
Table of Contents
1. Introduction
2. Risks and Necessity of Timeout Control
3. Timeout Parameter Examples
4. Context-Based Timeout Implementation
1. Context Timeout Propagation
2. Tracked Timeout Control
5. Retry Strategies
1. Exponential Backoff and Jitter
2. Error Type Judgment
6. Idempotency Guarantee
1. Request ID + Redis Implementation
2. Business Layer Idempotency Strategies
7. Performance Optimization
1. Connection Pool Configuration
2. sync.Pool Memory Reuse
8. Conclusion
1
Introduction
In distributed systems, the reliability of network requests directly determines service quality. Imagine if your payment system experiences inconsistent order statuses due to a third-party API timeout, or if transient network jitter causes user operations to fail. These issues often stem from the HTTP client lacking comprehensive timeout control and retry strategies. While the Golang standard library provides a basic HTTP client implementation, in high-concurrency and high-availability scenarios, we need more refined strategies to cope with complex network environments.
2
Risks and Necessity of Timeout Control
The 2024 Cloudflare network report shows that 78% of service interruption events are directly related to unreasonable timeout configurations. When an HTTP request is blocked for a long time due to a non-responsive target service, it not only occupies valuable system resources but may also trigger cascading failures—large numbers of blocked requests can exhaust connection pool resources, preventing new requests from being established, ultimately leading to service avalanches. Timeout control is essentially a resource protection mechanism, which sets reasonable time boundaries to ensure that the exception of a single request does not spread to the entire system.
Two typical risks of improper timeout configuration:
-
DoS Attack Amplification Effect: Clients lacking connection timeout limits will maintain a large number of half-open connections when encountering malicious slow response attacks, quickly exhausting server file descriptors.
-
Resource Utilization Inversion: When ReadTimeout is set too long (e.g., the default of 0 means no limit), slow requests will occupy connection pool resources for an extended period. Performance data from Netflix shows that optimizing the timeout from 30 seconds to 5 seconds increased connection pool utilization by 400%, resulting in a 2.3 times increase in service throughput.
3
Timeout Parameter Examples
Never rely on the default http.DefaultClient, which has a Timeout of 0 (no timeout). All timeout parameters must be explicitly configured in production environments to form a defensive programming habit.
The following code demonstrates how to configure connection timeout and keep-alive strategies using net.Dialer:
transport := &http.Transport{ DialContext: (&net.Dialer{ Timeout: 3 * time.Second, // TCP connection establishment timeout KeepAlive: 30 * time.Second, // Connection keep-alive time DualStack: true, // Support IPv4/IPv6 dual stack }).DialContext, ResponseHeaderTimeout: 5 * time.Second, // Response header timeout MaxIdleConnsPerHost: 100, // Maximum idle connections per host}client := &http.Client{ Transport: transport, Timeout: 10 * time.Second, // Overall request timeout}4
Context-Based Timeout Implementation
context.Context provides a more flexible control mechanism for request timeouts, especially in distributed tracing and request cancellation scenarios. Unlike the timeout parameters of http.Client, context timeouts can achieve request-level timeout propagation, such as passing the remaining timeout in a microservice call chain.
Context Timeout Propagation
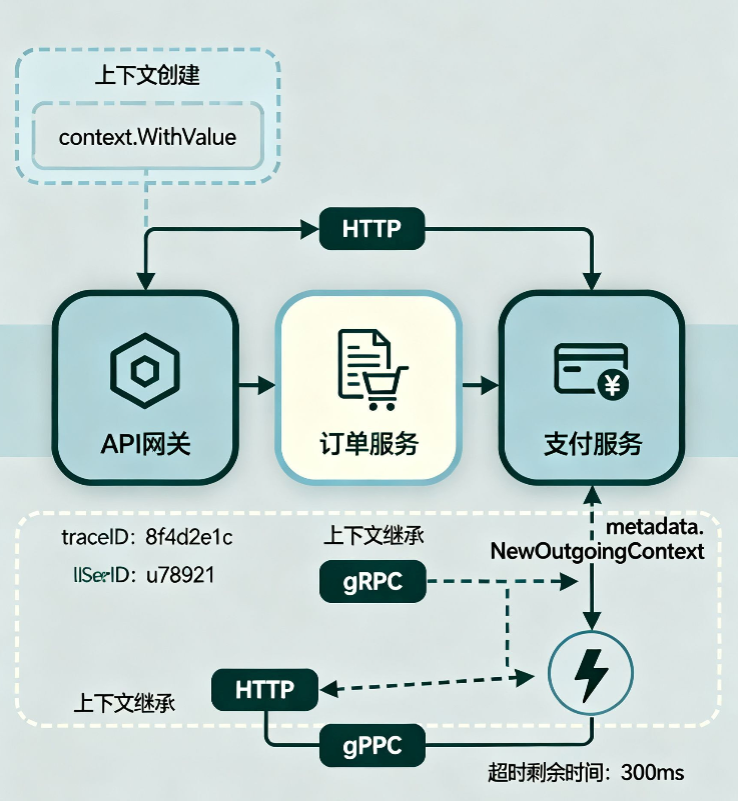
As shown in the figure, context creates a timeout context through WithTimeout or WithDeadline, which is propagated step by step during the request process. When the parent context is canceled, the child context will immediately terminate the request, preventing resource leaks.
Tracked Timeout Control
func requestWithTracing(ctx context.Context) (*http.Response, error) { // Derive a child context with a 5-second timeout from the parent context ctx, cancel := context.WithTimeout(ctx, 5*time.Second) defer cancel() // Ensure the context is canceled regardless of success or failure req, err := http.NewRequestWithContext(ctx, "GET", "https://api.example.com/data", nil) if err != nil { return nil, fmt.Errorf("Failed to create request: %v", err) } // Add distributed tracing information req.Header.Set("X-Request-ID", ctx.Value("request-id").(string)) client := &http.Client{ Transport: &http.Transport{ DialContext: (&net.Dialer{ Timeout: 2 * time.Second, }).DialContext, }, // Note: Do not set Timeout here, it is fully controlled by context } resp, err := client.Do(req) if err != nil { // Distinguish between context cancellation and other errors if ctx.Err() == context.DeadlineExceeded { return nil, fmt.Errorf("Request timed out: %w", ctx.Err()) } return nil, fmt.Errorf("Request failed: %v", err) } return resp, nil}Key Difference: context.WithTimeout and http.Client.Timeout are additive rather than substitutive. When both are set, the smaller value is taken.
5
Retry Strategies
Network request failures are inevitable, but blind retries may exacerbate service load and even trigger thundering herd effect. A robust retry mechanism needs to combine error type judgment, backoff algorithms, and idempotency guarantees to strike a balance between reliability and service protection.
Exponential Backoff and Jitter
Exponential backoff gradually increases the retry interval to avoid secondary impacts on the faulty service. In Golang implementations, random jitter should be added to prevent the spike effect caused by multiple clients retrying simultaneously.
The following is a simple retry implementation example:
type RetryPolicy struct { MaxRetries int InitialBackoff time.Duration MaxBackoff time.Duration JitterFactor float64 // Jitter factor, recommended 0.1-0.5} // Exponential backoff with jitterfunc (rp *RetryPolicy) Backoff(attempt int) time.Duration { if attempt <= 0 { return rp.InitialBackoff } // Exponential growth: InitialBackoff * 2^(attempt-1) backoff := rp.InitialBackoff * (1 << (attempt - 1)) if backoff > rp.MaxBackoff { backoff = rp.MaxBackoff } // Add jitter: [backoff*(1-jitter), backoff*(1+jitter)] jitter := time.Duration(rand.Float64() * float64(backoff) * rp.JitterFactor) return backoff - jitter + 2*jitter // Uniformly distributed within the jitter range} // General retry executorfunc Retry(ctx context.Context, policy RetryPolicy, fn func() error) error { var err error for attempt := 0; attempt <= policy.MaxRetries; attempt++ { if attempt > 0 { // Check if the context has been canceled select { case <-ctx.Done(): return fmt.Errorf("Retry canceled: %w", ctx.Err()) default: } backoff := policy.Backoff(attempt) timer := time.NewTimer(backoff) select { case <-timer.C: case <-ctx.Done(): timer.Stop() return fmt.Errorf("Retry canceled: %w", ctx.Err()) } } err = fn() if err == nil { return nil } // Determine if a retry should be attempted if !shouldRetry(err) { return err } } return fmt.Errorf("Reached maximum retry count %d: %w", policy.MaxRetries, err)}Error Type Judgment
Blindly retrying all errors is not only ineffective but may also lead to data inconsistency. The shouldRetry function needs to accurately distinguish between retryable error types:
func shouldRetry(err error) bool { // Network-level errors var netErr net.Error if errors.As(err, &netErr) { // Timeout errors and temporary network errors are retryable return netErr.Timeout() || netErr.Temporary() } // HTTP status code judgment var respErr *url.Error if errors.As(err, &respErr) { if resp, ok := respErr.Response.(*http.Response); ok { switch resp.StatusCode { case 429, 500, 502, 503, 504: return true // Rate limiting and server errors are retryable case 408: return true // Request timeout is retryable } } } // Application layer custom errors if errors.Is(err, ErrRateLimited) || errors.Is(err, ErrServiceUnavailable) { return true } return false}Industry Best Practice: Netflix’s retry strategy recommends retrying up to 3 times for 5xx errors, using the interval specified by the Retry-After header for 429 errors, and applying exponential backoff (initial 100ms, maximum 5 seconds) for network errors.
6
Idempotency Guarantee
The premise of a retry mechanism is that requests must be idempotent, otherwise retries may lead to data inconsistency (e.g., duplicate charges). The core of achieving idempotency is to ensure that multiple identical requests produce the same side effects, with common solutions including request ID mechanisms and optimistic locking.
Request ID + Redis Implementation
Based on a UUID request ID and a Redis idempotency check mechanism, duplicate requests can be ensured to be processed only once:
type IdempotentClient struct { redisClient *redis.Client prefix string // Redis key prefix ttl time.Duration // Idempotent key expiration time} // Generate unique request IDfunc (ic *IdempotentClient) NewRequestID() string { return uuid.New().String()} // Execute idempotent requestfunc (ic *IdempotentClient) Do(req *http.Request, requestID string) (*http.Response, error) { // Check if the request has been processed key := fmt.Sprintf("%s:%s", ic.prefix, requestID) exists, err := ic.redisClient.Exists(req.Context(), key).Result() if err != nil { return nil, fmt.Errorf("Idempotency check failed: %v", err) } if exists == 1 { // Return cached response or mark as duplicate request return nil, fmt.Errorf("Request already processed: %s", requestID) } // Use SET NX to ensure only one request can pass the check set, err := ic.redisClient.SetNX( req.Context(), key, "processing", ic.ttl, ).Result() if err != nil { return nil, fmt.Errorf("Idempotent lock failed: %v", err) } if !set { return nil, fmt.Errorf("Concurrent request conflict: %s", requestID) } // Execute request client := &http.Client{/* Configuration */} resp, err := client.Do(req) if err != nil { // Delete idempotent marker on request failure ic.redisClient.Del(req.Context(), key) return nil, err } // On successful request, update idempotent marker status ic.redisClient.Set(req.Context(), key, "completed", ic.ttl) return resp, nil}Key Design: The TTL of the idempotent key should be greater than the maximum retry period + business processing time. For example, if the maximum retry interval is 30 seconds and processing takes 5 seconds, it is recommended to set the TTL to 60 seconds to avoid duplicate processing caused by key expiration during retries.
Business Layer Idempotency Strategies
For write operations, idempotent logic must also be implemented at the business layer:
-
Update Operations: Use optimistic locking (e.g., UPDATE … WHERE version = ?)
-
Create Operations: Use unique indexes (e.g., order number, external transaction number)
-
Delete Operations: Use “soft delete” instead of physical deletion
7
Performance Optimization
In high-concurrency scenarios, the performance bottleneck of the HTTP client usually lies not in network latency but in connection management and memory allocation. By properly configuring the connection pool and reusing resources, throughput can be significantly improved.
Connection Pool Configuration
Optimizing the connection pool parameters of http.Transport has a huge impact on performance. The following is a configuration validated in production:
func NewOptimizedTransport() *http.Transport { return &http.Transport{ // Connection pool configuration MaxIdleConns: 1000, // Global maximum idle connections MaxIdleConnsPerHost: 100, // Maximum idle connections per host IdleConnTimeout: 90 * time.Second, // Idle connection timeout // TCP configuration DialContext: (&net.Dialer{ Timeout: 2 * time.Second, KeepAlive: 30 * time.Second, }).DialContext, // TLS configuration TLSHandshakeTimeout: 5 * time.Second, TLSClientConfig: &tls.Config{ InsecureSkipVerify: false, MinVersion: tls.VersionTLS12, }, // Other optimizations ExpectContinueTimeout: 1 * time.Second, DisableCompression: false, // Enable compression }}Uber’s performance testing shows that increasing MaxIdleConnsPerHost from the default of 2 to 100 reduced the latency of concurrent requests to the same API from 85ms to 12ms, increasing throughput by 6 times.
sync.Pool Memory Reuse
Frequent creation of http.Request and http.Response can lead to significant memory allocation and GC pressure. Using sync.Pool to reuse these objects can reduce memory allocation by 90%:
var requestPool = sync.Pool{ New: func() interface{} { return &http.Request{ Header: make(http.Header), } },} // Acquire request object from the poolfunc AcquireRequest() *http.Request { req := requestPool.Get().(*http.Request) // Reset necessary fields req.Method = "" req.URL = nil req.Body = nil req.ContentLength = 0 req.Header.Reset() return req} // Release request object to the poolfunc ReleaseRequest(req *http.Request) { requestPool.Put(req)}8
Conclusion
HTTP requests may seem simple, but they connect the “veins” of the entire system. Ignoring timeouts and retries is like leaving a gap in the veins—there’s no problem under normal conditions, but when pressure comes, it leads to significant bleeding. Building highly reliable network requests requires balancing timeout control, retry strategies, idempotency guarantees, and performance optimization.
Remember, in distributed systems, timeouts and retries are not optional features, but essential for survival.
Additional Resources:
-
Golang Official HTTP Client Documentation(https://pkg.go.dev/net/http)
-
Netflix Hystrix Timeout Design Pattern(https://github.com/Netflix/Hystrix/wiki/Configuration)
Previous Reviews
1. The Spark of Collision between RN and Hawk: C++ Exception Handling|DeWu Technology
2. DeWu TiDB Upgrade Practice
3. DeWu Management Category Configuration Online: From Business Pain Points to Technical Implementation
4. How Large Models Innovate Search Relevance? Intelligent Upgrades Make Search More “Understandable”|DeWu Technology
5. RAG—Chunking Strategy Practice|DeWu Technology
Written by / Wu
Follow DeWu Technology for technical insights every Monday and Wednesday
If you find this article helpful, feel free to comment, share, and like it~
Reproduction without permission from DeWu Technology is strictly prohibited, and legal responsibility will be pursued.
“
Scan to add the assistant on WeChat
If you have any questions or want to know more technical information, please add the assistant on WeChat:
