 Click the blue textto follow us
Click the blue textto follow us
With thedevelopment ofLLM, the importance of accelerators capable of efficiently processingLLM computations has become increasingly prominent. This article discusses the necessity ofLLM accelerators and provides a comprehensive analysis of the main hardware and software features of currently available commercialLLM accelerators. Based on this, it proposes development ideas and future research directions for the next generation ofLLM accelerators.
Introduction
With the success ofChatGPT, research and development ofLLM and its applications have accelerated. Recently, in addition to traditional text-based chatbots, multimodalLLM capable of processing text, images, audio, and video have emerged. As these models become increasingly complex, the data requirements for training and inference, along with the associated hardware costs, have also grown exponentially.
GPUs are commonly used forLLM training and inference due to their versatility and availability. However, the high power consumption ofGPUs leads to thermal issues, necessitating expensive cooling systems. Therefore, optimizing hardware forLLM computations is crucial for reducing costs.
LLM accelerators are specifically designed to enhanceLLM computations and are currently being developed in various forms. Unlike general-purposeGPUs, LLM accelerators utilize dedicated circuits to improve efficiency, providing higher performance with lower energy consumption. While advancements in hardware are critical, the supporting software stack is also becoming increasingly important.
This article analyzes the hardware and software ofLLM accelerators, particularly off-the-shelfLLM accelerators. Based on this, it discusses the fundamental elements and challenges faced byLLM accelerators, specifically those implemented asASICs for commercialLLM accelerators. This article aims to analyze the characteristics of proprietaryLLM accelerators, identify the challenges they face, and propose future research directions.
Types of LLM Accelerators
Based on hardware architectures optimized forLLM computations, the main types ofLLM accelerators includeGPUs,ASICs,FPGAs.
GPUs are the most widely usedLLM accelerators, capable of quickly processing large amounts of data due to their highly parallel structure. They can execute multiple threads simultaneously and achieve parallel processing through multiGPU interconnect technologies.
FPGALLM accelerators implemented in the form ofFPGAs provide an intermediate platform betweenASICs andGPUs, offering programmable flexibility and a degree of optimization forLLM computations. They can adapt to newLLM architectures or algorithms through relatively flexible hardware reconfiguration and have relatively low power consumption.
ASIC-basedLLM accelerators are chips tailored forLLM computations. UnlikeFPGAs,ASICs are optimized for specific tasks, providing excellent efficiency. They can optimize memory usage inLLM computations and typically have lower power consumption thanGPUs.
Requirements for Accelerators
In addition to efficiently processingTransformer blocks,LLM accelerators must also meet various requirements, such asmulti-head attention and feedforward operations, which are widely used inLLM training and inference.
Low Power Consumption: LLM accelerators require higher throughput and lower power consumption thanGPUs, necessitating collaborative hardware and software design to achieve energy-efficient computing. Optimizing memory and host-accelerator interfaces, as well as compiler technologies, is essential.
Low Latency: Reducing inference latency is critical forLLM services. Techniques such astiling andpipelining can decomposeLLM computations into smaller units for optimal processing. Current research has also proposed methods to optimize data transfer between accelerators and memory or between accelerators.
High Memory Capacity: Models likeLlama 3.1 have up to405 billion parameters, requiring a large amount of memory.Inference requires1,944 GB or972 GB to achieve32 or16 bit precision, equivalent to about24 or12 NVIDIA H100 80GB GPUs. Efficient memory management also requires optimizing queries, keys, and values for storing and loading models.
Support for Mixed Precision: To reduce the memory required duringLLM training and inference, methods such as quantization are used to reduce memory usage. While 4-bit and 8-bit formats are employed, operations like addition withinTransformer blocks require mixed precision.
Support for Parallel Processing: AsLLM models grow larger, executing them on a single accelerator becomes more challenging. Parallel and distributed training and inference techniques using multiple accelerators are necessary.
Overview of LLM Accelerators
For the analysis ofLLM accelerators, we selectedNVIDIA H100,AMD MI300X,Cerebras WSE-2,Google TPU v4,Graphcore IPU,Groq LPUP,Intel Gaudi 3,SambaNova SN40L, andTenstorrent Grayskull.
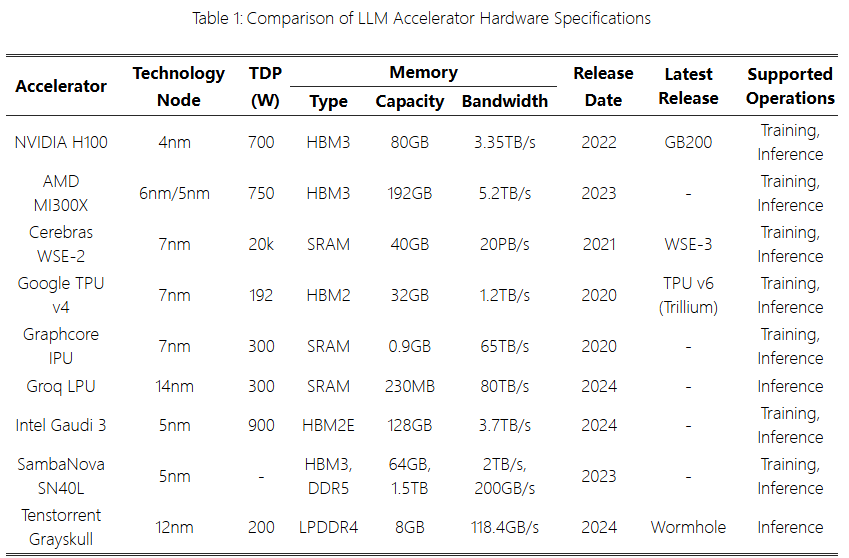
Hardware Characteristics
Memory and Performance
Table 1 shows the specifications of eachLLM accelerator, including memory and power consumption. TDP refers to thermal design power, GB indicates gigabytes, and TB indicates terabytes.
NVIDIA H100 (SXM) is widely used forLLM training and inference, consisting of132 Streaming Multiprocessors (SMs) each equipped with tensor cores, caches, etc.
AMD MI300X adopts a chip architecture, utilizing8 accelerator composite chips for acceleration.
“Cerebras”WSE-2 is a wafer-scale chip, with an area 55 times larger than a typicalGPU chip (WSE-2: 46255 mm2; NVIDIA A100: 826 mm2), containing850,000 cores. It usesSRAM to provide40 GB of memory, but its drawback is extremely high power consumption, exceeding20k W.
Google TPU v4 consists of two TensorCores. TPU follows an optical reconfigurable network architecture, suitable for large-scale machine learning tasks, enabling distributed processing at supercomputer scale by connecting up to4,096 chips.
Graphcore IPU consists of1472 independent processor cores dedicated to large-scale parallel processing. EachIPU is equipped with900 MB ofSRAM, with SRAM allocated to each processing unit within the IPU, called atile, providing fast data communication based on the processor’s internal memory architecture.
Groq LPU consists of software-definedTSP (Tensor Streaming Processor) for large-scale computing. Through network interconnection, it can scale up to10440 TSPs. Equipped with230 MB ofSRAM, it requires hundreds ofLPUs to run models likeLlama 70B, leading to significant power consumption and operational cost issues.
Intel Gaudi 3 provides high parallel processing performance through8 matrix multiplication engines (MMEs) and64 tensor processing cores (TPCs. It is equipped with128 GB HBM2E, supporting over3TB/s bandwidth.
SambaNova SN40L consists of1040 distributed pattern computing units for computation. Unlike otherLLM accelerators, it features a three-tier memory system composed ofHBM,DRAM, andSRAM. This memory configuration achieves high parallelism by fusing hundreds of complex operations into a single kernel call using streaming data flow, thus supporting performance improvements.
Tenstorrent Grayskull adopts a RISC-V based architecture, designed to intelligently process and move data through an on-chip network (NoC) structure, utilizing up to120 computing cores calledTensix cores.
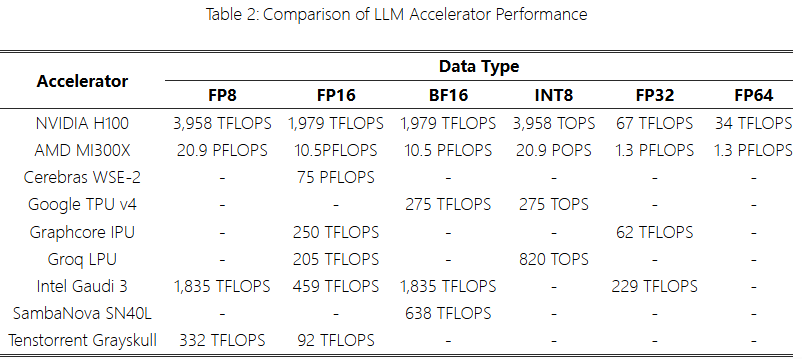
Performance of eachLLM accelerator is shown in Table 2.
Interconnect
Another important aspect ofLLM accelerators is interconnectivity. As the scale ofLLM grows, processing them with a single accelerator becomes challenging, making interconnect technologies within and between accelerators extremely important. The interconnect status of variousLLM accelerators is shown in Table 3.
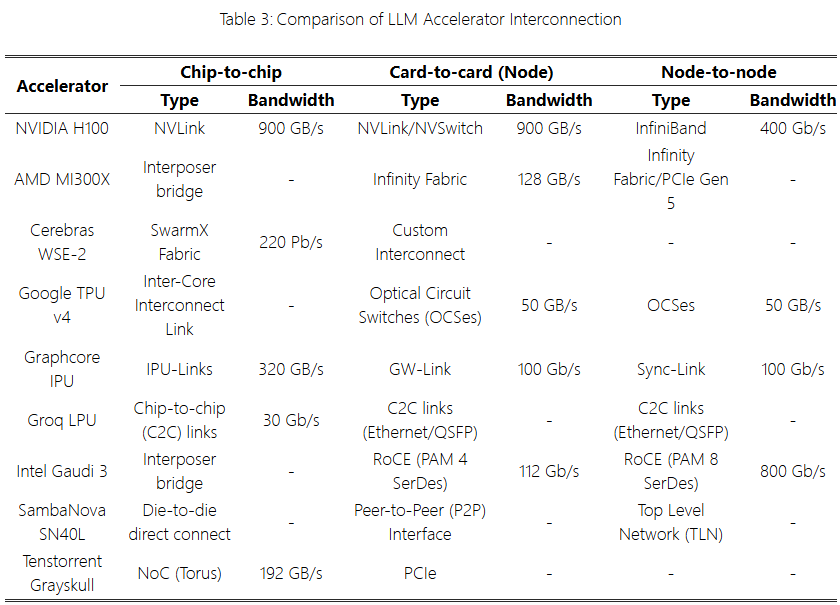
NVIDIA H100(SXM) supports proprietaryNVLink,NVSwitch, andInfiniBand (Mellanox/NVIDIA) interconnects. NVLink is used for communication betweenGPUs, typically providing higher bandwidth thanPCIe. NVSwitch connects largeGPU clusters, managing and processing large-scale network traffic. InfiniBand is a high-speed communication technology between computing nodes, supportingRDMA (Remote Direct Memory Access) technology, primarily used inHPC (High-Performance Computing) and data centers.NVIDIA providesNVIDIA Collective Communication Library (NCCL) to support optimal parallel processing across multipleGPUs.
AMD MI300X uses proprietaryInfinity Fabric to support high-bandwidth interconnects. Infinity Fabric Mesh provides128gb /s bidirectional links for accelerators.AMD also offersROCm communication collective library (RCCL), for communication between multipleLLM accelerators.
Google TPU v4 supports low-latency data transfer between chips viaICI (Inter-Chip Interconnect). Multiple connectedTPUs are referred to asTPU Pods, which can be reconfigured throughOCS (Optical Circuit Switch) to achieve communication between TPU Pods, enhancing scalability and flexibility compared to traditional electronic switches.
Intel Gaudi 3 supports high-speed data interconnects through integrated Ethernet-basedRDMA (RDMA over Converged Ethernet, RoCE) network technology. RoCE implements the RDMA protocol over Ethernet, enabling low-latency data transfer through direct data transmission between accelerators.Gaudi 3 facilitates large-scale parallel data transmission through RDMA network cards, providing high scalability and communication efficiency. Intel also offers optimization techniques for multi-device interconnects through the InteloneAPI Collective Communication Library (oneCCL).
Tenstorrent Grayskull allows data exchange between cores through a two-dimensional bidirectional toroidal network. It is designed based on a data flow architecture, providing high efficiency in parallel computing environments. However,PCIe is used for card-to-card communication.
Other accelerators such asGraphcore IPU support accelerator clusters throughIPU-link andGW-Link, whileCerebras WSE-2,Groq LPU, andSambaNova SN40L support communication between multiple accelerators using custom interconnects.
Software Features
One important aspect ofLLM accelerators is compatibility with existingLLM software. Frameworks likeTensorFlow, PyTorch, andJAX are commonly used for machine learning and deep learning, as well as frameworks specifically designed forLLM development, such asvLLM andDeepSpeed, are being utilized. Table 4 shows the software support status for proprietaryLLM accelerators. “✓” indicates official support within the framework, while “▲” indicates unofficial or experimental support. When the product name is enclosed in parentheses, it indicates support for that hardware.
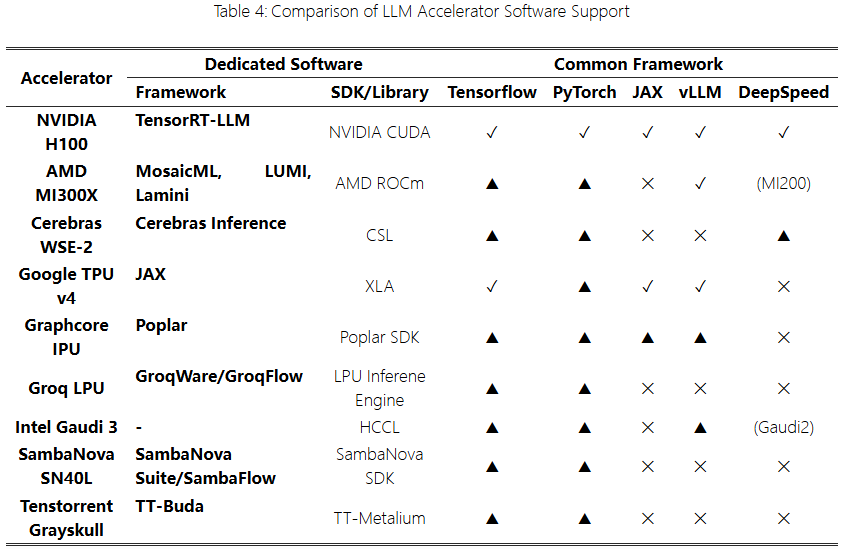
NVIDIA H100 is one of the representatives ofLLM accelerators, widely supported by various frameworks due to its extensive application inLLM. NVIDIA provides dedicated frameworks such as TensorRT-LLM and executes computational acceleration throughNVIDIA CUDA libraries.
LLM accelerators likeAMD MI300X,Cerebras WSE-2, and Google TPU v4 also support various proprietary frameworks and hardware acceleration libraries. ExistingLLM frameworks that do not officially supportLLM accelerators have modified versions of the framework source code, adding compiler and model conversion code to support their hardware. They can also use methods to convert code or models developed in existing frameworks into compatible models, such asONNX, and connect them to their proprietary frameworks.
To support variousLLM, eachLLM accelerator optimizes base models to fit its hardware and distributes them. However, due to the challenges of supporting all models, there are differences in the models that each accelerator can train and infer.
Challenges and Future Directions for LLM Accelerators
Memory: As the scale ofLLM increases, the required memory capacity also grows. While HBM is adopted to meet these demands, the complex manufacturing process of HBM leads to rising prices forLLM accelerators. With the continuous increase in the scale ofLLM, new solutions are needed. Although LLM accelerators equipped with SRAM or LPDDR have been proposed as alternatives to HBM, these may not be sufficient to meet future demands.
Low Power Consumption: The TDP range of theLLM accelerators analyzed in this article is from192W to20kW. In particular, the power consumption ofAMD MI300X andIntel Gaudi 3 is higher than that ofNVIDIA H100 by50-200W. Additionally, asLLM services require multiple accelerators, the total system power consumption increases sharply.
Scalability: MostLLM accelerators use interconnects developed by each manufacturer. Executing large-scaleLLM models on a single accelerator is challenging; thus, interconnect technology is crucial for scaling by connecting multiple accelerators and expanding these connected accelerator groups.
Software Compatibility: MostLLM accelerators use proprietary software stacks. Providing a seamless development environment is essential, as many users rely on frameworks commonly used withGPUs. Furthermore, while support forLLM accelerators in existing frameworks is important, the most critical aspect is compiler technology, which allows developed models to achieve optimal performance onLLM accelerator hardware.
Conclusion
This article analyzes the hardware and software characteristics of commercialLLM accelerators and discusses the challenges faced by commercialLLM accelerators. By comparing the specifications and performance of major accelerators, we identify current technological trends and issues such as memory capacity, power consumption, scalability, and software compatibility. Future research needs innovative hardware designs and software optimization techniques to address these challenges, focusing on improving energy efficiency and scalability while ensuring software compatibility.
Original link:
https://arxiv.org/html/2503.09650v1
|
High-End WeChat Group Introduction |
|
|
Venture Capital Group |
AI, IOT, chip founders, investors, analysts, brokers |
|
Flash Memory Group |
Covering over 5000 global Chinese flash and storage chip elites |
|
Cloud Computing Group |
Public and private cloud discussions on all-flash, software-defined storage SDS, hyper-convergence, etc. |
|
AI Chip Group |
Discussions on AI chips and heterogeneous computing with GPUs, FPGAs, CPUs |
|
5G Group |
IoT, 5G chip discussions |
|
Third Generation Semiconductor Group |
Discussions on compound semiconductors such as GaN, SiC |
|
Storage Chip Group |
Discussions on various storage media and controllers such as DRAM, NAND, 3D XPoint |
|
Automotive Electronics Group |
Discussions on MCU, power supplies, sensors, etc. |
|
Optoelectronic Devices Group |
Discussions on optoelectronic devices such as optical communication, lasers, ToF, AR, VCSEL |
|
Channel Group |
Storage and chip product quotes, market trends, channels, supply chains |

< Long press to recognize the QR code to add friends >
Join the above group chats
 Long press and follow
Long press and follow
to take you into the new era of information revolution of storage, intelligence, and interconnectivity
of all things
 WeChat ID: SSDFans
WeChat ID: SSDFans