Skip to content
The architecture of traditional Digital Signal Processors (DSP) has become inadequate for specific signal processing computational applications. However, the combination of Very Long Instruction Word (VLIW) and Single Instruction/Multi Data (SIMD) architectures can provide the parallel throughput required for high computational performance, with data typically being 16, 24, and 32 bits wide. This is particularly suitable for algorithms used in applications such as speech/audio and communications. In earlier generations of DSP algorithm development, system and software developers would develop system algorithms in MathWorks MATLAB®, and then transfer the algorithms to DSP, converting MATLAB’s floating-point data type outputs to fixed-point type outputs during the transfer. DSP developers use fixed-point data to meet the demands for loop and accuracy calculations while minimizing hardware usage and power consumption.
Achieving Higher Throughput With Floating Point
Due to the need for time-to-market, new algorithms and computations leverage custom software algorithms and a more aggressive time-to-market window to differentiate products.Current systems may skip the conversion step from floating-point to fixed-point and only keep floating-point running on the DSP.Newer applications, such as automotive ADAS and RADAR/LiDAR, require high precision throughout all parts of the computational path.In front-end FFT calculations, larger point FFTs (e.g., 4K, 8K, and higher) cannot maintain bit precision in fixed-point (overflow).Therefore, achieving the highest performance requires the use of single-precision or half-precision floating-point data types.
In various automotive applications, especially in ADAS, powertrain, and motor control/management, predictive modeling for faster/smoother system responses is becoming increasingly common. Predictive modeling uses statistical models that can predict outcomes based on various inputs. The advantage of this implementation is that DSP processors can run highly complex models and respond to a broader range of sensor and environmental inputs, generating outputs more quickly. Machine learning algorithms are also helpful in matching the state of predictive models, enabling them to learn expected outcomes and further improve response times and output quality. Predictive modeling is best implemented using single-precision floating-point in linear algebra-based algorithms to determine the range and accuracy of computational data. Meanwhile, mathematical computations can be classified as linear algebra operations performed on DSP processors for extensive calculations.
Applications with high-performance processing—such as 5G wireless communication with data rates of 10 Gbps and automotive ADAS, RADAR, and LiDAR requiring over 200 Gbps of data throughput—need DSPs with very wide vector computation capabilities and high levels of parallel execution. These new DSP computing drivers change the architectural and instruction set architecture (ISA) requirements of traditional DSP cores. DSPs require extremely high levels of computational throughput while also maintaining high levels of single-precision and half-precision floating-point computation. Traditional DSP processors focus on fixed-point data type processing, while the added floating-point units are not optimal in terms of processing power and power consumption. Traditional DSP processors have limited instruction support for linear algebra; for matrix transpose operations, while providing SQRT and/or 1/SQRT support, a complete range of linear algebra algorithms must be software simulated for mathematical operations.
A New Generation DSP Architecture For A Data-Driven World
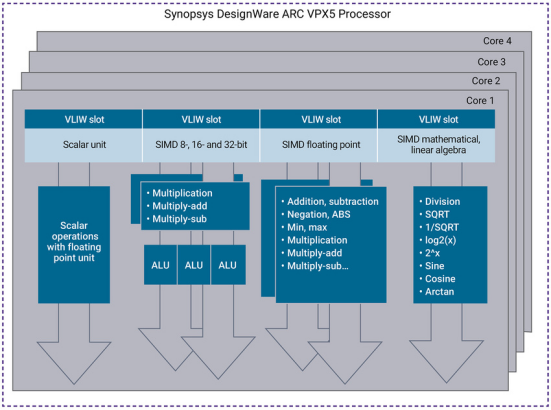
The next generation of DSP cores can meet the computational requirements for floating-point and linear algebra data throughput. The DSP is the DesignWare® ARC® VPX5 processor IP solution, which will be developed as part of its native architecture for floating-point and linear algebra vector computation, effectively achieving ultra-high levels of parallel processing through vector SIMD and VLIW architectures. The DesignWare ARC VPX5 processor IP has four parallel execution dimensions (Figure 1).
Figure 1: Four Dimensions of Parallel Execution on DesignWare ARC VPX5 Processor IP
Dimension 1: Multi-SIMD Computing Engines for Floating Point
The basic vector data length is 512 bits, allowing SIMD computations for 8-bit, 16-bit, and 32-bit data, or half-precision and single-precision floating-point data units. All SIMD engines use a vector length of 512 bits for computation; this establishes the upper limit of the computational capability of the ARC VPX5 processor.
For integer data lengths of 8 bits, 16 bits, and 32 bits, there are two 512-bit SIMD computing engines and three ALU processing units. This provides a very high level of computation for algorithms such as machine learning convolution operations (5×5, 3×3, and 1×1).
For half-precision and single-precision floating-point computations, there are three vector SIMD computing engines, all supporting a maximum vector length of 512 bits. The dual SIMD engines for “regular” floating-point vector operations provide ultra-high performance for floating-point vector operations, including DSP functions like FFT and matrix operations.
The third vector SIMD floating-point engine is dedicated to linear algebra mathematical functions. This dedicated engine allows for offloading and parallel computation of mathematical functions, which will be further explained in the fourth dimension section.
Dimension 2: Flexibility Achieved Through Multi-Tasking VLIW
In a four-issue VLIW scheme, flexible allocation is executed, allowing the processor to allocate the maximum possible number of parallel operations. The development of the VLIW scheme closely cooperates with the development of software compilers, so the compiler pre-allocates operators compiled from the original C code program. The combination of the compiler with the VLIW architecture allows operations to be executed in parallel across multiple SIMD engines.
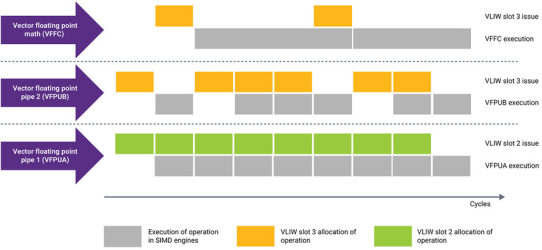
For example, Figure 2 shows how the compiler can combine the VLIW allocation scheme to achieve parallel execution across three floating-point SIMD engines using only two VLIW slots, achieving optimal VLIW slot allocation and smaller instruction code size. Since the two vector SIMD floating-point engines have zero-cycle insertion latency, vector data can be loaded into the SIMD engines in each cycle. The insertion latency for the linear algebra vector SIMD engine is four cycles, so after loading data, there is an additional wait of three cycles before new vector data can be loaded. The compiler can pre-allocate VLIW slots for this different insertion latency, thus providing effective parallel execution across all three vector SIMD floating-point engines.
Figure 2: Compiler Allocation for Parallel Execution of Three Vector FPUs
Dimension 3: Configurable for Single-Core, Dual-Core, and Quad-Core
The DesignWare ARC VPX5 processor IP operates in parallel with multiple vector SIMD computing engines and has VLIW allocation capabilities, allowing single-core to scale up to dual-core and quad-core configurations. This can double or triple the computational performance of the single-core VPX5 to meet higher computational demands. The DesignWare ARC MetaWare development tools fully support code compilation and execution across multi-core configurations. Additionally, since the product includes signaling capabilities, it supports multi-core task execution and synchronization.
For single-core, dual-core, and quad-core configurations, data movement is key to the VPX5 product. There is a 2D Direct Memory Access (DMA) engine that can be configured with up to four channels, providing up to 512 bits of transfer per cycle. DMA can move data in parallel between various multi-core data memories, local cluster memories, or between input/output on the external AXI bus. This high-performance DMA complements the high computational throughput of the VPX5 processor, enabling the vector SIMD engines to continuously access new vector data in the tightly coupled vector data memory on each core.
Dimension 4: Linear Algebra Computation
Many next-generation algorithms use mathematical equations and computations that rely on basic functions of linear algebra to achieve computational throughput. Such examples include object tracking and recognition, predictive modeling, and some filtering operations. Under this new driving trend, the VPX processor stands out in providing dedicated vector SIMD floating-point computing engines purely for linear algebra. This engine hardware accelerates linear functions such as division, SQRT, 1/SQRT, log2(x), 2^x, sine, cosine, and arctangent, executing them within SIMD vectors to deliver very high performance.
What Does This Mean For Performance Metrics?
With four-dimensional parallel processing capabilities, the DesignWare ARC VPX5 processor IP meets the demands for high-throughput applications for floating-point and linear algebra processing. Compared to other DSP processors with similar architectures, this solution offers industry-leading performance metrics—for example, the highest configured VPX5 can provide 512 half-precision floating-point operations per cycle at 1.5GHz, equivalent to 768 GFLOP. Furthermore, the ARC VPX5 can deliver 16 floating-point mathematical computations per cycle based on the usage of linear algebra operations. For 8-bit integer data used in machine learning computation algorithms, the VPX5 can provide up to 512 MACs per cycle.
The DesignWare ARC MetaWare development tools are now available to support the VPX5 processor, providing a complete compiler, debugging, and simulation platform. This enables developers to quickly and efficiently compile C code algorithms into the processing engines of the VPX5 core. The loop-equivalent simulation platform allows developers to freely evaluate loop count performance and check the optimal performance of critical algorithms and programs. In addition to providing DSP libraries, the DesignWare ARC MetaWare development tools also offer linear algebra and machine learning inference (MLI) libraries. This allows developers to easily port code to databases through API interfaces and quickly achieve optimal performance. Various neural network-based computing components are provided for MLI algorithms to enable high-performance software AI computation.
The DesignWare ARC VPX5 processor IP is the next generation DSP designed to meet the data computation needs of processing-intensive applications. The four parallel processing dimensions for floating-point, AI, and linear algebra computation enable the DesignWare ARC VPX5 processor to deliver ultra-high performance for applications such as automotive ADAS sensor nodes (RADAR and LiDAR), 5G new radio (NR) communication baseband modems, power systems, engine management, robotics, motor control, and 5G automotive communication (5G C-V2X). With industry-leading 512 FLOP/cycle and a unique 16 mathematical FLOP/cycle for linear algebra, the VPX5 provides system developers with the performance to meet the demands of next-generation high-performance computing algorithms. Combined with the ARC MetaWare development tools that include DSP and mathematical libraries, developers can quickly port C code algorithms and achieve optimal performance to accelerate time-to-market.
Author: Graham Wilson, Product Marketing Manager, Synopsys ARC Processors