In recent years, recommendation systems have played an increasingly important role across various industries. Among them, the embedding layer of recommendation systems has become a performance bottleneck due to the large volume of data and irregular memory access patterns. Existing works utilize the data locality of the embedding layer to cache frequently accessed embedding vectors and intermediate results, thereby reducing memory access and computational redundancy in the embedding layer, and improving the performance of recommendation systems. However, these solutions rely on static data caching, which is only applicable to the inference process of recommendation systems and cannot be applied to the training scenarios where embedding vectors are dynamically updated. To address this, this paper proposes a redundancy-free near-memory processing solution, ReFree, suitable for training recommendation systems. ReFree can identify reusable embedding vectors and gradient data in real-time during the forward and backward propagation processes of embedding layer training, and utilizes a near-memory computing architecture to achieve redundancy-free near-memory acceleration throughout the embedding layer training process. Evaluation results show that ReFree achieves a performance improvement of up to 10.9 times compared to the current state-of-the-art solutions, with an average energy consumption reduction of 5.3 times.
This work, “Towards Redundancy-Free Recommendation Model Training via Reusable-aware Near-Memory Processing“, was presented at the 61st ACM/IEEE Design Automation Conference (DAC 2024), which is a top international conference in the field of design automation and is classified as an A-level conference recommended by the China Computer Federation (CCF).

-
Paper link: https://dl.acm.org/doi/10.1145/3649329.3656511
Background and Motivation
Personalized recommendation systems are widely used in various applications, including e-commerce, search engines, media services, and social networks. Typical personalized systems usually combine users’ personal attribute information and user interaction information to make recommendations. The dense personal attribute information is processed by a fully connected neural network layer (FC layer), while the sparse user interaction information is processed by an embedding layer. The embedding layer typically consists of multiple embedding tables, each corresponding to a categorical feature, and each embedding table may contain millions to billions of embedding vectors, with each vector representing an entry.
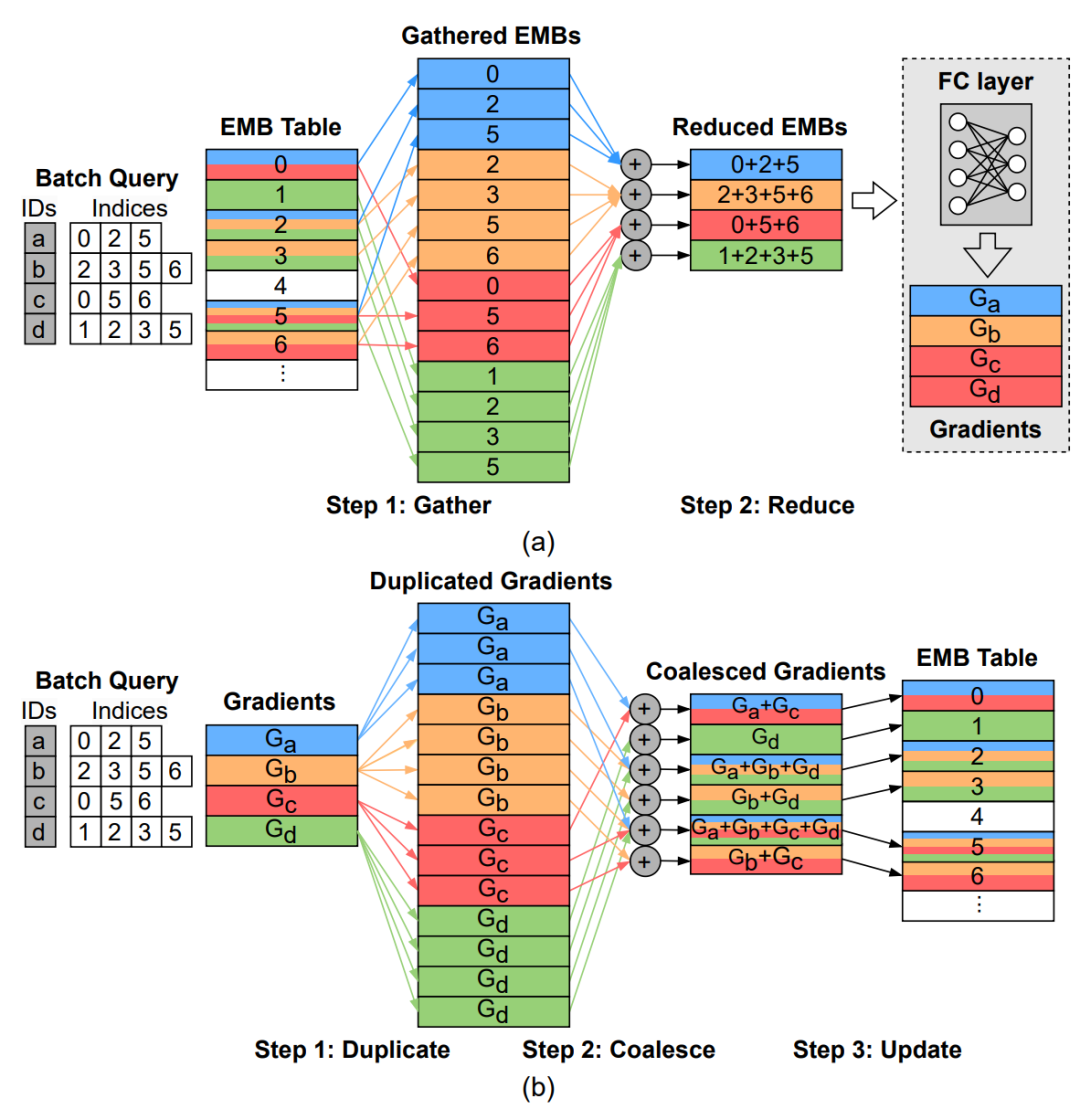
Figure 1: Training process of the DLRM recommendation model embedding layer, (a) Forward propagation and (b) Backward propagation
Figure 1 illustrates the forward and backward propagation processes of the embedding layer during the training of the recommendation model. As shown in Figure 1(a), the embedding layer performs a lookup-aggregation operation during forward propagation, looking up the embedding table based on the provided indices and accessing the corresponding embedding vectors. It then merges the accessed vectors into a single vector through simple element-wise operations (such as summation and weighted sum) to serve as input for subsequent processes. During backward propagation, gradient vectors for each query are generated to update the embedding table. As shown in Figure 1(b), the embedding layer performs gradient copying, gradient merging, and embedding vector update operations during backward propagation. First, the gradient vector for each training sample is copied to match the embedding vectors accessed during forward propagation. Then, the gradient data updating the same embedding vector is merged, and the merged gradient vector is updated to the corresponding embedding vector.
The embedding layer exhibits two types of data locality: lookup locality and aggregation locality. Lookup locality refers to a small portion of embedding vectors being accessed frequently, while the majority are rarely accessed, resulting in a highly skewed access distribution. Aggregation locality indicates that frequently accessed embedding vectors may be accessed simultaneously, meaning that popular data combinations are frequently accessed and aggregated. Since recommendation systems often adopt batch execution modes to enhance throughput, these two types of locality can lead to memory access and computational redundancy within a batch. Memory access redundancy arises from lookup locality; if multiple queries contain the same embedding vector, that embedding vector will be accessed multiple times from memory, causing redundant memory access. Computational redundancy stems from aggregation locality; if multiple queries contain the same combination of embedding vectors, those vector combinations will be aggregated multiple times, leading to redundant computation. Due to the widespread existence of these two types of locality, such redundancies are also prevalent in various real-world scenarios.
To reduce memory access redundancy in the embedding layer, prior works have cached popular data in faster storage (such as HBM, buffers, or caches) to avoid repeated memory access for popular data. To reduce computational redundancy in the embedding layer, existing works have pre-stored partial aggregation results between popular data (e.g., any two or three), so that when these vector combinations are accessed later, their results can be read directly, avoiding repeated computation. However, existing solutions face the following drawbacks. First, they all rely on preprocessing to analyze popular data and require a significant amount of additional storage space to store popular data and intermediate results. Second, existing works do not support dynamic awareness; if the frequency distribution of embedding layer data access changes, they need to be reprocessed. Furthermore, in training scenarios, embedding data is frequently updated within training batches (especially popular data), making existing preprocessing-based caching solutions inefficient for training scenarios.
Design and Implementation
To efficiently address the redundancy issues in the embedding layer of recommendation models, this paper proposes real-time redundancy awareness, which analyzes data in each processing batch in real-time to accurately predict memory access and computational redundancy and efficiently reuse results, without relying on preprocessed caching.
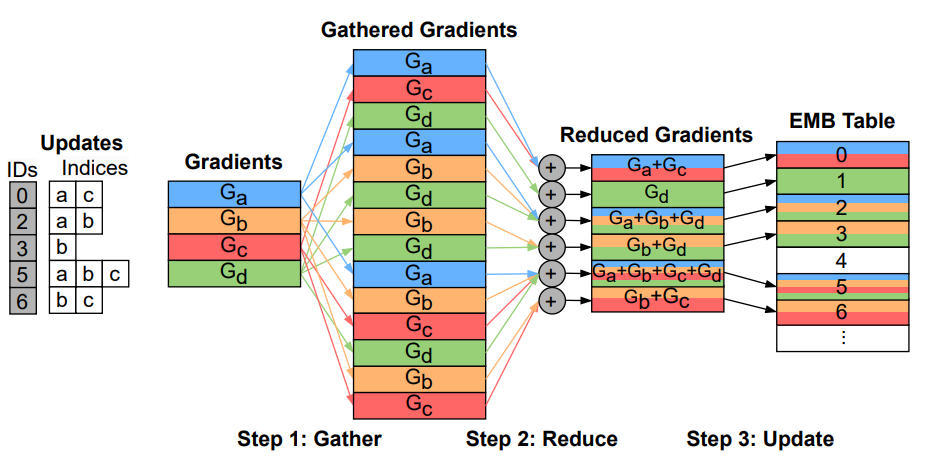
Figure 2: Unified backward propagation process after forward propagation operations
Unified forward and backward propagation operations: To achieve unified redundancy elimination in the forward and backward propagation processes of the embedding layer, this paper first unifies the backward propagation with the forward propagation operations. Since the gradient merging operation in the backward propagation process performs the same arithmetic operations as the embedding vector aggregation operation in the forward propagation process, this paper unifies the backward propagation to the same lookup-aggregation operation as the forward propagation. As shown in Figure 2, we treat the gradient data of a batch as a gradient vector table, where the query ID is the index of the embedding vector to be updated, and the query index is the gradient that needs to be collected to update the corresponding embedding vector. Therefore, the backward propagation is unified with the forward phase operations (with an additional update step), allowing for the construction of a unified solution for the entire training process.

Figure 3: Memory access redundancy elimination, (a) Forward propagation phase (reduced from 14 to 6) and (b) Backward propagation phase (reduced from 14 to 4)
Memory access redundancy elimination: In training scenarios, all access indices for training batches are known in advance, allowing us to analyze the reusability of data, accessing all embedding vectors that appear in a training batch only once and reusing them multiple times based on requests. Figure 3 illustrates how to eliminate memory access redundancy by accessing all appearing embedding vectors only once. We first obtain the different data indices accessed by each training sample (in this case, a total of 6 different embedding vectors were accessed during forward propagation, and a total of 4 during backward propagation). For example, vector 0 is looked up in training samples a(0,2,5) and c(0,5,6), and can be shared by these two samples, recorded as 0(2,5|5,6), storing all vectors and their reusable relationships in an aggregation buffer. Thus, this paper transforms the previously request-centric access into data-centric access, ensuring that each request’s data is accessed only once, allowing it to be reused by all samples within the batch, completely eliminating memory access redundancy within the same batch.

Figure 4: Computational redundancy elimination, (a) Forward propagation phase (reduced from 10 to 7) and (b) Backward propagation phase (reduced from 7 to 5)
Computational redundancy elimination: An intuitive idea for eliminating computational redundancy is to reuse partial results of combinations that appear multiple times within a batch. However, the number of combinations grows exponentially with the increase in the number of vectors (combinatorial explosion), making it costly to analyze repeated combinations in advance. However, we observe that reusable combinations are more likely to occur among popular data, so prioritizing access to popular data can generate reusable intermediate results early, maximizing the opportunity for intermediate data reuse and thus reducing redundant computation. Figure 4 illustrates how to eliminate computational redundancy by prioritizing access to popular data and reusing their partial results. We sort the access frequency of vectors and access embedding vectors in order of frequency from high to low. For example, by prioritizing access to the two most frequently accessed vectors 5 and 2, their partial result 5+2 is reused by 3 training samples, thus reducing two computations.
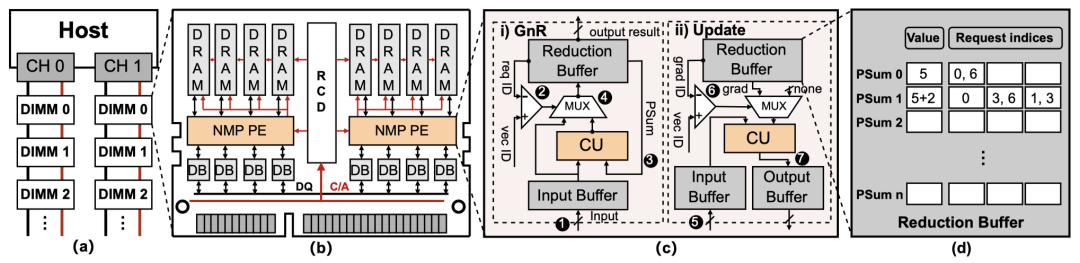
Figure 5: ReFree architecture design: (a) Overall architecture, (b) Memory module supporting near-memory computing, (c) Design of near-memory computing units, (d) Data structure of aggregation buffer
Redundancy-Free Near-Memory Computing Architecture: Since the embedding layer is a typical memory bottleneck application, we apply the aforementioned redundancy-aware embedding layer execution mode in a near-memory architecture, designing a low-redundancy recommendation model near-memory computing architecture, ReFree. Figure 5 shows the basic architecture of ReFree. ReFree adds near-memory computing units (NMP PE) in LRDIMM to perform embedding layer operations, where the near-memory computing units support lookup-aggregation and update operations of the embedding layer in both inference and training scenarios. The near-memory computing unit contains an aggregation buffer that stores reusable information for the current processing batch. Each time a new embedding vector is accessed, it will be reused by all queries in the current processing batch. Additionally, generated intermediate results will also be shared among all queries, significantly reducing redundant memory access and computation, thus accelerating the execution speed of the embedding layer.
We tested ReFree on multiple datasets, and experimental results show that ReFree significantly reduces memory access and computational redundancy, achieving a performance improvement of up to 10.9 times compared to the current state-of-the-art near-memory computing solutions, with an average energy consumption reduction of 5.3 times.
For detailed content, please refer to
Haifeng Liu, Long Zheng, Yu Huang, Haoyan Huang, Xiaofei Liao, Hai Jin, “Towards Redundancy-Free Recommendation Model Training via Reusable-aware Near-Memory Processing”, In Proceedings of the 61st ACM/IEEE Design Automation Conference, 2024: 255:1 – 255:6.