Hello, I am Yule~
In the previous article on advanced C++ programming techniques regarding cache lines, we discussed the impact of cache lines on program performance. However, sometimes, even within the same cache line, there can be interference, which is what this article will discuss: <span>False Sharing</span>.
Since the previous writing was somewhat rushed, some foundational knowledge points were not listed, leading to many readers who are unfamiliar with this topic having only a vague understanding. Therefore, in this article, I may mention some basic knowledge points as a supplement to the previous article.
Alright, let’s get started~
We all know that caches are ubiquitous, whether in our daily project coding or in the hardware and software of computer systems. Typically, we access caches to avoid the poorer performance of data processing; that is, if a portion of data already exists in the cache, there is no need to reprocess or retrieve it, which is a typical example of taking advantage of existing resources.
The cache mentioned in this article specifically refers to CPU caches, which are divided into three levels: L1, L2, and L3, where L1 is closest to the CPU and L3 is closest to the memory. Each CPU has its own cache, situated between the CPU and the memory.
We can refer to the following diagram (from the internet) for better understanding:
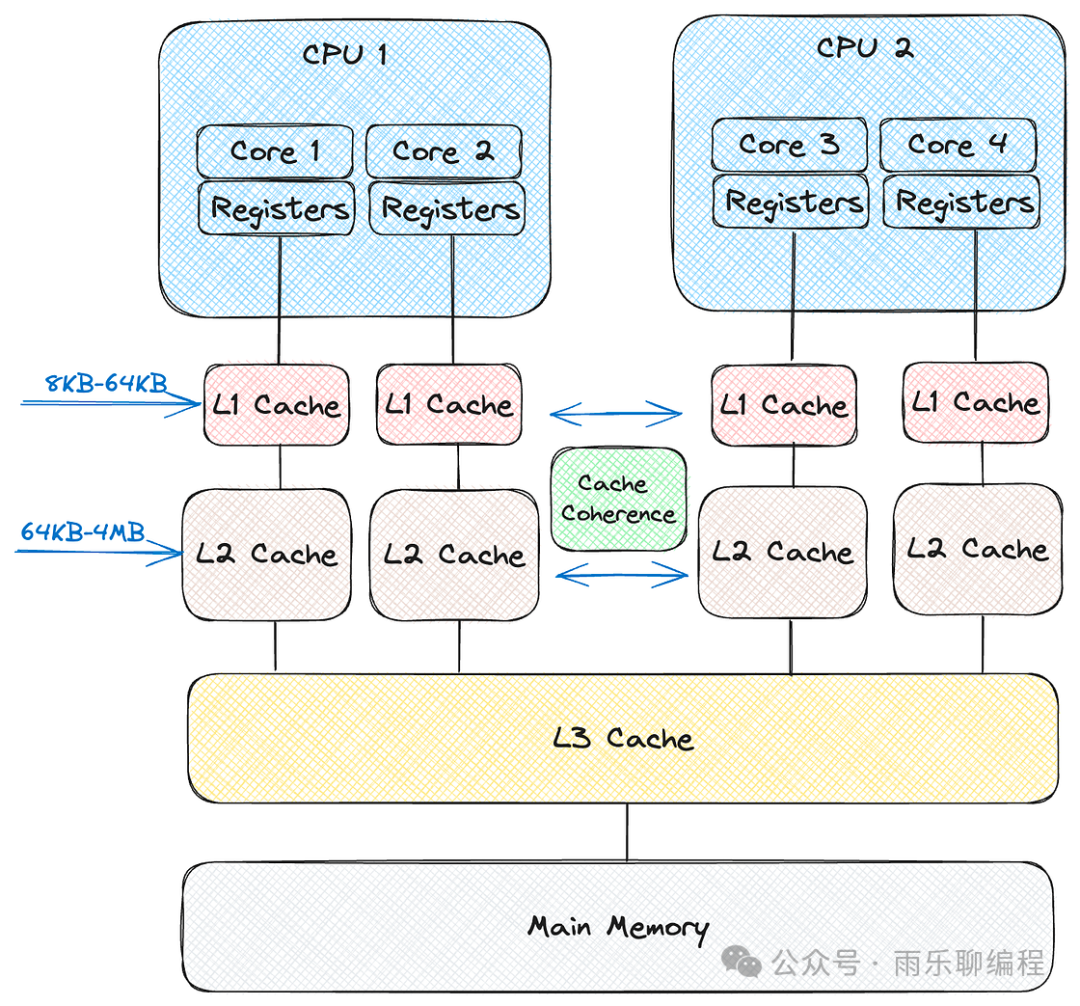
Cache
From the perspective of distance from the CPU, L1 is the closest cache, typically located on the chip, with a capacity ranging from 8KB to 64KB; L2 is situated between L1 and L3, with a larger cache size, generally between 64KB and 4MB; L3 is located after L2, closer to the memory, and is used to store shared data among various CPU cores.
Next, let’s briefly discuss these cache levels.
L1 Cache
In terms of proximity to the CPU, L1 is the closest cache, typically located on the chip, with a capacity ranging from 32KB to 64KB. It is primarily used for two types of tasks: data caching and instruction caching. It is mainly used to store the data and instructions most frequently accessed by the CPU core. Its access speed is comparable to that of the CPU; if the L1 cache is hit, it typically consumes 1 to 3 clock cycles.
If the CPU needs to access data or instructions, the first step is to check whether the data exists in the L1 cache. If it does, it is referred to as a <span>cache hit</span>, meaning that the data can usually be retrieved in just 1 to 3 clock cycles; otherwise, it is referred to as a cache miss, at which point the CPU must retrieve the data from L2, L3, or memory.
How does the CPU decide which data to place in the L1 cache? It mainly relies on two principles: temporal locality and spatial locality.
Temporal locality means that the CPU keeps recently used data because it is likely to be used again soon. Spatial locality is more predictive; the CPU not only retrieves recently accessed data but also brings in nearby data into the cache, as programs typically access memory in a contiguous manner.
However, since the L1 cache is quite small, it is crucial to select which data to store carefully. If the cache is full and needs to be replaced, a common method is LRU (Least Recently Used), which replaces the data that has not been used for the longest time. Some CPUs, for simplicity, use random replacement methods, which, while not as intelligent, can reduce computational overhead and may execute faster.
L2 Cache
The L2 cache is situated between L1 and L3. As discussed earlier, if the CPU does not find a cache hit in L1, it will look for data in the L2 cache, which typically has a size of 512KB to 2MB.
Its principle is similar to that of L1, with the main difference being that it is slightly farther from the actual executing CPU core. However, despite being located after L1, it has a larger capacity and can store more frequently used data. Similarly, algorithms like LRU will determine which data should be stored in the L2 cache.
If the CPU modifies data, it will first update L1, but these updates will also reflect in L2. We can think of L2 as a buffer for L1; if modifications in L1 are not reflected in L2, then L2 would contain outdated data, which would be useless for the CPU.
L3 Cache
The L3 cache is located between the L2 cache and the main memory. It is a shared cache among multiple cores and their L1 and L2 caches. The L3 cache has the largest capacity of all cache levels but also the highest latency. You can think of it as a backup for L1 and L2 caches. If the required data is not found in either L1 or L2 caches, the search will proceed to the L3 cache.
If the CPU modifies certain data, these changes will also appear in the L3 cache. The L3 cache uses a consistency protocol, allowing all cores to access any data in the cache consistently. Additionally, it can track which core is changing or accessing the data. Similarly, multiple algorithms may run simultaneously to keep the most useful data in the L3 cache.
Cache Thrashing
Cache Thrashing refers to frequent invalidation of the cache, causing the CPU to constantly retrieve data from memory, rendering the cache almost ineffective and actually slowing down performance.
A common example of cache thrashing is the false sharing that occurs in the CPU cache line mechanism. Before delving into false sharing, let’s first explore the cache line mechanism in common CPU architectures.
Cache Line
When the CPU reads data from memory or cache, it does not read a single byte but rather a block of bytes, typically 64 bytes. We refer to this block of bytes as a cache line. Since a cache line consists of multiple bytes, it is likely to store multiple variables.
If the CPU needs to access a variable that has been fetched from the previous cache line, the read speed will be faster. However, because the CPU maintains consistency based on cache lines, if any byte within a cache line changes, all cache lines will be invalidated, affecting all CPUs in the cluster. If different CPUs need to process shared variables on the same cache line, cache thrashing will occur, leading to what is commonly referred to as <span>False Sharing</span>.
False Sharing
Using an example from cppreference, as follows:
#include <atomic>
#include <chrono>
#include <cstddef>
#include <iomanip>
#include <iostream>
#include <mutex>
#include <new>
#include <thread>
#ifdef __cpp_lib_hardware_interference_size
using std::hardware_constructive_interference_size;
using std::hardware_destructive_interference_size;
#else
// 64 bytes on x86-64 │ L1_CACHE_BYTES │ L1_CACHE_SHIFT │ __cacheline_aligned │ ...
constexpr std::size_t hardware_constructive_interference_size = 64;
constexpr std::size_t hardware_destructive_interference_size = 64;
#endif
std::mutex cout_mutex;
constexprint max_write_iterations{10'000'000}; // the benchmark time tuning
structalignas(hardware_constructive_interference_size)
OneCacheLiner // occupies one cache line
{
std::atomic_uint64_t x{};
std::atomic_uint64_t y{};
}
oneCacheLiner;
structTwoCacheLiner// occupies two cache lines
{
alignas(hardware_destructive_interference_size) std::atomic_uint64_t x{};
alignas(hardware_destructive_interference_size) std::atomic_uint64_t y{};
}
twoCacheLiner;
inline auto now() noexcept { return std::chrono::high_resolution_clock::now(); }
template<bool xy>
void oneCacheLinerThread()
{
constauto start{now()};
for (uint64_t count{}; count != max_write_iterations; ++count)
if constexpr (xy)
oneCacheLiner.x.fetch_add(1, std::memory_order_relaxed);
else
oneCacheLiner.y.fetch_add(1, std::memory_order_relaxed);
const std::chrono::duration<double, std::milli> elapsed{now() - start};
std::lock_guard lk{cout_mutex};
std::cout << "oneCacheLinerThread() spent " << elapsed.count() << " ms\n";
if constexpr (xy)
oneCacheLiner.x = elapsed.count();
else
oneCacheLiner.y = elapsed.count();
}
template<bool xy>
void twoCacheLinerThread()
{
constauto start{now()};
for (uint64_t count{}; count != max_write_iterations; ++count)
if constexpr (xy)
twoCacheLiner.x.fetch_add(1, std::memory_order_relaxed);
else
twoCacheLiner.y.fetch_add(1, std::memory_order_relaxed);
const std::chrono::duration<double, std::milli> elapsed{now() - start};
std::lock_guard lk{cout_mutex};
std::cout << "twoCacheLinerThread() spent " << elapsed.count() << " ms\n";
if constexpr (xy)
twoCacheLiner.x = elapsed.count();
else
twoCacheLiner.y = elapsed.count();
}
int main()
{
std::cout << "__cpp_lib_hardware_interference_size "
# ifdef __cpp_lib_hardware_interference_size
"= " << __cpp_lib_hardware_interference_size << '\n';
# else
"is not defined, use " << hardware_destructive_interference_size
<< " as fallback\n";
# endif
std::cout << "hardware_destructive_interference_size == "
<< hardware_destructive_interference_size << '\n'
<< "hardware_constructive_interference_size == "
<< hardware_constructive_interference_size << "\n\n"
<< std::fixed << std::setprecision(2)
<< "sizeof( OneCacheLiner ) == " << sizeof(OneCacheLiner) << '\n'
<< "sizeof( TwoCacheLiner ) == " << sizeof(TwoCacheLiner) << "\n\n";
constexprint max_runs{4};
int oneCacheLiner_average{0};
for (auto i{0}; i != max_runs; ++i)
{
std::thread th1{oneCacheLinerThread<0>};
std::thread th2{oneCacheLinerThread<1>};
th1.join();
th2.join();
oneCacheLiner_average += oneCacheLiner.x + oneCacheLiner.y;
}
std::cout << "Average T1 time: "
<< (oneCacheLiner_average / max_runs / 2) << " ms\n\n";
int twoCacheLiner_average{0};
for (auto i{0}; i != max_runs; ++i)
{
std::thread th1{twoCacheLinerThread<0>};
std::thread th2{twoCacheLinerThread<1>};
th1.join();
th2.join();
twoCacheLiner_average += twoCacheLiner.x + twoCacheLiner.y;
}
std::cout << "Average T2 time: "
<< (twoCacheLiner_average / max_runs / 2) << " ms\n\n"
<< "Ratio T1/T2:~ "
<< 1.0 * oneCacheLiner_average / twoCacheLiner_average << '\n';
}
In this example, there are two structures:
- • OneCacheLiner, a structure where the atomic variables
<span>x</span>and<span>y</span>are placed in the same cache line. - • Two threads update
<span>x</span>and<span>y</span>respectively; since they are packed in the same line, false sharing occurs, leading to cache thrashing. - •
<span>TwoCacheLiner</span>structure where<span>x</span>and<span>y</span>are forced apart using<span>alignas(64)</span>, occupying different cache lines. - • Two threads update
<span>x</span>and<span>y</span>respectively; since they are in different cache lines, the threads do not interfere with each other, thus avoiding false sharing.
The output of the above code is as follows:
__cpp_lib_hardware_interference_size = 201703
hardware_destructive_interference_size == 64
hardware_constructive_interference_size == 64
sizeof( OneCacheLiner ) == 64
sizeof( TwoCacheLiner ) == 128
oneCacheLinerThread() spent 517.83 ms
oneCacheLinerThread() spent 533.43 ms
oneCacheLinerThread() spent 527.36 ms
oneCacheLinerThread() spent 555.69 ms
oneCacheLinerThread() spent 574.74 ms
oneCacheLinerThread() spent 591.66 ms
oneCacheLinerThread() spent 555.63 ms
oneCacheLinerThread() spent 555.76 ms
Average T1 time: 550 ms
twoCacheLinerThread() spent 89.79 ms
twoCacheLinerThread() spent 89.94 ms
twoCacheLinerThread() spent 89.46 ms
twoCacheLinerThread() spent 90.28 ms
twoCacheLinerThread() spent 89.73 ms
twoCacheLinerThread() spent 91.11 ms
twoCacheLinerThread() spent 89.17 ms
twoCacheLinerThread() spent 90.09 ms
Average T2 time: 89 ms
Ratio T1/T2:~ 6.16
If you have any questions about this article, feel free to add me on WeChat for direct communication. I have also created a technical group related to C/C++; if you are interested, please contact me to join.
 Recommended Reading Click the title to jump
Recommended Reading Click the title to jump
1. Advanced C++ Programming Techniques: Cache Lines
2. Advanced C++ Optimization: Branch Prediction
3. Discussing Memory Order in C++