Processes, Process Descriptors, and Task Structures
What are Processes and Process Descriptors
A process is a program in execution, but it is not limited to just a segment of executable code (also known as the text section); it also includes other resources such as open files, pending signals, internal kernel data, processor state, address space, and one or more execution threads. In other words, a process is the totality of a program in execution and the resources it encompasses. In fact, it is possible for multiple different processes to execute the same program, and multiple concurrent processes can share files and other resources. In the Linux kernel, processes are generally referred to as tasks.
An execution thread, abbreviated as thread, is an active entity within a process, with each thread having its own program counter, process stack, and set of process registers. The kernel’s scheduling entity is the thread, not the process; the process is the basic unit of resource allocation. Typically, a process contains one or more threads, but Linux does not make a special distinction between processes and threads; for Linux, a thread is a special type of process.
Processes provide two virtual mechanisms: virtual processors and virtual memory.
-
Virtual Processor: In reality, multiple processes share the same processor, but the virtual processor mechanism gives the illusion to processes that they have exclusive access to the processor.
-
Virtual Memory: When a process acquires and uses memory, it makes the process feel as if it has access to the entire system’s memory resources.
Threads within the same process can share virtual memory but have their own virtual processors.
A process comes to life when it is created, which in Linux typically occurs at the moment the system call fork() returns. The fork() system call creates a new process (child process) by duplicating an existing process (the process that called fork, the parent process). When the call ends, the parent process resumes execution at the same point where it called fork(), while the child process begins execution. A characteristic of the fork() system call is that it returns twice: once to the parent process at the point where fork() was called, and once to the newly created child process.
We create a new process to execute a new program, but as mentioned above, the fork() system call duplicates an existing process. The way to have the newly created process execute a new program is to call the exec family of functions within the new process, which creates a new address space and loads the new program.
Ultimately, a process can exit using the exit() system call, which releases the resources occupied by the process. The parent process can query whether the child process has terminated using the wait4() system call.
The Linux kernel stores programs in a task queue (task list), which is a doubly linked circular list where each item is of type task_struct, known as a process descriptor. This structure is defined in the <include/linux/sched.h> file, and the process descriptor contains all the information about a specific process. This structure is quite large.
struct task_struct {
#ifdef CONFIG_THREAD_INFO_IN_TASK
/*
* For reasons of header soup (see current_thread_info()), this
* must be the first element of task_struct.
*/
struct thread_info thread_info;
#endif
unsigned int __state;
#ifdef CONFIG_PREEMPT_RT
/* saved state for "spinlock sleepers" */
unsigned int saved_state;
#endif
/*
* This begins the randomizable portion of task_struct. Only
* scheduling-critical items should be added above here.
*/
randomized_struct_fields_start
void *stack;
refcount_t usage;
/* Per task flags (PF_*), defined further below: */
unsigned int flags;
unsigned long trace;
#ifdef CONFIG_SMP
int on_cpu;
struct __call_single_node wake_entry;
unsigned int wakee_flips;
unsigned long wakee_flip_decay_ts;
struct task_struct *last_wakee;
/*
* recent_used_cpu is initially set as the last CPU used by a task
* that wakes affine another task. Waker/wakee relationships can
* push tasks around a CPU where each wakeup moves to the next one.
* Tracking a recently used CPU allows a quick search for a recently
* used CPU that may be idle.
*/
int recent_used_cpu;
int wake_cpu;
#endif
int on_rq;
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
struct sched_entity se;
struct sched_rt_entity rt;
struct sched_dl_entity dl;
const struct sched_class *sched_class;
#ifdef CONFIG_SCHED_CORE
struct rb_node core_node;
unsigned long core_cookie;
unsigned int core_occupation;
#endif
#ifdef CONFIG_CGROUP_SCHED
struct task_group *sched_task_group;
#endif
#ifdef CONFIG_UCLAMP_TASK
/*
* Clamp values requested for a scheduling entity.
* Must be updated with task_rq_lock() held.
*/
struct uclamp_se uclamp_req[UCLAMP_CNT];
/*
* Effective clamp values used for a scheduling entity.
* Must be updated with task_rq_lock() held.
*/
struct uclamp_se uclamp[UCLAMP_CNT];
#endif
struct sched_statistics stats;
#ifdef CONFIG_PREEMPT_NOTIFIERS
/* List of struct preempt_notifier: */
struct hlist_head preempt_notifiers;
#endif
#ifdef CONFIG_BLK_DEV_IO_TRACE
unsigned int btrace_seq;
#endif
unsigned int policy;
int nr_cpus_allowed;
const cpumask_t *cpus_ptr;
cpumask_t *user_cpus_ptr;
cpumask_t cpu_mask;
void *migration_pending;
#ifdef CONFIG_SMP
unsigned short migration_disabled;
#endif
unsigned short migration_flags;
#ifdef CONFIG_PREEMPT_RCU
int rcu_read_lock_nesting;
union rcu_special rcu_read_unlock_special;
struct list_head rcu_node_entry;
struct rcu_node *rcu_blocked_node;
#endif /* #ifdef CONFIG_PREEMPT_RCU */
#ifdef CONFIG_TASKS_RCU
unsigned long rcu_tasks_nvcsw;
u8 rcu_tasks_holdout;
u8 rcu_tasks_idx;
int rcu_tasks_idle_cpu;
struct list_head rcu_tasks_holdout_list;
#endif /* #ifdef CONFIG_TASKS_RCU */
#ifdef CONFIG_TASKS_TRACE_RCU
int trc_reader_nesting;
int trc_ipi_to_cpu;
union rcu_special trc_reader_special;
struct list_head trc_holdout_list;
struct list_head trc_blkd_node;
int trc_blkd_cpu;
#endif /* #ifdef CONFIG_TASKS_TRACE_RCU */
struct sched_info sched_info;
struct list_head tasks;
#ifdef CONFIG_SMP
struct plist_node pushable_tasks;
struct rb_node pushable_dl_tasks;
#endif
struct mm_struct *mm;
struct mm_struct *active_mm;
int exit_state;
int exit_code;
int exit_signal;
/* The signal sent when the parent dies: */
int pdeath_signal;
/* JOBCTL_*, siglock protected: */
unsigned long jobctl;
/* Used for emulating ABI behavior of previous Linux versions: */
unsigned int personality;
/* Scheduler bits, serialized by scheduler locks: */
unsigned sched_reset_on_fork:1;
unsigned sched_contributes_to_load:1;
unsigned sched_migrated:1;
/* Force alignment to the next boundary: */
unsigned:0;
/* Unserialized, strictly 'current' */
/*
* This field must not be in the scheduler word above due to wakelist
* queueing no longer being serialized by p->on_cpu. However:
*
* p->XXX = X; ttwu()
* schedule() if (p->on_rq && ..) // false
* smp_mb__after_spinlock(); if (smp_load_acquire(&p->on_cpu) && //true
* deactivate_task() ttwu_queue_wakelist())
* p->on_rq = 0; p->sched_remote_wakeup = Y;
*
* guarantees all stores of 'current' are visible before
* ->sched_remote_wakeup gets used, so it can be in this word.
*/
unsigned sched_remote_wakeup:1;
/* Bit to tell LSMs we're in execve(): */
unsigned in_execve:1;
unsigned in_iowait:1;
#ifndef TIF_RESTORE_SIGMASK
unsigned restore_sigmask:1;
#endif
#ifdef CONFIG_MEMCG
unsigned in_user_fault:1;
#endif
#ifdef CONFIG_LRU_GEN
/* whether the LRU algorithm may apply to this access */
unsigned in_lru_fault:1;
#endif
#ifdef CONFIG_COMPAT_BRK
unsigned brk_randomized:1;
#endif
#ifdef CONFIG_CGROUPS
/* disallow userland-initiated cgroup migration */
unsigned no_cgroup_migration:1;
/* task is frozen/stopped (used by the cgroup freezer) */
unsigned frozen:1;
#endif
#ifdef CONFIG_BLK_CGROUP
unsigned use_memdelay:1;
#endif
#ifdef CONFIG_PSI
/* Stalled due to lack of memory */
unsigned in_memstall:1;
#endif
#ifdef CONFIG_PAGE_OWNER
/* Used by page_owner=on to detect recursion in page tracking. */
unsigned in_page_owner:1;
#endif
#ifdef CONFIG_EVENTFD
/* Recursion prevention for eventfd_signal() */
unsigned in_eventfd:1;
#endif
#ifdef CONFIG_IOMMU_SVA
unsigned pasid_activated:1;
#endif
#ifdef CONFIG_CPU_SUP_INTEL
unsigned reported_split_lock:1;
#endif
#ifdef CONFIG_TASK_DELAY_ACCT
/* delay due to memory thrashing */
unsigned in_thrashing:1;
#endif
unsigned long atomic_flags; /* Flags requiring atomic access. */
struct restart_block restart_block;
pid_t pid;
pid_t tgid;
#ifdef CONFIG_STACKPROTECTOR
/* Canary value for the -fstack-protector GCC feature: */
unsigned long stack_canary;
#endif
/*
* Pointers to the (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
/* Real parent process: */
struct task_struct __rcu *real_parent;
/* Recipient of SIGCHLD, wait4() reports: */
struct task_struct __rcu *parent;
/*
* Children/sibling form the list of natural children:
*/
struct list_head children;
struct list_head sibling;
struct task_struct *group_leader;
/* 'ptraced' is the list of tasks this task is using ptrace() on.
* This includes both natural children and PTRACE_ATTACH targets.
* 'ptrace_entry' is this task's link on the p->parent->ptraced list.
*/
struct list_head ptraced;
struct list_head ptrace_entry;
/* PID/PID hash table linkage. */
struct pid *thread_pid;
struct hlist_node pid_links[PIDTYPE_MAX];
struct list_head thread_group;
struct list_head thread_node;
struct completion *vfork_done;
/* CLONE_CHILD_SETTID: */
int __user *set_child_tid;
/* CLONE_CHILD_CLEARTID: */
int __user *clear_child_tid;
/* PF_KTHREAD | PF_IO_WORKER */
void *worker_private;
u64 utime;
u64 stime;
#ifdef CONFIG_ARCH_HAS_SCALED_CPUTIME
u64 utimescaled;
u64 stimescaled;
#endif
u64 gtime;
struct prev_cputime prev_cputime;
#ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN
struct vtime vtime;
#endif
#ifdef CONFIG_NO_HZ_FULL
atomic_t tick_dep_mask;
#endif
/* Context switch counts: */
unsigned long nvcsw;
unsigned long nivcsw;
/* Monotonic time in nsecs: */
u64 start_time;
/* Boot based time in nsecs: */
u64 start_boottime;
/* MM fault and swap info: this can arguably be seen as either mm-specific or thread-specific: */
unsigned long min_flt;
unsigned long maj_flt;
/* Empty if CONFIG_POSIX_CPUTIMERS=n */
struct posix_cputimers posix_cputimers;
#ifdef CONFIG_POSIX_CPU_TIMERS_TASK_WORK
struct posix_cputimers_work posix_cputimers_work;
#endif
/* Process credentials: */
/* Tracer's credentials at attach: */
const struct cred __rcu *ptracer_cred;
/* Objective and real subjective task credentials (COW): */
const struct cred __rcu *real_cred;
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred;
#ifdef CONFIG_KEYS
/* Cached requested key. */
struct key *cached_requested_key;
#endif
/*
* executable name, excluding path.
*
* - normally initialized setup_new_exec()
* - access it with [gs]et_task_comm()
* - lock it with task_lock()
*/
char comm[TASK_COMM_LEN];
struct nameidata *nameidata;
#ifdef CONFIG_SYSVIPC
struct sysv_sem sysvsem;
struct sysv_shm sysvshm;
#endif
#ifdef CONFIG_DETECT_HUNG_TASK
unsigned long last_switch_count;
unsigned long last_switch_time;
#endif
/* Filesystem information: */
struct fs_struct *fs;
/* Open file information: */
struct files_struct *files;
#ifdef CONFIG_IO_URING
struct io_uring_task *io_uring;
#endif
/* Namespaces: */
struct nsproxy *nsproxy;
/* Signal handlers: */
struct signal_struct *signal;
struct sighand_struct __rcu *sighand;
sigset_t blocked;
sigset_t real_blocked;
/* Restored if set_restore_sigmask() was used: */
sigset_t saved_sigmask;
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
unsigned int sas_ss_flags;
struct callback_head *task_works;
#ifdef CONFIG_AUDIT
#ifdef CONFIG_AUDITSYSCALL
struct audit_context *audit_context;
#endif
kuid_t loginuid;
unsigned int sessionid;
#endif
struct seccomp seccomp;
struct syscall_user_dispatch syscall_dispatch;
/* Thread group tracking: */
u64 parent_exec_id;
u64 self_exec_id;
/* Protection against (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed, mempolicy: */
spinlock_t alloc_lock;
/* Protection of the PI data structures: */
raw_spinlock_t pi_lock;
struct wake_q_node wake_q;
#ifdef CONFIG_RT_MUTEXES
/* PI waiters blocked on a rt_mutex held by this task: */
struct rb_root_cached pi_waiters;
/* Updated under owner's pi_lock and rq lock */
struct task_struct *pi_top_task;
/* Deadlock detection and priority inheritance handling: */
struct rt_mutex_waiter *pi_blocked_on;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
/* Mutex deadlock detection: */
struct mutex_waiter *blocked_on;
#endif
#ifdef CONFIG_DEBUG_ATOMIC_SLEEP
int non_block_count;
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
struct irqtrace_events irqtrace;
unsigned int hardirq_threaded;
u64 hardirq_chain_key;
int softirqs_enabled;
int softirq_context;
int irq_config;
#endif
#ifdef CONFIG_PREEMPT_RT
int softirq_disable_cnt;
#endif
#ifdef CONFIG_LOCKDEP
# define MAX_LOCK_DEPTH 48UL
u64 curr_chain_key;
int lockdep_depth;
unsigned int lockdep_recursion;
struct held_lock held_locks[MAX_LOCK_DEPTH];
#endif
#if defined(CONFIG_UBSAN) && !defined(CONFIG_UBSAN_TRAP)
unsigned int in_ubsan;
#endif
/* Journalling filesystem info: */
void *journal_info;
/* Stacked block device info: */
struct bio_list *bio_list;
/* Stack plugging: */
struct blk_plug *plug;
/* VM state: */
struct reclaim_state *reclaim_state;
struct backing_dev_info *backing_dev_info;
struct io_context *io_context;
#ifdef CONFIG_COMPACTION
struct capture_control *capture_control;
#endif
/* Ptrace state: */
unsigned long ptrace_message;
kernel_siginfo_t *last_siginfo;
struct task_io_accounting ioac;
#ifdef CONFIG_PSI
/* Pressure stall state */
unsigned int psi_flags;
#endif
#ifdef CONFIG_TASK_XACCT
/* Accumulated RSS usage: */
u64 acct_rss_mem1;
/* Accumulated virtual memory usage: */
u64 acct_vm_mem1;
/* stime + utime since last update: */
u64 acct_timexpd;
#endif
#ifdef CONFIG_CPUSETS
/* Protected by ->alloc_lock: */
nodemask_t mems_allowed;
/* Sequence number to catch updates: */
seqcount_spinlock_t mems_allowed_seq;
int cpuset_mem_spread_rotor;
int cpuset_slab_spread_rotor;
#endif
#ifdef CONFIG_CGROUPS
/* Control Group info protected by css_set_lock: */
struct css_set __rcu *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock: */
struct list_head cg_list;
#endif
#ifdef CONFIG_X86_CPU_RESCTRL
u32 closid;
u32 rmid;
#endif
#ifdef CONFIG_FUTEX
struct robust_list_head __user *robust_list;
#ifdef CONFIG_COMPAT
struct compat_robust_list_head __user *compat_robust_list;
#endif
struct list_head pi_state_list;
struct futex_pi_state *pi_state_cache;
struct mutex futex_exit_mutex;
unsigned int futex_state;
#endif
#ifdef CONFIG_PERF_EVENTS
struct perf_event_context *perf_event_ctxp;
struct mutex perf_event_mutex;
struct list_head perf_event_list;
#endif
#ifdef CONFIG_DEBUG_PREEMPT
unsigned long preempt_disable_ip;
#endif
#ifdef CONFIG_NUMA
/* Protected by alloc_lock: */
struct mempolicy *mempolicy;
short il_prev;
short pref_node_fork;
#endif
#ifdef CONFIG_NUMA_BALANCING
int numa_scan_seq;
unsigned int numa_scan_period;
unsigned int numa_scan_period_max;
int numa_preferred_nid;
unsigned long numa_migrate_retry;
/* Migration stamp: */
u64 node_stamp;
u64 last_task_numa_placement;
u64 last_sum_exec_runtime;
struct callback_head numa_work;
/*
* This pointer is only modified for current in syscall and
* pagefault context (and for tasks being destroyed), so it can be read
* from any of the following contexts:
* - RCU read-side critical section
* - current->numa_group from everywhere
* - task's runqueue locked, task not running
*/
struct numa_group __rcu *numa_group;
/*
* numa_faults is an array split into four regions:
* faults_memory, faults_cpu, faults_memory_buffer, faults_cpu_buffer
* in this precise order.
*
* faults_memory: Exponential decaying average of faults on a per-node
* basis. Scheduling placement decisions are made based on these
* counts. The values remain static for the duration of a PTE scan.
* faults_cpu: Track the nodes the process was running on when a NUMA
* hinting fault was incurred.
* faults_memory_buffer and faults_cpu_buffer: Record faults per node
* during the current scan window. When the scan completes, the counts
* in faults_memory and faults_cpu decay and these values are copied.
*/
unsigned long *numa_faults;
unsigned long total_numa_faults;
/*
* numa_faults_locality tracks if faults recorded during the last
* scan window were remote/local or failed to migrate. The task scan
* period is adapted based on the locality of the faults with different
* weights depending on whether they were shared or private faults
*/
unsigned long numa_faults_locality[3];
unsigned long numa_pages_migrated;
#endif /* CONFIG_NUMA_BALANCING */
#ifdef CONFIG_RSEQ
struct rseq __user *rseq;
u32 rseq_sig;
/*
* RmW on rseq_event_mask must be performed atomically
* with respect to preemption.
*/
unsigned long rseq_event_mask;
#endif
struct tlbflush_unmap_batch tlb_ubc;
union {
refcount_t rcu_users;
struct rcu_head rcu;
};
/* Cache last used pipe for splice(): */
struct pipe_inode_info *splice_pipe;
struct page_frag task_frag;
#ifdef CONFIG_TASK_DELAY_ACCT
struct task_delay_info *delays;
#endif
#ifdef CONFIG_FAULT_INJECTION
int make_it_fail;
unsigned int fail_nth;
#endif
/*
* When (nr_dirtied >= nr_dirtied_pause), it's time to call
* balance_dirty_pages() for a dirty throttling pause:
*/
int nr_dirtied;
int nr_dirtied_pause;
/* Start of a write-and-pause period: */
unsigned long dirty_paused_when;
#ifdef CONFIG_LATENCYTOP
int latency_record_count;
struct latency_record latency_record[LT_SAVECOUNT];
#endif
/*
* Time slack values; these are used to round up poll() and
* select() etc timeout values. These are in nanoseconds.
*/
u64 timer_slack_ns;
u64 default_timer_slack_ns;
#if defined(CONFIG_KASAN_GENERIC) || defined(CONFIG_KASAN_SW_TAGS)
unsigned int kasan_depth;
#endif
#ifdef CONFIG_KCSAN
struct kcsan_ctx kcsan_ctx;
#ifdef CONFIG_TRACE_IRQFLAGS
struct irqtrace_events kcsan_save_irqtrace;
#endif
#ifdef CONFIG_KCSAN_WEAK_MEMORY
int kcsan_stack_depth;
#endif
#endif
#ifdef CONFIG_KMSAN
struct kmsan_ctx kmsan_ctx;
#endif
#if IS_ENABLED(CONFIG_KUNIT)
struct kunit *kunit_test;
#endif
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
/* Index of current stored address in ret_stack: */
int curr_ret_stack;
int curr_ret_depth;
/* Stack of return addresses for return function tracing: */
struct ftrace_ret_stack *ret_stack;
/* Timestamp for last schedule: */
unsigned long long ftrace_timestamp;
/*
* Number of functions that haven't been traced
* because of depth overrun:
*/
atomic_t trace_overrun;
/* Pause tracing: */
atomic_t tracing_graph_pause;
#endif
#ifdef CONFIG_TRACING
/* Bitmask and counter of trace recursion: */
unsigned long trace_recursion;
#endif /* CONFIG_TRACING */
#ifdef CONFIG_KCOV
/* See kernel/kcov.c for more details. */
/* Coverage collection mode enabled for this task (0 if disabled): */
unsigned int kcov_mode;
/* Size of the kcov_area: */
unsigned int kcov_size;
/* Buffer for coverage collection: */
void *kcov_area;
/* KCOV descriptor wired with this task or NULL: */
struct kcov *kcov;
/* KCOV common handle for remote coverage collection: */
u64 kcov_handle;
/* KCOV sequence number: */
int kcov_sequence;
/* Collect coverage from softirq context: */
unsigned int kcov_softirq;
#endif
#ifdef CONFIG_MEMCG
struct mem_cgroup *memcg_in_oom;
gfp_t memcg_oom_gfp_mask;
int memcg_oom_order;
/* Number of pages to reclaim on returning to userland: */
unsigned int memcg_nr_pages_over_high;
/* Used by memcontrol for targeted memcg charge: */
struct mem_cgroup *active_memcg;
#endif
#ifdef CONFIG_BLK_CGROUP
struct request_queue *throttle_queue;
#endif
#ifdef CONFIG_UPROBES
struct uprobe_task *utask;
#endif
#if defined(CONFIG_BCACHE) || defined(CONFIG_BCACHE_MODULE)
unsigned int sequential_io;
unsigned int sequential_io_avg;
#endif
struct kmap_ctrl kmap_ctrl;
#ifdef CONFIG_DEBUG_ATOMIC_SLEEP
unsigned long task_state_change;
# ifdef CONFIG_PREEMPT_RT
unsigned long saved_state_change;
# endif
#endif
int pagefault_disabled;
#ifdef CONFIG_MMU
struct task_struct *oom_reaper_list;
struct timer_list oom_reaper_timer;
#endif
#ifdef CONFIG_VMAP_STACK
struct vm_struct *stack_vm_area;
#endif
#ifdef CONFIG_THREAD_INFO_IN_TASK
/* A live task holds one reference: */
refcount_t stack_refcount;
#endif
#ifdef CONFIG_LIVEPATCH
int patch_state;
#endif
#ifdef CONFIG_SECURITY
/* Used by LSM modules for access restriction: */
void *security;
#endif
#ifdef CONFIG_BPF_SYSCALL
/* Used by BPF task local storage */
struct bpf_local_storage __rcu *bpf_storage;
/* Used for BPF run context */
struct bpf_run_ctx *bpf_ctx;
#endif
#ifdef CONFIG_GCC_PLUGIN_STACKLEAK
unsigned long lowest_stack;
unsigned long prev_lowest_stack;
#endif
#ifdef CONFIG_X86_MCE
void __user *mce_vaddr;
__u64 mce_kflags;
u64 mce_addr;
__u64 mce_ripv : 1,
mce_whole_page : 1,
__mce_reserved : 62;
struct callback_head mce_kill_me;
int mce_count;
#endif
#ifdef CONFIG_KRETPROBES
struct llist_head kretprobe_instances;
#endif
#ifdef CONFIG_RETHOOK
struct llist_head rethooks;
#endif
#ifdef CONFIG_ARCH_HAS_PARANOID_L1D_FLUSH
/*
* If L1D flush is supported on mm context switch
* then we use this callback head to queue kill work
* to kill tasks that are not running on SMT disabled
* cores
*/
struct callback_head l1d_flush_kill;
#endif
#ifdef CONFIG_RV
/*
* Per-task RV monitor. Nowadays fixed in RV_PER_TASK_MONITORS.
* If we find justification for more monitors, we can think
* about adding more or developing a dynamic method. So far,
* none of these are justified.
*/
union rv_task_monitor rv[RV_PER_TASK_MONITORS];
#endif
/*
* New fields for task_struct should be added above here, so that
* they are included in the randomized portion of task_struct.
*/
randomized_struct_fields_end
/* CPU-specific state of this task: */
struct thread_struct thread;
/*
* WARNING: on x86, 'thread_struct' contains a variable-sized
* structure. It *MUST* be at the end of 'task_struct'.
*
* Do not put anything below here!
*/
};This quite large structure, which is the file descriptor, can describe a running program, including its open files, process address space, pending signals, process state, and so on.
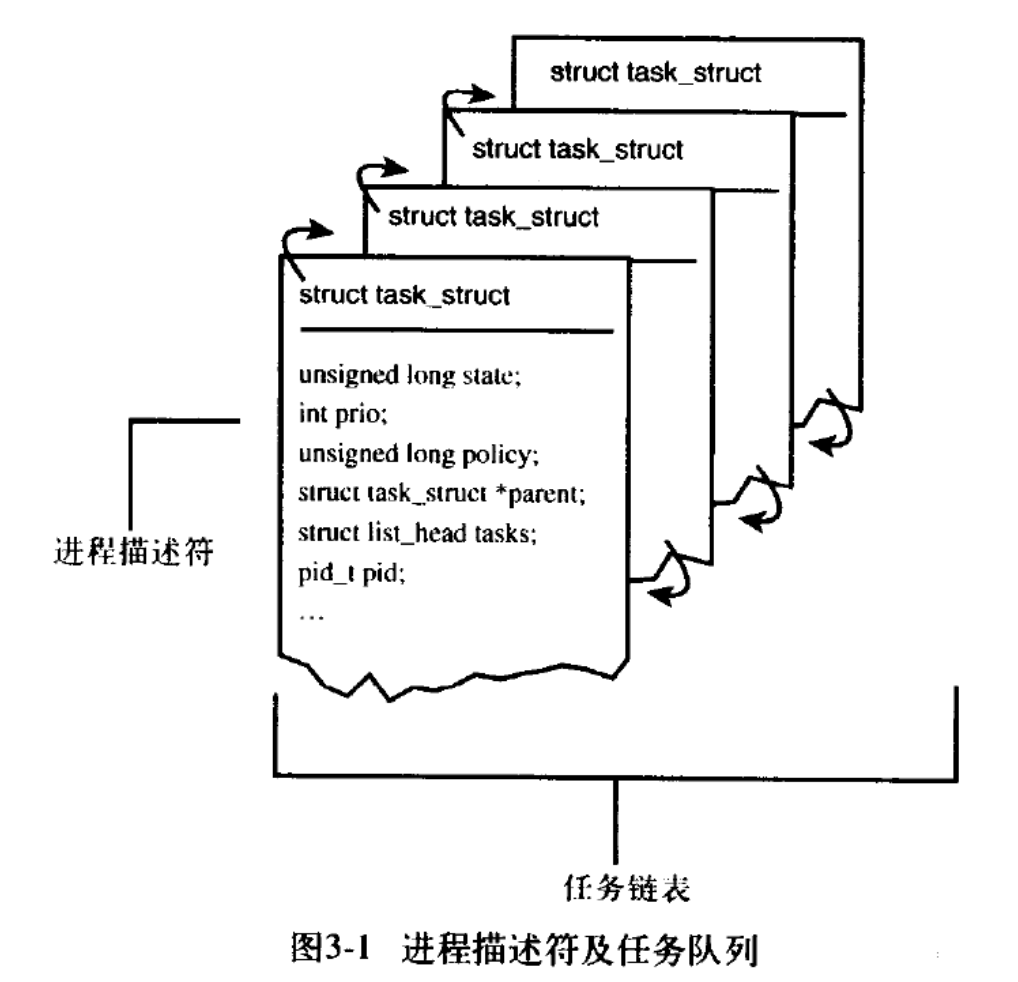
This is how Linux connects all processes using a doubly linked list.
Process Descriptor
Linux allocates the task_struct structure using the slab allocator. By pre-allocating and reusing task_struct structures, it avoids the resource consumption associated with dynamic allocation and deallocation. To quickly and conveniently access the current process’s task_struct, the kernel stores each process’s task_struct at the end of the kernel stack. This way, the position of the task_struct structure can be calculated using the stack pointer, avoiding the need for additional registers, saving resources and improving speed.
Using the slab allocator to dynamically generate task_struct, it is sufficient to create a new struct thread_info at the bottom of the stack (stack grows downwards) or at the top of the stack (stack grows upwards). This makes calculating the address offset of this newly added structure very simple.
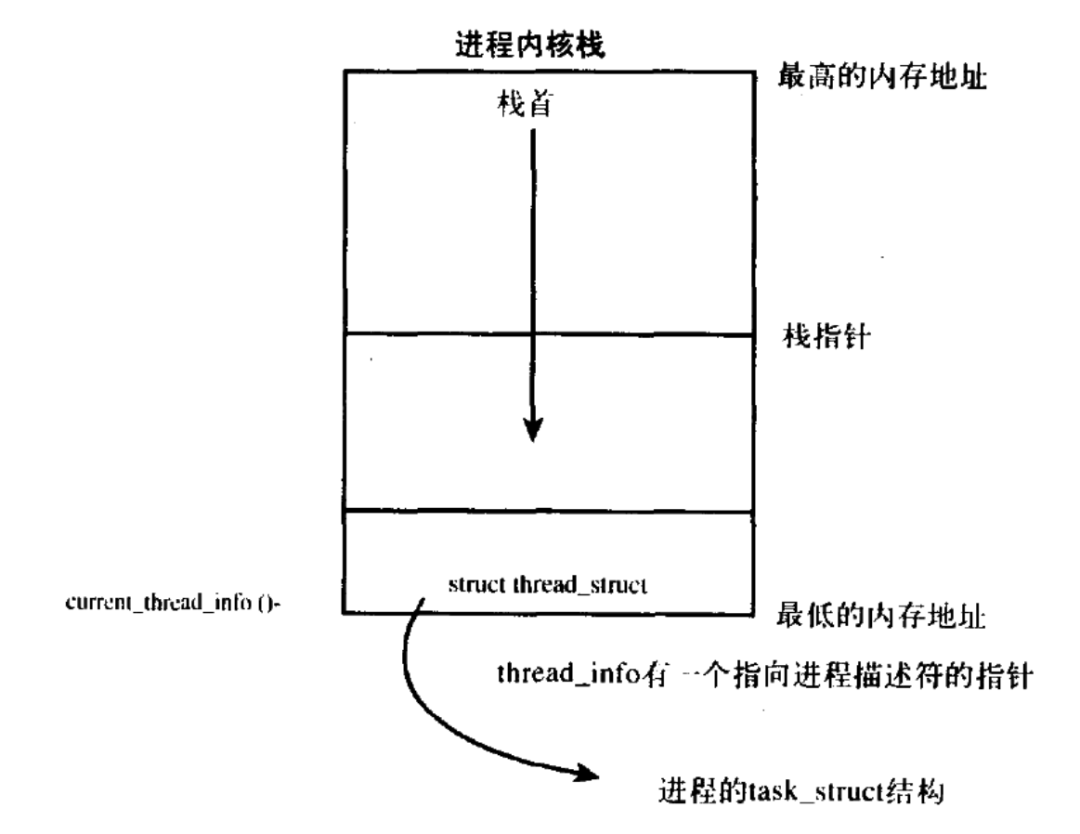
The position of the thread_info structure is in <arch/x86/include/asm>
/* Linux 6.2 */
struct thread_info {
unsigned long flags; /* low level flags */
unsigned long syscall_work; /* SYSCALL_WORK_ flags */
u32 status; /* thread synchronous flags */
#ifdef CONFIG_SMP
u32 cpu; /* current CPU */
#endif
};
/* linux 2.6 */
struct thread_info {
struct task_struct *task; /* Pointer to the actual task_struct of this task */
struct exec_domain *exec_domain;
unsigned long flags;
unsigned long status;
__u32 cpu;
__u32 preempt_count;
mm_segment_t addr_limit;
struct restart_block restart_block;
unsigned long previous_esp;
_u8 supervisor_stack[0];
}The thread_info for each task is allocated at the end of the kernel stack. The code to obtain the task_struct of the currently running process is as follows, located in <current.h>
#include <linux/thread_info.h>
#define get_current() (current_thread_info()->task)
#define current get_current()
struct task_struct;
static inline struct task_struct *get_current(void) {
struct task_struct *current;
__asm__("andl %%esp,%0; ":"=r" (current) : "0" (~8191UL));
return current;
}The kernel identifies each process by a unique process identification value (PID), which is a number of type pid_t, essentially an int type. The maximum default PID is set to 32768 (the maximum value for a short int, which can also be increased to the limits allowed by the type, with the upper limit modifiable in /proc/sys/kernel/pid_max), which effectively is the maximum number of processes that can exist simultaneously in the system. The kernel stores each process’s PID in their respective process descriptors.
In the kernel, most of the code that handles processes operates directly through task_struct. The current process and its process descriptor can be found using the current macro (in current.h). The implementation of this macro is closely related to the hardware architecture; some architectures have rich registers that can directly hold a register dedicated to storing a pointer to the current process’s task_struct, but architectures like x86, which have fewer registers, can only create a thread_info structure at the end of the kernel stack, and find the task_struct structure by calculating the offset, as shown in the macro current_thread_info()->task.
Process States
In the process descriptor, there is a state field that stores the current state of the process. There are five types of process states, and any process must be in one of these five states.
-
TASK_RUNNING: Running state, the process is executable, currently executing, or in the run queue waiting to execute. In kernel space, executing processes are in this state, and in user space, this is also the only state in which a process executes.
-
TASK_INTERRUPTIBLE: Interruptible state, the process is in a sleeping state, blocked, waiting for certain conditions to be met. Once the conditions are met, the kernel will immediately set the process to running state, but it may also be prematurely awakened and put into execution due to receiving a signal.
-
TASK_UNINTERRUPTIBLE: Uninterruptible state, similar to TASK_INTERRUPTIBLE, except that it will not be awakened and put into execution by receiving a signal.
-
TASK_ZOMBIE: Zombie state, indicating that the process has finished, but the parent process has not yet called the
wait4()system call (resources have not yet been reclaimed). At this point, the child process’s process descriptor is still retained, and the parent process can still find the child process’s information through the process descriptor. Once the parent process callswait4(), the child process’s process descriptor will be released.The transformation relationship of the five process states is as follows:
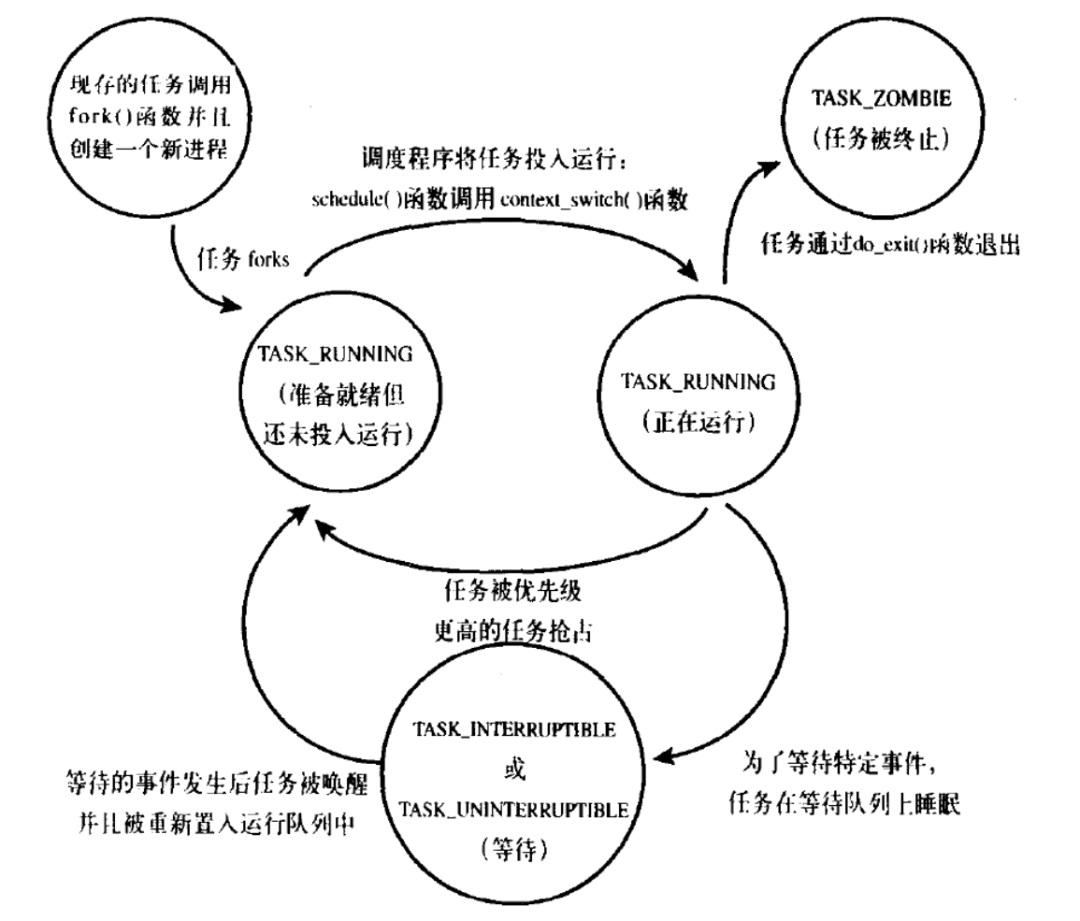
-
TASK_STOPPED: Stopped state, the process is not running and cannot run. This state usually occurs when the process receives signals such as SIGSTOP, SIGTSTP, SIGTTIN, SIGTTOU, etc. Additionally, during debugging, receiving any signal will cause the process to enter this state.
The kernel can change the state of a process using the following function:
set_task_state(task, state);Where task represents the process, and state represents the specified state.
Process Context and Process Family Tree
The executable program code is an important component of a process, and this code is loaded from the executable file into the process’s address space for execution. Generally, programs execute in user space, and when a program calls a system call or triggers an exception, it will trap into kernel space. At this point, we say the kernel is “executing on behalf of the process” and is in the process context. In this context, the current macro is effective. Unless a higher-priority process needs to execute and the scheduler makes the corresponding scheduling, otherwise, when the kernel exits, the program will resume execution in user space.
System calls and exception handlers are explicitly defined interfaces to the kernel; processes can only trap into kernel execution through these interfaces, meaning that all access to the kernel must go through these interfaces.
In the Linux system, all processes have a clear inheritance relationship, meaning that all processes are descendants of the process with PID 1. The kernel starts the init process in the final stage of system startup, which reads the system initialization script initscript and executes other related programs, ultimately completing the entire system startup process.
In the Linux system, each process must have a parent process, and each process can also have zero or more child processes. All processes that share the same parent process are called siblings. The process descriptor stores the inter-process relationships, with each task_struct containing a pointer to its parent process’s task_struct (the parent pointer) and a linked list of child processes (the children list).
For the current process, we can obtain its parent process descriptor or traverse all child processes using the following program:
/* Get parent process descriptor */
struct task_struct *my_parent = current->parent;
/* Traverse child processes */
struct task_struct *task;
struct list_head *list;
list_for_each(list, &current->children) {
task = list_entry(list, struct task_struct, sibling);
/* task points to a child process */
}
/* The init process's process descriptor is statically allocated as init_task.
The inter-process relationship can be described as follows */
struct task_struct *task;
for (task = current; task != &init_task; task = task->parent) {
;
}
/* At this point, task points to init */Through this inheritance system, it is possible to find any other specified process starting from any process in the system, as the task queue itself is a doubly linked circular list. For a given process, the methods to obtain the next and previous processes in the list are as follows:
list_entry(task->tasks.next, struct task_struct, tasks); /* next_task(task) macro */
list_entry(task->tasks.prev, struct task_struct, tasks); /* next_task(task) macro */It is also possible to access the entire task queue sequentially using the for_each_process(task) macro, where each access points the task pointer to the next element in the list:
struct task_struct *task;
for_each_process(task) {
/* Print the name and PID of each task */
printk("%s[%d]\n", task->comm, task->pid);
}
