(This article is adapted from SemiWiki)
When discussing the bottlenecks faced by Digital Signal Processors (DSPs), the focus often lies on computational throughput—such as the number of Multiply-Accumulate (MAC) operations per second, the width of vector units, and clock frequencies. However, after engaging in-depth discussions with embedded AI engineers focused on real-time voice processing, radar systems, or low-power vision applications, one often uncovers a commonly overlooked critical issue: memory stalls are the real “invisible killer.”
In today’s edge AI and signal processing workload scenarios, DSPs must perform complex tasks such as inference, filtering, and data transformation under extremely stringent power and timing constraints. Despite continuous upgrades to computational cores and efforts in edge computing to reduce the distance between computation engines and memory, advancements in toolchains have not fully resolved the challenges in the memory domain. Memory read/write speeds still struggle to meet demands, and the core contradiction lies not in the performance of memory itself, but in the inability of data to reach computational units in a timely manner at critical junctures, which becomes a major obstacle to the efficient operation of the system.
Why DSPs Are Troubled by Latency Issues
Compared to general-purpose Central Processing Units (CPUs), the DSPs used in embedded AI predominantly rely on non-cacheable memory regions, such as local buffers, registers, and deterministic tightly coupled memory (TCM). This design consideration is quite reasonable: for real-time systems, the uncertainty caused by cache misses or the risks of non-deterministic delays are burdens that cannot be borne. However, this architecture also has drawbacks—every memory access must precisely match the exact loading latency; any deviation can cause the processor pipeline to stall.
In practical applications, when the processor is handling spectral analysis, convolution window operations, or beamforming sequences, if data does not arrive on time, the entire processing flow will be interrupted. The Multiply-Accumulate unit is forced to remain idle, task delays accumulate, leading to a significant reduction in computational efficiency, while power consumption is wasted during the wait, severely impacting overall system performance.
Introducing Predictive Loading Processing
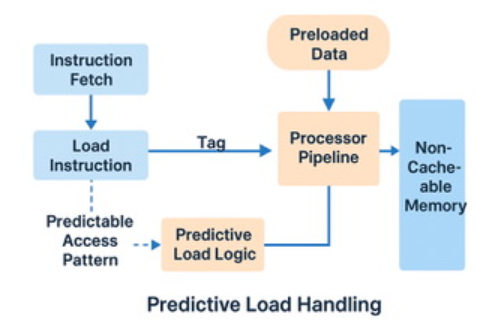
Imagine if a DSP could recognize data access patterns, accurately identify loops that read memory at fixed strides—such as fetching one data point every four addresses—and proactively initiate a “deep prefetch” mechanism, ensuring that data is ready before the actual load instruction is issued. This way, memory stalls and pipeline bubbles would cease to exist, and instruction execution would proceed smoothly without interruption.
This is precisely the goal pursued by traditional prefetch models or stride-based streaming technologies. Although these techniques have been widely applied with significant results, they are not the core focus of this article.
A groundbreaking predictive loading processing technology is revolutionizing traditional perceptions with a new paradigm. This is not merely an upgrade of prefetch technology, but a fundamental technological innovation. Unlike traditional methods that aim to predict the next access address, predictive loading processing takes a different approach, focusing on the time dimension of memory access, specifically accurately estimating the duration required for each data retrieval.
This technology continuously tracks the latency data of historical loading operations, whether it be Static Random Access Memory (SRAM), cache bypass operations, or Dynamic Random Access Memory (DRAM) accesses, accurately grasping the typical response times of memory requests across various storage areas. The Central Processing Unit (CPU) does not need to pre-issue load instructions but maintains a regular operational rhythm. By applying latency predictions to vector operations, it schedules operation execution based on predicted times, allowing the processor to adapt to memory timing without altering the instruction flow. This mechanism does not rely on speculative predictions and carries no additional risks, perfectly aligning with the pipeline architecture of deterministic DSPs through a conservative and robust strategy. This technology’s advantages are particularly evident when processing large AI models stored in DRAM or frequently reading and writing temporary buffers, as the latency in these scenarios, while stable, is relatively long.
This distinction is crucial. We are not merely performing smarter prefetch operations; we are enabling the processor to perceive latency and adapt its timing arrangements, regardless of the presence or absence of traditional caches or stride patterns.
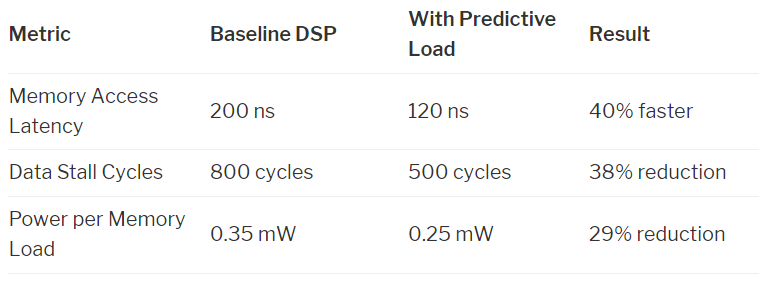
When predictive loading processing is integrated into the general DSP pipeline, it can immediately yield measurable performance improvements and reduced power consumption. The table below illustrates the performance in typical AI/DSP scenarios. These data reflect the expected efficacy in the following workloads:
-
Convolution operations on image blocks
-
Sliding Fast Fourier Transform (FFT) window operations
-
Inference of AI models on quantized inputs
-
Filtering or decoding streaming sensor data
Minimal Cost, Maximum Impact
One of the core advantages of predictive loading processing is its non-intrusive nature. This technology does not require complex deep reordering logic, cache controllers, nor does it rely on heavy speculative mechanisms, allowing it to flexibly integrate into numerous DSPs. Whether as a dedicated logic module or through compiler-assisted prefetch tags, it can seamlessly embed into the instruction dispatch or load decode stages. Importantly, its deterministic operational mode fully aligns with functional safety standards, including the ISO 26262 standard, making it uniquely adaptable in safety-critical fields such as automotive radar, medical diagnostics, and industrial control systems.
Revisiting the AI Data Pipeline
Predictive loading processing reveals an important trend: enhancing computational efficiency is not only about strengthening mathematical computation capabilities but also about ensuring that data is ready in a timely manner. As the gap between processor speeds and memory latencies—the “memory wall”—continues to widen, future efficient processor architectures will no longer solely pursue faster core computation speeds. Instead, they will rely on smarter data transfer paths to achieve precise and timely information delivery, thereby eliminating the critical bottlenecks that lead to idle high-performance CPUs. As DSPs increasingly become the mainstay of edge AI computation, we firmly believe that predictive loading processing will become a hallmark technological feature of the next generation of signal processing cores.
After all, in the realm of data processing, sometimes the key to system performance is not clock speed, but the response latency of data.
END