Practical Notes: Deploying Large Models with vLLM in a Linux Production Environment

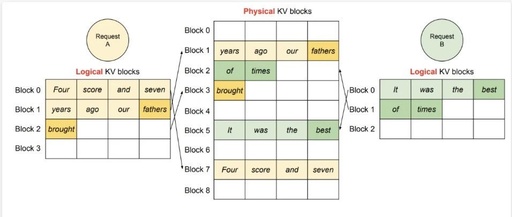
This article is a complete practical record of deploying a local large model using vLLM on a Linux server. On one hand, it serves as a reviewable note for myself, and on the other hand, I hope to help you, who are also experimenting with local large models, to avoid some pitfalls. 1. Overall Approach: … Read more