
How can we achieve strong inference capabilities in language models at a low cost? Driven by this fundamental question, we propose Tina — a family of lightweight inference models realized with high cost efficiency. Tina demonstrates that significant improvements in inference performance can be achieved even with minimal resources. This achievement is realized through the application of Low-Rank Adaptation (LoRA) for efficient parameter updates on a micro base model with only 1.5 billion parameters during the reinforcement learning (RL) process.
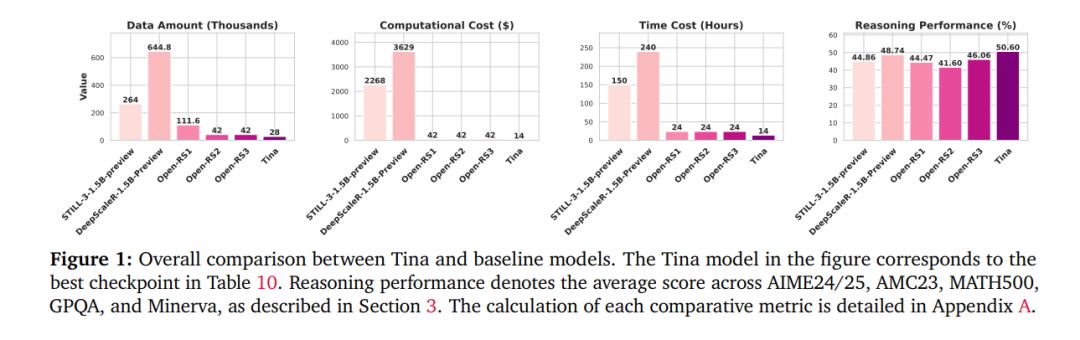
The models trained using this minimalist approach are not only competitive in inference performance but sometimes even surpass the state-of-the-art (SOTA) RL inference models built on the same base model. Notably, Tina achieves this performance while consuming only a tiny fraction of the post-training computational costs of existing SOTA models. In fact, the optimal Tina model improves inference performance by over 20% on the AIME24 benchmark, achieving a Pass@1 accuracy of 43.33%, with post-training and evaluation costs of only $9 (approximately 1/260 of the cost of traditional methods).
Our work reveals the astonishing effectiveness of using LoRA to achieve efficient RL inference. We validated this across multiple open-source inference datasets and various ablation experimental setups, all based on a fixed set of hyperparameters.
Furthermore, we propose that the efficiency of this method may be attributed to LoRA’s ability to quickly guide the model to adapt to the inference structure formats encouraged by the RL reward mechanism while largely preserving the original knowledge of the base model.
To promote research openness and reproducibility, we have fully open-sourced all code, training logs, model weights, and checkpoint files.
1 Introduction
Language Models (LMs) have shown increasingly enhanced capabilities across various tasks, yet they still face challenges in achieving robust multi-step reasoning (Wang and Neiswanger, 2025; Xu et al., 2025). Inference capabilities are crucial for many applications requiring complex problem-solving, such as scientific discovery and complex planning. Enhancing complex reasoning capabilities through Supervised Fine-Tuning (SFT) is a common practice today, typically relying on knowledge distillation processes (Min et al., 2024; Huang et al., 2024), where models learn by mimicking the reasoning trajectories generated by stronger models (e.g., OpenAI’s o1, 2024). While this method is effective, it relies on high-quality expert demonstrations, which are often costly to obtain. Moreover, this imitation process may lead to models merely acquiring superficial “copying” abilities rather than developing the capacity for dynamic reasoning paths.
In contrast, Reinforcement Learning (RL) allows models to learn flexibly from verifiable reward signals (DeepSeek-AI, 2025; Lambert et al., 2025), encouraging models to explore more logical paths and potentially discover more robust solutions. However, traditional RL processes are often complex in structure and extremely resource-intensive. This leads us to the core question of our research:
How can we effectively endow language models with reasoning capabilities through reinforcement learning at a lower cost?
To address this question, we intentionally chose a minimalist path. Unlike large models with hundreds of billions of parameters (e.g., Qwen-7B/32B, QwQ-32B-preview, etc. [Min et al., 2024; NovaSky Team, 2025; Zeng et al., 2025; Muennighoff et al., 2025; Cui et al., 2025; Lyu et al., 2025; OpenThoughts Team, 2025; Hu et al., 2025]), we focus on small models, specifically selecting DeepSeek-R1-Distill-Qwen-1.5B (with only 1.5 billion parameters) as the base model. This model is expected to possess stronger initial reasoning capabilities than general pre-trained models of the same scale due to its lineage (from the DeepSeek/Qwen series) and distillation process. This strategic choice helps to more rigorously assess the incremental effects of RL, thereby more accurately quantifying the contributions of the RL technique itself.
More importantly, selecting a small architecture significantly lowers the experimental threshold. To further enhance the efficiency of the RL phase, we introduced Low-Rank Adaptation (LoRA) (Hu et al., 2021) as a parameter-efficient post-training method. LoRA allows for changing model behavior by training only a minimal number of new parameters, aligning closely with our core motivation of achieving reasoning capabilities in the most economical way.
By combining “small model architectures” with “LoRA reinforcement learning fine-tuning, we propose the Tina model family (Tiny Inference Architecture), achieving significant inference performance at extremely low costs. Our contributions are as follows:
• Significant Effects of Efficient RL Inference
We demonstrate that the performance of the Tina model in inference tasks is comparable, and in some cases even surpasses, that of state-of-the-art RL models trained with full parameters on the same base model (see Figure 1 and Table 3). In particular, the optimal Tina model achieves over 20% improvement in inference performance on the AIME24 benchmark, with a Pass@1 accuracy of 43.33%.
• Hypothesis of Rapid Adaptation to Inference Formats
Based on the performance of the Tina model during the post-training phase, we hypothesize that the efficiency and effectiveness of LoRA stem from its ability to quickly adapt to inference output formats during the RL process while largely preserving the original knowledge of the base model. Compared to the deep knowledge integration required in full parameter training, this is a more computationally efficient way to enhance reasoning. We tested this hypothesis by training only the LoRA parameters, indicating the potential for significant improvements in reasoning capabilities by merely adapting the inference format. This finding is also consistent with recent research — small models continue to perform excellently on reasoning tasks (Hugging Face, 2025; DeepSeek-AI, 2025), while large models are better suited for storing world knowledge (Allen-Zhu and Li, 2025).
• A Path to Democratizing Reinforcement Learning for Inference
We provide a reproducible and cost-effective method that lowers the barrier to entry for RL inference research. The reproduction cost of the optimal Tina model is only $9, and the total cost to reproduce all experiments and analyses in this paper is only $526. To promote research openness, we have fully open-sourced the code, training logs, evaluation scripts, and all model weights and checkpoints.
For convenient viewing, visit the link below or click “Read the original text” at the bottom
https://www.zhuanzhi.ai/vip/4e735bfa6003d7dc6661e4fc843729e6

Click “Read the original text” to view and download this article