High-Performance Computing (HPC) is a technology that utilizes multiple computer processors to perform large-scale computational tasks. Through parallel processing and distributed computing, HPC can handle massive amounts of data, achieving high-performance scientific computing, engineering simulations, and data analysis. With the rise of AI, HPC systems are increasingly expanding from parallel processing of large complex problems (such as climate simulation, quantum computing, genome analysis, etc.) to the field of big data analysis. By mining and analyzing vast amounts of data, HPC provides computational power to quickly uncover hidden patterns and trends in the data, supporting business decision-making. It has been observed that HPC achieves the allocation and management of computing resources (processors) and storage resources through cluster management systems and job scheduling systems (such as LSF, PBS, etc.). Virtualization also aims to improve resource utilization by abstracting physical hardware (such as CPU, memory, storage) to create virtual instances (virtual machines or containers), supporting multi-task isolation and flexible resource allocation. It seems that both aim to achieve one goal—resource scheduling and allocation. So, are the two the same? It is difficult to simply say yes or no, as there are both connections and distinctions in terms of management functions. However, the differences outweigh the connections, especially in aspects such as functional applications, technical principles, system architecture, and construction costs. First, let’s look at a system architecture diagram of HPC: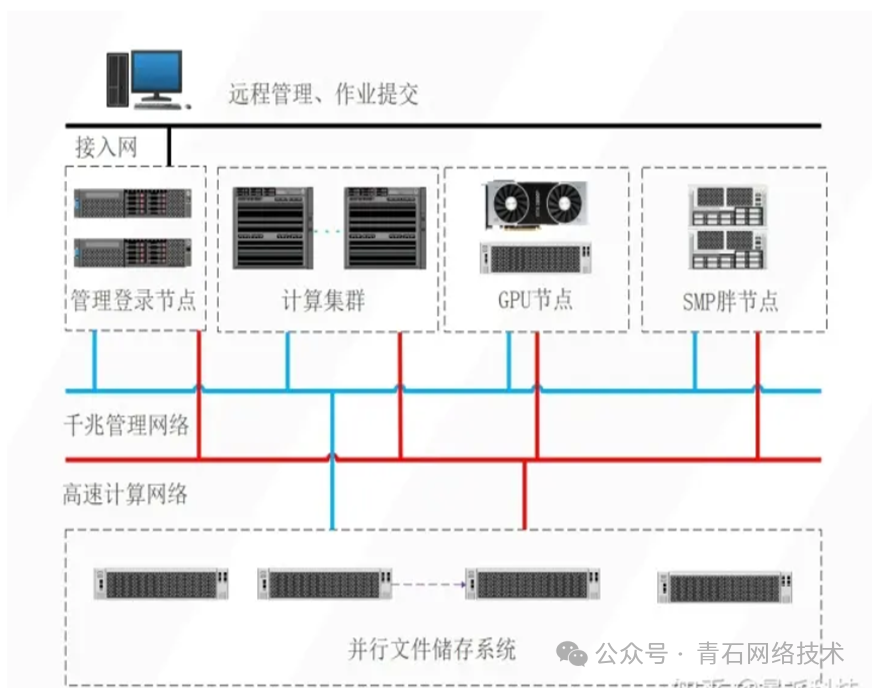 HPC System Architecture The entire system consists of two networks: one is a standard IP network, and the other is a high-speed Infiniband network, all directly connected to bare metal. The purposes are also divided into two types: parallel cluster nodes are connected via Gigabit Ethernet, while high-concurrency, high-throughput fat node servers are interconnected via IB network. The hardware resources such as processors and memory are uniformly scheduled and allocated by the LSF software on the management node server (manual allocation, not automatic), fulfilling the job’s demand for storage and computational resources and controlling the progress of job computation. The server virtualization system mainly operates on the IP network, as shown in the architecture diagram below:
HPC System Architecture The entire system consists of two networks: one is a standard IP network, and the other is a high-speed Infiniband network, all directly connected to bare metal. The purposes are also divided into two types: parallel cluster nodes are connected via Gigabit Ethernet, while high-concurrency, high-throughput fat node servers are interconnected via IB network. The hardware resources such as processors and memory are uniformly scheduled and allocated by the LSF software on the management node server (manual allocation, not automatic), fulfilling the job’s demand for storage and computational resources and controlling the progress of job computation. The server virtualization system mainly operates on the IP network, as shown in the architecture diagram below: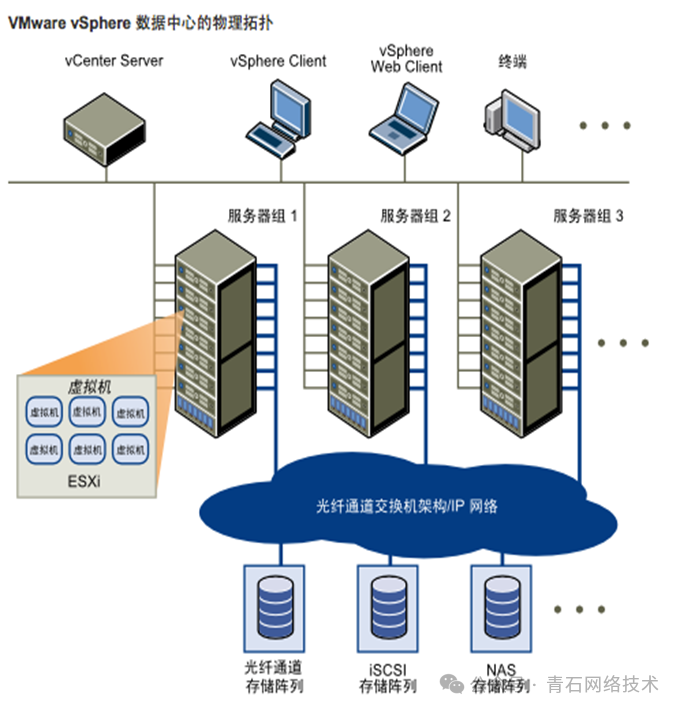 Server Virtualization System Architecture It can be seen that server virtualization can also have two networks; in addition to the IP network connecting the servers, the backend can also use an FC-SAN fiber storage network. Vcenter serves as the management end of the system, supporting dynamic resource scheduling and allocation (for hosts and virtual machines), optimizing resource availability and allocation methods. In simple terms, it allocates physical machine processor and memory resources to virtual machines, optimizing layout to ensure maximum resource utilization. Both systems have servers and storage, but the networking technologies are different, the IB network of the HPC system is very expensive, and the LSF/PBS job scheduling software costs nearly a million. In contrast, the server virtualization suite costs only about 100,000 yuan. Moreover, it does not require an IB network; IPSAN can achieve high-speed and stable operation. There are already cloud products (AWS ParallelCluster, Azure HPC) that utilize virtualization technology to provide on-demand scalable HPC resources, allowing users to run HPC jobs through virtual machines or containers, balancing performance and cost. With the development of containers, hardware-accelerated virtualization (such as DPU), and cloud-native technologies, the boundaries between HPC and virtualization are gradually blurring, with both collaborating to enhance elastic scaling, resource management, and heterogeneous computing scenarios. Lightweight simulation computing can be deployed on cloud platforms, but for high-concurrency, high-throughput solving operations (such as Genome-Wide Association Studies (GWAS)), physical IB networks are still required.
Server Virtualization System Architecture It can be seen that server virtualization can also have two networks; in addition to the IP network connecting the servers, the backend can also use an FC-SAN fiber storage network. Vcenter serves as the management end of the system, supporting dynamic resource scheduling and allocation (for hosts and virtual machines), optimizing resource availability and allocation methods. In simple terms, it allocates physical machine processor and memory resources to virtual machines, optimizing layout to ensure maximum resource utilization. Both systems have servers and storage, but the networking technologies are different, the IB network of the HPC system is very expensive, and the LSF/PBS job scheduling software costs nearly a million. In contrast, the server virtualization suite costs only about 100,000 yuan. Moreover, it does not require an IB network; IPSAN can achieve high-speed and stable operation. There are already cloud products (AWS ParallelCluster, Azure HPC) that utilize virtualization technology to provide on-demand scalable HPC resources, allowing users to run HPC jobs through virtual machines or containers, balancing performance and cost. With the development of containers, hardware-accelerated virtualization (such as DPU), and cloud-native technologies, the boundaries between HPC and virtualization are gradually blurring, with both collaborating to enhance elastic scaling, resource management, and heterogeneous computing scenarios. Lightweight simulation computing can be deployed on cloud platforms, but for high-concurrency, high-throughput solving operations (such as Genome-Wide Association Studies (GWAS)), physical IB networks are still required.