Keep it simple, keep it single functional.
— Kelly Johnson
Next, let’s look at the redistributor.
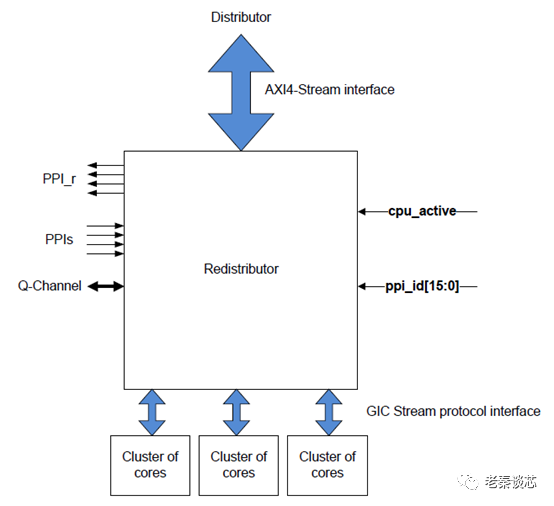 Figure 1 GIC-600 redistributor
Figure 1 GIC-600 redistributor
The part connected to the distributor will not be discussed. Cpu_active indicates the state of the cluster or core, which can be used for idle management. ppi_id is used to distinguish each redistributor in multi-core designs. PPIs are the PPI interrupt lines, which are described as follows in GIC-600:
 Figure 2 PPI Description
Figure 2 PPI Description
From the above, it can be seen that the so-called “private” means that these interrupt signals are exclusive to the core. For PPI, ARMv8 defines three specifications: 8, 12, and 16. Thus, the number of PPIs may vary for different cores.
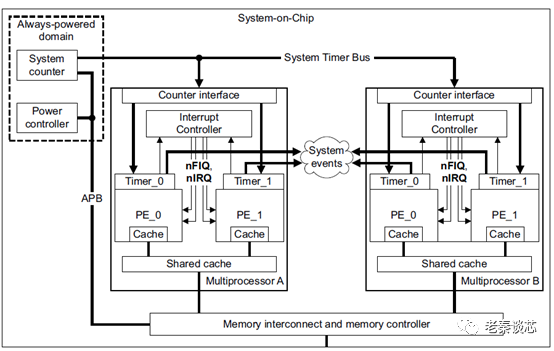 Figure 3 Generic Timer
Figure 3 Generic Timer
The above is the timer diagram from the ARMv8-A architecture specification. We can see that the core’s timer will send a PPI, while the interrupt controller returns FIQ or IRQ to the core. Observant readers may ask, why are there no FIQ and IRQ signals on the redistributor? In fact, it was mentioned in the first article that under the current GICv3 architecture, the FIQ and IRQ interrupts, as well as system registers, are located at the cluster/core side, leaving a set of interfaces for external use, called the CPU interface (implemented on the interrupt controller side in GICv2), which is the bottom interface in Figure 1. This is actually a simplified AXI4-Stream.
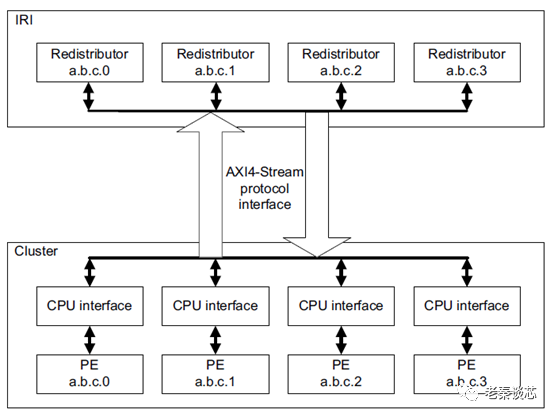 Figure 4 GIC Stream Protocol Interface
Figure 4 GIC Stream Protocol Interface
Since it is bi-directional, there are two sets of signals.
 Figure 5 Signals from Redistributor to CPU
Figure 5 Signals from Redistributor to CPU
 Figure 6 Signals from CPU to Redistributor
Figure 6 Signals from CPU to Redistributor
Since this is a simplified bus protocol, to facilitate communication between the CPU and the redistributor, ARM also specifies the specific packet format. The following diagram shows the command format sent from the CPU side; for specific explanations, please refer to the GICv3 documentation, and we will not post more images here.
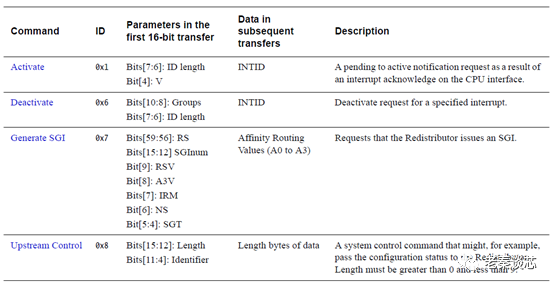 Figure 7 CPU Interface Command
Figure 7 CPU Interface Command
At this point, only the most complex ITS remains, which is designed to implement message-based interrupts. As mentioned earlier, LPI is a type of message-based interrupt. This means that interrupt information is not transmitted via interrupt lines. ITS is responsible for parsing the received LPI interrupts.
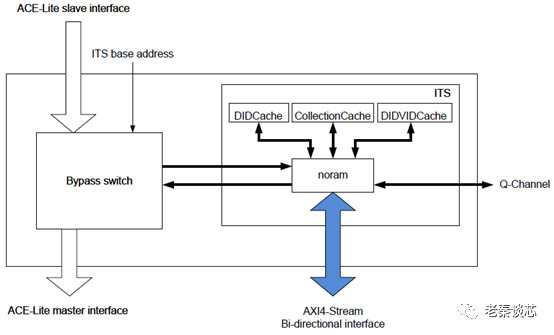 Figure 8 GIC-600 ITS Component
Figure 8 GIC-600 ITS Component
Since it is an information interrupt, there must be a way to differentiate these interrupts, so that appropriate interrupt handling strategies can be found. Therefore, there are two concepts here.
-
EventID, used to indicate the event type of the interrupt sent by the peripheral
-
DeviceID, used to indicate which peripheral initiated the LPI
The ITS needs to take the DeviceID sent by the peripheral, select the entry indexed by DeviceID from the device table. From that entry, it obtains the location of the interrupt translation table; then, based on the EventID, it selects the entry indexed by EventID from the interrupt translation table. It obtains the interrupt number and the collection number to which the interrupt belongs; finally, using the collection number, it selects the entry indexed by the collection number from the collection table. It obtains the mapping information of the redistributor, and finally routes the interrupt information to the corresponding redistributor based on the mapping information from the collection entry.
Lastly, it should be mentioned that GICv3 begins to support affinity routing. Please forgive me for being a bit lazy and directly pasting part of the document:

Here, let me explain what affinity is. When I first encountered this concept, I was completely confused until one day I read a book related to operating systems and finally understood (let’s ignore my ignorance~). CPU affinity is a type of scheduling property; the Linux scheduler will run specified processes on the “bound” CPU according to the affinity settings, rather than running them on other CPUs. One benefit is that it can improve cache hit rates. When a process runs on a certain CPU, it maintains many states in that CPU’s cache. The next time that process runs on the same CPU, it executes faster due to the data in the cache. Therefore, multiprocessor schedulers should consider this affinity, keeping processes on the same CPU as much as possible. Similarly, this is beneficial for concurrent programs as well. It is a reflection on CPU design that, in the end, it must have a love-hate relationship with the operating system, haha~
I hope everyone can gain something from this.
Copyright belongs to the original author; if there is any infringement, please contact for deletion.
END
关于安芯教育
安芯教育是聚焦AIoT(人工智能+物联网)的创新教育平台,提供从中小学到高等院校的贯通式AIoT教育解决方案。
安芯教育依托Arm技术,开发了ASC(Arm智能互联)课程及人才培养体系。已广泛应用于高等院校产学研合作及中小学STEM教育,致力于为学校和企业培养适应时代需求的智能互联领域人才。