to the images. Each image contains 6 objects, each randomly selected shape (square or circle). The authors used 6 colors (red, blue, green, orange, yellow, gray) to identify each object.
To avoid complex natural language processing, the questions were hand-coded. Additionally, the images were simplified to reduce the complexity involved in image processing.
Each image has 10 relation questions and 10 non-relation questions. For example, relation questions include “What is the shape of the object farthest from the gray object?” and “How many objects share the same shape as the green object?” Non-relation question examples are: “What is the shape of the gray object?” and “Is there a blue object at the top or bottom of the scene?”

Examples of CLEVR dataset image understanding questions
Task Two: bAbI Question Answering Dataset
bAbI is a pure text QA dataset. It consists of 20 tasks, each corresponding to a specific type of reasoning, such as deduction, induction, or counting. Each question is related to a set of supporting facts. For example, the facts “Sandra picked up the soccer ball” and “Sandra went to the office” support the question “Where is the soccer ball?” (Answer: “Office”).
If the accuracy for completing a task exceeds 95%, the model is considered successful.
Many memory-augmented neural networks have performed well on bAbI. When each task was jointly trained with a sample size of 10K, the Memory Network scored 14/20, DeepMind DNC scored 18/20, Sparse DNC scored 19/20, and EntNet scored 16/20.
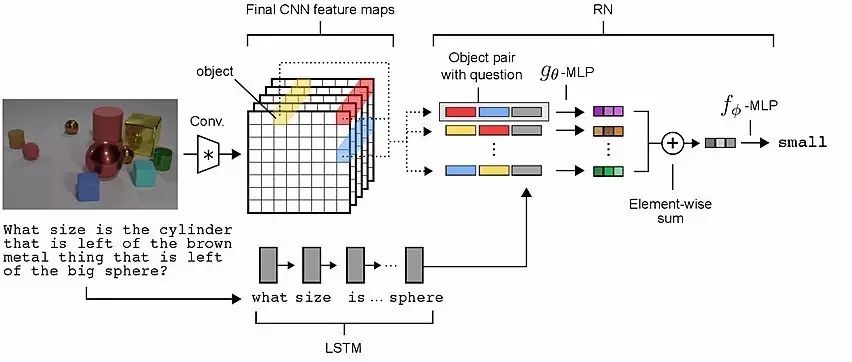
Structure diagram of visual QA questions
Test results showed that RN’s data was 18/20.
Task Three: Complex Reasoning about Dynamic Physical Systems
We developed a dataset simulating a system of colored balls connected by springs using the MuJoCo physics engine. Each scene contains 10 colored balls moving on a tabletop. Some balls move independently and collide freely with other balls and obstacle walls. Others, randomly selected, have invisible springs or fixed forces connecting them.
By introducing randomly selected connections between these balls, a constantly changing physical system is created. The authors defined two independent tasks based solely on observing the colors and corresponding coordinates of the balls in multiple consecutive frames: 1) infer whether the connection force between the balls exists or not, and 2) how many “systems” (including balls and nodes) are on the tabletop.
Both tasks involve reasoning about the relative positions and speeds of the balls. The difference is that the first task’s inference is explicit, while the second task requires implicit reasoning, making it more difficult.
Effective allocation to leverage the strengths of different structured neural networks
The paper demonstrates how to apply the dedicated RN module for calculating relationships between entities to broader deep learning architectures, significantly enhancing their ability to perform relation reasoning tasks.
The modular structure RN proposed in the paper achieved a 95.5% accuracy on the CLEVR dataset, surpassing human levels. The bAbI results also showed that RN has general reasoning capabilities, solving 18/20 tasks without catastrophic failures.
The authors noted that one of the most interesting aspects of the work is how inserting the RN module into relatively simple CNN and LSTM-based VQA architectures improved the CLEVR results from 68.5% to 95.5%, achieving the current optimal level that also surpasses human performance.
The authors speculate that RN provides a more flexible reasoning mechanism, allowing CNNs to focus more on processing local spatial structure data, thus achieving a significant overall performance improvement.
The authors wrote that it is important to distinguish between “processing” and “reasoning” during computation.For example, a powerful deep learning architecture like ResNet is very efficient as a visual processor but may not be the most suitable choice for reasoning arbitrary relationships.
A key contribution of their work is that RN, through learning to induce upstream processing tasks, provides a set of useful representations for objects.
It is important to note that neither the input data nor the target function specifies any particular form or semantics of internal object representations. This indicates that RN has rich structured reasoning capabilities, even with unstructured inputs and outputs.
The authors believe that the newly proposed Relation Network (RN) module is a simple yet powerful method for enabling deep neural networks to learn to perform various structured reasoning tasks in the complex real world.
DeepMind’s two latest papers uploaded to arXiv demonstrate the powerful capabilities of neural networks in deconstructing the world.
Neural networks can deconstruct the world into systems composed of objects and the relationships within and between these systems, and based on this, generalize to make new inferences about the scenes and the relationships between the objects that seem very different but share commonalities at their core.
DeepMind’s blog concluded that they believe the new methods proposed in the papers are scalable and can be applied to more tasks, building more complex models to better understand a key aspect of human intelligence: reasoning.
-
Paper: Visual Interaction Network: https://arxiv.org/pdf/1706.01433.pdf
-
Paper: Simple Fact Relation Reasoning Module: https://arxiv.org/pdf/1706.01427.pdf
