Author: Huang Yefeng
This article is originally from EET Electronic Engineering Magazine
Apple’s Mac has started using its own chips, which is undoubtedly a blow to Intel. During last year’s MacBook series product launch, Apple mentioned its own M1 chip, boasting that its CPU performance has increased by 2.8 times and GPU performance by 5 times compared to previous MacBook products; the comparison is with Intel processors. The device’s battery life has also improved to 20 hours.
These numbers are incredible, especially considering the current stagnation of Moore’s Law in the semiconductor industry. Of course, the comparison content and objects are debatable. However, Apple has used such comparative figures before. Back in the days when Macs were still using PowerPC processors (in 1999), Apple claimed in a promotion that the PowerPC G3 was 2 times faster than the Intel Pentium II at that time. This feels quite familiar.

This so-called “2 times faster” claim gives a glimpse into Apple’s consistent processor philosophy, even when Apple did not have its own chip design team back then. In fact, the so-called 2 times faster was based on a comparison between a Mac and a Windows PC, with the former using a PowerPC G3 processor and the latter using an Intel Pentium II processor, where the comparison content involved both executing a set of Photoshop tasks automatically.
The Mac in the demonstration was able to complete these tasks in half the time of the Windows PC. The key here is that the PowerPC G3 added an AltiVec acceleration unit, which is a 128-bit vector processing unit capable of executing 4 single-precision floating-point mathematical operations in a single cycle. Photoshop could fully utilize this unit, and the efficiency of AltiVec was higher than Intel’s MMX extension instructions at that time.
In simple terms, it relies on dedicated units to achieve a crushing advantage in performance and efficiency. Although PowerPC has long been defeated by x86, this philosophy has largely continued to today’s Apple chips (including A-series and M-series SoCs). Below, I will detail this aspect reflected in the M1 from a technical perspective.

In fact, the emergence of the M1 chip has not only instilled a sense of white terror in the x86 camp but also poses a significant threat to Arm camp participants like Qualcomm. Qualcomm has collaborated with Microsoft on two generations of chips (SQ1 and SQ2) and has pushed the Surface Pro X (and its Windows 10 on Arm) for two years, yet it seems insignificant in the face of the M1.
This article is a sister piece to “Can Intel’s New CEO Make Chips Like Apple’s M1? The Big-Little Core Counterattack Battle of PC Processors”. It will discuss how Apple has technically achieved deterrence against Intel, Qualcomm, and other competitors through the lens of the M1 chip; and attempt to explore why Apple can do this, as well as whether competitors like Intel and Qualcomm can achieve the same. Apart from the first two sections, the remaining parts can be read selectively based on interest.
Crushing Intel and Qualcomm
Regarding why Apple wants to switch to its own chips for MacBooks, there could be many answers, including complete control of the Apple ecosystem and further control over cost budgets. If we look only at the performance and efficiency of the processors themselves, a chart from AnandTech basically answers this question well:
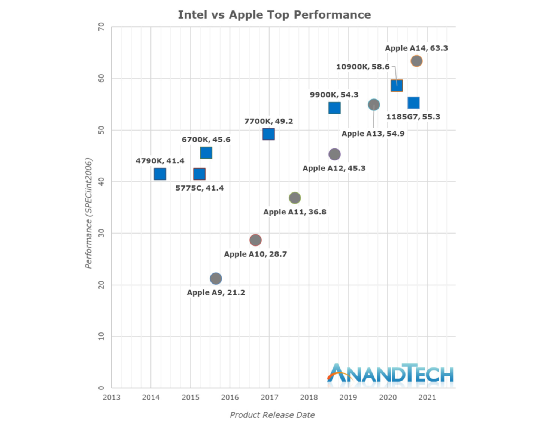
This chart compares Intel and Apple chips, showing the trend of single-thread performance changes since 2013 (the specific test item is SPECint2006). In the past five years, Intel’s processor products have seen an increase of about 28% in single-thread performance, while Apple CPUs have achieved a performance increase of 198%. In other words, the single-thread performance of the A14 processor is nearly 3 times that of the A9.
The M1 shares the Firestorm big core with the A14 chip, and it can be roughly assumed that the two have similar single-thread performance (M1 has a higher frequency than A14, and the L2 cache is also larger, etc.). Therefore, the performance of Apple chips in 2020 has just formed a scissors-cross trend compared to Intel processors. Hence, it seems logical for the latest MacBooks to start using their own chips from a performance perspective.
In fact, Apple claimed back in the A7 chip (iPhone 5s) era that its Cyclone core was a “desktop-level architecture.” However, not many people paid attention at that time. Moreover, before the appearance of the M1, more people still firmly believed that Arm processors could only be low-power compared to x86, and could not achieve high performance like x86. Apple has proven this viewpoint wrong through practical actions.
Many comparative tests mention that the M1 is even more powerful than Intel’s Core i9. Is this statement exaggerated? Let’s roughly outline where the M1 chip stands in terms of performance compared to mainstream x86 and Arm processors aimed at PCs.
The configuration of Apple’s M1 chip is as follows:

The official has not disclosed the TDP (or approximate power consumption) of the M1 chip. AnandTech estimates that the CPU TDP of the M1 is between 20-24W. Tests from Geekbench also basically confirm that its CPU TDP is around 25W (peak power consumption 24W, daily peak power consumption around 15W). This value may not be accurate, as it may also include DRAM power consumption, but it is pretty close.
According to Geekbench data, the GPU part’s full-speed peak power consumption is around 10W; the total peak power consumption that the entire M1 chip can achieve is about 34W. AnandTech mentioned in testing that the GFXBench Aztec High test showed a power consumption of 17.3W, which should be difficult to reflect how much is solely attributed to the GPU. Overall, this power consumption and TDP level are roughly comparable to Intel and AMD’s low-power processors.
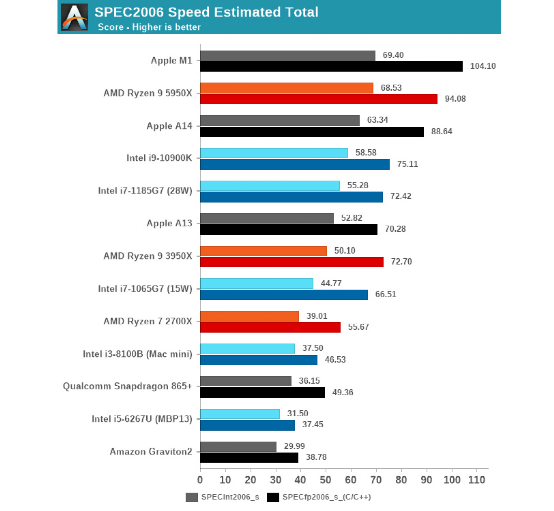
AnandTech conducted a variety of tests, here I will only select SPEC2006/SPEC2017 to illustrate its actual performance. In the SPECint2006 integer performance test, the Apple M1 is close to AMD Zen 3; in the SPECfp2006 floating-point performance test, M1 has a significantly greater advantage. Overall, its performance can be summarized as follows:
Source: AnandTech
It should be noted that this is the single-thread performance score. The M1’s score is significantly stronger than Intel’s 11th generation Core (the Core i7-1185G7 at the same TDP level), and the Core i9-10900K (10th generation Core, Comet Lake-S), and even stronger than AMD Zen 3 (Ryzen 9 5950X).
Apple’s claims about performance improvements compared to previous MacBooks seem to be completely credible. The SPEC2017 test results are also similar to SPEC2006, but M1 and AMD Zen 3 (Ryzen 9 5950X) have mutual strengths and weaknesses; M1’s integer performance is overall inferior to Zen 3, while its floating-point performance surpasses.
This comparison is also based on the fact that the maximum frequency of M1’s big core is only 3.2GHz, while Intel’s 11th generation Core (i7-1185G7) can boost to 4.8GHz, and the Core i9-10900K can even reach 5.3GHz; AMD Zen 3 (Ryzen 9 5950X) can boost to 4.9GHz. Compared to M1, the counterparts have significantly higher power consumption.
In other words, Apple’s M1 has indeed become the IPC king of CPUs today. IPC refers to Instructions Per Cycle, or how much work can be done per Hz. It can be seen that M1 is capable of outperforming the most powerful x86 processors currently available.
Source: AnandTech
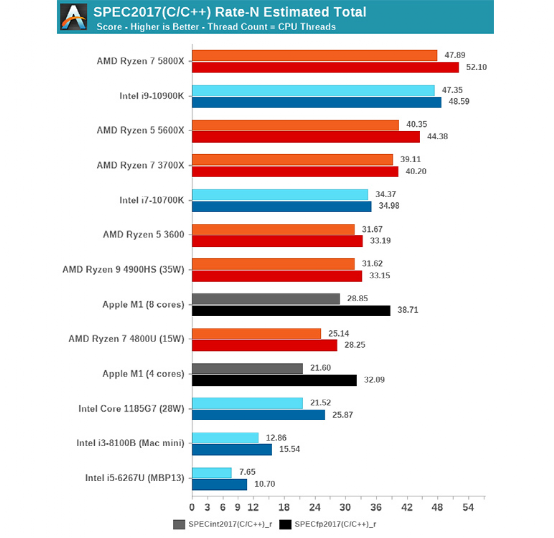
In terms of multi-core performance testing, the M1 itself is limited to only 4 big cores and 4 small cores, which naturally cannot be compared with those beasts that have 8-core, 10-core and support hyper-threading. However, M1 can still crush Intel’s low-power version of the 11th generation Core (i7-1185G7, 4 cores 8 threads, boost frequency 4.8GHz, TDP 28W). If M1 were to expand its core count and processor scale, achieving multi-thread performance supremacy should not be difficult.
Other test results are roughly similar, including Geekbench 5 single-thread tests, where M1 easily takes the crown, surpassing AMD Zen 3 (Ryzen 9 5950X) and Intel Core i9-10900K; CineBench R23 single-thread performance is slightly weaker than AMD Zen 3, while multi-thread performance is about 15.6% weaker than AMD Ryzen 4800U (Zen 2, 8 cores 16 threads) and 60% stronger than Intel’s 11th generation Core (i7-1165G7, 4 cores 8 threads).
To ensure compatibility of the M1 chip with x86 software, Apple has implemented the Rosetta 2 translation layer. This allows previous x86 software to run on M1 chips without modification. This solution may lower the execution efficiency of programs. Even with Rosetta 2 translation, the M1 chip can run traditional x86 programs at a performance level comparable to Intel’s 8th generation Core (for programs with low reliance on AVX instructions, the performance of M1+Rosetta 2 is similar to that of the 10th generation Core).
Due to space constraints, the details of the test items cannot be elaborated. However, to summarize: among CPUs of the same core scale, Apple’s M1 chip can achieve stronger performance than x86 processors at significantly lower power consumption during regular performance tests. It’s not a problem at all to completely crush Intel at the same scale, and even when competing with AMD, it is also AMD sacrificing power consumption in exchange for performance (in single-core performance tests, AMD Zen 3 can reach a power consumption level of 49W, while Apple’s M1 has an overall power consumption of 7-8W).

All of the above comparisons are against x86 processors. How does it compare with competitors in the Arm camp? In 2019, Microsoft released the Surface Pro X, which is equipped with a chip called Microsoft SQ1, which is essentially a rebranded Qualcomm Snapdragon 8cx; the second generation was updated in 2020 with the Microsoft SQ2 chip, which is the second generation Snapdragon 8cx.
Microsoft’s planning for Windows 10 on Arm was earlier than Apple’s. Qualcomm’s Snapdragon 8cx has also become an excellent comparison target for the M1 chip. Linus Tech Tips conducted performance tests comparing the Snapdragon 8cx (second generation) with the M1 chip.
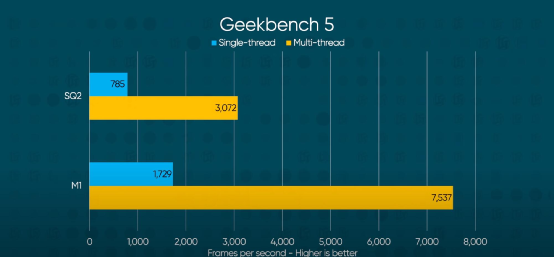
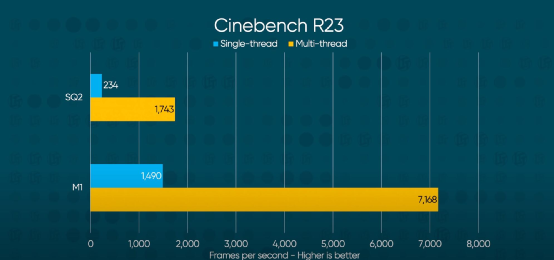
Source: Linus Tech Tips, where SQ2 is the second generation Qualcomm Snapdragon 8cx
From the Geekbench 5 and CineBench R23 test results, it is easy to see that M1 can easily outperform the Snapdragon 8cx (Microsoft SQ2). The performance levels of the two are simply not on the same scale, although the power consumption level of the Snapdragon 8cx should be lower (although it seems that the battery life of the Surface Pro X is not better than that of the M1 MacBook Air). (Although it seems that the battery life of Surface Pro X is not better than that of M1 MacBook Air.)
Ironically, Linus Tech Tips attempted to use some virtual machine tricks to install Windows 10 on Arm on the M1 MacBook Air. Then, running Geekbench 5 in the Windows virtual machine, it was found that its performance level was still far ahead of the Surface Pro X, which is quite a slap to Qualcomm and Microsoft:
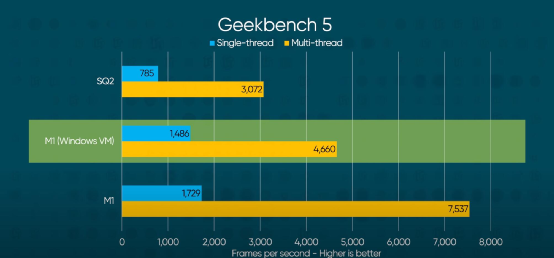
Source: Linus Tech Tips
This test also lacked power consumption monitoring, but it still indicates that the M1 chip, even with an additional virtual machine layer, can run other operating systems and still outperform Qualcomm’s current low-power PC competitors.
Apart from performance, the low power consumption of the M1 chip has also been demonstrated in many tests. In my previous article about big-little core design, I mentioned that the M1’s low power consumption performance can astonish x86 processors, with almost all daily usage scenarios, including office work, web browsing, and idle standby, showing power consumption several orders of magnitude lower than that of Intel and AMD’s competing products: M1 chip’s web browsing power consumption is only 1/6 of the 11th generation Core, video streaming power consumption is only 15% of the 11th generation Core, and Word processing power consumption is only 20%-30% of the 11th generation Core…
How exactly has Apple managed to punch Intel/AMD and kick Qualcomm and Arm?
To Make the Chip Bigger
The performance data presented in the previous section did not provide data on other components outside the CPU. This includes Apple’s 8-core GPU, which has a significant advantage over Intel’s latest Xe graphics (11th generation Core) and can achieve real gaming performance equivalent to the GeForce MX350; as well as AI dedicated units, AMX, and other components, which will not be elaborated on due to space constraints.
The title states that M1 is more powerful than Intel’s Core i9, which cannot be generalized—such as the Core i9 definitely outperforms M1 in multi-core performance, as the processor scale is much larger. However, as a low-power processor, M1 indeed reaches the level of Core i9 in many scenarios.

For example, Final Cut Pro video editing real-time preview and encoding/decoding of various formats; Xcode coding directly outperforms the high-end version of iMac 2020; even Adobe Premiere, known for its poor optimization, M1 poses a threat to Core i9 in many projects (and it’s still under Rosetta 2 translation). It’s important to note that M1 is designed for portable devices, while Core i9 is designed for workstations (i9-10900K).
How has Apple achieved this level? Many people say it is due to Apple’s high degree of hardware-software integration, which is indeed an important factor but not specific enough. Summarizing into three points, it is roughly the M1 chip’s ultra-wide microarchitecture; the accumulation of various dedicated units; and Apple’s strong ecosystem control.
These points will be elaborated on in the following text. However, the external manifestation of these points is a very large chip area (die size) or a large number of transistors. Because whether it is the ultra-wide processor microarchitecture or the dedicated hardware units for certain functions, they require more die space. Apple’s own chips in the A-series product line have a tradition of having a large die size. As early as the Apple iPhone 5s era, its chip size was much larger than that of other mobile SoCs, sometimes even double (the A11 Monsoon big core and cache occupy an area that is more than double that of Snapdragon 845’s A75 big core and cache).
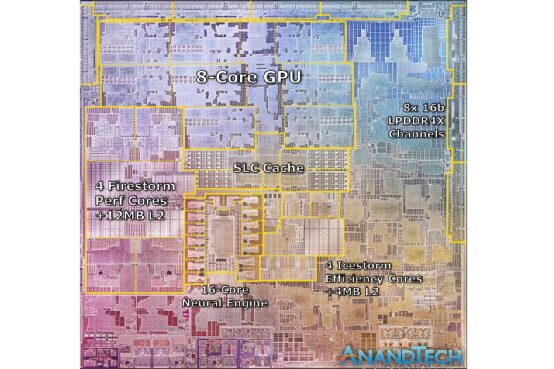
Source: AnandTech
If we look at die size alone, when Apple’s A7 and A8 used 4MB L3 cache, their contemporaries, Cortex-A57/A72/A73, did not have L3 cache until A75. Let alone Apple’s preference for large L2 cache; Apple A11 has 8MB L2 cache, which can be described as enormous. Qualcomm Snapdragon 835 only has 3MB L2 cache and no L3 cache (2016-2017).
Moreover, Apple has liked to add system cache (or System Level Cache – SLC) to the entire SoC chip for several years now. This system cache belongs to the SoC level cache and is shared among various IPs (such as CPU, GPU, NPU, etc.) in the SoC. The system cache of the A12 reached 8MB, doubling that of the A11.
The system cache of the A14 and M1 is currently 16MB, which is 2-3 times that of competitors in the mobile camp like Kirin and Snapdragon. The L3 cache of Intel’s 11th generation Core Tiger Lake (i7-1185G7) is only 12MB. As for L2 cache, M1’s Firestorm big core has 12MB, while small cores have 4MB. The L2 cache of Intel’s 11th generation Core (i7-1185G7) is 4x 1.25MB. In comparison, Core i9-10900K (10th generation Core) has 2.5MB L2 cache (256KB per core) and 20MB L3 cache.
(However, Apple’s cache design seems to differ from that of general CPUs, including shared L2 cache; and the system cache should also not be as fast as L3 cache dedicated to the CPU.)
The gigantic L1 cache compared to other competitors (such as 192KB of L1 instruction cache, which is 3 times that of Arm’s public design and 6 times that of existing x86 designs; reportedly, it is also very fast), does not need further discussion. In terms of cache size alone, Apple has always been unparalleled in packing resources for consumer electronics applications at the low-power processor level. The following text will further elaborate that “packing resources” is not only about cache.

So can competitors like Intel, AMD, and Qualcomm also pack resources like this? Excluding some limitations in microarchitecture, Intel, AMD, and Qualcomm can indeed do this, but it is very uneconomical. Because packing resources means increasing die size, which in turn means a sharp increase in cost. The advancement of chip manufacturing processes is partly to achieve higher performance within a smaller die size and reduce costs.
Apple can do this because what Apple ultimately sells to users are terminal devices. For example, in an iPhone, apart from the SoC chip, there are also screens, flash memory, value-added services, etc. But when facing users, there is only one terminal device price. Setting aside the millions of units of iPhone sold annually and the fact that iPhone captures more than half of the entire smartphone market’s profits, Apple can balance, offset, and transfer various cost expenditures among different components. iPads and MacBooks also benefit from the experience of iPhone chip design and the revenue brought by the huge shipment volume of iPhones.
On the other hand, companies like Intel, AMD, and Qualcomm only sell processors, and they need to rely on processors to make profits. Downstream mobile phone manufacturers need to make money, and upstream IP suppliers also need to make money. In the case of profit overlaps at different stages of the industry chain, cost control becomes particularly important.
Moreover, Intel’s processors are not only aimed at a specific model of PC but also at PCs of different price points, as well as other markets like servers and data centers. The core IP will largely be reused, and if the core is designed to be large and wide, it will appear particularly expensive for usage scenarios that require a large number of cores for parallel computing. Therefore, these companies, which exist solely as chip manufacturers, find it difficult to pack resources as “disregard for martial ethics” as Apple does because their business models are fundamentally different.
For general chip manufacturers, it is evidently more economical to obtain performance improvements by increasing chip frequency rather than enlarging chip area and increasing costs.

Regarding cost control, it is particularly worth mentioning that in the previous article titled “The Rise of Deep Learning: The Funeral of General Computing?”, I mentioned that the costs of chip design and manufacturing are climbing year by year, especially the costs associated with cutting-edge manufacturing processes, including factory construction costs. Even without considering technical limitations, existing market participants can no longer iterate manufacturing processes according to Moore’s Law as they did in the past. This situation affects Intel much more than TSMC and Samsung. This is because Intel’s primary revenue source is cutting-edge processes, while TSMC and Samsung’s early manufacturing processes are also significant sources of revenue.
At the moment when Intel is struggling with 10nm and 7nm production difficulties, it is likely to fall into a vicious cycle, which not only affects the market competitiveness of its chip products but may also distance it further from being regarded as the world’s most advanced process factory. The burdens that Intel bears are evidently heavier than those of Apple, AMD, Qualcomm, and Samsung, which are different levels of market participants.
Ultra-Wide Architecture (Optional Reading)
Of course, “making the chip bigger” is only a result, not a purpose. The reason for making the chip bigger, apart from obtaining higher data bandwidth from larger cache, also lies in Apple’s enthusiasm for ultra-wide processor architecture and its preference for adding various dedicated units to the SoC. The following text is optional reading and is aimed at light tech enthusiasts.
Earlier, it was mentioned that the Apple M1, with a frequency of only 3.2GHz, achieved performance surpassing that of competitors’ processors with frequencies close to 5GHz. If M1’s frequency were raised to 5GHz, wouldn’t it be extraordinary? This point may be unachievable because Apple’s “wide” core approach makes it less favorable for frequency increases, otherwise, power consumption would easily spiral out of control. Generally, increasing frequency raises power consumption at a cubed rate relative to frequency. Therefore, those processors that achieve performance comparable to M1 at nearly 5GHz also pay the corresponding power consumption price.
During the iPhone 6s era, Apple’s A9 and earlier processors generally had lower frequencies than competing products on the market at the same time. For example, the Apple A8 had a frequency of 1.5GHz, and the A9 was 1.8GHz, while the Arm Cortex-A72 at the same time had reached 2.5GHz, and the A73 was at 2.8GHz. Yet Apple’s processors still maintained performance levels that could outpace all. This is because Apple has always favored “wide” cores to achieve higher instruction parallelism, which is also reflected in IPC numbers (although today’s A-series processors have also reached 3GHz levels).
That is to say, the more tasks can be done per cycle, the more efficiently lower frequencies can accomplish tasks. High instruction parallelism or high IPC requires “wider” processor cores, such as being able to simultaneously read, decode, execute, or write multiple instructions per cycle. There are many ways to improve instruction parallelism, and one crucial factor in modern processor architecture is out-of-order execution capability. That is, allowing instructions without dependency to be executed out of order, so that later instructions do not have to wait for earlier instructions to complete execution.

However, out-of-order execution requires additional circuitry to resolve many potential practical issues, which demands more chip area and power consumption. And “widening” the entire architecture, such as increasing the number of instructions decoded per cycle, many dispatch units, and adding more ALU execution units to increase instruction parallelism, all require additional chip area.
Moreover, widening the architecture is not that simple; how to maintain a high utilization rate for these widened units without wasting resources is also crucial. But a wider processor architecture is at least the foundation for achieving high instruction parallelism.
As previously mentioned, for chip manufacturers like Intel, it is often more economical to obtain performance improvements by increasing processor frequency rather than enlarging chip area, widening chip architecture, and increasing costs. A narrower and “deeper” processor architecture also makes it easier to boost frequency.
The width of the CPU portion of Apple’s M1 chip has reached a new high to some extent. The following chart from AnandTech, drawn by Andrei Frumusanu, illustrates the architecture frame of the Firestorm core (the big core of A14 and M1). Most interpretations of the Firestorm microarchitecture circulating today stem from this:
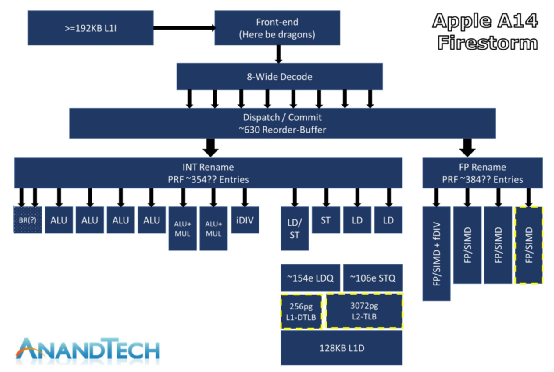
Source: AnandTech
There are several points worth mentioning. First, the front end has an 8-wide instruction decode. What does this mean? AnandTech commented that it is currently the “widest commercial design in the industry.” AMD and Intel’s contemporary processors generally have a decode width of 4-wide (Intel is 1+4); on the Arm side, the mainstream decode width is 4-wide, and this year’s promoted Cortex-X1 is 5-wide; the rumored super-wide Samsung M3 (Exynos 9810) has a decode width of 6-wide.
According to AnandTech’s research, Apple’s A11 and A12 already reached 7-wide, and the A13 has entered the 8-wide realm.
Secondly, the ROB (Re-order Buffer), which is for out-of-order execution, has reached about 630 entries (or roughly 630). A deeper ROB indicates a higher degree of out-of-order execution and reflects a wider architecture. In comparison, Intel’s 11th generation Core (Willow Cove) has a ROB of 352 entries, AMD Zen 3 has 256 entries, and Arm Cortex-X1 has 224 entries. It seems that achieving high instruction parallelism is Apple’s goal.
The backend execution engine of Firestorm is also very “wide”. The integer pipeline part has a physical register renaming (INT Rename PRF) size of about 354 entries, and there are “at least” 7 execution ports for arithmetic operations, including 4 simple ALUs (ADD instructions), 2 complex ALUs (MUL), and one dedicated integer division unit. Each core can handle 2 branches per cycle.
However, the integer pipeline part has “not changed much”; the focus of the floating-point and vector execution pipeline part is Firestorm. As mentioned earlier, M1’s floating-point computing capability has a significant advantage over competitors. Firestorm has added a fourth execution pipeline, and the floating-point renaming registers have 384 entries, which is also “quite large”. There are 4 128-bit NEON pipelines, and the throughput of floating-point operations is consistent with existing AMD and Intel desktop processors. The throughput of floating-point operations and the number of pipelines have a 1:1 relationship, meaning that the Firestorm core can execute 4 FADD (floating-point addition) operations and 4 FMUL (floating-point multiplication) operations per cycle, with 3 and 4 cycles of latency, which is four times the throughput of Intel processors and twice that of Zen 3.
AnandTech commented that this might be the reason why Apple performs so well in browser tests. An important application on PCs today is web browsing, which Apple seems to have recognized as a pressing user demand.
Lastly, in the storage subsystem part, it is worth mentioning that the load-store front end can reach a maximum of 148-154 loads and 106 stores, which is wider than any microarchitecture on the market. In comparison, AMD Zen 3 has these two numbers at 44 and 64, and Intel’s 10th generation Core (Sunny Cove) has 128 and 72, respectively.
The L1 TLB (translation lookaside buffer, a type of page table cache, is a memory management unit used to speed up the conversion of virtual addresses to physical addresses) has doubled to 256 pages, and the L2 TLB has been increased to 3072 pages. Therefore, the L2 TLB can cover 48MB of cache. The improvements in cache and the comparisons with other competitors have already been explained in the previous paragraph.
However, the aforementioned points are not achieved overnight. During the iPhone Xs era, Apple’s A12’s Vortex core already had the scale of a desktop CPU in terms of width, significantly wider than the Arm Cortex-A76 and Samsung M3 at that time, whether in execution pipelines or storage subsystems. Therefore, the ultra-wide architecture of M1 today is also a continuation of Apple’s chip philosophy.

Introducing More Dedicated Units (Optional Reading)
The rise of dedicated processors has been increasingly significant as the performance improvement of general-purpose processors slows with the deceleration of Moore’s Law. This trend has become even more pronounced in the past two years.
This article has already mentioned that the PowerPC G3 achieved a “2 times” speed against Intel’s Pentium II by relying on a dedicated unit. It seems that Apple has planted this idea early on.
Previously, the Geekbench testing tool was often jokingly referred to as Apple Bench because many believed that some of its test items were explicitly designed for Apple and Arm, while being unfriendly to x86. Years ago, Linus Torvalds, the father of Linux, commented that Geekbench is sh*t. The reason was that on Arm64 architecture processors, SHA1 performance had dedicated hardware assistance, which made Arm processors score well.
In the single-core performance test of Geekbench 5, M1’s encryption sub-item score remains very high, far surpassing that of Core i9-10990K. This was previously believed by many to be a way for Arm to cheat scores and a basis for asserting that Arm could not match the performance of x86 processors. However, in this instance, Geekbench 5’s other projects, such as integer and floating-point performance, also show that M1 can crush Core i9 (10th generation Core). Moreover, dedicated hardware units assisting a certain project are fundamentally beneficial to the experience.

Similar situations are quite common in Apple’s contemporary chips. For example, using iPad (A14) and MacBook (M1 chip) for video editing (especially Final Cut Pro), the experience and efficiency far exceed that of Windows PCs (Intel Core).
This is based on the fact that the encoding and decoding modules in the M1 chip outperform most GPUs on the market (in Handbrake’s hardware H.265 test, M1’s encoding module showed a complete crushing of Intel and AMD); in addition, the AI dedicated processor in M1 also participates in image analysis, and the dedicated ISP (image signal processor) can perform ProRes RAW format demosaic operations; moreover, M1 also integrates SSD controllers, which aids in I/O sensitive operations.
Thus, for those who frequently need to edit videos, M1 is simply too well-suited. Similarly, this applies to programmers, photographers, and casual video entertainment users.
All of these are based on M1 being a SoC, which uses more dedicated units to address specific problems. While dedicated units may lack flexibility, Apple is well aware of what its target user groups typically do with their devices. By optimizing dedicated units and enhancing the operational experience in specific usage scenarios, both performance and efficiency (power consumption performance) are improved. This also confirms that when general computing stagnates, relying on dedicated computing is an important direction, although it doesn’t necessarily have to be dedicated processors.
The existence of these dedicated units, in my view, is not much different from Intel adding AVX-512 instruction support for its Core processors. Whether these dedicated units are scoring tools (some even say system cache is also a scoring tool) or clever tricks, they have indeed played a role.
One question that arises again is, if ultra-wide architecture and dedicated units are so good, why don’t Intel and AMD do the same? The reasons are likely varied, and Intel and AMD are indeed making efforts in these directions. Perhaps the more important point is that these two options still rely on increasing die size, as mentioned in the second part of the text.
There are also some practical issues, such as the fact that x86 uses variable-length instructions, with instruction lengths ranging from 1 to 15 bytes, while Arm uses fixed-length 4-byte instructions. This means that x86 decoders find it difficult to determine where an instruction starts, requiring length analysis for each instruction. Thus, x86 processors face many errors during the decoding phase. AMD has previously mentioned that increasing more decoders can lead to more issues, and the 4-wide decode width has become a limitation in their design.

Terrifying Ecosystem Control
From chip design to operating systems, to development ecosystems, to consumer terminal device design and manufacturing, and even sales, Apple has complete control. This is probably unparalleled in the entire industry (Samsung seems to lack the crucial operating system segment). The business model it fosters is also the foundation for Apple to act arbitrarily on the M1 and Firestorm cores, which has been mentioned in the previous text.
Moreover, in addition to the microarchitecture of the processor itself, Apple also has considerable say in higher-level system design and software architecture. A typical example of the M1’s design is the DRAM memory integrated into the chip, using a technology called Unified Memory Architecture. When the CPU and GPU use memory, there is no need to separate different spaces, so there is no need to perform memory copy operations during mutual communication, achieving lower latency and higher throughput.
(By the way: The single-core Firestorm has achieved a read bandwidth of 58GB/s and a write bandwidth of 33-36GB/s. Besides being impressive, AnandTech commented that “the design of a single core filling the memory controller is astonishing; we have never seen this before.”)
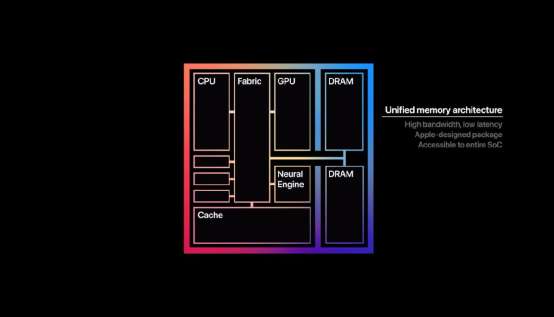
This design is not novel; AMD has also done similar technology in the past, but it has not become widespread. This design imposes new requirements on software development. Apple’s solid ecosystem control should make this a small matter. In contrast, it is evidently not so easy for the fragmented ecosystem of Windows PCs.
At the same time, another point that shows Apple’s solid ecosystem control is that Apple easily switched to its own GPU on the M1 chip. “Native code” does not seem so important in graphics computing, and Apple’s Metal API can be directly prepared for Apple’s GPU, meaning that Apple’s graphics computing reserves can immediately take effect on the M1 and existing ecosystem. (Although Metal seems to be slightly weaker in software efficiency compared to DirectX)
Microsoft’s deployment of the ecosystem for Windows 10 on Arm faces many hurdles, which is also related to Microsoft’s indecisive decision-making. However, despite the long emergence of the Arm version of Windows, a decent ecosystem has not been built, and Windows developers are disinterested in Windows Runtime, which demonstrates Apple’s decisiveness and super speed in building the ecosystem during this transition.
Recently, there have been rumors that Microsoft decided to develop its own chips for future Surface devices. Personally, I feel that this information is not very credible because Microsoft does not have the massive shipment volume of devices like Apple to share the design and manufacturing costs of chips, especially cutting-edge manufacturing costs. It’s important to note that without a large volume to share costs, Surface’s volume cannot afford cutting-edge processes. However, the emergence of this news also indicates how successful Apple has been in building the M1 and its surrounding ecosystem.
However, the essence of Apple’s model and ecosystem relies on the sales volume of consumer electronic terminal devices. If one day iPhone sales decline sharply, the chip business and surrounding ecosystem will soon struggle to survive. The fragmented ecosystem will not be so fragile.
To summarize this article with a pessimistic statement: it seems unlikely that the Windows PC camp will produce a chip like Apple’s M1. However, this is not a big deal, as they are two different ecosystems: the Android camp next door also does not get flustered just because the iPhone sells well.
Reference Sources: (Scroll to read)
[1] The 2020 Mac Mini Unleashed: Putting Apple Silicon M1 To The Test – AnandTech
https://www.anandtech.com/show/16252/mac-mini-apple-m1-tested
[2] Apple Annouces The Apple Silicon M1: Ditching x86 – What to Expect, Based on A14 – AnandTech
https://www.anandtech.com/show/16226/apple-silicon-m1-a14-deep-dive
[3] How did Microsoft screw this up? – Surface Pro X (SQ2) vs M1 Macbook Air – Linus Tech Tips
https://www.youtube.com/watch?v=OhESSZIXvCA
Author Introduction

Huang Yefeng, Aspencore industry analyst; network engineer; 9 years of experience in the technology media industry; focusing on imaging, image computing, machine learning, semiconductor, and mobile-related technology fields.