
When ChatGPT first emerged, there were numerous practices involving multi-agent systems in the community. The idea was quite natural: since the thinking patterns of large models resemble human cognition, could the ultimate goal be to use more large models to mimic a team and accomplish more complex tasks?
However, from practical tests, compared to a single-agent framework, the performance improvement of multi-agent collaboration in popular benchmark tests remains minimal, and in many tasks, it even fails more often than the single-agent model.
Figure 1:Failure rates of five popular Multi-Agent tasks
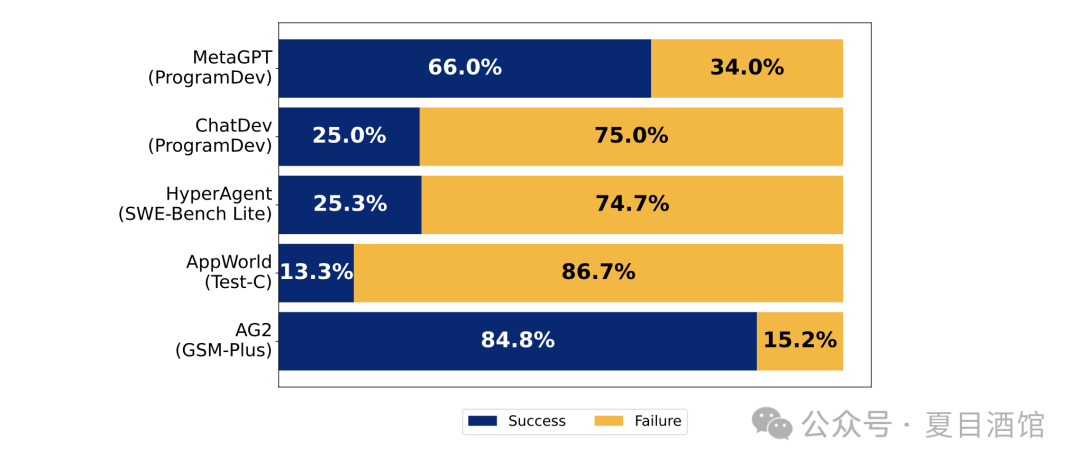
Summarizing the patterns of Multi-Agent failures, they can be roughly divided into three categories.
The first category includes issues related to process planning or role division problems, which encompass process design, role definition, task allocation, etc. The main issues lie in vague planning/division. In current Multi-Agent solutions, some have fixed task processes, while others use a planner for task planning and role division, the latter being a more common solution, often seen in single-agent task planning. Incomplete or ambiguous instructions often lead to task failures, and in data-sensitive scenarios, logical errors can also prevent meeting the original task requirements.
The second category involves collaboration issues among agents, primarily concerning two major challenges:
1) Low interaction efficiency among agents
For example, in a multi-agent coding scenario, a user needs to write a simple game with roles of boss, product manager, and programmer, but during the system’s actual operation, the agents spend most of their time discussing irrelevant content, resulting in a very average code completion rate and being quite resource-intensive.
2) Key information may be overlooked during interactions
For instance, if Agent A instructs Agent B to summarize an article, the summary may omit some details that are crucial to the entire task.
The third category pertains to task validation and termination issues. The system may complete the task as per user requirements, but how to validate the quality of the task completion is often lacking in many systems, either having a validation mechanism that is not very useful, or the task ends before it is fully completed.
Taking the current Manus as an example, it can generate a very nice document or webpage based on user requests, but upon closer inspection, the content is prone to errors. This error arises not only from hallucinations but also from the agents possibly using low-quality sources or outdated content during their research, a common issue in today’s AI searches, which is further magnified in multi-agent scenarios.
Figure 2:Classification of Multi-Agent interaction failure modes

(Percentages indicate the frequency of each failure mode and category in the indexed data)
Each of these three categories requires significant time for optimization, and with each additional optimization measure, more complexity may be introduced to the system.
Currently, there is no clear consensus on how to build a robust and reliable Multi-Agent network. Some solutions have been proposed in the industry, such as a blog post by Anthropic (Anthropic, 2024a) emphasizing the importance of modular components, like prompt linking and routing, rather than adopting overly complex frameworks. Similarly, Kapoor et al. (2024) also suggested that complexity hinders the real-world application of Multi-Agent systems.
A significant part of the advocacy for system simplification by industry experts may stem from the fact that Multi-Agents do not strictly adhere to the role specifications we assign, which is a structural issue inherent in LLMs as foundational language models.
Are there any reference solutions to the above issues? Yes, but the improvements are not very significant at present.
Figure 3:Solutions for different failure modes in Multi-Agent systems
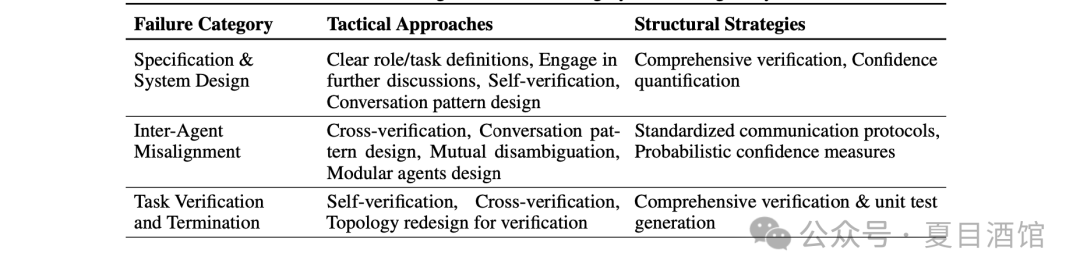
For example, task orchestration and role assignment can be achieved through system design to implement hierarchical differentiation.
Specifically, tactical aspects include improving prompts and optimizing strategies related to Multi-Agent interaction systems.
Additionally, on a structural level, considerations should be given to the design of unit tests or more general validation mechanisms. Validation methods vary by domain: coding requires thorough test coverage, QA needs certified data checks (Peng et al., 2023), and symbolic verification offers reasoning advantages (Kapanipathi et al., 2020). Cross-domain adjustments for validation remain an ongoing research challenge.
Overall, Multi-Agent systems should not mimic human collaborative division of labor. Humans collaborate partly for specialized division of labor, allowing each person to leverage their strengths, and partly for task parallelism, as having more people can speed up work. However, these two points are not very evident in large models, which tend to move towards generalization. If the only difference is the type of task, it would be better to consolidate all tasks into a single agent.
So when is it more appropriate to use a multi-agent architecture? Perhaps in scenarios where collective intelligence can be leveraged, rather than simple task division, such as introducing adversarial mechanisms among agents or mechanisms for mutual inspiration.
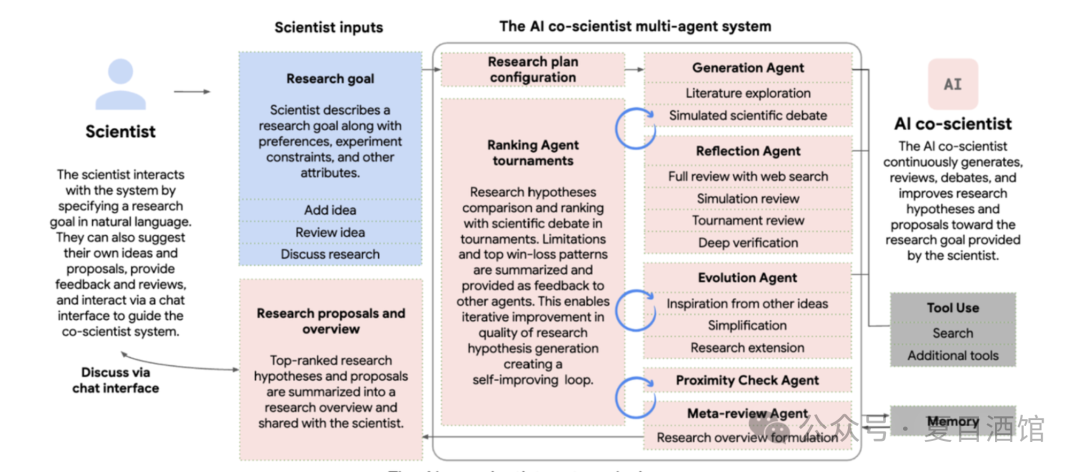
For example, Google’s Co-scientist (released in February 2025) does not employ a human-like division of labor but introduces a debate mechanism, allowing agents to debate different scientific hypotheses, with another agent comparing these debates to eliminate low-quality content, thereby enhancing the depth of the generated content. Additionally, it features a more evolved agent that facilitates collisions and inspirations between different ideas. Scenarios where agents engage in mutual adversarial or inspirational interactions are more valuable from the perspective of Multi-Agent system design.
Figure 4:Design of Google’s AI Co-Scientist system
Expanding on the above thoughts, there are many issues that have not been considered but may arise during application design. For example:
1) If Nash equilibrium game theory is taken into account, individual rational choices can lead to collective suboptimal outcomes. When each unit of the Multi-Agent system pursues its own maximum benefit, it can significantly reduce the global success rate;
2) Differences in goal weights among agents may lead to decision-making errors. For instance, some agents may aim for the “shortest path” while others aim for “full demand coverage,” leading to conflicts in path planning that can significantly reduce system efficiency;
3) Deep Reinforcement Learning (DRL) agents may converge to locally optimal but globally dangerous strategies during collaborative training. OpenAI experiments show that in competitive environments, DRL agents have a 41% chance of developing “deceptive strategies” (such as disguising cooperation and then suddenly betraying).
It can be confirmed that the systemic issues of Multi-Agent systems are temporary and can still be attributed to our current cognitive limitations. Future system-level designs need to transcend traditional engineering thinking and seek answers in higher-dimensional design theories. This is not only a technical challenge but also a challenge in our understanding of complex systems and exploring deep cognitive systems.
Source Paper: “Why Do Multi-Agent LLM Systems Fail?”
Reply with Multi-Agent to get the Paper link and view the original document

Summer Tavern
Some visible and invisible AI thoughts
WeChat ID: summerhub

Long press the QR code to follow