1. Block Overview
A significant innovation of vLLM is the division of the physical layer GPU and CPU available memory into several blocks, which effectively reduces memory fragmentation issues. Specifically, vLLM’s blocks are divided into logical and physical levels, with a mapping relationship between the two. The following diagram explains the relationship between the two levels of blocks.
Assuming each block can store kv cache data for 4 tokens. The tokens of a sentence are adjacent at the logical level, and each time a new token is generated during decoding, it is placed into an available block. However, at the physical level, the tokens of a sentence may be distributed across non-adjacent blocks, but this is not a problem; vLLM records the mapping relationship between the logical and physical blocks for each token in a sentence, facilitating lookup and reading.
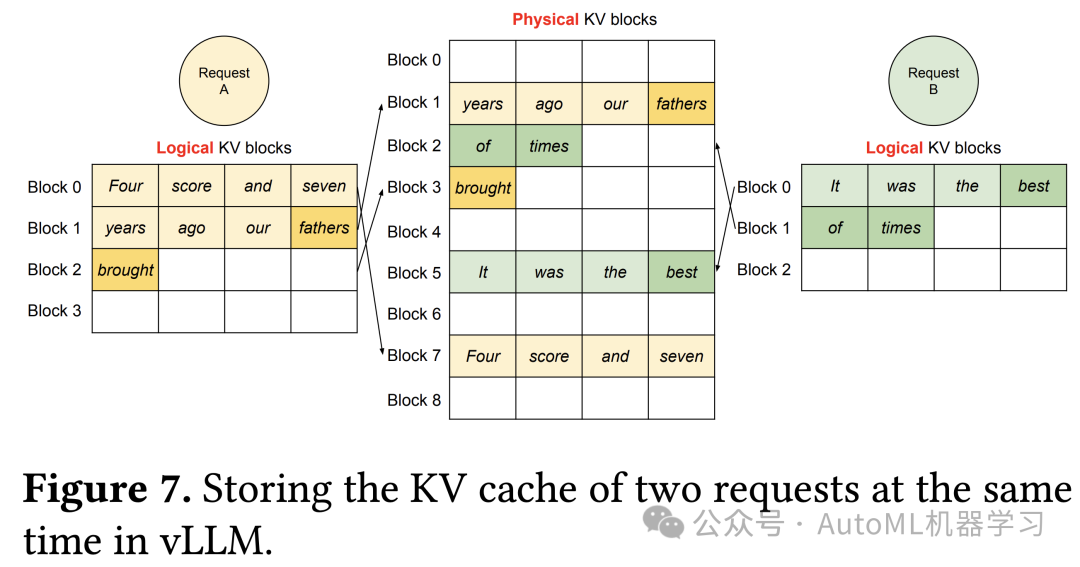
Next, we will detail the significance of block size, how the number of blocks is calculated, and finally introduce how vLLM manages blocks.
2. How to Calculate Block Size
The size of a block can be customized; defined above as 4, it simply means that each block can store a maximum of 4 tokens’ kv cache data. But when the block is set to 4, what is the corresponding size in GPU memory? This is actually easy to calculate,
Memory size occupied by a block (Byte) = Number of tokens (block_size) ✖️ Memory size occupied by a single token’s kv cache.
Therefore, we only need to calculate the size corresponding to a single token’s kv cache. The method for calculating block size is implemented in the vllm/vllm/worker/cache_engine.py file in the CacheEngine class’s get_cache_block_size function, and the code is quite simple, simplified as follows:
# vllm/vllm/worker/cache_engine.py
class CacheEngine:
@staticmethod
def get_cache_block_size(
block_size: int,
cache_dtype: str,
model_config: ModelConfig,
parallel_config: ParallelConfig,
) -> int:
head_size = model_config.get_head_size()
num_heads = model_config.get_num_kv_heads(parallel_config)
num_layers = model_config.get_num_layers(parallel_config)
key_cache_block = block_size * num_heads * head_size
value_cache_block = key_cache_block
total = num_layers * (key_cache_block + value_cache_block)
if cache_dtype == "auto":
dtype = model_config.dtype
else:
dtype = STR_DTYPE_TO_TORCH_DTYPE[cache_dtype]
dtype_size = _get_dtype_size(dtype)
return dtype_size * total
In the code above, we first obtain the values of num_heads and head_size, where num_heads * head_size represents the parameter amount required for a single token in a single layer of the multi-head attention mechanism calculation, but this only accounts for the parameter amount occupied by the key or value cache.
The memory occupied by a block = Number of tokens (block_size) ✖️ Number of layers (num_layers) ✖️ Memory occupied by a single layer kv cache (2✖️num_heads✖️head_size) ✖️ Size of data type (if it is fp16, then each data occupies 2 Bytes).
For example, assuming block_size=4, num_layers=4, num_heads=8, head_size=128, and using fp16 to store data, then
The memory size occupied by one block = 4 ✖️ 4 ✖️ 8 ✖️ 128 ✖️ 2 = 32,768 Bytes.
In summary, the memory size occupied by one block is the total memory occupied by the kv cache of block_size tokens. Different models have different block sizes.
3. How to Calculate Number of Blocks
The calculation of the number of blocks is implemented in the vllm/vllm/worker/worker.py file in the Worker class’s profile_num_available_blocks function, which is quite simple; the simplified code is as follows:
class Worker
@torch.inference_mode()
def profile_num_available_blocks(
self,
block_size: int,
gpu_memory_utilization: float,
cpu_swap_space: int,
cache_dtype: str,
) -> Tuple[int, int]:
torch.cuda.empty_cache()
# This line actually runs a forward pass with simulated data to record GPU usage
self.model_runner.profile_run()
torch.cuda.synchronize()
free_gpu_memory, total_gpu_memory = torch.cuda.mem_get_info()
peak_memory = total_gpu_memory - free_gpu_memory
cache_block_size = CacheEngine.get_cache_block_size(
block_size, cache_dtype, self.model_config, self.parallel_config)
num_gpu_blocks = int(
(total_gpu_memory * gpu_memory_utilization - peak_memory) //
cache_block_size)
num_cpu_blocks = int(cpu_swap_space // cache_block_size)
num_gpu_blocks = max(num_gpu_blocks, 0)
num_cpu_blocks = max(num_cpu_blocks, 0)
if self.model_runner.lora_manager:
self.model_runner.remove_all_loras()
gc.collect()
torch.cuda.empty_cache()
return num_gpu_blocks, num_cpu_blocks
The entire function logic is quite clear; simply understand that it first runs a forward pass with simulated data to record the GPU usage, allowing it to know the peak memory, then calculates the memory needed for each block, after which it can calculate the number of blocks. Specifically:
-
Line 13: vLLM defaults to using 256 sentences for profiling, each sentence being 128 tokens long. -
Lines 15 to 17: Statistics on GPU memory usage, returning values in bytes (Byte), and subsequent calculations are also based on bytes. -
Line 19: Calculate the size of each block, which has been introduced previously. -
Lines 20-23: Calculate the number of available GPU blocks. num_gpu_blocks = int( (total_gpu_memory * gpu_memory_utilization - peak_memory) // cache_block_size): gpu_memory_utilization: Default value is 0.9, indicating that the GPU memory utilization is 90%, which is quite high. Therefore, the final number of available GPU blocks equals the remaining GPU memory size divided by the size of each block. -
Line 24: Calculate the number of available CPU blocks. num_cpu_blocks = int(cpu_swap_space // cache_block_size)Here, cpu_swap_space represents the CPU swap space size corresponding to each GPU, measured in GB, with a default of 4. This means that each GPU corresponds to 4 GB of CPU swap space.
3. How are Blocks Managed?
3.1 Definition and Use of Logical Blocks
Logical Block (LogicalTokenBlock) is defined as follows:
# vllm/vllm/block.py
class LogicalTokenBlock:
def __init_(
self,
block_number: int,
block_size: int,
) -> None:
self.block_number = block_number
self.block_size = block_size
self.token_ids = [_BLANK_TOKEN_ID] * block_size
self.num_tokens = 0
def is_empty(self) -> bool:
return self.num_tokens == 0
def get_num_empty_slots(self) -> int:
return self.block_size - self.num_tokens
def is_full(self) -> bool:
return self.num_tokens == self.block_size
def append_tokens(self, token_ids: List[int]) -> None:
assert len(token_ids) <= self.get_num_empty_slots()
curr_idx = self.num_tokens
self.token_ids[curr_idx:curr_idx + len(token_ids)] = token_ids
self.num_tokens += len(token_ids)
def get_token_ids(self) -> List[int]:
return self.token_ids[:self.num_tokens]
def get_last_token_id(self) -> int:
assert self.num_tokens > 0
return self.token_ids[self.num_tokens - 1]
-
block_number: int:This is the index of the PhysicalTokenBlock instance, which can be understood as a flag used to distinguish different blocks. -
block_size: int:Represents how many tokens’ kv cache data a block can store. -
In the __init__function,self.token_idsis initialized as a list of length block_size, all set to -1. New tokens can later be added to this list viaappend_tokens. -
self.num_tokenscounts the number of used tokens, and whenself.num_tokens==block_size, it indicates that this block has been fully utilized.
The logic of using Logical Blocks is to instantiate an object in real-time as needed; if the current LogicalBlock has no remaining space, a new one is instantiated.
In the vLLM usage scenario, LogicalBlock is dynamically created as needed in the Sequence class located in vllm/vllm/sequence.py.
“
The
Sequenceclass has been detailed in a previous article on vLLM 【vLLM Framework Source Code Analysis (I)[1]】; here you only need to know that this class records all information of the entire inference process (prefilling and decoding) for each input sentence.”
We can better understand this by looking at the code as follows:
# vllm/vllm/sequence.py
class Sequence:
def __init__(self, ...):
...
self.logical_token_blocks: List[LogicalTokenBlock] = []
self._append_tokens_to_blocks(prompt_token_ids)
...
def _append_tokens_to_blocks(self, token_ids: List[int]) -> None:
cursor = 0
while cursor < len(token_ids):
if not self.logical_token_blocks:
self._append_logical_block()
last_block = self.logical_token_blocks[-1]
if last_block.is_full():
self._append_logical_block()
last_block = self.logical_token_blocks[-1]
num_empty_slots = last_block.get_num_empty_slots()
last_block.append_tokens(token_ids[cursor:cursor + num_empty_slots])
cursor += num_empty_slots
def _append_logical_block(self) -> None:
block = LogicalTokenBlock(
block_number=len(self.logical_token_blocks),
block_size=self.block_size,
)
self.logical_token_blocks.append(block)
-
In the __init__function,self.logical_token_blocksis initialized as an empty array to storeLogicalBlock. It can be seen that all tokens of the prompt are first stored in blocks via_append_tokens_to_blocks. -
The _append_tokens_to_blocksfunction traverses each token id in the passedtoken_idsarray, storing that token’s information in the LogicalBlock. – Line 12: Ifself.logical_token_blocksis empty, it dynamically calls_append_logical_blockto create aLogicalBlockand stores it inself.logical_token_blocks. – Line 16: If the most recently createdLogicalBlockis full, it similarly calls_append_logical_blockto create a newLogicalBlock.
3.2 Definition and Management of Physical Blocks
The code definition of Physical Block (PhysicalTokenBlock) is as follows:
-
device: Device:This is an instance of enum.Enum, which can be either CPU or GPU. -
self.ref_countvariable indicates how many times this block has been used, defaulting to 0, which means it is not in use. It can be greater than or equal to 1, indicating that the token cache within this block is reused; a usage scenario could be beam search, allowing cache reuse to reduce memory overhead.
# vllm/vllm/block.py
class PhysicalTokenBlock:
def __init_(
self,
device: Device,
block_number: int,
block_size: int,
) -> None:
self.device = device
self.block_number = block_number
self.block_size = block_size
self.ref_count = 0
def __repr__(self) -> str:
return (f'PhysicalTokenBlock(device={self.device}, '
f'block_number={self.block_number}, '
f'ref_count={self.ref_count})')
PhysicalTokenBlock is simply a description of a single block. vLLM implements the BlockAllocator class in the vllm/vllm/core/block_manager.py file to initialize all physical blocks and manage their allocation.
The code for the BlockAllocator class is quite simple, as follows. It mainly has three functions:
-
__init__: Initializes a specified number of physical blocks, which has been described in the previous section on how to calculate. -
allocate: Returns an available block via the list’s pop() function and sets theref_countof that block to 1. -
free: Recovers a specifiedPhysicalBlock, but the premise for recovery is that theref_countof this block must be 0, indicating that the token kv cache data within this block is no longer needed.
# vllm/vllm/core/block_manager.py
class BlockAllocator:
def __init_(
self,
device: Device,
block_size: int,
num_blocks: int,
) -> None:
self.device = device
self.block_size = block_size
self.num_blocks = num_blocks
# Initialize the free blocks.
self.free_blocks: BlockTable = []
for i in range(num_blocks):
block = PhysicalTokenBlock(device=device,
block_number=i,
block_size=block_size)
self.free_blocks.append(block)
def allocate(self) -> PhysicalTokenBlock:
if not self.free_blocks:
raise ValueError("Out of memory! No free blocks are available.")
block = self.free_blocks.pop()
block.ref_count = 1
return block
def free(self, block: PhysicalTokenBlock) -> None:
if block.ref_count == 0:
raise ValueError(f"Double free! {block} is already freed.")
block.ref_count -= 1
if block.ref_count == 0:
self.free_blocks.append(block)
def get_num_free_blocks(self) -> int:
return len(self.free_blocks)
3.3 Block Management and Mapping Module
Before introducing this Block management module, let’s first understand the three states set in vLLM to determine whether a sentence can be allocated a physical Block, as shown in the code below:
# vllm/vllm/core/block_manager.py
class AllocStatus(enum.Enum):
"""Result for BlockSpaceManager.can_allocate
"""
OK = enum.auto()
LATER = enum.auto()
NEVER = enum.auto()
The meanings of the three states are as follows:
-
OK: seq_group can be allocated now. -
LATER: seq_group cannot be allocated. The allocator’s capacity is greater than what seq_group requires. -
NEVER: seq_group can never be allocated. seq_group is too large to allocate in the GPU.
The BlockSpaceManager in vllm/vllm/core/block_manager.py is a high-level memory manager that manages the mapping between logical data blocks and physical memory blocks in memory-intensive computing tasks (especially in large-scale data processing using GPUs and CPUs).
Next, we will introduce some important functions of the BlockSpaceManager with the code.
-
Initialization function __init__: –watermark: A threshold mechanism used to determine when to stop allocating new blocks on the GPU to avoid running out of memory –watermark_blocks: Calculates how many blocks can still be allocated on the GPU before running out of memory. –sliding_window: An optional parameter used to limit the number of active logical blocks at any given time, helping to control memory usage. – Two types ofBlockAllocatorfor CPU and GPU are created, but note that these are all physical-level blocks – A dictionaryblock_tablesis created to store the mapping between each sequence id and the physical blocks it uses. Through this sequence id, we can find the correspondingSequenceinstance, establishing the mapping relationship between logical blocks and physical blocks.
# vllm/vllm/core/block_manager.py
class BlockSpaceManager:
def __init_(
self,
block_size: int,
num_gpu_blocks: int,
num_cpu_blocks: int,
watermark: float = 0.01,
sliding_window: Optional[int] = None,
) -> None:
self.block_size = block_size
self.num_total_gpu_blocks = num_gpu_blocks
self.num_total_cpu_blocks = num_cpu_blocks
self.block_sliding_window = None
if sliding_window is not None:
assert sliding_window % block_size == 0, (sliding_window,
block_size)
self.block_sliding_window = sliding_window // block_size
self.watermark = watermark
assert watermark >= 0.0
self.watermark_blocks = int(watermark * num_gpu_blocks)
self.gpu_allocator = BlockAllocator(Device.GPU, block_size,
num_gpu_blocks)
self.cpu_allocator = BlockAllocator(Device.CPU, block_size,
num_cpu_blocks)
# Mapping: seq_id -> BlockTable.
self.block_tables: Dict[int, BlockTable] = {}
-
can_allocate
class BlockSpaceManager:
def can_allocate(self, seq_group: SequenceGroup) -> AllocStatus:
seq = seq_group.get_seqs(status=SequenceStatus.WAITING)[0]
num_required_blocks = len(seq.logical_token_blocks)
if seq_group.prefix is not None and seq_group.prefix.allocated:
num_required_blocks -= seq_group.prefix.get_num_blocks()
if self.block_sliding_window is not None:
num_required_blocks = min(num_required_blocks,
self.block_sliding_window)
num_free_gpu_blocks = self.gpu_allocator.get_num_free_blocks()
# Use watermark to avoid frequent cache eviction.
if (self.num_total_gpu_blocks - num_required_blocks <
self.watermark_blocks):
return AllocStatus.NEVER
if num_free_gpu_blocks - num_required_blocks >= self.watermark_blocks:
return AllocStatus.OK
else:
return AllocStatus.LATER
The can_allocate method is used to determine whether a sequence group (seq_group) can successfully allocate the required memory blocks. This method first calculates the total number of physical memory blocks required for the logical data blocks of that sequence group based on the current task. It then checks the number of free memory blocks in the GPU allocator to confirm whether there are enough resources to meet the demand.
The concept of watermark_blocks is introduced in this method, primarily to prevent performance degradation caused by frequent cache eviction of memory blocks. In the dynamic environment of model training or data processing, memory demands are continuously changing. If memory blocks have to be frequently evicted and reallocated due to insufficient free memory blocks, it can lead to performance losses. This is because evicted memory blocks are likely to be needed again soon, and the reallocation process consumes additional time and resources.
By setting a threshold for watermark_blocks, when the number of free memory blocks on the GPU falls below this threshold, the system will avoid allocating new memory blocks to leave a buffer zone, reducing the occurrence of cache evictions. New memory block allocations will only continue once the number of free memory blocks exceeds this threshold. This strategy aims to balance memory allocation demands with system performance, avoiding efficiency losses due to frequent memory operations.
If it is determined that the memory blocks required by the sequence group can never be satisfied based on the current resource status, AllocStatus.NEVER is returned, meaning that the sequence group cannot be allocated under current conditions. If it is currently unallocatable but may be in the future, AllocStatus.LATER is returned, indicating that the sequence group is temporarily unallocatable but may be allocatable in the future as system status changes. If there are enough free memory blocks to meet allocation requirements, AllocStatus.OK is returned, indicating that the sequence group can be allocated the required memory immediately.
This method ensures that watermark_blocks effectively avoids frequent cache eviction issues while satisfying memory allocation demands, thereby optimizing overall system performance and resource utilization efficiency.
-
allocateThe code is simplified, but it does not affect understanding.
class BlockSpaceManager:
def allocate(self, seq_group: SequenceGroup) -> None:
seq = seq_group.get_seqs(status=SequenceStatus.WAITING)[0]
num_prompt_blocks = len(seq.logical_token_blocks)
block_table: BlockTable = []
for logical_idx in range(num_prompt_blocks):
block = self.gpu_allocator.allocate()
block.ref_count = seq_group.num_seqs()
block_table.append(block)
for seq in seq_group.get_seqs(status=SequenceStatus.WAITING):
self.block_tables[seq.seq_id] = block_table.copy()
The allocate method is used to allocate memory blocks for a sequence group. It traverses each sequence in the sequence group, allocates enough memory blocks for each sequence, and adds these blocks to the sequence’s block table. At the same time, it updates the sequence’s block table so that these blocks can be accessed correctly during subsequent training processes.
The BlockSpaceManager has many other functions; to avoid redundancy in the article, they will not be detailed here.
There will be a follow-up article on the vLLM scheduling Scheduler module, which will provide a more detailed introduction to BlockSpaceManager. I believe that through this article, you should have a clear understanding of vLLM’s blocks; if you are still unclear, feel free to read it repeatedly until you understand.
References
-
https://zhuanlan.zhihu.com/p/681018057 -
https://zhuanlan.zhihu.com/p/656939628 -
https://zhuanlan.zhihu.com/p/655561941 -
https://zhuanlan.zhihu.com/p/658233994 -
https://zhuanlan.zhihu.com/p/641999400 -
https://zhuanlan.zhihu.com/p/681402162