Click the “blue text” above to follow us!
2025.07.16
Word count: 8484
Estimated reading time: 22 minutes
Abstract
Implementing artificial intelligence with microcontrollers has become a hot topic and challenge in embedded product development in recent years. This article discusses the methods, technologies, and tools for deploying deep network models on MCUs, analyzes the process of deploying MCU AI, the support libraries for MCU deep network models, as well as network model conversion tools and optimization methods. Finally, it introduces the deep network model training and deployment tools released by well-known MCU suppliers.
Keywords
Microcontroller; MCU AI; TensorFlow Lite; Deep Neural Network; AIoT
Authors: Li Dongdong1, Lin Jinlong2
Classification number: TP872
Document identification code: A
0
Introduction
In 2012, after AlexNet[1] won the championship in the ImageNet image recognition competition, deep learning technology entered a stage of explosive development, and artificial intelligence technology has become a persistent hot topic in research and industry. Currently, deep learning technology has achieved great success in computer vision, natural language processing, and dynamic programming, and is widely used in fields such as video surveillance, speech recognition, autonomous driving, and medical diagnosis.
Cloud computing, the internet, and sensor technology, especially the development of 5G technology, have accelerated the development and application of Internet of Things (IoT) technology. It is expected that by 2035, the scale of devices in various sub-markets of IoT and systems will reach trillions[2]. IoT end devices typically consist of sensors that collect data (such as audio, video, temperature, humidity, location, and acceleration sensors) and output devices that perform tasks (such as motors, displays, and speakers). The rapid growth in demand for intelligent devices has promoted the integration of artificial intelligence and the Internet of Things, forming the intelligent Internet of Things (AIoT). Traditional IoT systems collect data from sensors, analyze it in the cloud, and control terminal devices from the cloud. However, the numerous nodes and complex AI analysis computations in AIoT place a heavy burden on network bandwidth and cloud computing servers, making it difficult to ensure the real-time operation of terminal devices. Therefore, edge computing technology is adopted to perform data analysis and inference at the data source, terminal, and edge nodes, thereby reducing latency and improving the system’s real-time response capability.
Due to limitations in cost, power consumption, and size, microcontrollers (MCUs) are typically used as the core for computation and control in edge and terminal devices. Limited storage resources and computing performance restrict the ability to deploy deep network models that run on server or PC platforms in MCU systems. Deploying deep neural network models for inference in MCU systems not only requires simplifying and compressing the models but also necessitates developing function libraries related to deep neural networks optimized for MCUs.
This article focuses on deploying deep network models on MCUs, discussing general methods for deploying deep network models, analyzing methods for compressing and pruning network models, and introducing the support and development environments for deep network models on commonly used MCU platforms.
1
MCU AI Deployment
Common deep learning application development frameworks include TensorFlow, Keras, PyTorch, and Caffe2. Using these frameworks, deep network models can be easily created, trained, and validated using Python, and then deployed into application systems. However, due to the insufficient storage resources and computing capabilities of MCU systems, models created and validated in the aforementioned frameworks cannot be directly deployed; they must be converted and optimized, and a deep network model support library that can run on MCUs must be constructed. This section discusses the process of deploying deep network models on MCUs, as well as the model conversion tools and MCU support libraries.
1.1Deployment Schemes
Currently, multiple teams have proposed schemes for deploying deep network models on MCUs, with differences in the steps defined in each scheme and the work content of each step.
Peter Warden et al.[3] successfully implemented inference functionality on MCUs by deploying TensorFlow Lite framework deep network models in 7 steps. Figure 1 shows the steps for deploying deep network models on MCUs as proposed by Peter Warden et al. Steps ①~③ involve training and validating the deep model on a server and PC; step ④ integrates the validated source assembly into the project, generating a binary program that can run on the MCU.
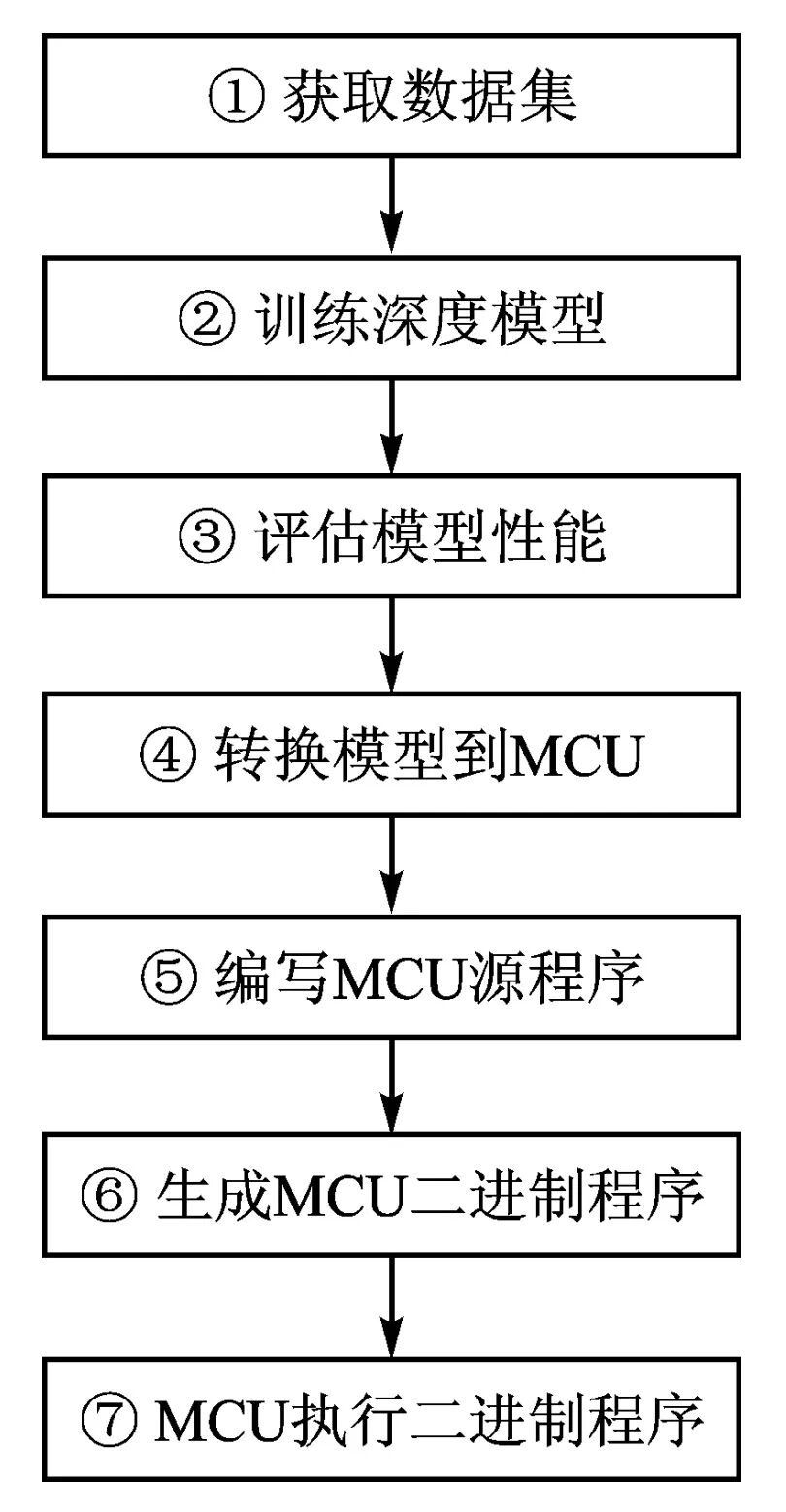
Figure 1 Peter Warden’s MCU Deep Network Model Deployment Process
Bharath Sudharsan et al. proposed a design process for resource-constrained neural networks (Resource Constrained Edge Neural Networks, RCE-NN)[4], dividing the process of deploying deep network models on MCUs into 5 steps: ① Build and train the model, determine model size, load, operations, and quantization methods; ② Convert and quantize the model while maintaining acceptable accuracy loss, reducing model size, saving memory, and lowering computational requirements; ③ Convert the quantized version of the model into a C language array and integrate the array with the main application program; ④ Build the binary executable program file; ⑤ Write the constructed binary executable program file to the MCU’s Flash memory, completing the model deployment.
In the ST[5] scheme, the process of deploying deep network models on MCUs is divided into 5 steps: data acquisition, data cleaning, and building deep network models, model conversion and optimization for MCUs, retraining and analyzing the converted and optimized model, and using development tools to convert the model into C source code and generate binary files. Renesas[6] divides the process into 4 steps: building and training the model using deep learning frameworks, model conversion, model validation, and achieving inference on MCUs.
In the RCE-NN[4] scheme, step 1 corresponds to steps ①~③ in Figure 1, step 2 corresponds to step ④ in Figure 1, and steps 3~5 correspond to steps ⑤~⑦ in Figure 1. In the ST[5] scheme, steps 1~4 correspond to steps ①~④ in Figure 1, and step 5 implements the functions of steps ⑤~⑦ in Figure 1. In the Renesas[6] scheme, step 1 corresponds to steps ①~③ in Figure 1, step 2 and step 3 correspond to step ④ in Figure 1, and step 4 corresponds to steps ⑤~⑦ in Figure 1.
It can be seen that the processes and work content of different MCU AI deployment schemes are fundamentally similar and can be summarized into three steps: training and validating the model, model conversion, and generating binary programs for deployment.
1.2Deep Network Function Libraries
Model conversion optimizes, prunes, and quantizes deep network models from servers or PCs to meet the resource and computational limitations of MCU systems, resulting in simplified models for real-time inference on MCUs. Applications run deep network models by calling the deep learning library functions that support MCUs. Some commonly used deep learning frameworks and application development environments have extended the MCU deep learning libraries.
TensorFlow Lite[7] is a tool optimized for device-side deep learning within the TensorFlow framework. By reducing the size of models and binary files, it enables deep learning models to run on devices with MCUs as the processing core. TensorFlow Lite does not limit processor vendors and supports processors based on ARM Cortex-M and RISC-V architectures. TensorFlow Lite for Microcontrollers (TFLm)[8] is a deep learning library that supports MCUs. Figure 2 shows the framework for deploying deep network models using TFLm, where models are first trained in TensorFlow, then converted using TensorFlow Lite to generate compact and efficient models (.tflite). The TFLm C++ library functions are used to load and perform inference on the model on the MCU.
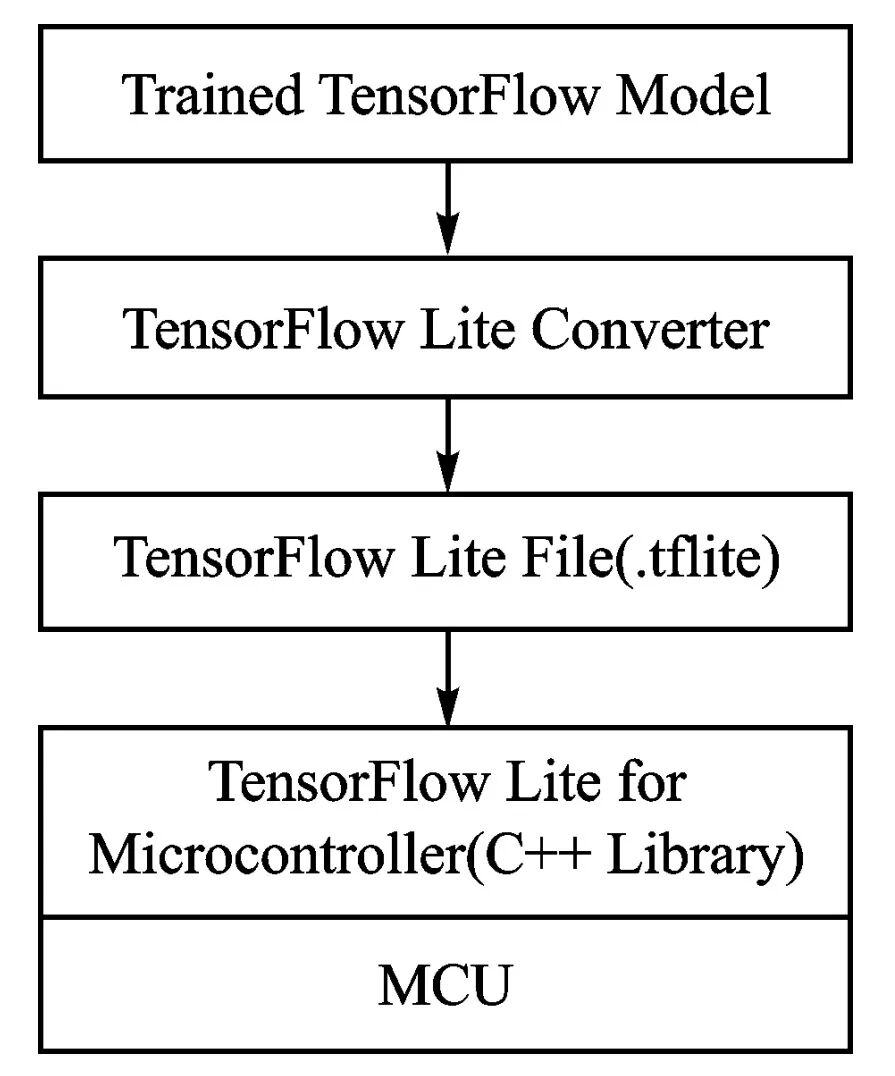
Figure 2 TFLm Deep Network Deployment Framework
Example Python statements for converting a TensorFlow model to a TensorFlow Lite model are as follows:
import tensorflow as tf
from keras.models import load_model
# Load TensorFlow model
model=load_model(“cloths_model.h5”)
# Create model converter
converter=tf.lite.TFLiteConverter.from_keras_model(model)
# Set optimization options
converter.optimizations=[tf.lite.Optimize.DEFAULT]
# Model conversion and quantization
tflite_model_quant=converter.convert()
# Save the converted model
open(“cloths_model.tflite”,”wb”).write(tflite_model_quant)
In this example, the TensorFlow model created with Keras, “cloths_model.h5”, is converted and quantized to the TensorFlow Lite model “cloths_model.tflite”.
ARM has developed a deep learning extension library for the Cortex microcontroller software interface standard (CM-SIS), called CMSIS-NN[9]. CMSIS-NN functions run on Cortex-M series MCUs and support deep network models from major frameworks such as TensorFlow Lite, Caffe2, and PyTorch, providing excellent performance implementations for common layers in deep neural networks. In some simple baseline implementations, acceleration can reach 4~5 times.
Based on the Fast Artificial Neural Network (FANN) library, the open-source toolkit FANN on MCU[10] converts FANN neural network models to lightweight and low-power neural network models that run on ARM Cortex-M and RISC-V architecture MCUs, generating binary programs.
CMix NN[11] is an open-source mixed-precision neural network function library for deploying neural network models on MCU targets.CMix NN supports convolution operations with any convolution kernel of 8-bit, 4-bit, and 2-bit precision. Using the CMix NN library, the MobilenetV1 model was deployed on STM32 MCU devices, achieving an accuracy of up to 68% on the Imagenet classification task Top-1.
1.3Generating C Source Files
Converting the model structure and data into C/C++ source code, then adding it to the application project, integrates the deep network model into the application system. Different development environments have different requirements for converting C/C++ source code. If the environment integrates the MCU deep learning library, only the model’s structure information and parameters need to be exported; otherwise, the operations in the deep network model also need to be converted into C/C++ source code.
Below is a command to export the structure and weight parameters of a TFLm deep network model:[12]:
xxd -i model_integer_only_quantization.tflite > model_quantized.cc
The command converts the model “model_integer_only_quantization.tflite” into the array source file “model_quantized.cc”.
In the application, call the TFLm library functions to run the model. An example program using the TensorFlow Lite C/C++ API is as follows:
# Load and create model Fashion_MNIST_model object Buffer
model=tflite::FlatBufferModel::BuildFromBuffer(Fashion_MNIST_model,Fashion_MNIST_model_len);
# Create interpreter
tflite::ops::builtin::BuiltinOpResolver resolver;
tflite::InterpreterBuilder(*model,resolver)(&interpreter);
# Model inference:
int output=interpreter->outputs()[0];
TfLiteTensor * output_tensor= interpreter->tensor(output);
TfLiteIntArray * output_dims=output_tensor->dims;
Keras2c[13]] developed by Rory Conlin et al. is a tool for converting simple neural network models from Keras/TensorFlow into real-time C code. Keras2c supports most Keras layers and model types, including multi-dimensional convolutions, recurrent layers, multi-input/output models, and shared model layers, implementing the core components of Keras/TensorFlow deep network models in pure C language. The converted C language model relies only on the standard function library of the MCU, making it lightweight and easy to integrate into existing application code. Figure 3 shows the process of Keras2c converting models into C: first, train and optimize the Keras deep network model; then, extract the deep network model structure and parameters using the Keras2c Python script, combining it with Keras2c’s C library to generate C language functions; finally, obtain callable C language deep network functions through automatic validation and testing. Below is an example of using Keras2c for model conversion:
from keras2c import k2c
k2c(my_model,”my_out_model”,num_tests=20)
After converting the my_model model, the generated files include the deep neural network function source code file (*.c), the corresponding header file for the function file (*.h), and the source code file for the model’s test program (*.c).
my_out_model.c;
my_out_model.h;
my_out_model_test_suite.c;;
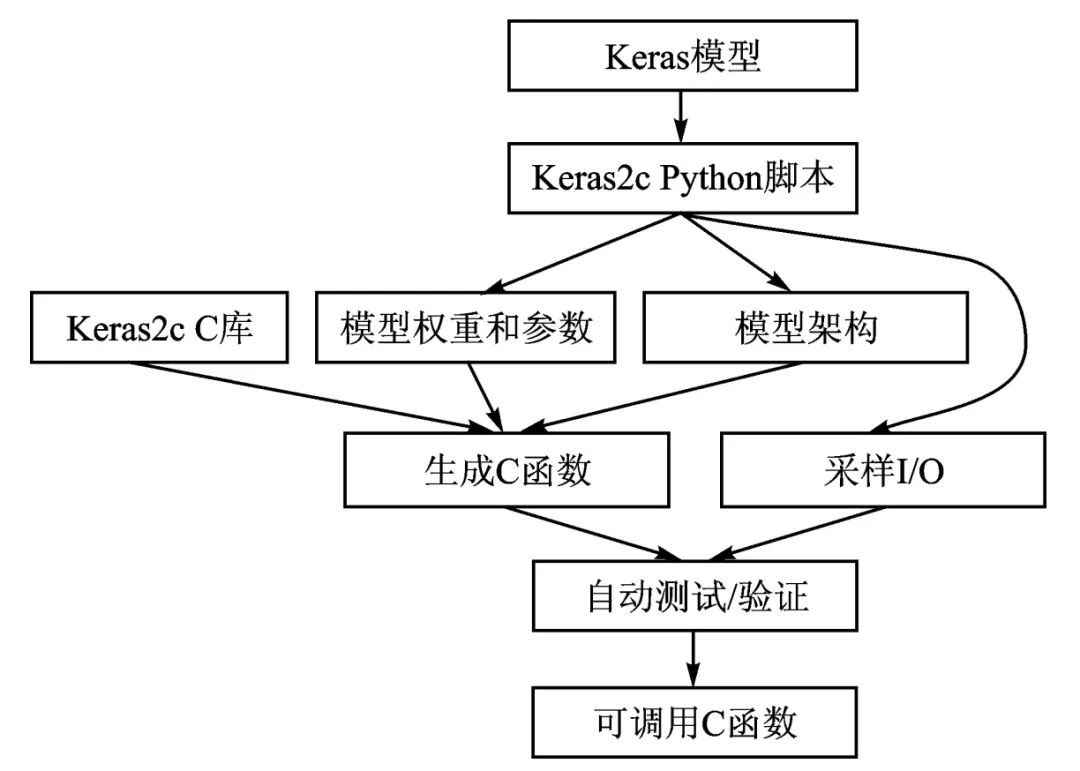
Figure 3 Keras2c Model Conversion Process
2
Model Simplification
The essence of converting deep network models for MCUs is to simplify the models. Typically, model simplification is done from two aspects: ① Pruning[14], which removes connections and modules in the network structure that have minimal impact, thereby simplifying the model structure, reducing computational complexity, and storage space; ② Quantization[15], which quantizes parameters in the model using a smaller numerical range (such as 8-bit, 4-bit, or 2-bit) to reduce the storage space occupied by model parameters.
2.1Pruning
Common pruning methods include weight pruning and neuron pruning. Weight pruning removes connections between neurons in the network with small weight coefficients during training and conversion; neuron pruning removes neurons that have minimal impact on the next layer. Pruning can transform dense neural networks into sparse neural networks.
Figure 4 is a schematic diagram of network model pruning, showing the simplified network structure after some connections and nodes have been pruned.
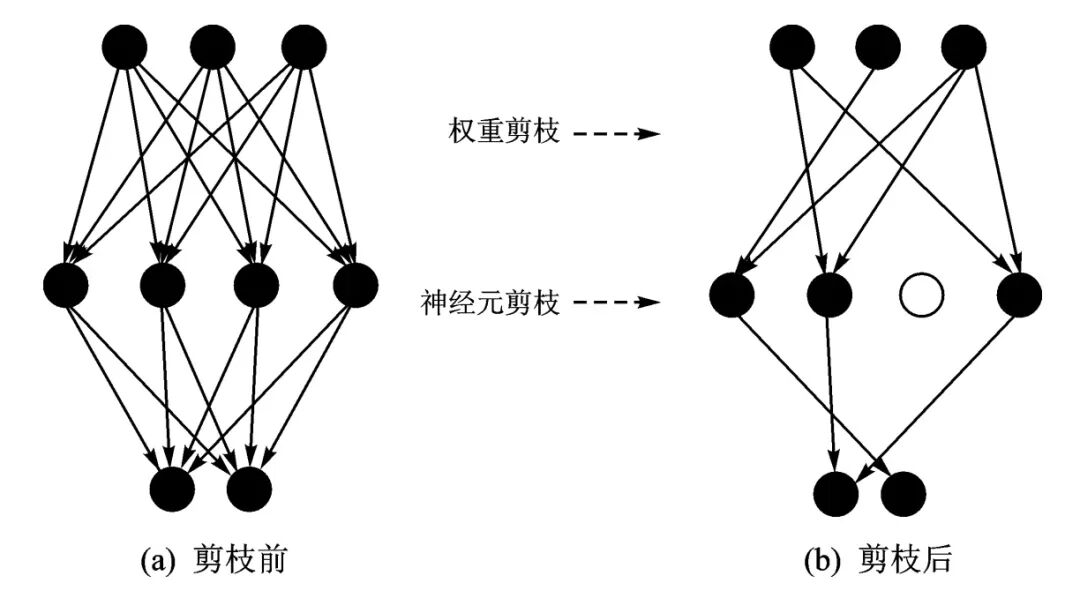
Figure 4 Schematic Diagram of Network Model Pruning
Research results show[16] that pruning common networks such as VGG-16 and ResNet-50 by 95% does not significantly reduce recognition accuracy.
Typical deep network pruning tools include TensorFlow Model Optimization Toolkit, PaddleSlim, Keras-surgeon, etc., and some deep network model conversion and optimization tools for MCUs also have network pruning capabilities.
2.2Quantization
Typically, parameters in neural network models are 32-bit single-precision floating-point numbers. Quantizing parameters can reduce the size of parameter space in the model. Generally, quantization targets include weight coefficients and activation functions.
Weight quantization involves quantizing the weight systems of connections in the neural network using a smaller range of data. For example, a simple method is to reduce the precision of network weights from float to 8 bits, which can reduce the storage space of weights by 3/4. In model conversion projects for MCUs, weight quantization can be achieved through simple command-line tools.
Activation function quantization is more complex, requiring calibration data and calculating the dynamic range of activations. Using quantization libraries provided by model frameworks (such as TensorFlow, PyTorch, etc.) automatically inserts simulated quantization operations during training and inference, achieving quantization-aware training for multiple activation functions.
3
MCU AI Development Environment
To help developers quickly implement AI applications using their own chips, well-known MCU manufacturers such as ST, NXP, Renesas, MicroChip, and TI have successively released MCU AI support libraries and solutions.
3.1eIQ
eIQ[18] is a toolkit released by NXP that supports machine learning development through an intuitive GUI and development workflow tools, as well as eIQ machine learning (ML) command-line host tool options. Developers can create, optimize, debug, and export models, import datasets, and quickly train and deploy neural network models and workloads for AI applications. eIQ can seamlessly output to DeepViewRT, TensorFlow Lite, TensorFlow Lite Micro, Glow, Arm NN, and ONNX runtime inference engines.
Figure 5 shows the eIQ workflow, which can not only convert and deploy existing models but also build and train models before deployment.
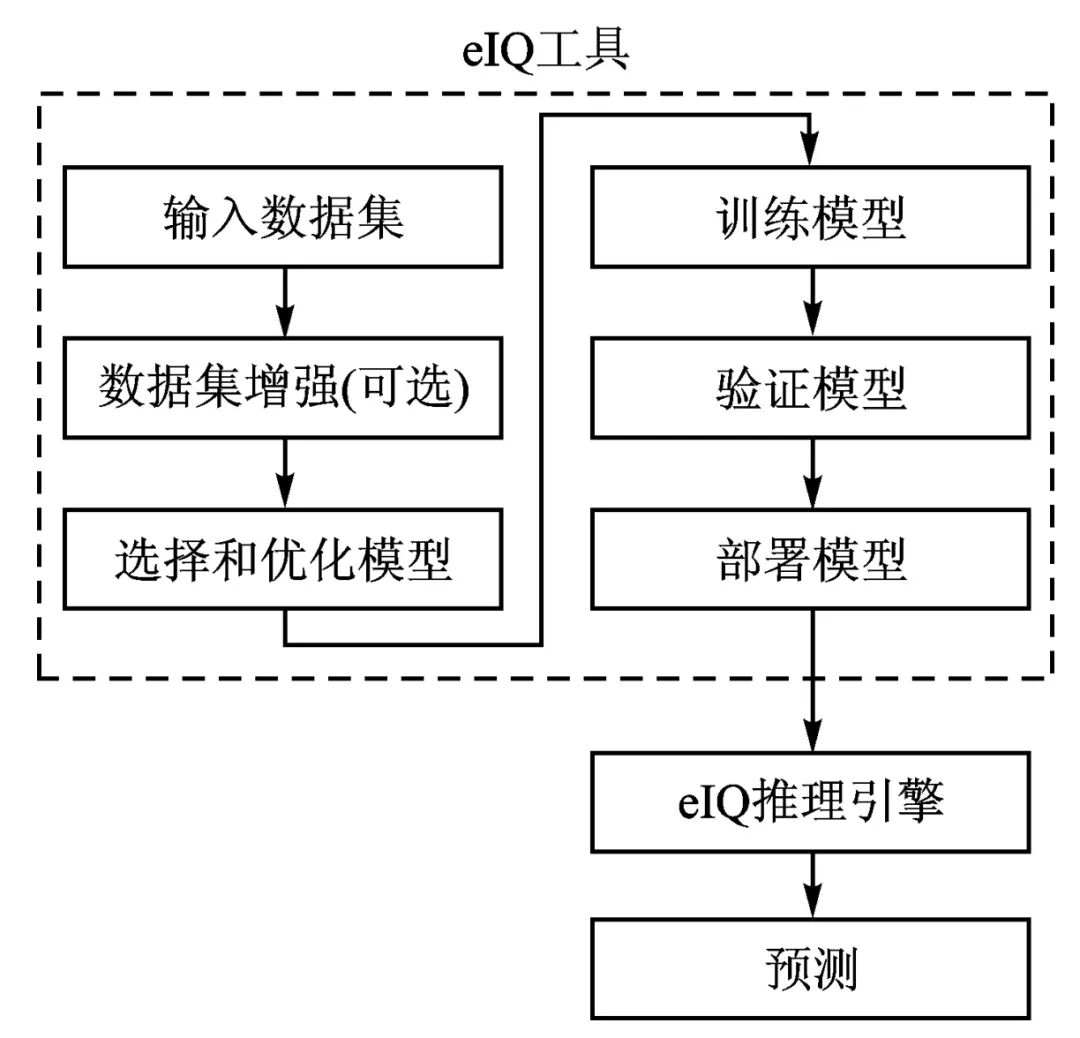
Figure 5 eIQ Project Workflow
3.2STM32Cube.AI
STM32Cube.AI[19] is an AI solution toolkit released by ST for ST series processors. It retrieves trained models from Keras, TensorFlow Lite, and other software, generating optimized code for running on STM32 series MCUs.
X-CUBE-AI[20] is a key part of the STM32Cube.AI expansion package, capable of generating STM32 optimized libraries from pre-trained neural network models, supporting frameworks such as Keras and TensorFlow Lite, and supporting 8-bit quantization of TensorFlow Lite, generating C code for libraries that support STM32Cube.AI and TFLm. Figure 6 shows the workflow of X-CUBE-AI.
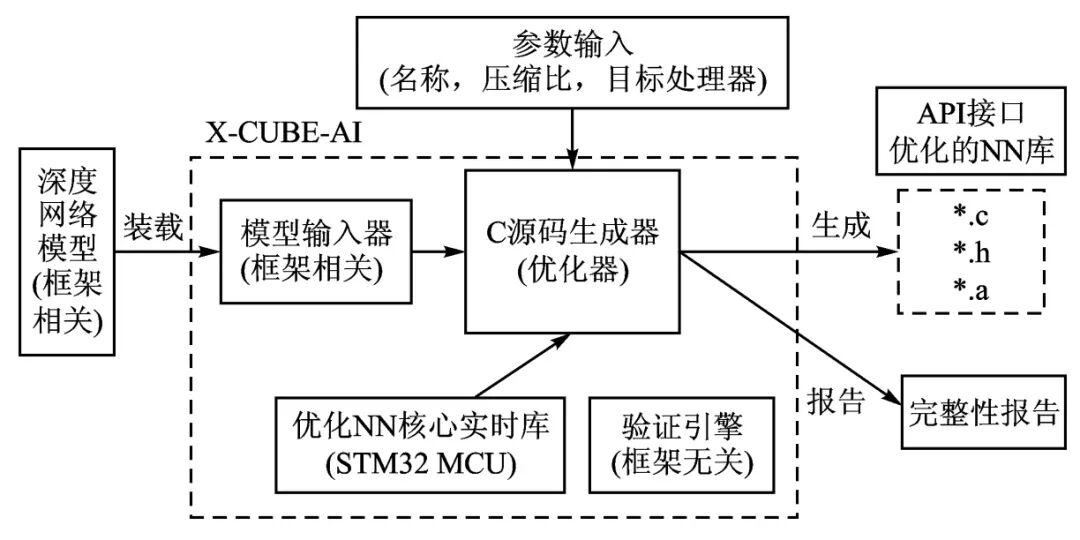
Figure 6 X-CUBE-AI Workflow
3.3e-AI
e-AI[21] is a development tool released by Renesas for implementing artificial intelligence in embedded processor environments. The e-AI development environment for MCU platforms supports multiple models of Renesas MCUs and will convert trained models on PyTorch, Keras, TensorFlow frameworks and TensorFlow Lite models into C source code, importing them into Renesas’s integrated development environment e2 studio. Figure 7 illustrates the e-AI MCU AI development process.
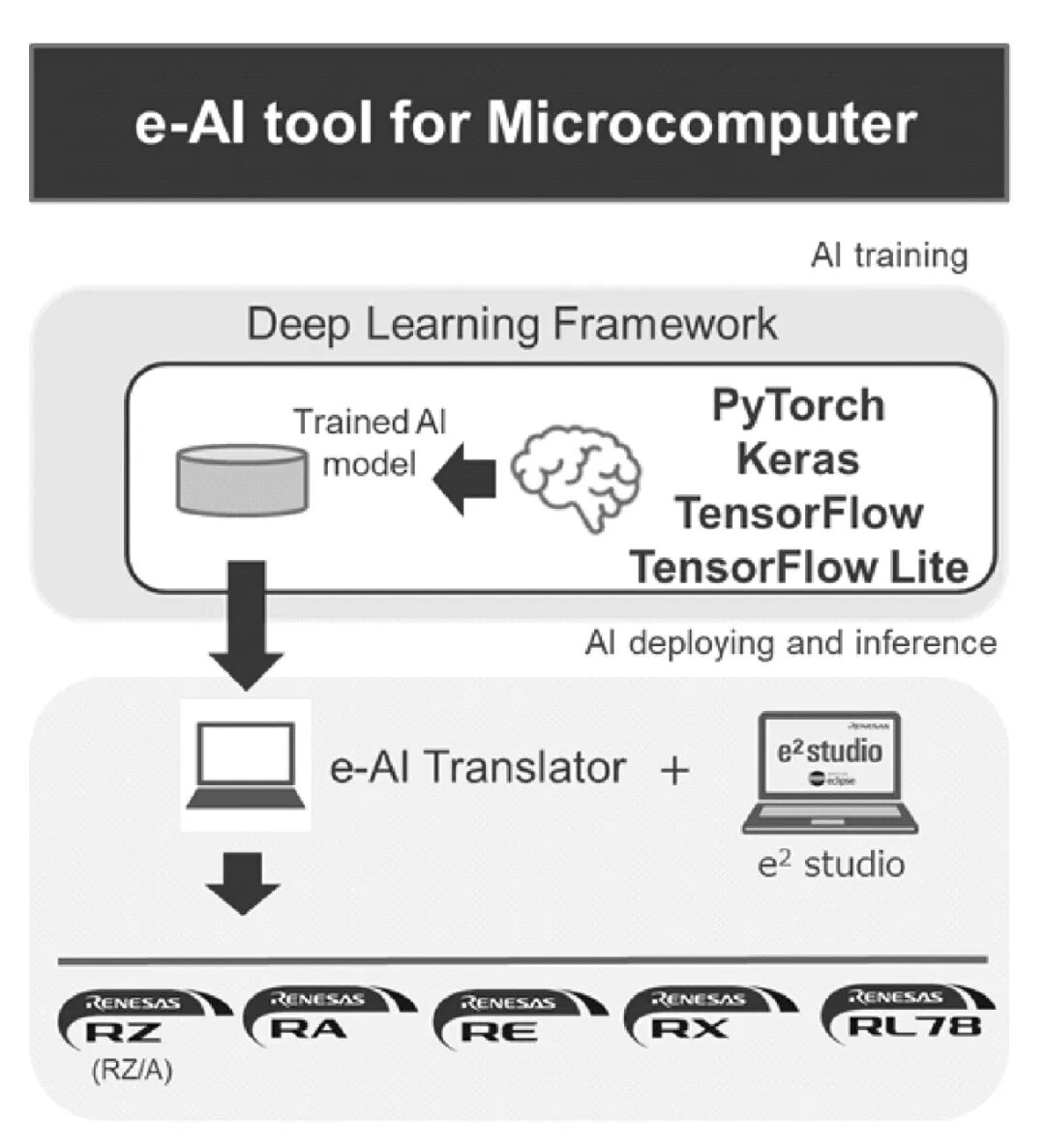
Figure 7 e-AI MCU AI Development Process
In addition, Texas Instruments (TI) has released the TI deep learning library (TIDL), Microchip learning plugins (ML-Plug), etc.
4
Conclusion
The application boom and vast market prospects of intelligent IoT and smart products drive the rapid development of MCU AI technologies, development environments, and tools. Deploying deep network models on MCU platforms is a key focus of MCU AI technology. Mainstream deep learning frameworks such as TensorFlow have developed tools for deep network model development that support MCUs, and several companies and researchers have released multiple machine learning and deep neural network libraries aimed at MCUs. Mature solutions and development tools for deploying deep network models on MCU platforms have been developed, and major MCU chip manufacturers have released MCU AI development tools that support their chips. The market is continuously emerging with MCU AI products that deploy deep network models. The technology and application product development of MCU AI has just begun, and the development prospects are very broad.
References

[1] Krizhevsky Alex, Sutskever Ilya, Hinton Geoffrey E. ImageNet Classification with Deep Convolutional Neural Networks[J]. Advances in Neural Information Processing Systems, 2012(2).
[2] Philip Sparks. The route to a trillion devices[EB/OL].[2021-11].https://community.arm.com/iot/b/blog/posts/white-paper-the-route-to-a-trillion-devices.
[3] Peter Warden, Daniel Stunayake. TinyML[J]. O’REILLY, 2020:32.
[4] Bharath Sudharsan, John G Breslin, Muhammad Intizar Ali. RCE-NN: a five-stage pipeline to execute neural networks (CNNs) on resource-constrained IoT edge devices[C]//Proceedings of the 10th International Conference on the Internet of Things, 2020.
[5] STM32 solutions for Artificial Neural Networks[EB/OL].[2021-11].https://www.st.com/content/st_com/en/eco-systems/stm32-ann.html.
[6] e-AI development environment for microcontrollers [EB/OL].[2021-11].https://www.renesas.com/us/en/application/technologies/e-ai/tool.
[7] TensorFlow Lite[EB/OL].[2021-11].https://tensorflow.google.cn/lite/guide.
[8] TensorFlow Lite for Microcontrollers[EB/OL].[2021-11].https://tensorflow.google.cn/lite/guide.
[9] L Lai, N Suda, V Chandra. CMSIS-NN: Efficient neural network kernels for arm cortex-M CPUs[J]. arXiv: 1801.06601, 2018.
[10] Xiaying Wang, Michele Magno, Lukas Cavigelli, et al. FANN-on-MCU: An Open-Source Toolkit for Energy-Efficient Neural Network Inference[J]. IEEE INTERNET OF THINGS JOURNAL, 2020, 7(5).
[11] Alessandro Capotondi, Manuele Rusci, Marco Fariselli, et al. CMix-NN: Mixed Low-Precision CNN Library for Memory-Constrained Edge Devices[J]. IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS-II: EXPRESS BRIEFS, 2020, 67(5).
(Author affiliations: 1. Chifeng City Construction Vocational Technical School, Chifeng 024005; 2. Peking University, School of Software and Microelectronics)
(This article is authorized for publication by the “Microcontroller and Embedded System Applications” magazine, originally published in the 12th issue of 2021)
END
[Click the “blue text” above to search for more content in the account]
Follow us for more exciting content
Share, like, and check it out!