Jin Lei from AofeisiQuantum Bit | WeChat Official Account QbitAI
Now, training a trillion-parameter large model can completely say goodbye to NVIDIA.
The one achieving this is Huawei!

Technical report: arxiv.org/abs/2505.04519
It is important to note that before this, training a trillion-parameter large model faced many “roadblocks”.
For example, challenges such as load balancing difficulties, high communication overhead, and low training efficiency.
The Huawei Pangu team (including the Noah’s Ark Lab, Huawei Cloud, etc.) has successfully overcome all these challenges based on the Ascend domestic computing platform—
Over 6000 Ascend NPU clusters completed the long-term stable training of a 718 billion (718B) parameter MoE model and achieved significant performance improvements through multiple breakthrough system optimization techniques.
These innovations greatly enhanced training efficiency and supported the development of industry-leading models!
It must be said that the value of the term “domestic” in large model hardware is continuously rising.
Purely Domestic NPU Smoothly Runs Near-Trillion Parameter Large Models
Before dissecting Huawei’s series of “black technologies”, we need to understand the difficulties behind training ultra-large parameter MoE models more deeply.
Overall, there are “four major challenges” guarding this path.
The first is the architecture parameter optimization problem, which requires exploring the optimal configuration among numerous parameter combinations and designing a large-scale MoE architecture compatible with the Ascend NPU to achieve efficient utilization of computing resources.
The second is the dynamic load balancing challenge, where the routing mechanism needs to intelligently allocate tasks to avoid uneven distribution of expert resources; this imbalance can not only reduce training efficiency due to the “barrel effect” but may also lead to abnormal model convergence, affecting final performance.
There is also the distributed communication bottleneck, where at nearly trillion-parameter scale, the flow of tokens among different computing nodes generates huge communication overhead, making the “communication wall” a key factor limiting training efficiency.
Finally, there is the hardware adaptation complexity, which requires deep collaboration between the MoE algorithm and dedicated AI accelerators like the Ascend NPU, necessitating full-stack optimization across algorithm design, software frameworks, and hardware characteristics to fully unleash the computing potential of the hardware.
In response to these issues, Huawei’s technical report details how they tackled each challenge from aspects such as model architecture, MoE training analysis, and system optimization.
First is the MoE structure selection and Ascend affinity structure optimization.
The team conducted preliminary experiments to determine a paradigm of fine-grained experts plus shared experts. Then, when selecting the model, they considered multiple factors.
In terms of computation and memory affinity, by increasing the hidden size in the model while reducing the number of activation parameters, they not only enhanced the model’s computational capacity but also reduced memory usage, improving the utilization of computing power during model training and throughput during inference.
In terms of multi-dimensional parallel affinity, they adopted an exponential number of experts set to 2, achieving TP8×EP4 super-hybrid parallelism.
Using TP-extend-EP technology, they avoided efficiency drops in operators like MatMul caused by fine-grained expert splitting, while employing grouped AllToAll communication technology to reduce the overhead generated by EP communication.
In terms of DaVinci architecture affinity, tensors were aligned by 256 to perfectly match the 16×16 matrix computing units, fully unleashing the computing power of the Ascend NPU.
In terms of pipeline orchestration affinity, they employed PP (pipeline parallelism), VPP (variable pipeline parallelism), and empty layers to achieve load balancing between PP and VPP, reducing idle computing resources (bubbles).
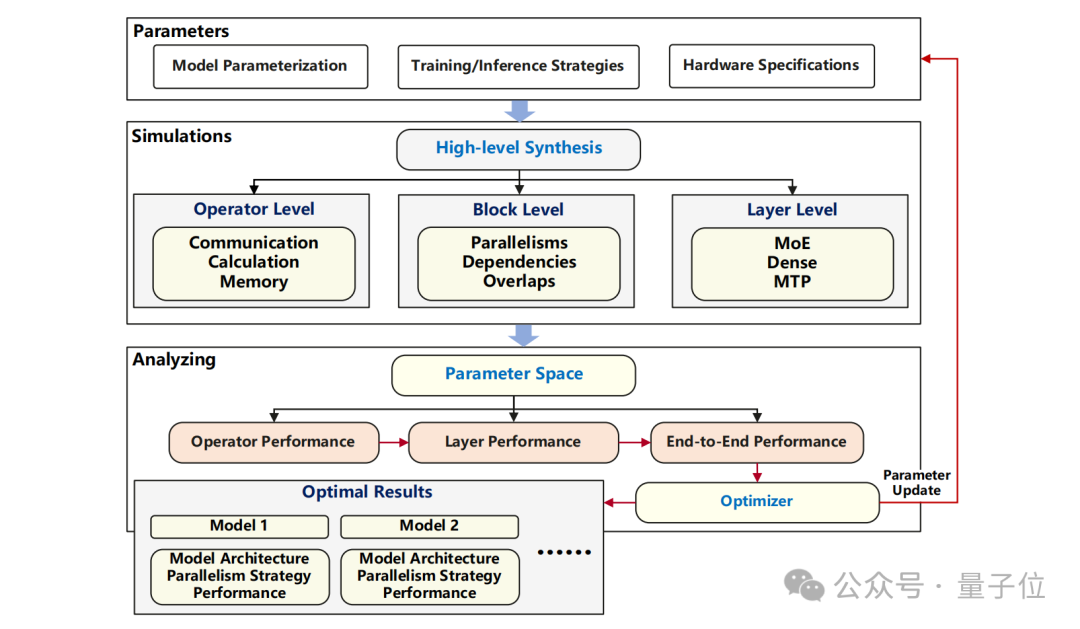
In terms of model structure simulation, the team significantly adjusted the selection range of model parameters based on hardware adaptation characteristics, narrowing the originally vast parameter search space to around 10,000.
To accurately determine the performance limits of different models, the team developed a specialized modeling simulation tool. This tool is impressive; it breaks down the model structure, runtime strategies, and hardware systems into individual parameters.
By simulating the calculations, data transfers, and read operations of operators, blocks, and layers, they can compute the overall performance of the model from start to finish. After comparing with actual test data, they found that the accuracy of this simulation tool can reach over 85%.
The team used this modeling simulation tool to test all parameter combinations that meet hardware adaptation requirements, carefully evaluating their data processing speeds during training and inference, ultimately finding relatively better-performing model structures, as shown in the figure below.

Next, let’s look at the MoE training analysis.
When training MoE models, compared to ordinary dense models, a particularly troublesome issue is load imbalance.
For example, it’s like a group of people working, where some are extremely busy while others have nothing to do; this inefficiency is inevitable.
To address this issue, the research community has proposed various auxiliary loss functions from an algorithmic perspective, focusing on different aspects of balance.
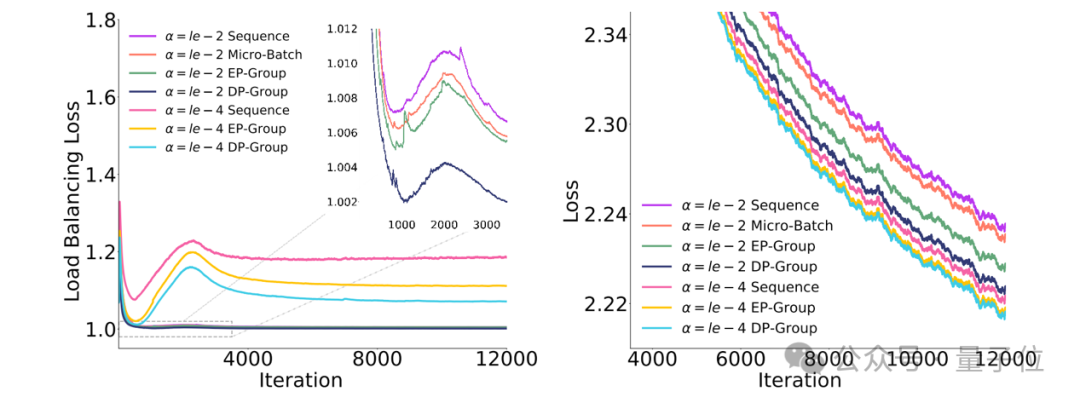
For instance, early on, there were auxiliary loss functions specifically targeting sequence-level balance, as well as the DP-Group (global batch size) balance auxiliary loss proposed by Tongyi Qianwen.
These auxiliary loss functions act like rules for the routing module in the MoE model (responsible for task allocation), constraining it to distribute tasks more evenly. The specific constraints are summarized in the table below.

△Balance BSZ indicates the number of tokens used to calculate expert selection frequency
The team also developed a new EP group load balancing loss algorithm.
Compared to traditional micro-batch auxiliary losses, it does not overly demand absolute balance in local task distribution, avoiding “overcorrection”; compared to DP group balance losses, it consumes fewer resources during data transmission, saving significant communication costs.
Moreover, in terms of the degree of constraint on expert task volume, it is a more balanced solution between the two.
To validate the effectiveness of this new algorithm, the team conducted ablation experiments on a pilot MoE model with a total parameter count of 20 billion (20B), as detailed below:
To address the “barrel effect” of uneven expert loads, MoE can adopt a drop-and-pad approach to enhance training throughput.
The team first compared the performance of drop-and-pad and dropless methods under different total expert counts on a 20B pilot MoE:
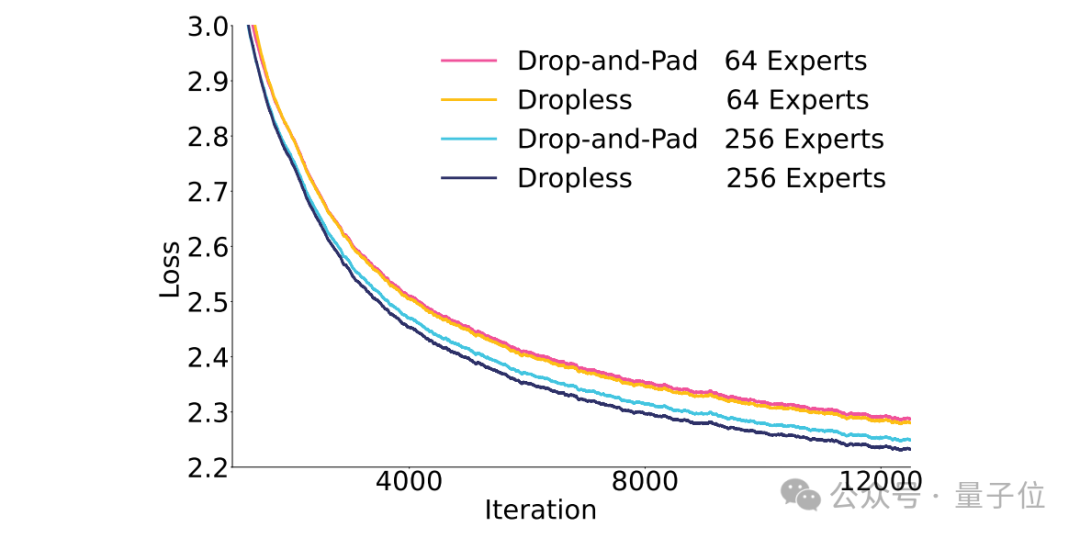
The results showed that dropless consistently outperformed the drop-and-pad scheme.
Moreover, this performance gap further widened as the number of experts increased and model parameters grew.
Therefore, the dropless approach was adopted during the training of the Pangu Ultra MoE, with a focus on optimizing training efficiency under this strategy.
Specifically, the team conducted comprehensive optimizations on the Pangu Ultra MoE model from four key directions, including improving parallel computing strategies, optimizing data transmission efficiency, enhancing memory usage, and achieving more even task distribution.
On a large computing cluster composed of over 6000 Ascend NPUs, the model’s Model FLOPs Utilization (MFU) reached 30.0%, a remarkable increase of 58.7% compared to before optimization.
The team used a comprehensive modeling simulation system to repeatedly experiment to find the best parallel computing scheme.
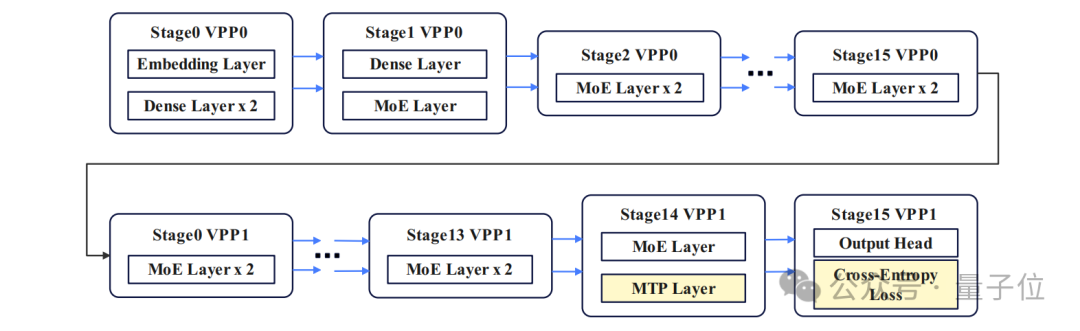
The final scheme determined was: adopting 16-way pipeline parallelism, 8-way tensor parallelism, 4-way expert parallelism, 2-way virtual pipeline parallelism, and 48-way data parallelism.
In terms of expert parallelism, the team employed the TP-extend-EP strategy.
In simple terms, this means allowing the TP group to define the number of experts, which helps avoid the efficiency drop in GMM operators when processing small-scale expert data due to expert parameter splitting.
In the entire system, the total number of expert groups is 32 (calculated from TP and EP combinations), divided into 256 experts.
The virtual pipeline parallel strategy performed particularly well; previously, idle computing resources (bubble rate) during training accounted for 18.98%, but with the new strategy, it dropped to 10.49%.
At the same time, by reasonably distributing tasks between the MTP layer and loss function layer, the overflow caused by uneven task distribution was controlled to within 5%, significantly reducing the negative impact of uneven task allocation.
To address communication bottlenecks in parallel scaling, the team designed two main technologies.
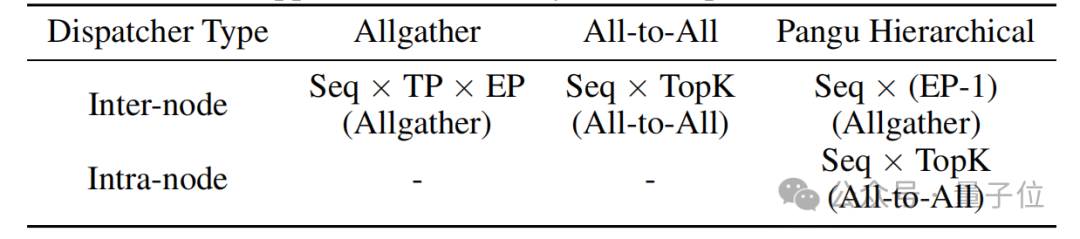
The first is Hierarchical EP Communication.
Compared to intra-machine communication, inter-machine communication has lower bandwidth. The team adopted hierarchical EP communication to reduce inter-machine communication volume.
Specifically, they used cross-machine Allgather communication to synchronize all tokens to within the machine, then sorted the tokens and redistributed them using intra-machine AlltoAll communication.
Both intra-machine and inter-machine communications can be masked by forward-backward communication techniques, as shown in the communication volume comparison below, demonstrating the effectiveness of hierarchical EP communication in reducing inter-machine communication volume.
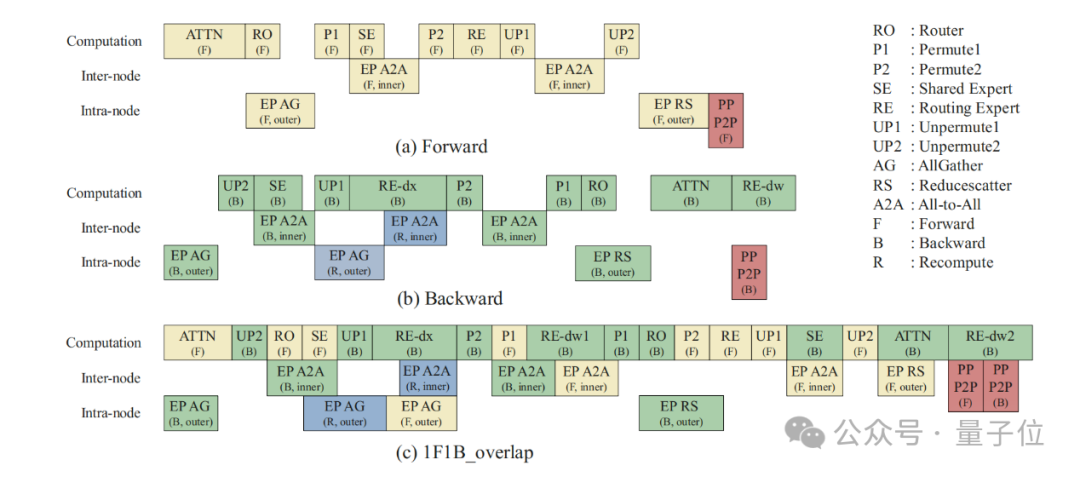
The second is Adaptive Pipe Overlap Mechanism.
Even with the hierarchical EP communication strategy, the time cost of EP communication remains high. Most EP communications and computations in the forward-backward process are interdependent, and natural masking strategies expose most EP communications.
If self-masking strategies like operator fusion are used, they inevitably reduce computational efficiency.
Therefore, the team adopted an adaptive forward-backward masking strategy based on VPP scheduling, achieving forward computation masking backward communication and backward computation masking forward communication as shown in the process diagram below.
The core design includes: utilizing the independent characteristics of inter-machine and intra-machine communication link bandwidth to achieve mutual masking, and using effective operator arrangement to alleviate host-bound issues, separating expert backward dw calculations from dx calculations for finer-grained masking.
When optimizing memory usage, the team adopted a new computation method.
Instead of using traditional full-weight computation, they re-computed fine-grained modules like MLA, Permute, and activation functions to avoid additional computational overhead.
At the same time, they employed Tensor Swapping technology to transfer activation values that are not cost-effective to recompute to the CPU, retrieving them when needed for backward computation, allowing for more efficient use of NPU memory.
The team is also researching new memory-saving methods, planning to combine various optimization strategies to find the most suitable combination based on different device configurations, improving memory utilization without compromising model performance.
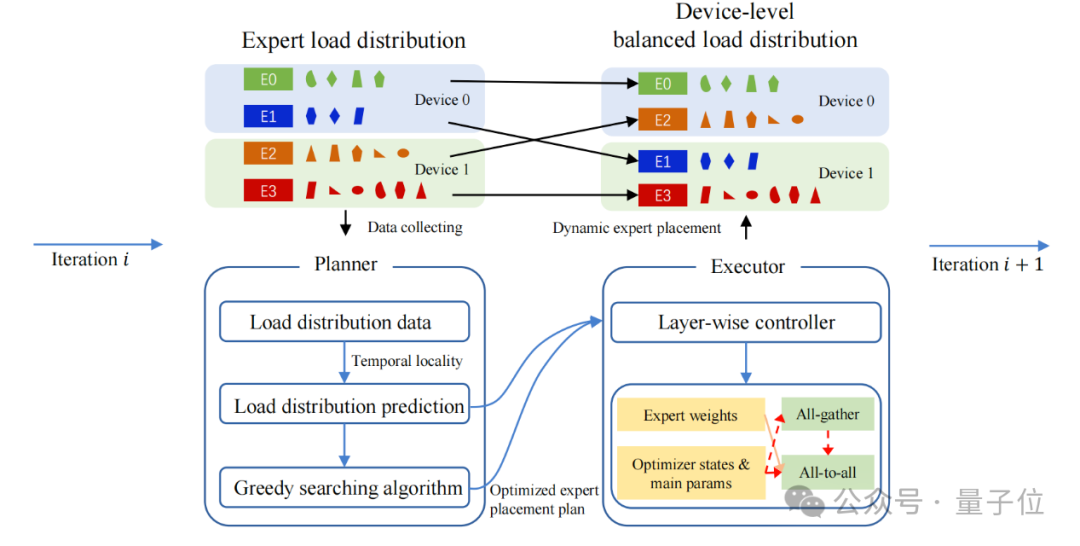
Ensuring that the task volume (number of tokens) handled by experts on each device is as uniform as possible can significantly enhance training efficiency.
To this end, the team designed a dynamic device-level load balancing mechanism.
First, the planner acts like a “little housekeeper”, observing the workload of experts over a period, predicting future task volumes, and using a greedy algorithm to plan how to redistribute experts for more balanced tasks across devices.
Then, the executor periodically acts to transfer expert parameters and optimizer states of different Transformer layers between devices. Through this dynamic adjustment, the model’s MFU increased by 10%.
In addition to the above, the team also developed some technologies specifically adapted for Ascend devices, including host-side optimization, computation offloading and data sharing, and fusion operators.
- Operator dispatch optimization: To address host-side performance bottlenecks, the team reduced operators that require frequent synchronization, avoiding unnecessary waiting. At the same time, they used fine-grained CPU core binding technology to improve the collaboration between CPU and NPU, ensuring smoother task dispatch.
- Computation offloading and data sharing: When encountering data computations that are inefficient for NPU or slow data transfers within the TP area, the authors separated these unsuitable computations from the main computation flow, allowing the CPU to handle them during data loading. Coupled with data sharing technology, the speed of computation and data transfer within the same node significantly improved.
- Fusion operators: In addition to the existing FlashAttention and RMSNorm fusion operators in the Pangu dense model, the team also added GMMAdd, Permute, and Unpermute fusion operators in the MoE model. The GMMAdd fusion operator processes the backward computation of GroupedMatMul and gradient accumulation together, utilizing parallel and pipeline techniques to reduce scheduling time. The Permute and Unpermute fusion operators integrate multiple operations for faster memory read and write.

Experimental Results
During the construction of the training dataset, the team implemented strict data quality control, emphasizing the diversity, complexity, and comprehensiveness of the corpus.
Special markers were introduced for long-chain reasoning samples to structurally separate inference trajectories from final answers.
The post-training phase adopted instruction fine-tuning strategies, with data covering a wide range of fields, including general Q&A, text generation, semantic classification, code programming, mathematical logic reasoning, and tool usage.
Particularly, the ratio of reasoning to non-reasoning samples was set at 3:1 to further enhance reasoning performance.
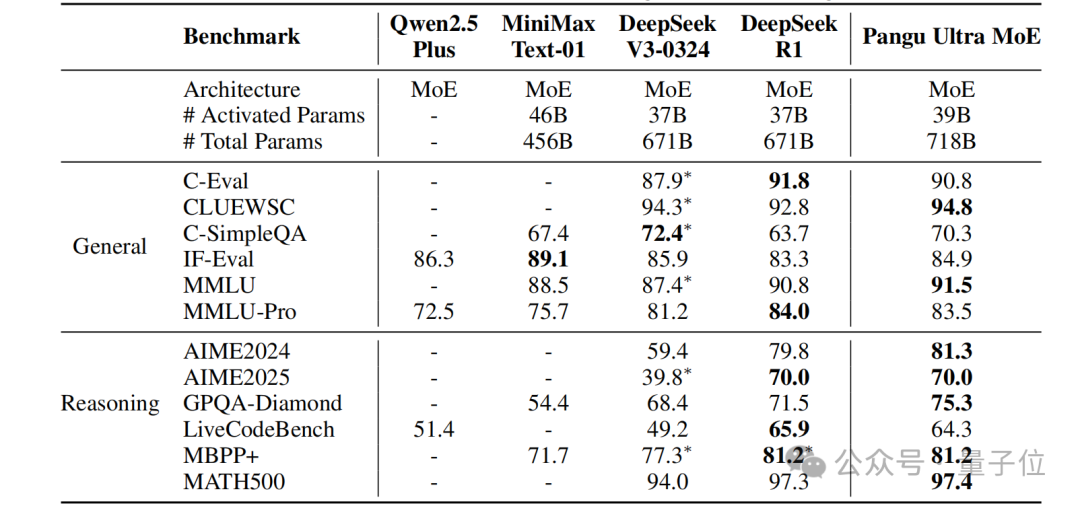
Experiments showed that the Pangu Ultra MoE dialogue version demonstrated exceptional competitiveness across multiple domains, performing comparably to DeepSeek-R1 on most benchmarks. For instance, in general understanding tasks (such as CLUEWSC 94.8 points, MMLU 91.5 points), it exhibited outstanding comprehension, and in high-difficulty tests like mathematical reasoning and code generation (such as AIME2024 81.3 points, MBPP+ 81.2 points), it performed excellently, showcasing remarkable coding and mathematical problem-solving abilities.
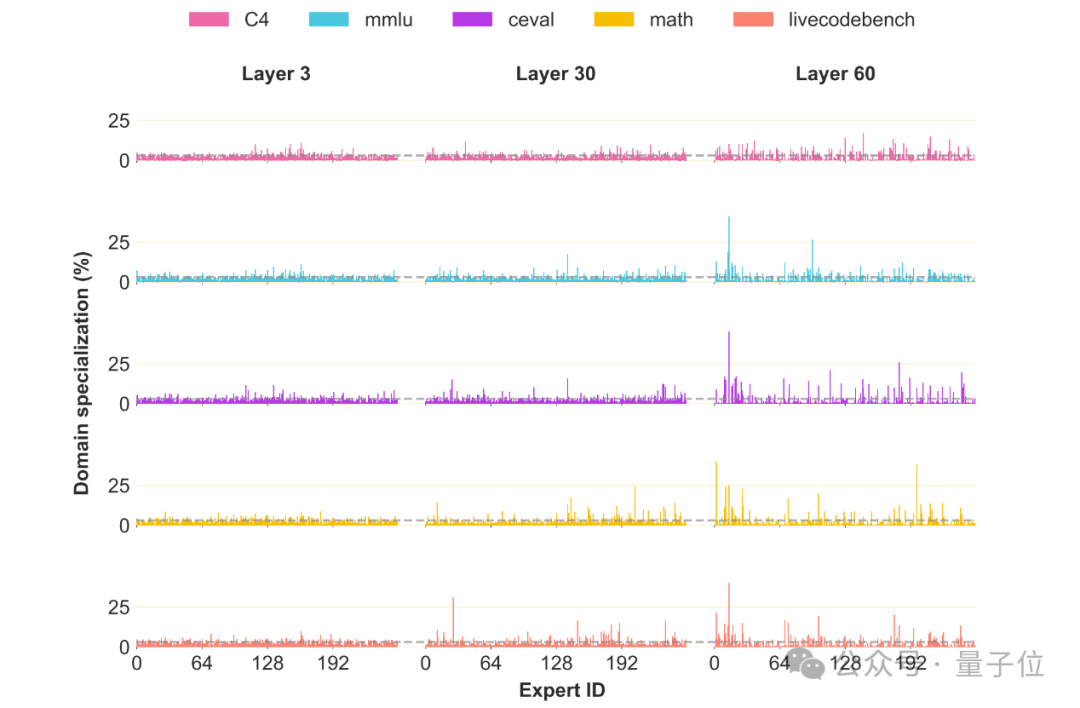
The team also conducted an expert specialization analysis of the Pangu Ultra MoE.
In different tasks, tokens from the same network layer are preferentially routed to different experts, showing significant task variability in expert specialization.
This confirms that the Pangu Ultra MoE has formed significant expert differentiation, a characteristic that not only enhances the model’s expressive capability but also provides crucial support for its outstanding performance.
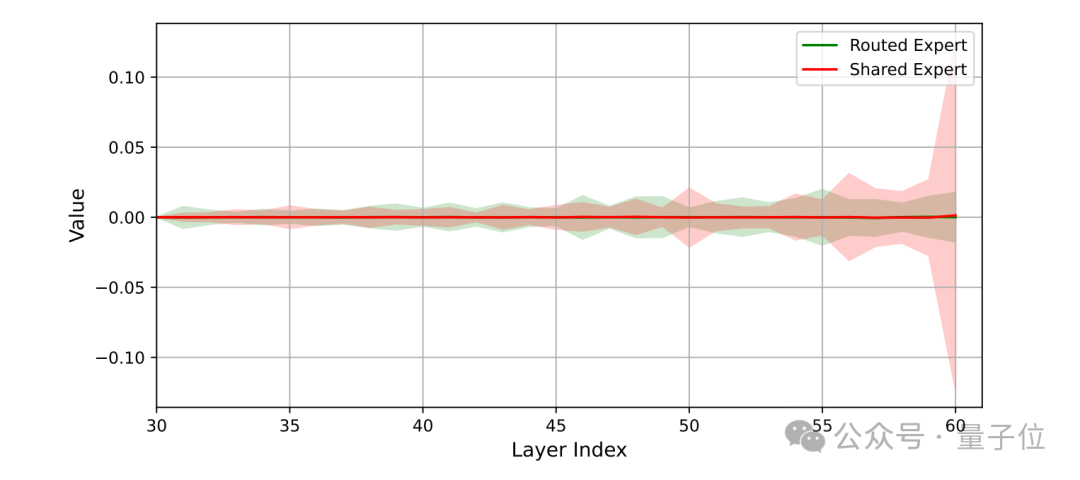
The output of the MoE layer in the Pangu Ultra MoE consists of a weighted sum contributed by both shared experts and routing experts.
Therefore, maintaining a balance between their outputs is crucial.
The diagram below shows that routing experts maintain a contribution strength comparable to shared experts across all network layers, and this balanced collaboration effectively enhances the model’s overall representational capability.
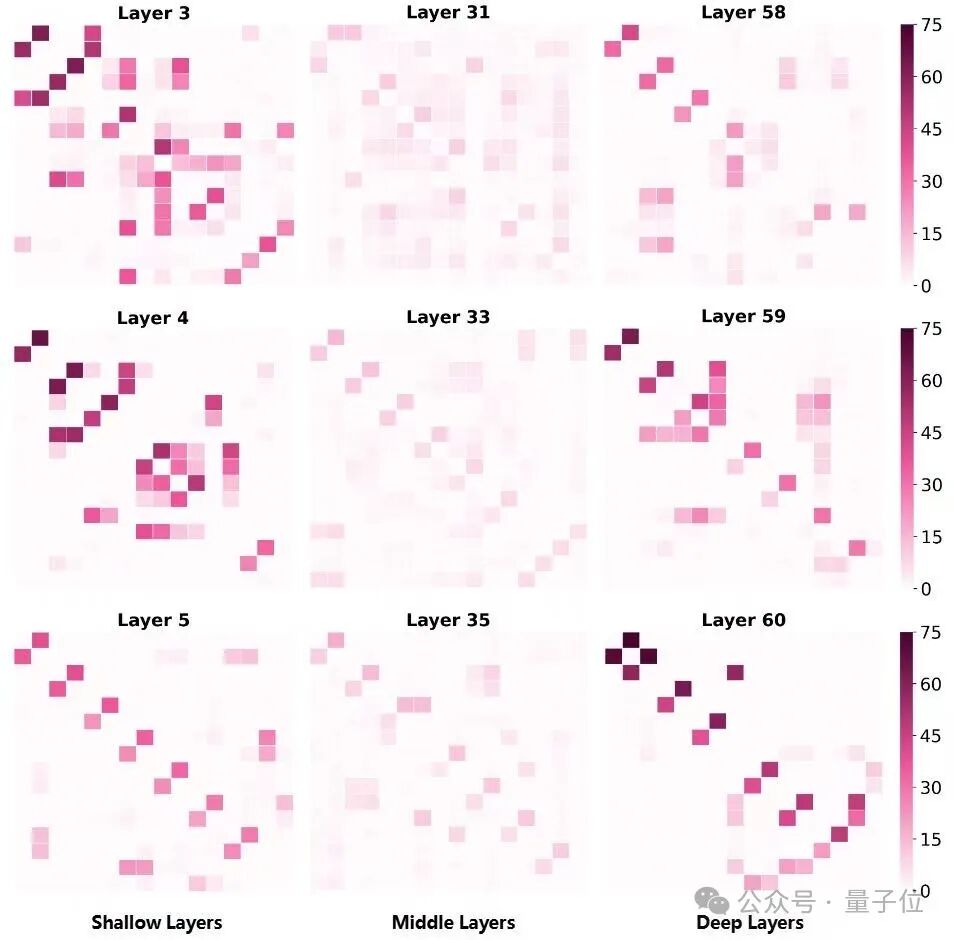
The team also analyzed the co-activation phenomenon of experts, where higher activation scores indicate stronger correlations between two experts.
In the diagram below, except for a few exceptions, there is no significant co-activation phenomenon among experts in these three layers, reflecting the low redundancy of experts in the Pangu Ultra MoE.
This is the essence behind Huawei’s domestic NPU running a near-trillion parameter large model.
The breakthroughs in Huawei’s Pangu Ultra MoE technology not only mark the domestic computing platform’s entry into the world-leading ranks in AI large model training but also highlight the strong capabilities of China’s technological self-innovation.
It proves that Chinese enterprises have the strength to transition from following to competing, and even leading in the global AI race.
In the future, with continuous technological iterations and the expansion of application scenarios, the Pangu Ultra MoE will inject strong momentum into the intelligent transformation of various industries, helping China occupy a high ground in the new round of technological revolution and contribute more “Chinese wisdom” to human technological progress.
Technical report download link:arxiv.org/abs/2505.04519
One-click three connections「Like」「Share」「Heart」
Feel free to leave your thoughts in the comments!
— The End —
🌟 Light up the star mark 🌟
Daily updates on cutting-edge technological advancements