From: Juejin, Author: Ruheng Link: https://juejin.im/post/6844903490 595061767
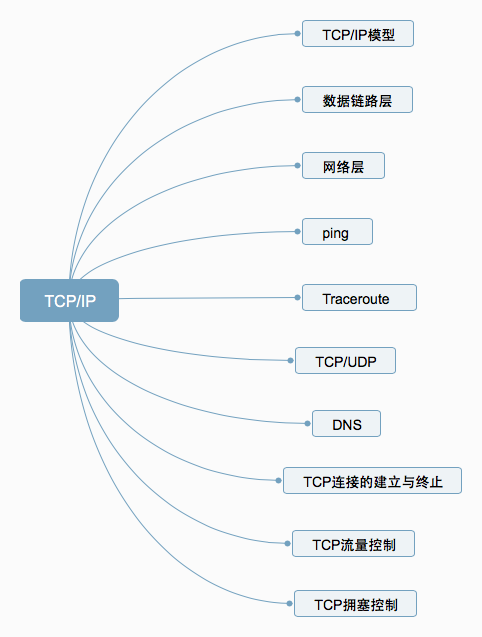
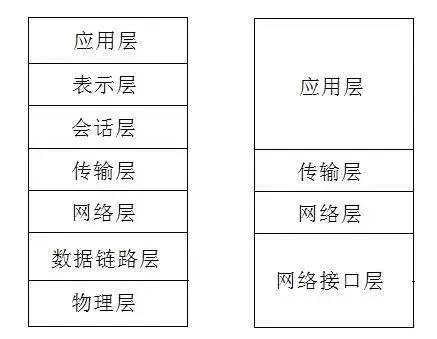
1. TCP/IP Model
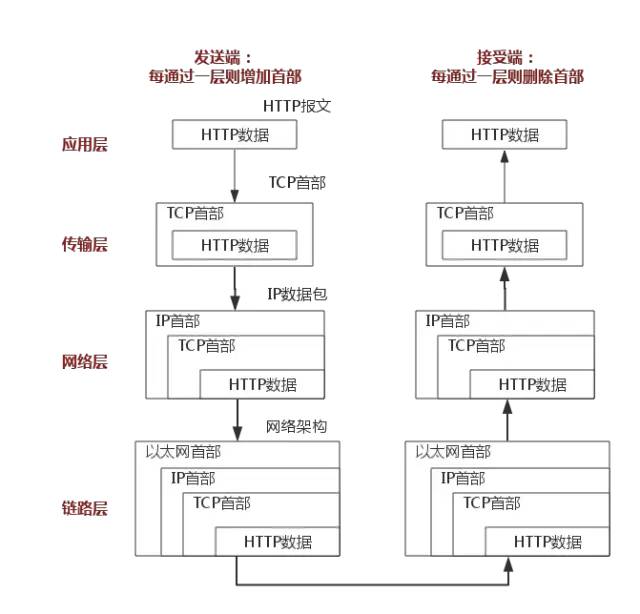
The above example uses the HTTP protocol to illustrate this process in detail.
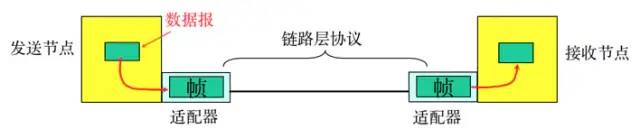
2. Data Link Layer
-
Frame encapsulation: Add headers and trailers to the network layer datagram, encapsulating it into a frame, where the frame header includes the source MAC address and destination MAC address.
-
Transparent transmission: zero-bit padding, escape characters.
-
Reliable transmission: rarely used on low-error-rate links, but wireless links (WLAN) will ensure reliable transmission.
-
Error detection (CRC): The receiver checks for errors, and if an error is detected, the frame is discarded.
3. Network Layer
1. IP Protocol
The IP protocol is the core of the TCP/IP protocol, with all TCP, UDP, ICMP, and IGMP data transmitted in IP data format. It is important to note that IP is not a reliable protocol, meaning it does not provide a mechanism for handling undelivered data, which is considered the responsibility of upper-layer protocols: TCP or UDP.
1.1 IP Address
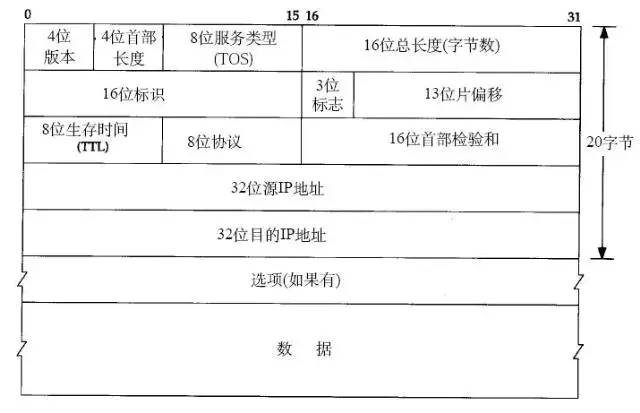
1.2 IP Protocol Header
2. ARP and RARP Protocols
3. ICMP Protocol
The IP protocol is not a reliable protocol; it does not guarantee data delivery. Naturally, the task of ensuring data delivery should be handled by other modules, one of which is the ICMP (Internet Control Message Protocol). ICMP is not a high-level protocol but rather a protocol at the IP layer.
When errors occur in transmitting IP packets, such as host unreachable or route unreachable, the ICMP protocol will encapsulate the error information and send it back to the host, providing an opportunity for the host to handle the error. This is why protocols built on top of the IP layer can potentially achieve reliability.
4. Ping
Ping is arguably the most famous application of ICMP and is part of the TCP/IP protocol. The “ping” command can check whether the network is reachable and is very helpful in analyzing and diagnosing network faults.
For example, when we cannot access a particular website, we usually ping that website. The ping command will echo back some useful information. Generally, the information is as follows:

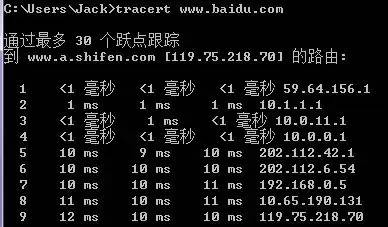
5. Traceroute
Traceroute is an important and convenient tool for detecting the routing situation between the host and the destination host.
The principle of Traceroute is very interesting. After receiving the destination host’s IP, it first sends a UDP packet with TTL=1 to the destination host. The first router that receives this packet automatically reduces the TTL by 1, and when the TTL becomes 0, the router discards the packet and simultaneously generates an ICMP message indicating that the host is unreachable. The host receives this message and then sends a UDP packet with TTL=2 to the destination host, prompting the second router to send an ICMP message back to the host. This process continues until the destination host is reached, allowing Traceroute to obtain all the router IPs along the way.
6. TCP/UDP
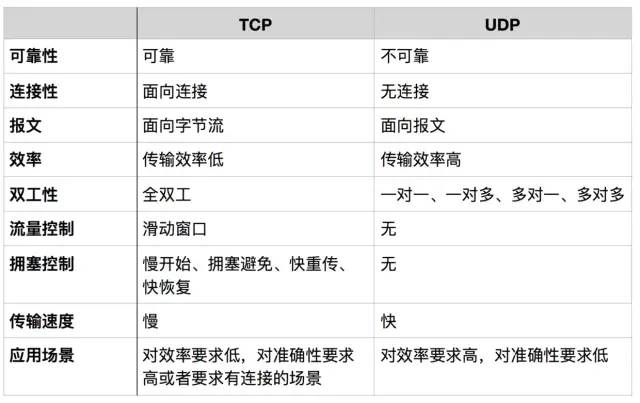
Connection-Oriented
The connection-oriented transmission method allows the application layer to specify the length of the message to UDP, and it sends it as is, meaning one message is sent at a time. Therefore, the application must choose an appropriate message size. If the message is too long, the IP layer must fragment it, reducing efficiency. If it is too short, it may result in IP being too small.
Stream-Oriented
When to Use TCP?
When to Use UDP?
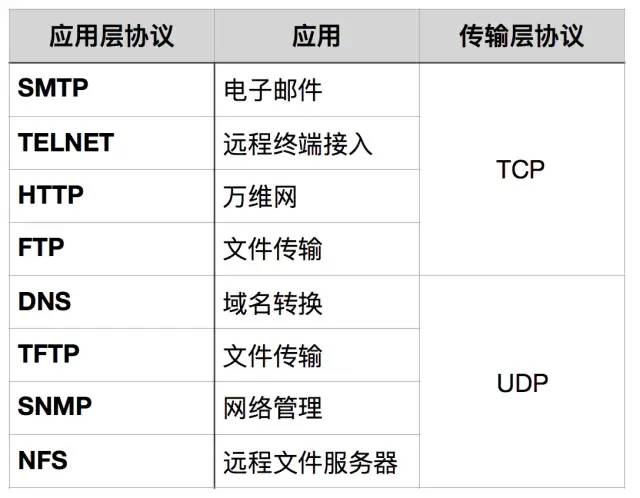
7. DNS
8. Establishing and Terminating TCP Connections
1. Three-Way Handshake
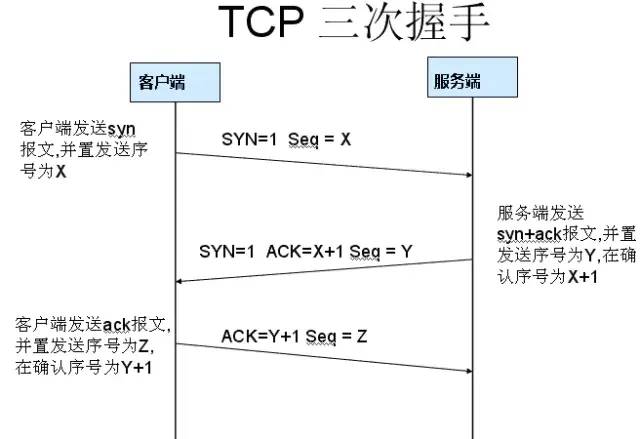
Why Three-Way Handshake?
2. Four-Way Handshake
After the client and server have established a TCP connection through the three-way handshake, once the data transmission is complete, the TCP connection must be terminated. This is where the mysterious “four-way handshake” comes into play.
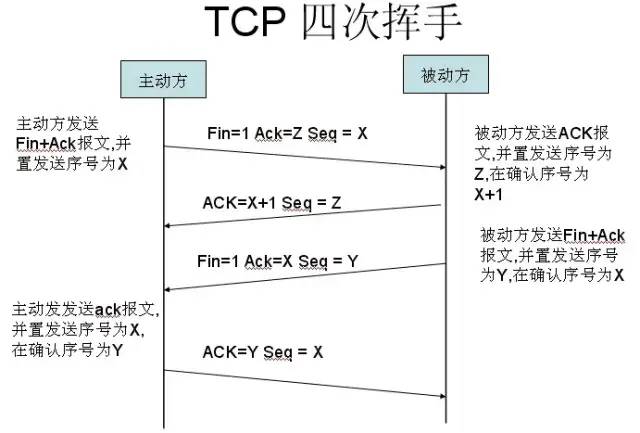
First Handshake: Host 1 (which can be either the client or the server) sets the Sequence Number and sends a FIN segment to Host 2; at this point, Host 1 enters the FIN_WAIT_1 state; this indicates that Host 1 has no data to send to Host 2;
Second Handshake: Host 2 receives the FIN segment sent by Host 1 and sends an ACK segment back to Host 1, with the Acknowledgment Number equal to the Sequence Number plus 1; Host 1 enters the FIN_WAIT_2 state; Host 2 informs Host 1 that it “agrees” to the close request;
Third Handshake: Host 2 sends a FIN segment to Host 1, requesting to close the connection, while Host 2 enters the LAST_ACK state;
Fourth Handshake: Host 1 receives the FIN segment sent by Host 2 and sends an ACK segment back to Host 2; then Host 1 enters the TIME_WAIT state; after Host 2 receives the ACK segment from Host 1, it closes the connection; at this point, Host 1 waits for 2MSL, and if it does not receive a reply, it indicates that the server has closed normally, allowing Host 1 to close the connection as well.
Why Four-Way Handshake?
Why Wait for 2MSL?
MSL: Maximum Segment Lifetime, which is the longest time any segment can exist in the network before being discarded. There are two reasons:
-
To ensure that the TCP protocol’s full-duplex connection can close reliably.
-
To ensure that any duplicate data segments from this connection disappear from the network.
First point: If Host 1 directly goes to CLOSED, then due to the unreliability of the IP protocol or other network reasons, if Host 2 does not receive the last ACK response from Host 1, it will continue to send FIN after a timeout. Since Host 1 has already CLOSED, it will not be able to find a corresponding connection for the retransmitted FIN. Therefore, Host 1 does not directly enter CLOSED but maintains the TIME_WAIT state, allowing it to ensure that it receives the FIN again, thus correctly closing the connection.
Second point: If Host 1 goes directly to CLOSED and then initiates a new connection to Host 2, we cannot guarantee that the new connection will have a different port number than the one that was just closed. This means it is possible for the new connection and the old connection to have the same port number. Generally, this will not cause issues, but special cases can occur: if the new connection and the old closed connection have the same port number, and some delayed data from the previous connection arrive at Host 2 after the new connection is established, since the TCP protocol considers the delayed data as belonging to the new connection, it can confuse the data packets of the new connection. Therefore, TCP connections must wait in the TIME_WAIT state for 2MSL to ensure that all data from this connection disappears from the network.
9. TCP Flow Control
If the sender sends data too quickly, the receiver may not be able to keep up, leading to data loss. Flow control ensures that the sender’s rate does not exceed the receiver’s capacity.
Using the sliding window mechanism allows for easy implementation of flow control on a TCP connection.
Assume A sends data to B. During the connection establishment, B informs A: “My receive window is rwnd = 400” (where rwnd represents receiver window). Thus, the sender’s sending window cannot exceed the value provided by the receiver. Note that TCP’s window is measured in bytes, not segments. Assume each segment is 100 bytes long, and the initial value for the sequence number of the data segments is set to 1. Uppercase ACK indicates the acknowledgment bit in the header, while lowercase ack represents the acknowledgment field value.

From the diagram, it can be seen that B performed three instances of flow control. The first reduced the window to rwnd = 300, the second to rwnd = 100, and finally to rwnd = 0, meaning the sender is not allowed to send more data. This state of pausing the sender will last until Host B issues a new window value.
TCP sets a persistence timer for each connection. Whenever one side of the TCP connection receives a zero-window notification from the other side, it starts the persistence timer. If the timer expires, it sends a zero-window probe segment (carrying 1 byte of data), prompting the other side to reset the persistence timer.
10. TCP Congestion Control
The sender maintains a state variable called the congestion window (cwnd). The size of the congestion window depends on the level of congestion in the network and changes dynamically. The sender sets its sending window equal to the congestion window.
The principle of controlling the congestion window is: as long as there is no congestion in the network, the congestion window increases to allow more packets to be sent. However, whenever congestion occurs, the congestion window decreases to reduce the number of packets injected into the network.
The slow start algorithm:
When a host begins to send data, if it injects a large amount of data into the network immediately, it may cause network congestion, as the current load situation is unknown. Therefore, a better method is to probe first, meaning gradually increasing the sending window from small to large, or in other words, gradually increasing the congestion window value.
Typically, when starting to send packets, the congestion window cwnd is set to the value of one maximum segment size (MSS). For every acknowledgment received for a new packet, the congestion window increases by one MSS. This gradual increase of the sender’s congestion window cwnd allows for a more reasonable rate of packet injection into the network.
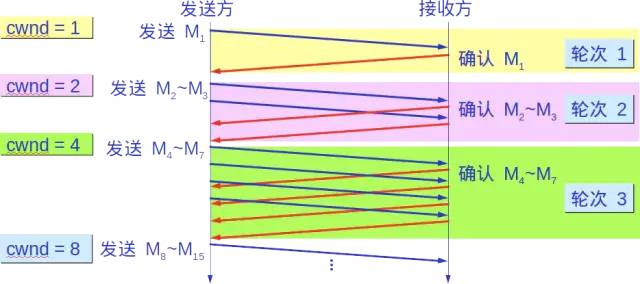
Every transmission round, the congestion window cwnd doubles. The time taken for a transmission round is actually the round-trip time RTT. However, the term “transmission round” emphasizes that all packets allowed to be sent by the congestion window cwnd are sent continuously, and acknowledgment for the last byte sent is received.
Additionally, to prevent the congestion window cwnd from growing too large and causing network congestion, a slow start threshold (ssthresh) state variable must be set. The usage of the slow start threshold ssthresh is as follows:
-
When cwnd < ssthresh, use the above slow start algorithm.
-
When cwnd > ssthresh, stop using the slow start algorithm and switch to the congestion avoidance algorithm.
-
When cwnd = ssthresh, either the slow start algorithm or the congestion control avoidance algorithm can be used.
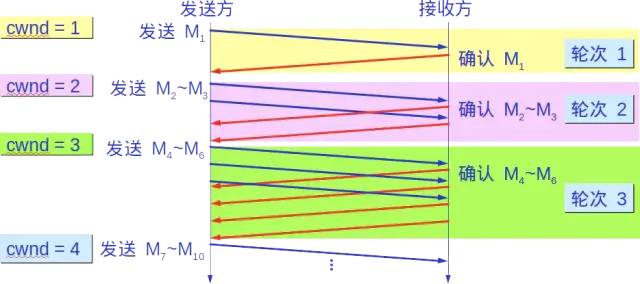
Congestion avoidance
Allows the congestion window cwnd to increase slowly, meaning that for every round-trip time RTT, the sender’s congestion window cwnd increases by 1, rather than doubling. This allows the congestion window cwnd to grow at a slower linear rate than the slow start algorithm.
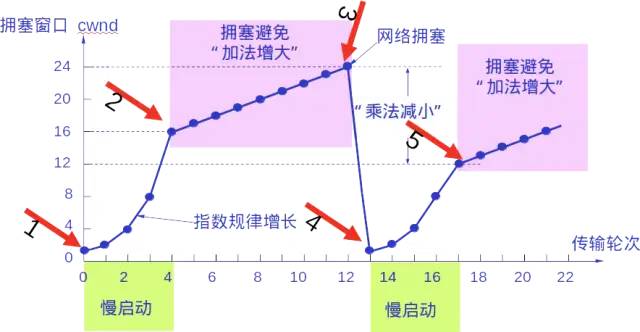
Whether in the slow start phase or the congestion avoidance phase, if the sender determines that congestion has occurred (indicated by the lack of acknowledgment), it will set the slow start threshold ssthresh to half of the sender’s window value at the time of congestion (but not less than 2). It will then reset the congestion window cwnd to 1 and execute the slow start algorithm.
The purpose of this is to quickly reduce the number of packets sent into the network, allowing the congested router enough time to process the packets in its queue.
The following diagram illustrates the process of congestion control with specific values. Now, the size of the sending window is equal to that of the congestion window.
2. Fast Retransmit and Fast Recovery
Fast Retransmit
The fast retransmit algorithm requires the receiver to immediately send a duplicate acknowledgment upon receiving any out-of-order packets (to allow the sender to know early that a packet has not reached the other side) rather than waiting until it sends data to send the acknowledgment.
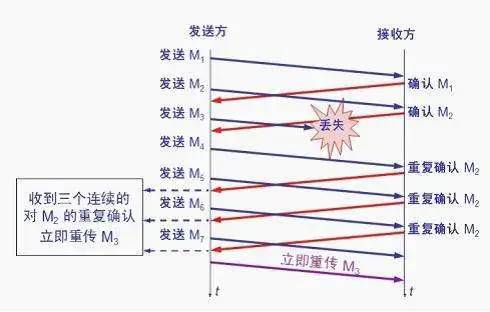
After receiving M1 and M2, the receiver sends acknowledgments for both. Now assume the receiver did not receive M3 but received M4.
Clearly, the receiver cannot acknowledge M4 because it is an out-of-order segment. According to reliable transmission principles, the receiver can either do nothing or send a delayed acknowledgment for M2 at an appropriate time.
However, according to the fast retransmit algorithm, the receiver should promptly send a duplicate acknowledgment for M2. This allows the sender to know early that packet M3 has not reached the receiver. The sender then sends M5 and M6. The receiver, upon receiving these two packets, will also send another duplicate acknowledgment for M2. Thus, the sender receives four acknowledgments for M2, the last three of which are duplicates.
The fast retransmit algorithm also stipulates that as soon as the sender receives three duplicate acknowledgments, it should immediately retransmit the unacknowledged packet M3 without waiting for the retransmission timer for M3 to expire.
By retransmitting unacknowledged packets early, the fast retransmit mechanism can increase overall network throughput by approximately 20%.
Fast Recovery
-
When the sender receives three consecutive duplicate acknowledgments, it executes the “multiplicative decrease” algorithm, halving the slow start threshold ssthresh. -
Unlike slow start, it does not execute the slow start algorithm (the congestion window cwnd is not set to 1), but instead sets the cwnd value to the value of ssthresh after it has been halved, then starts executing the congestion avoidance algorithm (“additive increase”), allowing the congestion window to increase slowly in a linear fashion.
