Abstract
The BPF subsystem in Linux has gained two significant capabilities before the 6.18 merge window:BPF Program Signing (signed BPF) and Deferred Task Context Execution. The signing mechanism provides assurance of the source and integrity of BPF programs loaded into the kernel, paving the way for allowing unprivileged users to load audited BPF programs in the future; its design includes a trusted hash chain and accompanying user/kernel verification logic. The patch from Meta introduces <span><span>bpf_task_work</span></span>, which allows scheduling sleepable BPF callbacks in the context of a task (for example, in an NMI context where “sleeping” is not allowed, the work to be done is first suspended and then executed in a later context where sleeping is permitted), ensuring concurrency safety and lifecycle management through metadata objects, atomic state machines, reference counting, and RCU. These two changes have been merged into the <span><span>bpf-next</span></span> branch and are expected to be further integrated upstream with Linux 6.18.
Background: Why Are These Two Changes Necessary?
BPF (Berkeley Packet Filter) has evolved from an early network filter into a general execution platform for running complex logic in the kernel: it is widely used in scenarios such as observability, network frame processing, tracing, policy, and security. As the number and complexity of BPF programs grow, two pressing issues have emerged: trustworthiness (who is allowed to place programs into the kernel?) and execution context limitations (some contexts cannot sleep and cannot perform blocking operations). To address these issues, the community has pushed for the design and implementation of program signing and a more flexible task context execution interface.
BPF Program Signing (Signed BPF) — Ensuring Source and Reducing Privilege Requirements
What is a “Signed BPF Program”?
A signed BPF program refers to a BPF program (or a combination of loader + metadata) that is digitally signed in user space or during the build chain, with the kernel verifying the signature upon loading to confirm that the program has not been tampered with and comes from a trusted publisher. Here, “signing” is not merely a file hash but involves a trusted hash chain scheme that establishes trust for future payloads and sequences.
Goals and Value
- System Integrity: Prevent unauthorized or tampered BPF programs from executing in the kernel.
- Principle of Least Privilege: Under appropriate security policies, signing allows the kernel to permit unprivileged users to load “audited/signed” BPF programs without granting high privileges such as CAP_BPF or CAP_SYS_ADMIN, thereby reducing the risk of abuse.
Design Highlights
The patch description proposes the idea of a “trusted hash chain”: by signing the combination of the loader instruction stream and related metadata, the kernel can progressively verify the integrity of the program and its context, thus supporting more complex use cases (such as staged loading and sequential verification of multiple payloads). Additionally, libbpf and the kernel loader will work together to support signature verification and provide corresponding testing.
Deferred Task Context Execution (bpf_task_work) — Running Sleepable Callbacks in Task Context
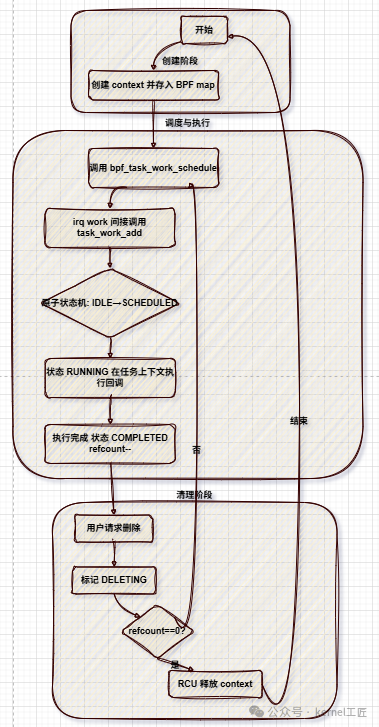 State machine and lifecycle management flowchart of bpf_task_work
State machine and lifecycle management flowchart of bpf_task_work
Question: Why is “Delayed Execution in Task Context” Necessary?
Some BPF use cases require running sleepable operations (such as performing blocking I/O, waiting for resources, or using sleepable APIs), but many contexts that trigger BPF (such as NMI, hard interrupts, or other non-sleepable paths) do not allow sleepable code to be executed directly. Therefore, a mechanism is needed to schedule work back to a “sleepable” task context for execution.
<span><span>bpf_task_work</span></span> What Does It Do?
The patch submitted by Meta introduces a new interface that allows BPF to queue callbacks for execution in the task_work of a specific task (a kernel-level delayed processing mechanism). The patch provides two kernel callable functions (kfuncs) for scheduling task work in different modes:
<span><span>bpf_task_work_schedule_signal()</span></span>— corresponding to<span><span>TWA_SIGNAL</span></span>mode;<span><span>bpf_task_work_schedule_resume()</span></span>— corresponding to<span><span>TWA_RESUME</span></span>mode.
Implementation Details
- Metadata Objects: Implemented through
<span><span>struct bpf_task_work_context</span></span>to manage scheduling states, and pointers to these context objects will be stored in the values of BPF maps for easy reference and reuse by BPF programs. - Concurrency and Lifecycle Management: Uses an atomic state machine (
<span><span>bpf_task_work_state</span></span>) to handle state transitions, combined with reference counting (refcounting) and RCU tasks trace to ensure correctness and safe reclamation in concurrent add/delete scenarios. - Safe Triggering in Non-Sleepable Contexts like NMI: To avoid deadlocks caused by locking in potential NMI contexts, kfuncs indirectly call
<span><span>task_work_add()</span></span>through<span><span>irq_work</span></span><code><span><span>, delegating the actual work addition to the soft interrupt path.</span></span>
Application Scenarios: What Problems Can Each Function Solve?
Applicable Scenarios for Signed BPF
- Enterprise Policies: In cloud/platform environments, operators can batch sign and distribute audited BPF for network policies, auditing, and security monitoring without opening loading capabilities to any unprivileged users.
- Supply Chain Integrity: Combined with the build chain (CI) and HSM, it can ensure that production environments only accept BPF from trusted build pipelines.
Applicable Scenarios for bpf_task_work
- Safely scheduling sleepable BPF code from high-priority or non-sleepable contexts (such as NMI, hardirq) (e.g., waiting for asynchronous I/O, blocking resource acquisition).
- Allowing the writing of more complex, blocking BPF subprograms, thereby expanding BPF’s capabilities in system maintenance, file systems, or more complex network protocol handling.
Conclusion
These patches reflect two directions in the evolution of the BPF ecosystem from “functionality available” to “controllable, auditable” and “more expressive execution models.” The signing work elevates the security of the BPF supply chain; <span><span>bpf_task_work</span></span> expands BPF’s execution capabilities from “non-sleep safe fast paths” to a broader semantic space of “safely scheduling sleepable subprograms.” Together, they will make BPF more trusted and practical in platform orchestration, security policies, and complex system programming. Unless unexpected issues arise, these changes are expected to merge upstream with Linux 6.18.
References and Sources
https://git.kernel.org/pub/scm/linux/kernel/git/bpf/bpf-next.git/commit/?h=for-next&id=348f6117c16ae89a06f53ec6dc893bd7b7a724b4
Thank you for reading. Feedback and comments are welcome.