
The risks of distributed storage actually arise from the contradictions between “sharing”, “large data volumes”, “high performance”, and the use of X86 servers with cheap disks as carriers. This is not an issue of “data architecture” as some readers claim. In fact, any storage has this problem, but it is more severe in distributed storage.
This article analyzes the existing risks from the perspective of network and disk throughput of the host, so it is unrelated to which manufacturer’s storage is used.
Some people say you are alarmist. If what you say is true, wouldn’t so many people using distributed storage blow up with such landmines? Software-defined solutions actually have many bugs; the important thing is to identify problems and prepare remedies or plans in advance.
Others argue that distributed storage has only been used for less than two years, and the issues you mention are premature. However, we have already identified problems that cannot be ignored. The Diaoyu Islands issue was postponed, and hasn’t it caused trouble now?

To provoke thought, what is the most important metric for storage?
Many people, including storage experts, believe it is performance metrics like IOPS and throughput. However, I think the most important aspect of storage is data security.
What would happen if a fast storage suddenly lost data? Data loss is a disaster for any system.
Therefore, regardless of the type of storage, data security and reliability are paramount.
Traditional storage used dedicated hardware, which provided a higher reliability guarantee, so people primarily focused on performance metrics. However, the reliability of X86-based SRVSAN is not optimistic.
Why is this issue not particularly prominent in traditional storage?
Besides dedicated devices, there are also different application scenarios and data volumes. In traditional industries like telecommunications and banking, the original system construction was siloed. Not only was the network a standalone setup, but the storage was as well.
Typically, there were database services and log records using two servers connected by eight ports of a small optical switch, with only one storage attached to the small optical switch. The data volume was not that large, and the storage capacity was below 5TB. Therefore, data migration was easy and fast, with many methods available.
Since it was dedicated storage, it could completely adopt “offline” methods, and with a small data volume, it could be completed during quiet hours.
Entering the era of cloud computing, storage is shared, data is application-reliable, providers are uncontrollable, and data volume has massively increased… Traditional methods have failed. (See Guo Jiong’s article on the “Storage Characteristics of Resource Pools in the Cloud World”)
In the second half of 2014, we began building distributed block storage based on X86, which underwent strict testing and was commercially launched by the end of that year, making it the industry’s first commercially available software-defined distributed storage, widely reported by various media.
To date, it has been commercially used for nearly two years, with stable storage operation and excellent performance. It has expanded from the original 2P raw capacity to 4.5P.
However, recently I have been increasingly worried because the inherent data security risks of SRVSAN have been ignored, and mainstream manufacturers have not recognized this issue. If this risk explodes in several years, it could cause significant system failures.
In fact, two months before writing this article, I had already shared my concerns and thoughts with the general manager of the existing distributed block storage product line, who took it seriously and has been addressing it. Many software-defined solutions fear the unforeseen, which suddenly occurs; if anticipated, corresponding solutions can be prepared.
Most readers are not too familiar with storage, so I will start with some basic knowledge and lead into problems for discussion and solutions. I have roughly divided it into seven parts, but due to space limitations, I will first introduce the first three parts:
-
1. Types of Storage
-
2. File Systems
-
3. Storage Media
-
4. RAID and Replication
-
5. SRVSAN Architecture
-
6. Security Risks of SRVSAN
-
7. Solutions
1. Types of Storage
Generally, we classify storage into four types: DAS based on local machines, NAS storage over networks, SAN storage, and object storage. Object storage is a product of combining SAN and NAS storage, drawing advantages from both.
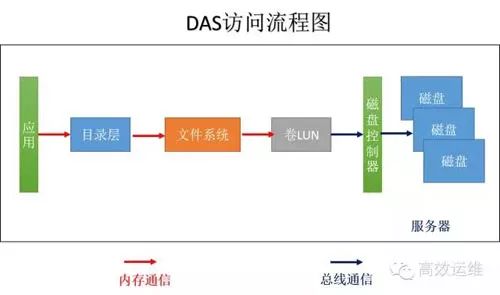
Figure 1
Let’s understand how an application retrieves a file’s information stored in storage, using Windows as an example, as shown in Figure 1.
1. The application issues a command to “read the first 1K data of the readme.txt file in this directory”.
2. Through memory communication to the directory layer, it converts the relative directory to the actual directory, “read the first 1K data of C:\ test\readme.txt”.
3. Through the file system, such as FAT32, it queries the file allocation table and directory entries to obtain the LBA address location, permissions, etc. of the file storage.
The file system first checks if the data is available in the cache; if so, it returns the data directly; if not, the file system communicates via memory to the next step with the command “read information starting from LBA1000, length 1024”.
4. The volume (LUN) management layer translates the LBA address into the physical address of the storage and encapsulates the protocol, such as SCSI, for the next step.
5. The disk controller retrieves the corresponding information from the disk based on the command.
If the disk sector size is 4K, the actual data read in one I/O operation is 4K. When the read head retrieves the 4K data, the file system captures the first 1K of data and passes it to the application. If the application makes the same request next time, the file system can read it directly from the server’s memory.
Whether DAS, NAS, or SAN, the data access process is quite similar. DAS integrates computing and storage capabilities within a single server. A common personal computer is a DAS system, as shown in Figure 1.
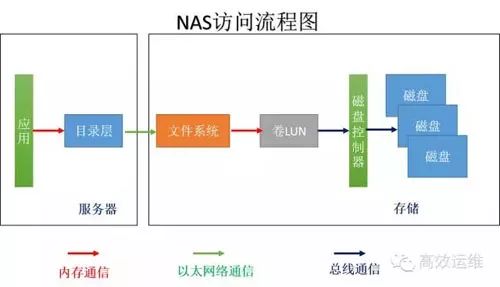
Figure 2
If computing and storage are separated, with storage becoming an independent device that manages its own file system, it is called NAS, as shown in Figure 2.
Typically, computing and storage communicate over Ethernet using CIFS or NFS protocols. Servers can share a file system, meaning that regardless of whether the server speaks Shanghai dialect or Hangzhou dialect, the network connection to the NAS file system translates it into Mandarin.
Thus, NAS storage can be shared by different hosts. Servers only need to make requests without doing extensive calculations, delegating much work to storage, freeing up CPU resources for other computing-intensive tasks suitable for NAS.
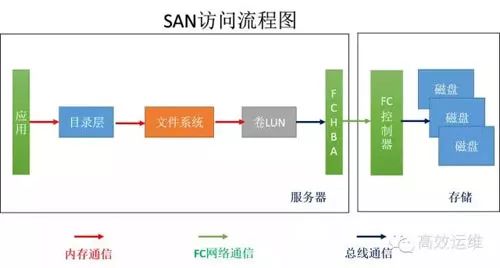
Figure 3
When computing and storage are separated, with storage becoming an independent device that only accepts commands without complex calculations, it is referred to as SAN, as shown in Figure 3.
Since it does not have a file system, it is also called “raw storage”. Some applications require raw devices, such as databases. Storage only accepts clear and straightforward commands; other complex tasks are handled by the server side. Coupled with FC networks, this type of storage offers high data read/write speeds.
However, each server has its own file system for management, and for storage, it does not discriminate as long as data arrives, it will store it without needing to know what it is, whether it is English or French, it will faithfully record it.
However, only those who understand English can read English data, and those who understand French can read French data. Therefore, generally, the relationship between servers and SAN storage is one-to-one, and SAN’s shareability is poor. Of course, some hosts with cluster file systems can share the same storage area.
From the above analysis, we know that the speed of storage is determined by the network and the complexity of the commands.
Memory communication speed > Bus communication > Network communication
Among network communications, there are FC networks and Ethernet networks. FC networks can currently achieve 8Gb/s, but Ethernet networks have popularized 10Gb/s and 40Gb/s network cards through fiber optics. This means that traditional Ethernet networks are no longer a bottleneck for storage. In addition to FCSAN, IPSAN is also an important member of SAN storage.
In terms of storage operations, besides the familiar read/write, there are also create, open, get attributes, set attributes, find, etc.
For intelligent SAN storage, commands other than read/write can be completed in local memory, making it extremely fast.
NAS storage lacks intelligence; each time a command is passed to storage, it must be encapsulated in an IP packet and transmitted over Ethernet to the NAS server, which is significantly slower than memory communication.
-
DAS is the fastest but can only be used by itself;
-
NAS is slower but has good shareability;
-
SAN is fast but has poor shareability.
Overall, object storage combines the high-speed direct access characteristics of SAN and the distributed sharing characteristics of NAS.
The basic unit of NAS storage is a file, the basic unit of SAN storage is a data block, while the basic unit of object storage is an object, which can be viewed as a combination of file data and a set of attribute information. This attribute information can define RAID parameters based on files, data distribution, quality of service, etc.
The approach separates “control information” from “data storage”. The client uses an object ID and offset as the basis for reading and writing, first obtaining the real address of the data storage from “control information” before directly accessing “data storage”.
Object storage is widely used on the internet; the cloud storage services we use are typical examples of object storage. Object storage has excellent scalability and can be expanded linearly. It can be encapsulated through interfaces and can also provide NAS and SAN storage services.
VMware’s vSAN is essentially an object storage. Distributed object storage is a type of SRVSAN, which also has security risks due to the inherent issues brought by X86 servers.
2. File Systems
A computer’s file system is the “accountant” managing files.
-
First, it must manage the warehouse and know where various goods are stored;
-
Then it must control the entry and exit of goods and ensure their safety.
If there is no “accountant” to manage the warehouse and allow every “worker” to freely enter and exit, it would lead to chaos and loss of goods.
For example, when the young spinning city machine room was just put into use, everyone’s goods were piled up in the machine room without any unified management. When equipment needed to be shelved, one had to search through a large pile of goods, and after installation, no one cleaned up the garbage, leading to a situation where one couldn’t even find a place to pile things, and sometimes one’s own goods were lost, while others’ were used instead…
Everyone complained, and later a warehouse was established, and a warehouse manager was hired to keep records of the goods’ whereabouts and storage locations, establishing a system for goods’ entry and exit, solving the problems. This is what a file system is supposed to do.
The file system manages interfaces for file access, organizes and allocates file storage, and manages file attributes (like ownership, permissions, creation events, etc.).
Every operating system has its own file system. For example, Windows commonly uses FAT, FAT32, NTFS, while Linux uses ext1-4, etc.
There are many forms of storage for files, with the most commonly used being (mechanical) disks, SSDs, CDs, tapes, etc.
After obtaining these media, the first step is “formatting”, which is the process of establishing a file storage organizational structure and an “account book”. For example, formatting a USB drive with FAT32, we can see the structure and account book as shown in Figure 4:

Figure 4
The Master Boot Record: records the overall and basic information of this storage device, such as sector size, cluster size, number of heads, total number of disk sectors, number of FAT tables, partition boot code, etc.
The partition table: is the “account book” of this storage; if the partition table is lost, it means data loss. Therefore, generally, two copies are kept, namely FAT1 and FAT2. The partition table mainly records the usage of each cluster; when a cluster is empty, it indicates it has not been used yet, while a special mark indicates a bad cluster, and a position with data indicates the next position of the file block.
The directory area: contains directory and file location information.
The data area: the area that records specific file information.
To help understand what a FAT file system is, consider the following example.
Assuming each cluster is made up of 8 sectors, with a size of 512*8=4K. The readme.txt file in the root directory is 10K, as shown in Figure 5:
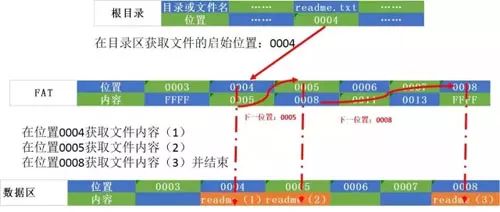
Figure 5
-
1. In the directory area, find the location of the readme.txt file in the FAT table, which is 0004
-
2. At location 0004, read the corresponding cluster’s 8 sectors to obtain the file block readme(1) into memory and get the next data block’s location 0005.
-
3. At location 0005, read the corresponding cluster’s 8 sectors to obtain the file block readme(2) into memory and get the next data block’s location 0008.
-
4. At location 0005, read the corresponding cluster’s 4 sectors to obtain the file block readme(3) into memory and receive an end flag.
-
5. Combine readme(1), readme(2), and readme(3) into the readme file.
In this example, we see that in the FAT file system, the storage location of the file is determined by querying the FAT table and directory entries. The file distribution is in data blocks measured in clusters, indicated by a “chain” to show where the file data is stored.
When reading a file, it must start from the file head. This method is not very efficient.
Different Linux file systems are generally similar, often adopting the ext file system, as shown in Figure 6.
 Figure 6
Figure 6
The boot block is used for server booting; even if this partition is not a boot partition, it is retained.
The superblock stores relevant information about the file system, including the file system type, number of inodes, number of data blocks.
The inodes block stores the inode information of files, with each file corresponding to one inode. It contains metadata about the file, specifically including the following:
The number of bytes in the file
The User ID of the file owner
The Group ID of the file
The read, write, and execute permissions of the file
The timestamp for the file, which includes three: ctime (the last time the inode was modified), mtime (the last time the file content was modified), and atime (the last time the file was accessed).
The link count, which indicates how many file names point to this inode
The location of the file data block
When checking a directory or file, the system first queries the inode table to retrieve file attributes and data storage points, then reads data from the data blocks.
The data blocks store directory and file data.
To understand the process of reading the \var\readme.txt file in the ext file system, see Figure 7.
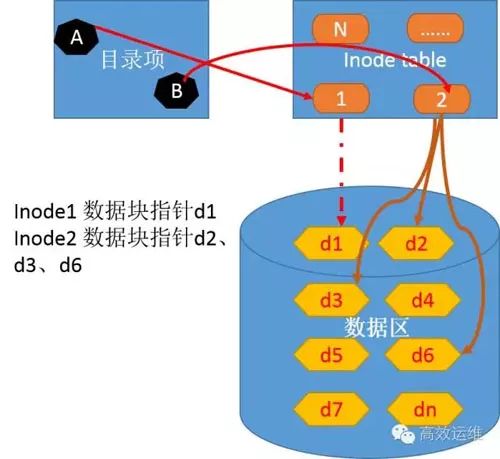 Figure 7
Figure 7
-
1. The inode node corresponding to the root directory A is 2, and inode 1 corresponds to data block d1.
-
2. Retrieving d1 content reveals that the directory var corresponds to inode 28, which points to data block d5.
-
3. Retrieving d5 content reveals that readme.txt corresponds to inode 70.
-
4. Inode 70 points to data blocks d2, d3, and d6. Read these data blocks and combine d2, d3, and d6 data blocks into memory.
When formatting a hard disk, the operating system automatically divides it into two areas:
-
One is the data area, where file data is stored;
-
The other is the inode area, where inode information is stored.
When inode resources are exhausted, even if there is still free space in the data area, new files cannot be written.
In summary, Windows file systems tend to be “serial”, while Linux file systems are “parallel”.
Now let’s look at distributed file systems.
If the persistent storage layer is not a single device but multiple devices connected via a network, data is dispersed across multiple storage devices. This means the metadata not only records which block number is used but also which data node it belongs to.
Thus, metadata must be stored on each data node and must be synchronized in real-time. Achieving this is quite difficult. If we separate the metadata server and establish a “master-slave” architecture, it eliminates the need to maintain metadata tables on each data node, simplifying data maintenance and improving efficiency.
The Hadoop file system, HDFS, is a typical distributed file system.
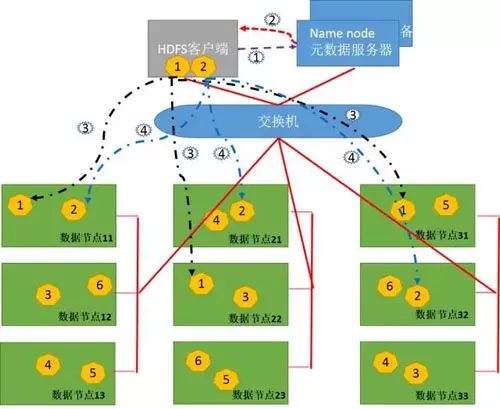
Figure 8
-
1. The client divides FileA into blocks of 64M, resulting in two blocks: block1 and block2.
-
2. The client sends a write data request to the nameNode, as shown by the purple dotted line 1.
-
3. The nameNode records block information and returns available DataNodes to the client, as shown by the red dotted line 2.
Block1: host11, host22, host31
Block2: host11, host21, host32
-
4. The client sends block1 to DataNode; the sending process is streamed.
Streaming write process:
1) The 64M block1 is divided into packages of 64k;
2) The first package is sent to host11;
3) After host11 receives the first package, it sends it to host22, while the client sends the second package to host11;
4) After host22 receives the first package, it sends it to host31, while receiving the second package from host11;
5) This continues as shown by the black dotted line 3 until block1 is fully sent;
6) Host11, host22, and host31 notify the NameNode and Client that “the message has been sent”;
7) After the client receives the notification, it informs the namenode that it has finished writing. Thus, it is complete;
8) After sending block1, the client sends block2 to host11, host21, and host32, as shown by the blue dotted line 4.
…
HDFS is the prototype of distributed storage, which will be detailed in future discussions.
3. Storage Media
There are many types of storage media, with disks and SSDs being the most commonly used today, along with CDs, tapes, etc. Disks have long dominated due to their cost-performance advantage.
Round magnetic disks are housed in a square sealed box, making a screeching sound when running; this is the common disk we encounter. The disk is the medium that actually stores data, with magnetic heads “floating” above each side of the disk.
The disk is divided into many concentric circles, each called a track, and each track is further divided into small sectors, with each sector capable of storing 512B of data. The magnetic head moves rapidly across the disk to read or write data.
In fact, the disk spins rapidly while the head moves laterally. The main factors determining disk performance are the rotational speed of the disk, the head’s seek time, the capacity of each disk, and the interface speed. The higher the rotational speed, the shorter the seek time, and the larger the single disk capacity, the better the disk performance.

Figure 9

Figure 10
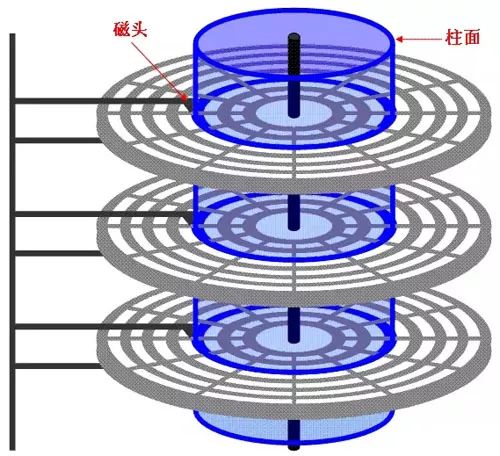
Figure 11
The performance of disks is mainly measured by IOPS and throughput.
IOPS refers to how many read/write operations the disk performs in one second.
Throughput refers to how much data is read.
In fact, these metrics should have prerequisites, such as whether it is large packets (blocks) or small packets (blocks), whether it is read or written, and whether it is random or sequential. Generally, the IOPS performance of disks provided by manufacturers refers to small packet sequential read tests. This metric usually represents the maximum value.
Currently, the performance of SATA and SAS disks commonly used on X86 servers is as follows:

Figure 12
In actual production, it is estimated that a SATA 7200 RPM disk provides approximately 60 IOPS and a throughput of 70MB/s.
In 2014, we first used a 2P raw capacity SRVSAN storage data persistence layer consisting of 57 X86 servers, each with 12 SATA7200 3TB disks. A total of 684 disks provided approximately 41040 IOPS and 47.88GB/s.
These metrics clearly do not meet storage needs, and we need to find ways to “accelerate”.
Mechanical disks have also undergone many optimizations, such as non-contiguous sector addressing.
Because the disks spin fast (7200 RPM means 120 revolutions per second, with one revolution taking 8.3 milliseconds, meaning that the maximum delay when reading/writing the same track is 8.3 seconds), to prevent the read head from missing the read/write, the sector addresses are not continuous but are jump-numbered, such as a 2:1 crossover factor (1, 10, 2, 11, 3, 12, …).
At the same time, disks also have caches and queues; they do not read/write one I/O at a time, but accumulate a certain amount of I/O and complete them based on the position of the head and algorithms. I/O is not necessarily “first come, first served”, but follows efficiency.
The best way to accelerate is to use SSDs. The control part of the disk consists of mechanical parts and control circuits, and the speed limitations of mechanical parts prevent significant breakthroughs in disk performance. SSDs, which use fully electronic control, can achieve excellent performance.
SSDs use flash memory as the storage medium, combined with appropriate control chips. Currently, there are three types of NAND Flash used to produce solid-state drives:
-
Single-level cell storage (SLC, stores 1bit of data)
-
Multi-level cell storage (MLC, stores 4bits of data)
-
Triple-level cell storage (TLC, stores 8bits of data)
SLC has the highest cost and longest lifespan but the fastest access speed, while TLC has the lowest cost, shortest lifespan, but the slowest access speed. To reduce costs, enterprise-level SSDs used in servers generally use MLC, while TLC can be used for USB drives.

Figure 13
There are still some barriers to the widespread adoption of SSDs, such as high costs, write cycle limitations, irretrievability upon failure, and performance degradation as the number of writes increases or as the drive approaches full capacity.
The minimum I/O unit for disks is a sector, while for SSDs, it is a page.
For example, each page stores 512B of data and 218B of error correction code; 128 pages form a block (64KB), and 2048 blocks form an area, with one flash memory chip consisting of two areas. The larger the page size, the greater the capacity of the flash memory chip.
However, SSDs have a bad habit of affecting an entire block when modifying data in a single page. This requires reading the entire block of data containing the page into the cache, initializing the block to 1, and then writing the data back from the cache.
For SSDs, speed may not be an issue, but the number of writes is limited, so larger blocks are not always better. Of course, similar problems exist for mechanical disks; larger blocks lead to faster read/write speeds, but also result in greater waste, as even a partially filled block occupies a full block’s space.
The performance of SSDs varies significantly among different models and manufacturers. Below are the parameters of the SSDs used as cache in our distributed block storage:
Using PCIe 2.0 interface, capacity is 1.2T, overall read/write IOPS (4k small packets) is 260000 times, read throughput is 1.55GB/s, write throughput is 1GB/s.
In one SRVSAN server, a single SSD is configured as cache along with 12 SATA7200 3T disks, where the disks only provide 1200 times and 1200M of throughput.
This is far less than the capabilities provided by the cache SSD, so accessing the cache directly can provide very high storage performance; the key to SRVSAN is calculating the algorithm for hot data to improve the hit rate of hot data.
Using high-cost SSDs as cache and cheap SATA disks as the capacity layer.


◐◑ Major | The Ministry of Industry and Information Technology Issues the “Industrial Internet Development Action Plan (2018-2020)” and the “2018 Work Plan of the Industrial Internet Special Working Group”
◐◑ Central United Front Work Department Research Group Visits Unique Network for Guidance
◐◑ Yixun Smart Analysis Platform Launched, Easily Solving Smart Management Challenges
◐◑ Black Technology from Russia: Blockchain Fog Computing Platform Launching This Summer
◐◑ Exploring Sigfox, LoRa, and NB-IoT Wireless Transmission Technologies in the Internet of Things Era
WeChat Editor | Liu Chunfang Zhang Wenjuan