Reprinted from AI Technology ReviewInsights into the replication of Manus from cutting-edge research on agents.
The emergence of Manus has pushed agents to the forefront of the current AI landscape, making this previously somewhat abstract concept tangible. However, there is no shortage of controversy in the industry regarding Manus, with critics arguing that it lacks underlying technological innovation and is more about integrating existing technologies to innovate in engineering, a phenomenon referred to as “shelling”.
While engineering innovation is indeed a form of competitive advantage, the term “shelling” is not without merit. In recent years, both academia and industry have made significant progress in the technology and practical results of agents. At the AI Agent Reasoning and Decision-Making Symposium (AIR 2025), researchers from University College London, Nanyang Technological University, Weco AI, Google DeepMind, Meta, Huawei, Alibaba, and others discussed reinforcement learning, reasoning, decision-making, and AI agents.
Professor An Bo from Nanyang Technological University in Singapore revealed the evolution from RL-based agents to LLM-powered agents, sharing multiple advancements from his team regarding agents. The Q* algorithm employs multi-step reasoning as cautious planning, requiring offline reinforcement learning to alternately update Q-value labels and fit QVM, using rewards from the best-performing rollback trajectories, and rewards from trajectories completed with more powerful LLMs, which involves three key steps.
Yuxiang, CTO of the startup Weco AI, elaborated on the search for intelligence in the solution space, introducing the AI-driven agent—AIDE, capable of handling complete machine and engineering tasks. If machine learning and engineering are viewed as a code optimization problem, it formalizes the entire search or code optimization process as a tree search in the solution space. In this formalized solution space, AIDE is a code space that any large language model can write.
Song Yan from University College London approached the topic from DeepSeek, discussing the role of reinforcement learning in large language model reasoning and pointing out another “Aha moment” in reinforcement learning, where large language models learned to self-correct during the reinforcement learning phase, possibly due to their foundational models already possessing self-correction capabilities. It was further discovered that when agents used certain keywords, they engaged in various backtracking, self-reporting, and complex reasoning.
Researcher Feng Xidong from Google DeepMind initially outlined the concept of describing the components of reinforcement learning in natural language, which would redefine all reinforcement learning concepts as content represented in natural language, attempting to map strategies, value functions, Bellman equations, Monte Carlo sampling, temporal difference learning, and policy improvement operators to their natural language counterparts.
This article compiles highlights from the conference, with the following being the core content of the speeches:
1Transformative Forces of Agents: From RL to LLM
Professor An Bo from Nanyang Technological University delivered a talk titled “From RL-based to LLM-powered Agents,” revealing the evolution from RL-based agents to LLM-powered agents in recent years and sharing multiple advancements regarding agents.

Last year, we conducted some work that combined a temporary model to improve its performance on certain benchmark problems. Our approach was to learn strategies from interactions with the environment, thus possessing strong practical applicability. Therefore, I believe we are trying to leverage the advantages of prior knowledge, drawing from both the model and practical applicability to enhance performance.
For this work, we found that utilizing knowledge models could enhance performance in certain practical work scenarios.
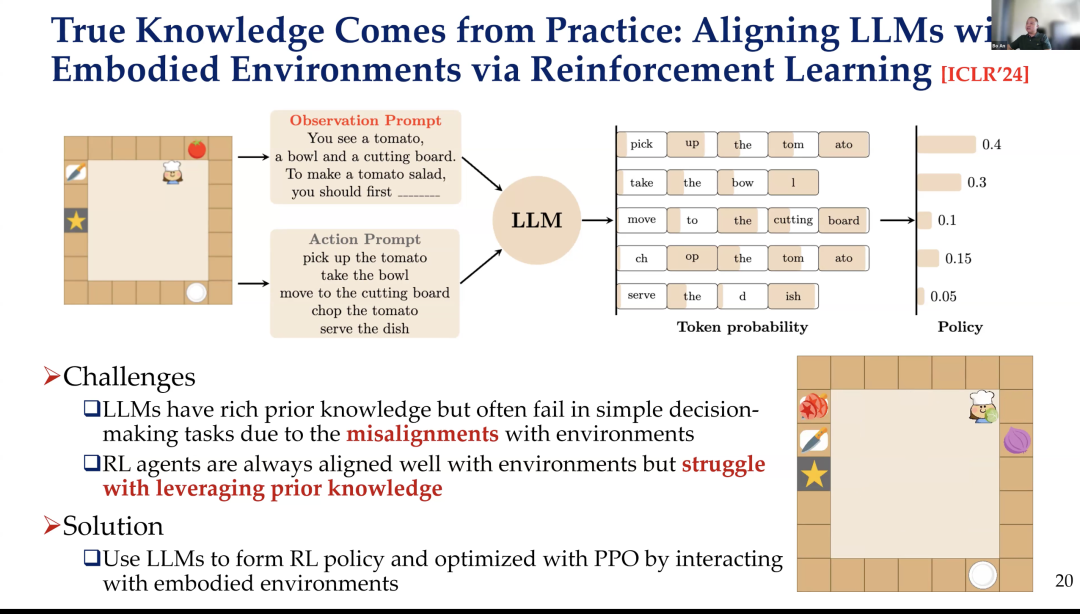
Reasoning and inference are crucial, especially after the release of OpenAI-o1 and DeepSeek R1. We have a version purely based on our own research, which is indeed very challenging.
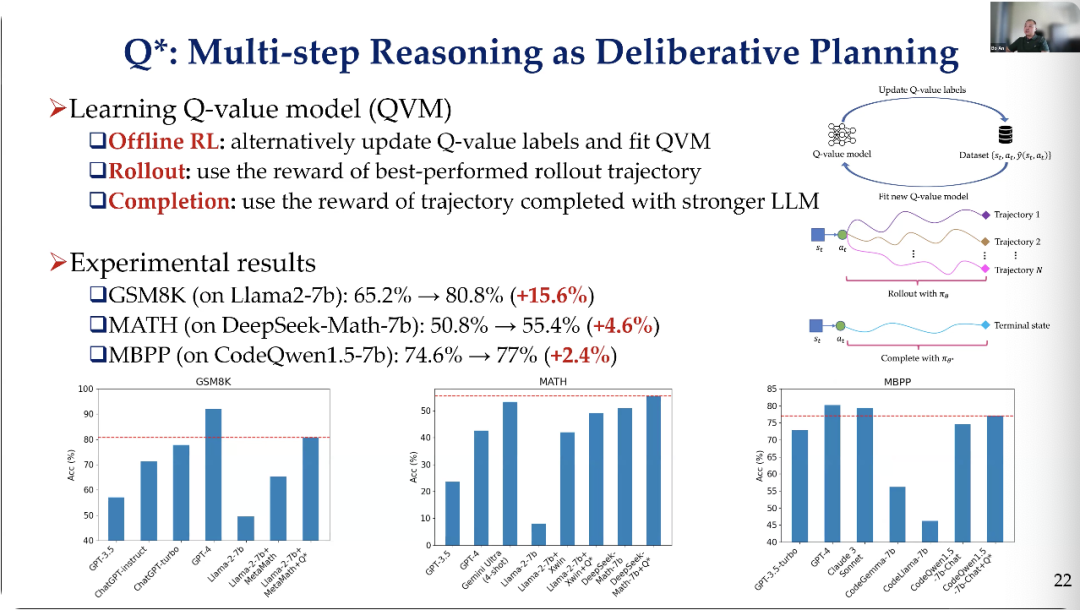
However, we published the first paper on Q* before OpenAI released related models. We need a G function to estimate the cost from the initial state to the current node. In our work, the G function we used was trained by leveraging data from the literature. For the heuristic function (h value), we actually made our own corrections.
Thus, based on our data, there are many ways to train such a powerful model. Ultimately, we combined both and applied the A* search algorithm to enhance the reasoning capabilities of large language models.

So, we conducted some early experiments. You can lower those values because the foundational model was not strong enough at that time. I think the key point is that if you apply this reasoning method, it can enhance the performance of the foundational model.
Then we trained their Q-value function in some way. Therefore, we are also considering whether we can overcome difficulties, such as applying this method to improve recent DeepSeek models and other models.
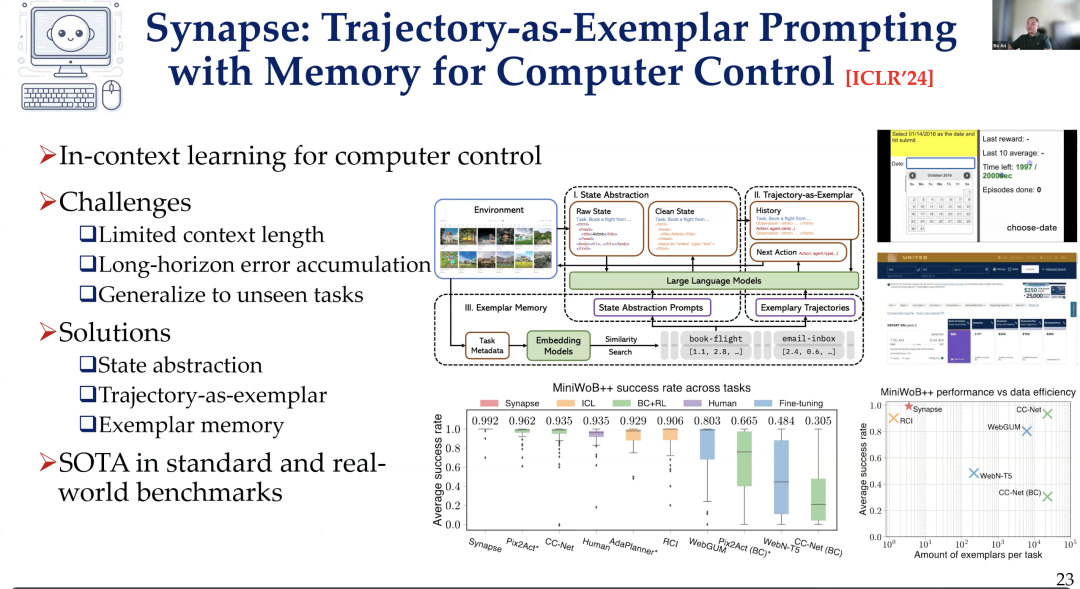
Thus, we also did some work on Synapse in terms of control, which was one of our results published early last year. This work involved ideas such as state abstraction training, learning from demonstrations, and using memory, among other methods, to improve computer control tasks.
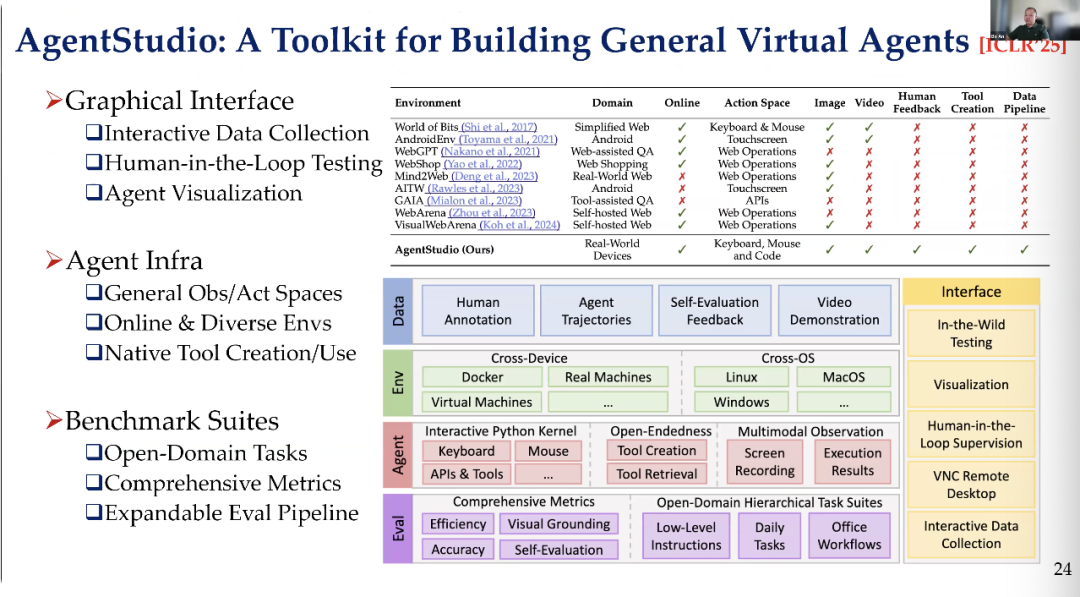
We also provided a developer toolkit for building general virtual agents. We offered better interfaces, more robust front-end support, and a large number of benchmarks for designing general virtual agents suitable for PC control, computer control, and other scenarios, as well as for mobile device control.
The next work involves using language model-driven agents to play challenging video games.
Therefore, we built an agent architecture that includes different components, such as the need to understand the environment. It contains a reflection model, memory model, retrieval model, etc., to tackle many challenging video games and different software. This project is open-source and very appealing to those interested.

Recently, we conducted some unpublished work on fine-tuning language models using reinforcement learning (RL).
I think this is somewhat different from some earlier work, as in most of the work we have seen in the past, reinforcement learning did not involve agents. You know, people just built different components, using language models as brains and combining other components to handle complex tasks.
But here, I believe that in the future, for many real-world problems, we need the capabilities of reinforcement learning. However, if we want to apply reinforcement learning to these scenarios, we will face many challenges, the most significant of which is the exponential growth of the exploration space. Because the sampling space for open and practical action skills grows exponentially with the size and thickness of the rectangle, as the exploration space is at the token level, the token space is enormous. Therefore, we need to address the exploration problem. At the same time, we note that not all tokens play a meaningful role in the final decision-making action.
So, I think the insight we gain here is that we must design some mechanisms to determine how to conduct more effective exploration to improve the efficiency of reinforcement learning fine-tuning, thereby enhancing the performance of language models. Therefore, we designed a method called “CoSo,” which contains several key ideas. First, we use factual reasoning to identify tokens that are critical to actions.
Not every token influences the actions taken by the agent or has the same impact. Therefore, we use causal reasoning to identify these tokens and then use this information to decide how to explore. Secondly, we can interrupt the optimization process and focus our exploration on those influential tokens.
This utilizes the results we learned in the first step. Then we conducted many experiments and observed that this method significantly improved the performance of visual language models (VLM) on some very challenging tasks. I believe this is still an ongoing work, such as the creative work I just mentioned.

2Searching for Intelligence in the Solution Space
Yuxiang, CTO of the startup Weco AI, shared a talk titled “AIDE: Searching Intelligence in the Space of Solutions,” elaborating on new thoughts on finding intelligence in the solution space and introducing a powerful AI-driven agent—AIDE.
We call it AIDE because it acts like a powerful AI-driven agent capable of handling complete machine and engineering tasks. So, if we view machine learning and engineering as a code optimization problem, it formalizes the entire search or code optimization process as a tree search in the solution space. In this formalized solution space, it is merely a code space that any large language model can write.
You may have seen other more specific agents, such as those prompt API agents or reactive agents, which organize all historical solutions into a tree structure. Then, all these historical solutions are incorporated into context, but this process is actually incremental. Therefore, it quickly accumulates contextual information, so it may not perform well in long-term code optimization processes.

So, this problem is redefined as an optimization problem. Machine learning can be done in machines, and then we can define all relevant evaluation metrics. This aligns very well with the machine learning engineering agent we proposed, whose defined rewards or optimization objectives are also very simple. We are merely searching in this code space, aiming to optimize the objective function in machine learning code and machine learning engineering tasks. This objective function can be validation accuracy, loss, or any metric related to your machine learning cost.
In this case, the code space is very specifically defined as the Python script space used to solve the problem. The benefit is that we can now compare solutions on a fair metric and make these research methods that depend on a single known evaluation standard more unified, making the entire search process more robust.

Therefore, we developed this algorithm, which is essentially a tree search problem. You start from an empty tree, first generating an initial node, which is actually a set of basic solutions. Then, it iteratively proposes new solutions by looking at existing code and existing solutions. These solutions have already been generated, and then it will propose your solutions, and based on this idea, it will generate that code, run the code to evaluate the solutions, and record new nodes.
The evaluation metric here is scrolling (scroll), which is usually in machine learning tasks, this metric can be accuracy, loss, or whatever you call it. Then it will select the next node based on this metric for further optimization. So, it involves all these search strategies, summarization operators, and coding operators. These operators are no longer entirely defined by algorithms but are partially defined by large language models.

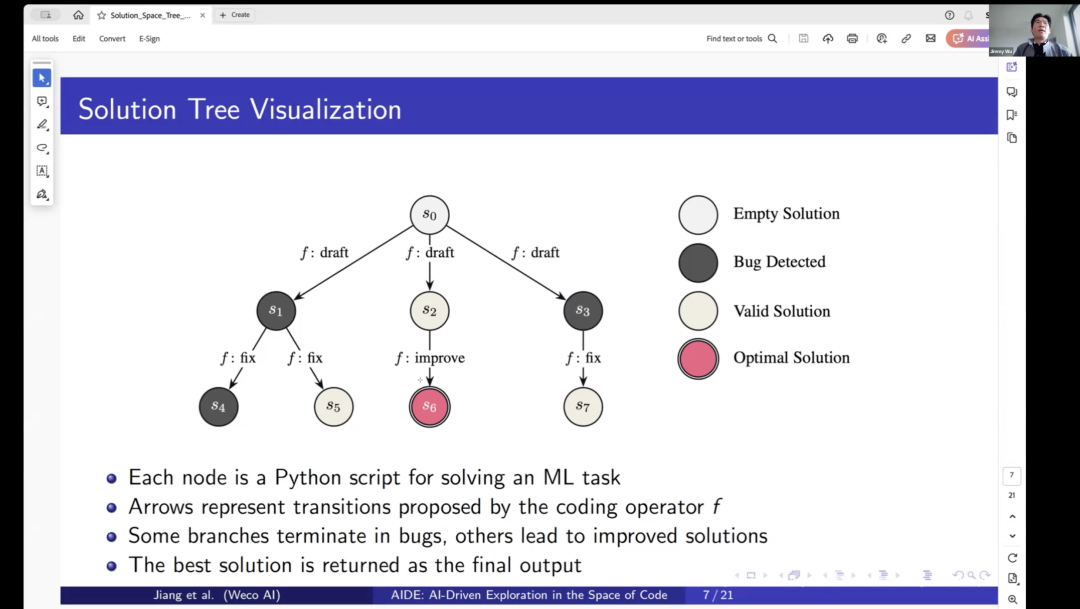
So, to illustrate more intuitively, we start from S0, which is an initial empty solution, that is, our data state. We do not have any existing solutions for machine learning tasks, and then it starts drafting three. For example, drafting three solutions in different directions. So in the prompt, there is a trick where we explicitly ask it to explore different directions to ensure sufficient diversity between S01, S2, and S3. Then in the next step, it will choose a node to start optimizing.
For example, trying different steps to fix the problem, if it successfully fixes it, it becomes a valid solution. Then this solution is stored as a valid solution, at which point you have a current best node, such as S5, and then it starts exploring the next node to optimize. It will ensure that each drafted solution is explored at least once and will generate another improved solution from nodes like S2, which will then be evaluated as solution 6 or 7, and this process will continue until all optimization steps are exhausted.
So ultimately, selecting the optimal solution is actually quite simple because all these solutions are evaluated using the same evaluation metric. Therefore, based on the evaluation metric, you can obtain that optimal solution.
What defines the entire process? There are several key components. First is the search strategy. In this case, we actually adopted a very simple hot encoding strategy.
In the drafting phase, when it drafts multiple solutions, since it does not yet have a tree, meaning we have not assigned initial solutions, it will create multiple solutions to explore different methods. And in the debugging phase, when it enters the debugging phase, it will have a maximum debugging step limit, and it will stay at that node until it reaches the allowed maximum debugging steps.
Typically, we set this maximum debugging step to 10 to 20 steps to avoid the agent spending too much time debugging, thus falling into an almost infinite loop, wasting a lot of time and computational resources. Of course, the most important and interesting part is not when to choose a node for improvement.
So when it finishes debugging or drafting, it will enter a stage to improve a bucket node. This is just a greedy algorithm that will select the currently best-performing solution in the tree and then decide to further optimize the highest-performing node in the tree.

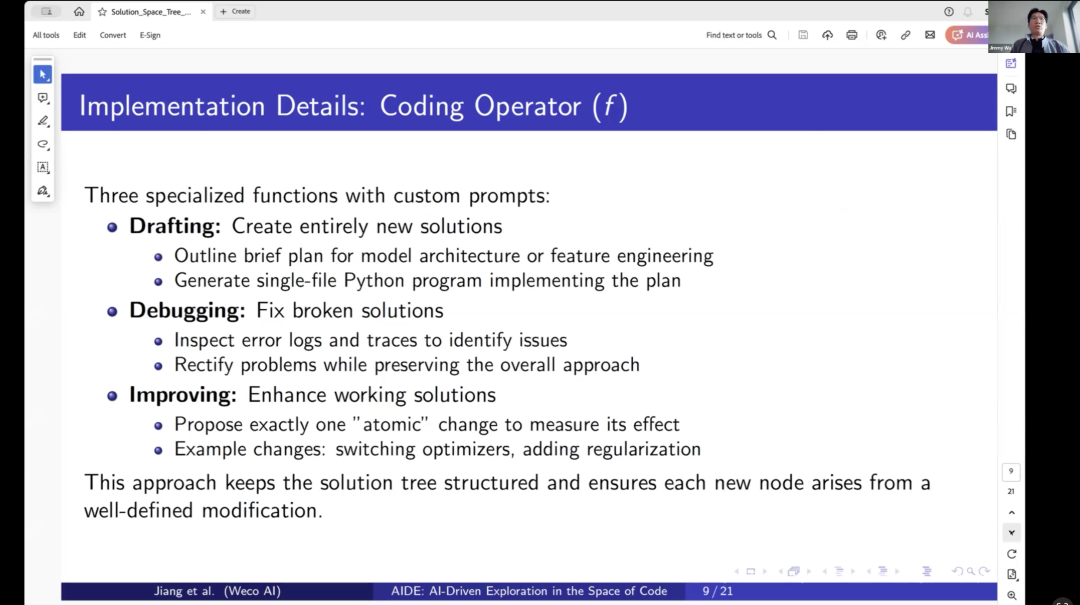
So in the coding operators, we will also adopt different prompting strategies based on different stages. For example, in the drafting phase, we encourage it to formulate a plan for model architecture and feature engineering and ask it to generate a single-file Python program to implement this plan. In the underlying phase, the agent will receive error logs and stack traces to identify the problem.
Then, it will correct the problem by retaining the overall previous approach. Therefore, we ensure that debugging does not actually change the solution itself. In the improvement mode or improvement phase, we prompt the agent to propose an atomic-level change. This is another observation we want to incorporate into this framework, that each step is actually interpretable. The actions themselves are interpretable and atomic.
Thus, we do not allow the agent or large language model to propose multiple improvements at once. Instead, we prompt it to make improvements step by step, incrementally. In this process, we do not skip any intermediate steps of optimization ideas, which allows it to conduct more detailed exploration and overall greater interpretability.
That is to say, it can better demonstrate what the best path to reach the optimal solution is. For example, switching optimizers, adding a layer, making the network deeper, or transitioning from one architecture to another, adding regularization, etc. If you check the final tree trajectory or tree structure it generates, you will find many such atomic optimization steps, and many times these steps are very insightful.
Finally, because a major issue is that you need to manage context, such as possibly needing to run 8 steps. For example, OpenAI ran 500 steps, and even Gemini cannot really handle such long contexts. So, there must be a way to manage context. This is what we call the summarization operator, which extracts relevant information to avoid context overload.
The summarization operator will include performance metrics, such as current accuracy, high parameter settings, and information from the debugging phase. This is very important, especially in the debugging phase. The benefit is that we can truncate the number of nodes it could handle before.
We can place the summarized information into the context of the large language model to generate debugging nodes or improvement nodes. This will maintain an almost constant window size for the agent to use, allowing us to truly scale over a long time frame, such as comparison steps.
Moreover, because we define it as step-by-step improvement, this also makes the entire optimization operator stateless. It no longer relies on the entire trajectory but is stateless, and will not grow explosively like prompts or context size.

3Focusing on Generalist GUI Agents
Shiao Kun from Huawei London delivered a talk titled “Towards Generalist GUI Agents: Model and Optimization,” introducing models and optimizations for generalist GUI agents.
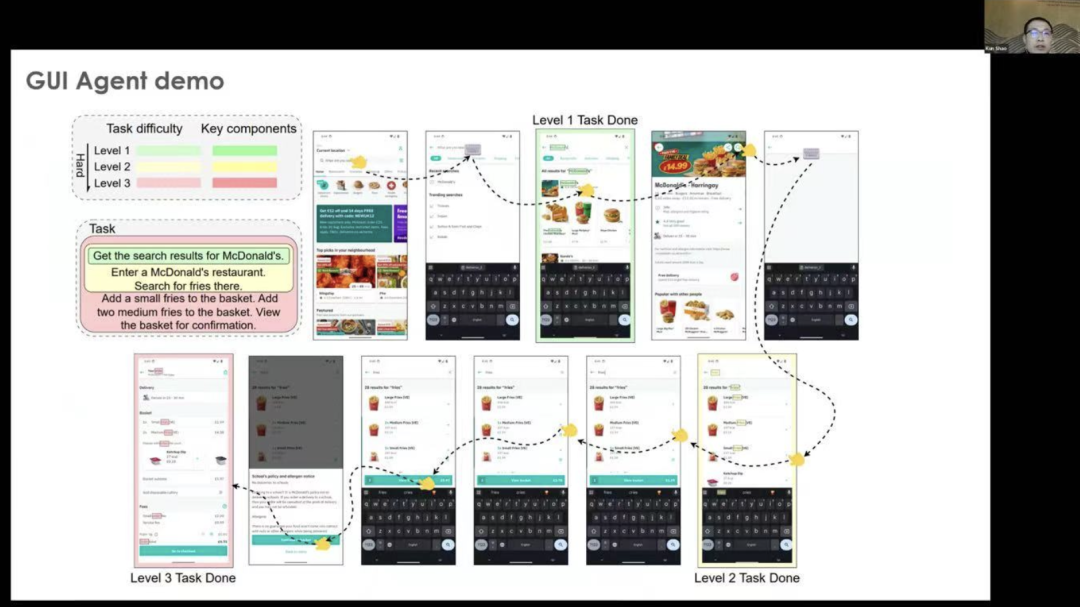
Below is a demonstration of GUI agents, which have different tasks, such as obtaining research results about the dollar. We can start from the main user interface page. Then, we can perform some steps to go to McDonald’s, enter the McDonald’s restaurant, and search for fries there. We can also set multiple steps and enhance the objectives. This is where GUI agents can assist us.

On another website, the GUI agent may find better solutions to help humans complete such tasks. This is the significance of GUI agents.
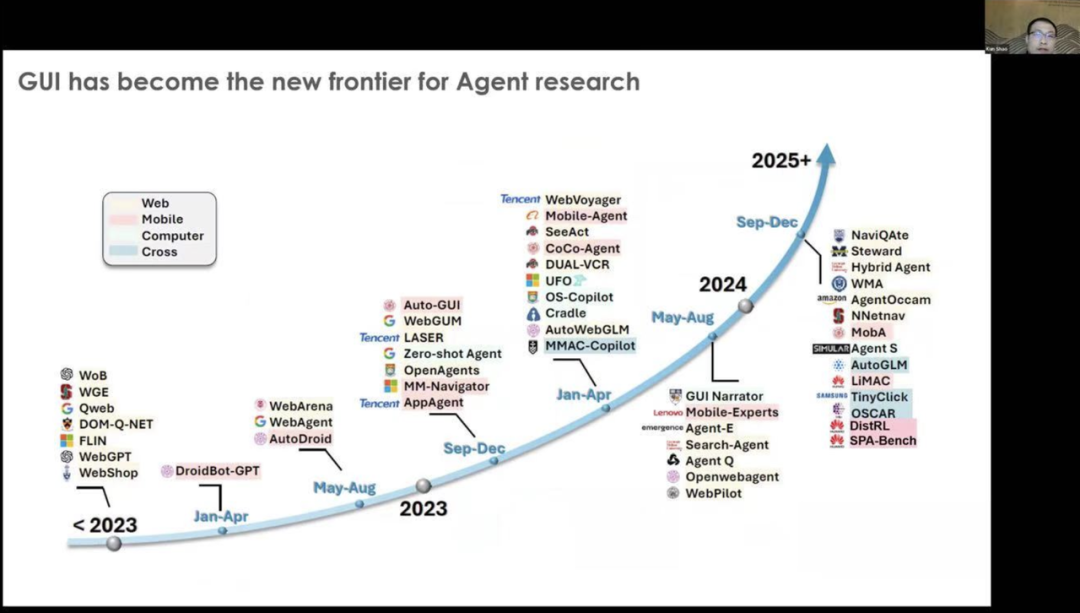
From 2023 to 2025, you can see that GUI agents have become widely popular. It has reignited interest in agent research, with both academia and large tech companies focusing on GUI agents. This attention is not limited to mobile devices but also covers websites and computing fields.
 We also introduced these themes into GUI agents, such as the first one being about generation. In fact, using this model to guide actions is not ideal. Therefore, when we provide the current model capabilities for GUI agents, we have different types of improvement methods to achieve better models. But you must understand how to implement it, how to design Pythonian for the UI, and how to design a hierarchical architecture.The second is about agent systems. After we have the project model, we also need some other automated models to improve the performance and efficiency of GUI agents. To achieve this, we have different solutions, including database planning, reflection mechanisms, and we can also use memory and retrievers.Another key point I want to emphasize is that we also want to do a lot of work on fine-tuning, as it can be said that reinforcement learning is very important for the fine-tuning of agents, and we need some purpose. For example, how to leverage the current model as a benchmark. How to play the role of the generative role model, and how to better fine-tune the role model. At the same time, we need to find better ways to achieve efficient, reliable, and robust reinforcement learning training, and we need to find the algorithms that best suit GUI agents.The final question is about evaluation. When designing different benchmark tasks, evaluation is very important for two agents, and we need to design evaluation metrics.
We also introduced these themes into GUI agents, such as the first one being about generation. In fact, using this model to guide actions is not ideal. Therefore, when we provide the current model capabilities for GUI agents, we have different types of improvement methods to achieve better models. But you must understand how to implement it, how to design Pythonian for the UI, and how to design a hierarchical architecture.The second is about agent systems. After we have the project model, we also need some other automated models to improve the performance and efficiency of GUI agents. To achieve this, we have different solutions, including database planning, reflection mechanisms, and we can also use memory and retrievers.Another key point I want to emphasize is that we also want to do a lot of work on fine-tuning, as it can be said that reinforcement learning is very important for the fine-tuning of agents, and we need some purpose. For example, how to leverage the current model as a benchmark. How to play the role of the generative role model, and how to better fine-tune the role model. At the same time, we need to find better ways to achieve efficient, reliable, and robust reinforcement learning training, and we need to find the algorithms that best suit GUI agents.The final question is about evaluation. When designing different benchmark tasks, evaluation is very important for two agents, and we need to design evaluation metrics.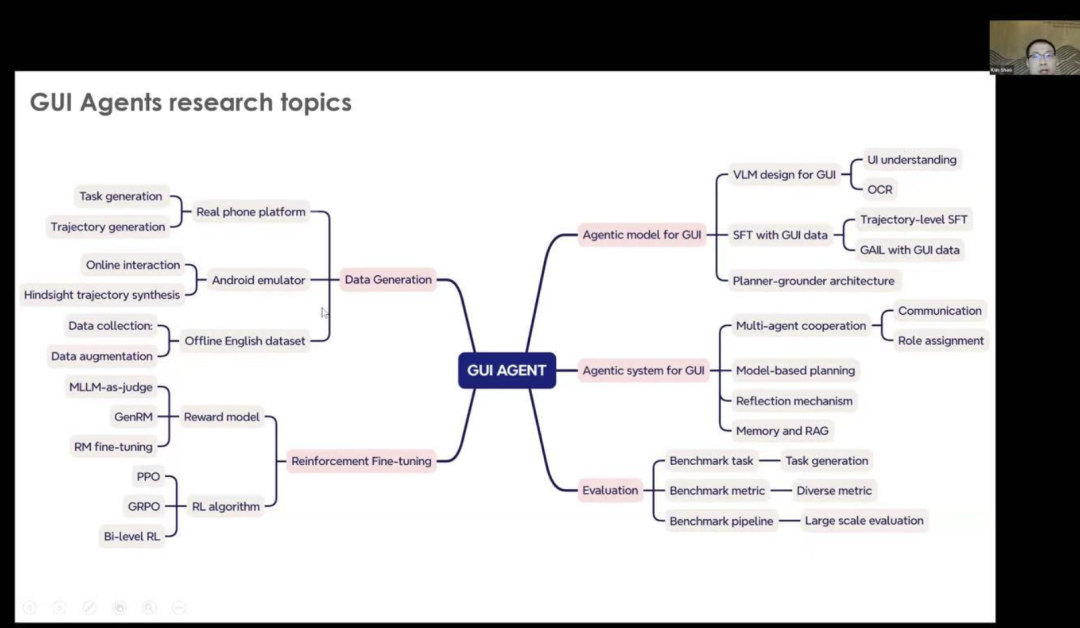 Similarly, we also propose some research questions.The first question is that we need to find and propose a benchmark test. Because currently, we can see many papers about GUI agents. So we need to design a comprehensive benchmark test that can be used for different applications and different agents. Therefore, when you find a process for evaluating agents, it should not rely solely on human intervention.The second part is that we need to design an action model. It is well known that if we only use the current foundational model to perform agent tasks, we need to find some ways to train a model that performs well and efficiently.The final question is about how to efficiently fine-tune GUI agents. We must enable agents to make full use of limited data and gradually improve performance. Fine-tuning for GUI agents is not an easy task, so we also need to find some ways to address this issue.
Similarly, we also propose some research questions.The first question is that we need to find and propose a benchmark test. Because currently, we can see many papers about GUI agents. So we need to design a comprehensive benchmark test that can be used for different applications and different agents. Therefore, when you find a process for evaluating agents, it should not rely solely on human intervention.The second part is that we need to design an action model. It is well known that if we only use the current foundational model to perform agent tasks, we need to find some ways to train a model that performs well and efficiently.The final question is about how to efficiently fine-tune GUI agents. We must enable agents to make full use of limited data and gradually improve performance. Fine-tuning for GUI agents is not an easy task, so we also need to find some ways to address this issue. 4The “Aha Moment” of DeepSeek Reinforcement LearningSong Yan from UCL delivered a talk titled “The Power of Reinforcement Learning in LLM Reasoning,” discussing the role of reinforcement learning in large language model reasoning.This is the result of R1-zero, which has excellent benchmark results, even outperforming OpenAI’s o1. Even more impressively, its training process is very stable. Moreover, it shows excellent scalability. For R1-zero, its past accuracy is not better than the latest original version. But when you try to generate content, it can obviously produce better results.
4The “Aha Moment” of DeepSeek Reinforcement LearningSong Yan from UCL delivered a talk titled “The Power of Reinforcement Learning in LLM Reasoning,” discussing the role of reinforcement learning in large language model reasoning.This is the result of R1-zero, which has excellent benchmark results, even outperforming OpenAI’s o1. Even more impressively, its training process is very stable. Moreover, it shows excellent scalability. For R1-zero, its past accuracy is not better than the latest original version. But when you try to generate content, it can obviously produce better results.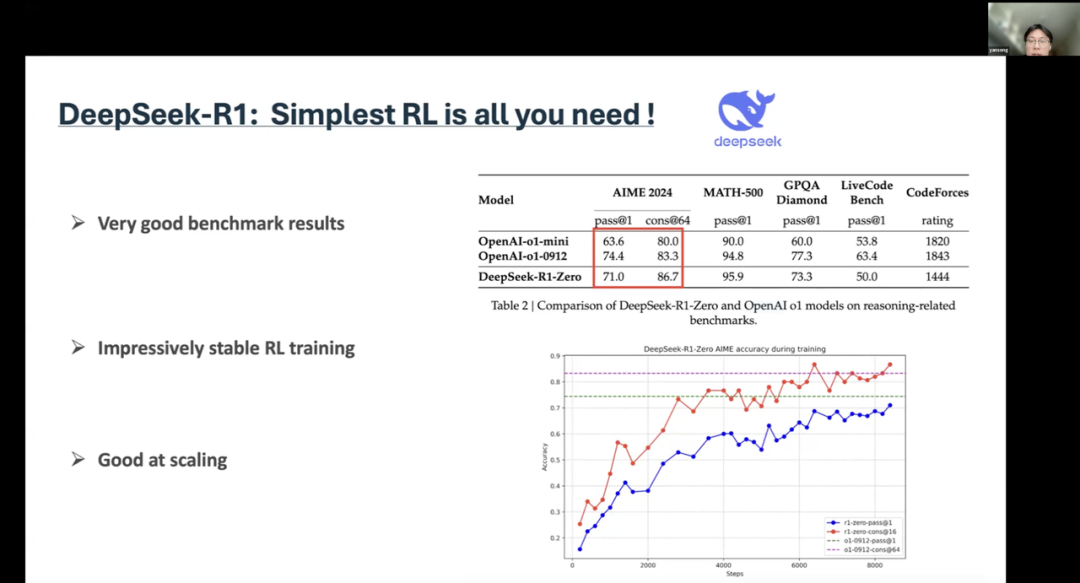 There is also an “Aha moment” mentioned in their paper. During the reinforcement learning phase, the language model learned to increase the thinking budget. This may be because you need more tokens to think and solve some problems. This view is supported by some evidence. They found that when agents used certain keywords, they engaged in various backtracking, self-reporting, and complex reasoning.But there is also another possible explanation. First, the foundational model itself already possesses self-correction capabilities. So, from a technical perspective, this is not a very “Aha” moment, but rather indicates that reinforcement learning can indeed work under simple settings. I think that is the most important.
There is also an “Aha moment” mentioned in their paper. During the reinforcement learning phase, the language model learned to increase the thinking budget. This may be because you need more tokens to think and solve some problems. This view is supported by some evidence. They found that when agents used certain keywords, they engaged in various backtracking, self-reporting, and complex reasoning.But there is also another possible explanation. First, the foundational model itself already possesses self-correction capabilities. So, from a technical perspective, this is not a very “Aha” moment, but rather indicates that reinforcement learning can indeed work under simple settings. I think that is the most important.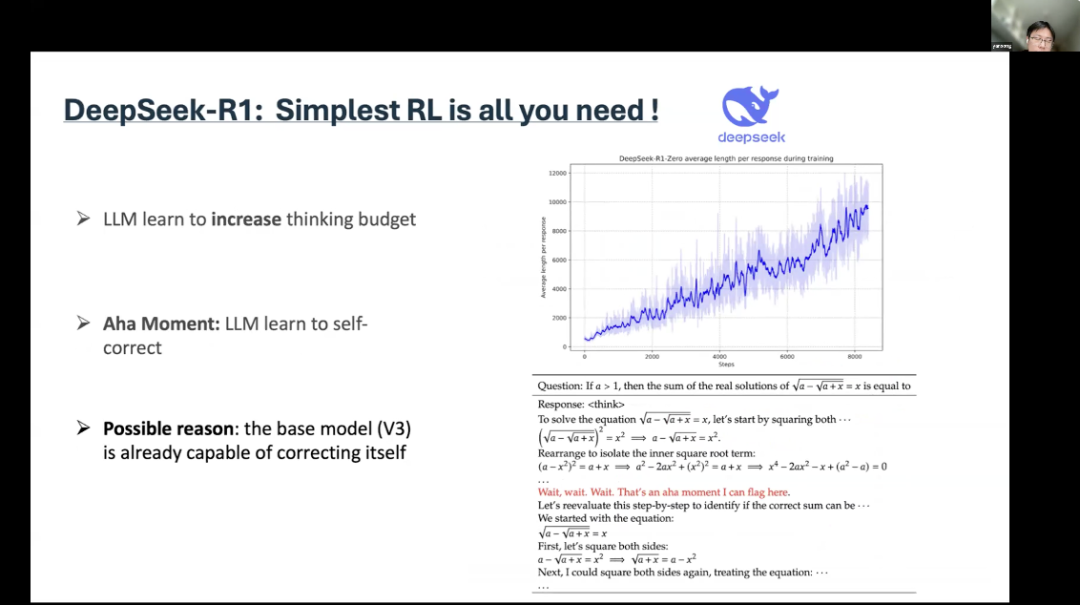 For the R1 version, they started training with initial data and then trained in a reinforcement learning (RL) scenario. The conclusion is that large language models (LLMs) have strong capabilities to perform stable reinforcement learning, while small language models adopt knowledge distillation for training.
For the R1 version, they started training with initial data and then trained in a reinforcement learning (RL) scenario. The conclusion is that large language models (LLMs) have strong capabilities to perform stable reinforcement learning, while small language models adopt knowledge distillation for training.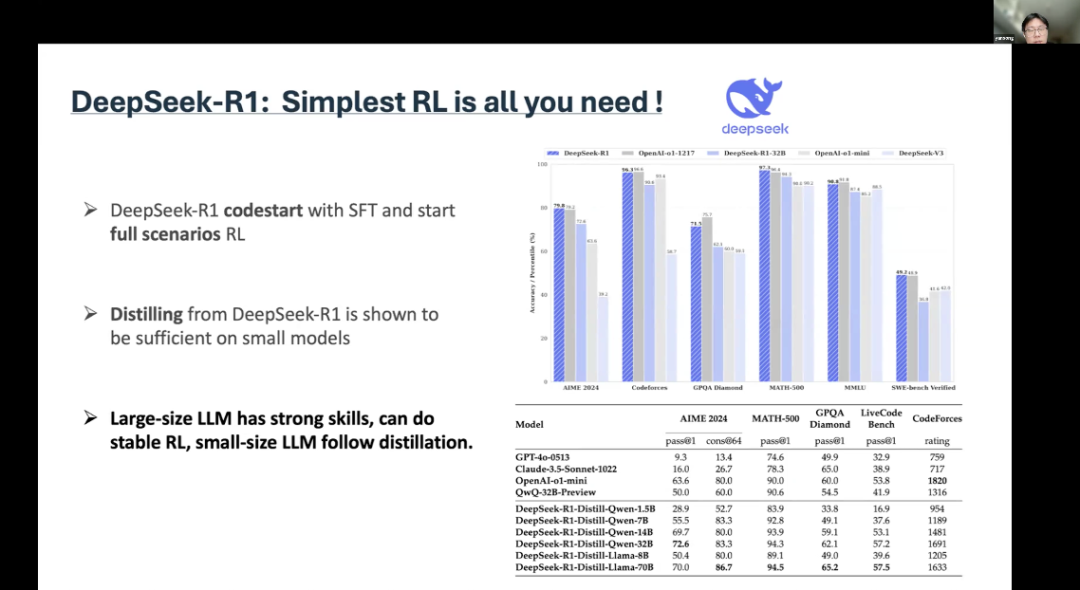 After the release of R1, we launched TinyZero in subsequent training and incremental updates, which is a large model with 3 billion parameters. In addition, SimpleRL achieved Zero-RL on a 7 billion parameter LLM. So, all this work used Zero-RL. At least the basic idea is that you need a strong foundational model to learn reasoning. The next step is that they can learn to explore, and then they can learn to self-correct.
After the release of R1, we launched TinyZero in subsequent training and incremental updates, which is a large model with 3 billion parameters. In addition, SimpleRL achieved Zero-RL on a 7 billion parameter LLM. So, all this work used Zero-RL. At least the basic idea is that you need a strong foundational model to learn reasoning. The next step is that they can learn to explore, and then they can learn to self-correct. Recently, there have also been some multimodal Zero-RL works. These works are based on the Open-R1 codebase, OpenRLHF codebase, or Verl codebase.
Recently, there have also been some multimodal Zero-RL works. These works are based on the Open-R1 codebase, OpenRLHF codebase, or Verl codebase. We also conducted some small-scale experiments. The basic setup is that we try to train on mathematical problems, selecting difficulty levels from three to five, which is consistent with the previous codebase settings of SimpleRL. We found this quite important. We need to filter, and we did this on Qwen2.5-Math-7B.Its performance is good, as shown in the figure. The blue line indicates reinforcement learning starting from the foundational model, which can generalize to AIME2024, which is very difficult to solve. But it was only trained on mathematical problems, and by using supervised fine-tuning data, it can achieve better performance on GSM8k. However, on AIME2024, the results it provided were very poor. This indicates that supervised fine-tuning data may impair the generalization ability brought by reinforcement learning.We also conducted experiments on LLaMA, but the results were not ideal.
We also conducted some small-scale experiments. The basic setup is that we try to train on mathematical problems, selecting difficulty levels from three to five, which is consistent with the previous codebase settings of SimpleRL. We found this quite important. We need to filter, and we did this on Qwen2.5-Math-7B.Its performance is good, as shown in the figure. The blue line indicates reinforcement learning starting from the foundational model, which can generalize to AIME2024, which is very difficult to solve. But it was only trained on mathematical problems, and by using supervised fine-tuning data, it can achieve better performance on GSM8k. However, on AIME2024, the results it provided were very poor. This indicates that supervised fine-tuning data may impair the generalization ability brought by reinforcement learning.We also conducted experiments on LLaMA, but the results were not ideal.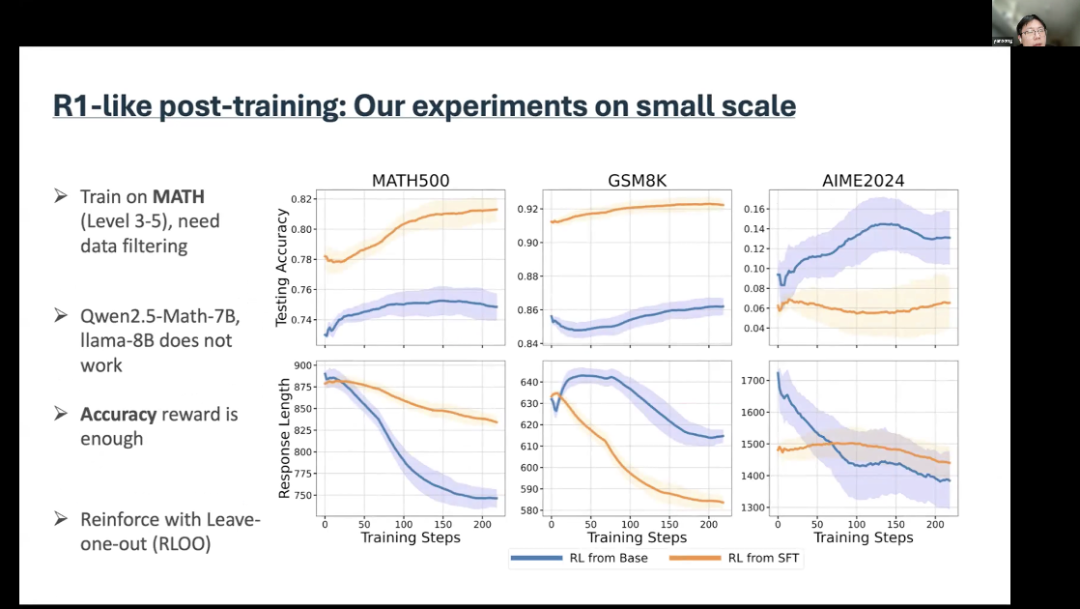
Next, Yan Song will also share some forward-looking insights from recent work.
 5A New Paradigm of Natural Language Reinforcement LearningFeng Xidong from UCL and Google DeepMind explored “Natural Language Reinforcement Learning,” introducing the idea of describing the components of reinforcement learning in natural language.What if we had a new paradigm of reinforcement learning? What if we learned a language value function instead of learning a predetermined value function? In other words, we try to describe the value of states and state-action pairs using natural language. Why not express all components of reinforcement learning in language? This is precisely the direction we have been working on recently.
5A New Paradigm of Natural Language Reinforcement LearningFeng Xidong from UCL and Google DeepMind explored “Natural Language Reinforcement Learning,” introducing the idea of describing the components of reinforcement learning in natural language.What if we had a new paradigm of reinforcement learning? What if we learned a language value function instead of learning a predetermined value function? In other words, we try to describe the value of states and state-action pairs using natural language. Why not express all components of reinforcement learning in language? This is precisely the direction we have been working on recently. We draw inspiration from traditional reinforcement learning concepts, but we are redefining all these reinforcement learning concepts as content in the natural language representation space. We attempt to map strategies, value functions, Bellman equations, Monte Carlo sampling, temporal difference learning, and policy improvement operators to their natural language counterparts.Here I present an example of this. In reinforcement learning, you have a policy that is distributed. But in natural language reinforcement learning, you might have a language policy. That is, you do not necessarily need to directly map your states and actions. Instead, you can try saying, “I will analyze the state first and then take action.” So, let us respond with a language policy.In traditional reinforcement learning, you have scalar rewards, i.e., immediate rewards. But in natural language reinforcement learning, you might have language feedback, such as “You have achieved the goal,” which is not just a +1 reward like in traditional reinforcement learning; it can contain richer information.In terms of states, you do not need to be a high-dimensional state; you can also describe states using language. For example, you can say, “You are rolling…” and so on. For value functions, in reinforcement learning, we have been accustomed to using expected cumulative rewards in the past. But now, we can have a more natural language representation. We can try to summarize future trajectories using language descriptors, and ultimately, there is the Bellman equation.The traditional Bellman equation attempts to measure the relationship between the current state and its subsequent states. We can also do something similar in natural language evaluation. If you are trying to evaluate the current state, then your current state evaluation cannot differ significantly from the subsequent state evaluation. Therefore, your natural language evaluation must have consistency and self-consistency across continuous states. So, this is also the Bellman equation, but it occurs in the natural language space.
We draw inspiration from traditional reinforcement learning concepts, but we are redefining all these reinforcement learning concepts as content in the natural language representation space. We attempt to map strategies, value functions, Bellman equations, Monte Carlo sampling, temporal difference learning, and policy improvement operators to their natural language counterparts.Here I present an example of this. In reinforcement learning, you have a policy that is distributed. But in natural language reinforcement learning, you might have a language policy. That is, you do not necessarily need to directly map your states and actions. Instead, you can try saying, “I will analyze the state first and then take action.” So, let us respond with a language policy.In traditional reinforcement learning, you have scalar rewards, i.e., immediate rewards. But in natural language reinforcement learning, you might have language feedback, such as “You have achieved the goal,” which is not just a +1 reward like in traditional reinforcement learning; it can contain richer information.In terms of states, you do not need to be a high-dimensional state; you can also describe states using language. For example, you can say, “You are rolling…” and so on. For value functions, in reinforcement learning, we have been accustomed to using expected cumulative rewards in the past. But now, we can have a more natural language representation. We can try to summarize future trajectories using language descriptors, and ultimately, there is the Bellman equation.The traditional Bellman equation attempts to measure the relationship between the current state and its subsequent states. We can also do something similar in natural language evaluation. If you are trying to evaluate the current state, then your current state evaluation cannot differ significantly from the subsequent state evaluation. Therefore, your natural language evaluation must have consistency and self-consistency across continuous states. So, this is also the Bellman equation, but it occurs in the natural language space.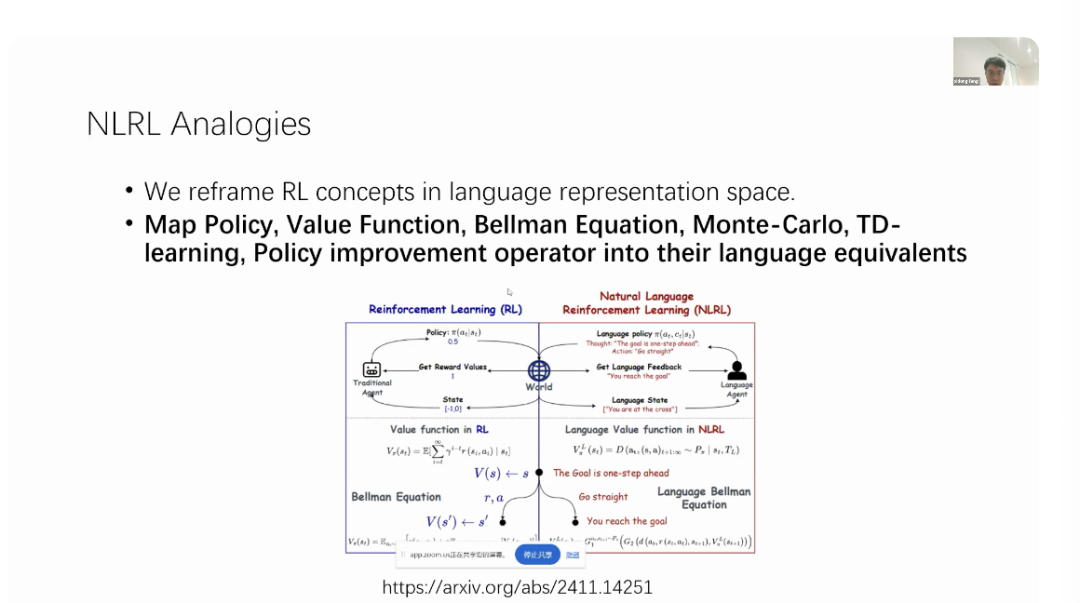 Similarly, we can try to map traditional Monte Carlo sampling and temporal difference learning methods into natural language. Suppose we have two language aggregators G1 and G2. In traditional Monte Carlo methods, we estimate the cumulative discounted reward by sampling a large number of trajectories and try to estimate our trajectory by calculating the average reward of these trajectories.In natural language, we can also do something similar. We start sampling from time step (t+1) until infinity. We have many language-based geometric sampling results, and we assume we have some language information aggregators because, of course, we cannot perform averaging or summation operations on language as they are not numerical. But if there is a language aggregator, we can ask it to summarize and aggregate information from these different sampled language trajectories.G1 can be responsible for aggregating evaluation results from multiple trajectories and aggregating all steps into one item. This is physically the same thing, just happening in a different space. Therefore, we need to implement different aggregation operators in traditional reinforcement learning. In traditional reinforcement learning, it is the average; in the language-based case, it is just a language aggregator.The same goes for temporal difference learning. The idea of temporal difference learning is that if you are trying to evaluate the value of the current state, you can take a step forward and combine the immediate reward with the future state evaluation results to form your evaluation of the current state.In natural language reinforcement learning, we can also do exactly the same thing. Suppose we have two language aggregators G1 and G2, where G2 is responsible for merging immediate rewards and future evaluation results. We can let G2 receive immediate transformation descriptions and future state evaluation results, and let G1 be responsible for aggregating evaluation results from multiple trajectories. Although the implementation methods differ between traditional reinforcement learning and natural language reinforcement learning, the concepts are similar. You can see how our new language temporal difference learning responds to traditional temporal difference learning through different aggregators.
Similarly, we can try to map traditional Monte Carlo sampling and temporal difference learning methods into natural language. Suppose we have two language aggregators G1 and G2. In traditional Monte Carlo methods, we estimate the cumulative discounted reward by sampling a large number of trajectories and try to estimate our trajectory by calculating the average reward of these trajectories.In natural language, we can also do something similar. We start sampling from time step (t+1) until infinity. We have many language-based geometric sampling results, and we assume we have some language information aggregators because, of course, we cannot perform averaging or summation operations on language as they are not numerical. But if there is a language aggregator, we can ask it to summarize and aggregate information from these different sampled language trajectories.G1 can be responsible for aggregating evaluation results from multiple trajectories and aggregating all steps into one item. This is physically the same thing, just happening in a different space. Therefore, we need to implement different aggregation operators in traditional reinforcement learning. In traditional reinforcement learning, it is the average; in the language-based case, it is just a language aggregator.The same goes for temporal difference learning. The idea of temporal difference learning is that if you are trying to evaluate the value of the current state, you can take a step forward and combine the immediate reward with the future state evaluation results to form your evaluation of the current state.In natural language reinforcement learning, we can also do exactly the same thing. Suppose we have two language aggregators G1 and G2, where G2 is responsible for merging immediate rewards and future evaluation results. We can let G2 receive immediate transformation descriptions and future state evaluation results, and let G1 be responsible for aggregating evaluation results from multiple trajectories. Although the implementation methods differ between traditional reinforcement learning and natural language reinforcement learning, the concepts are similar. You can see how our new language temporal difference learning responds to traditional temporal difference learning through different aggregators.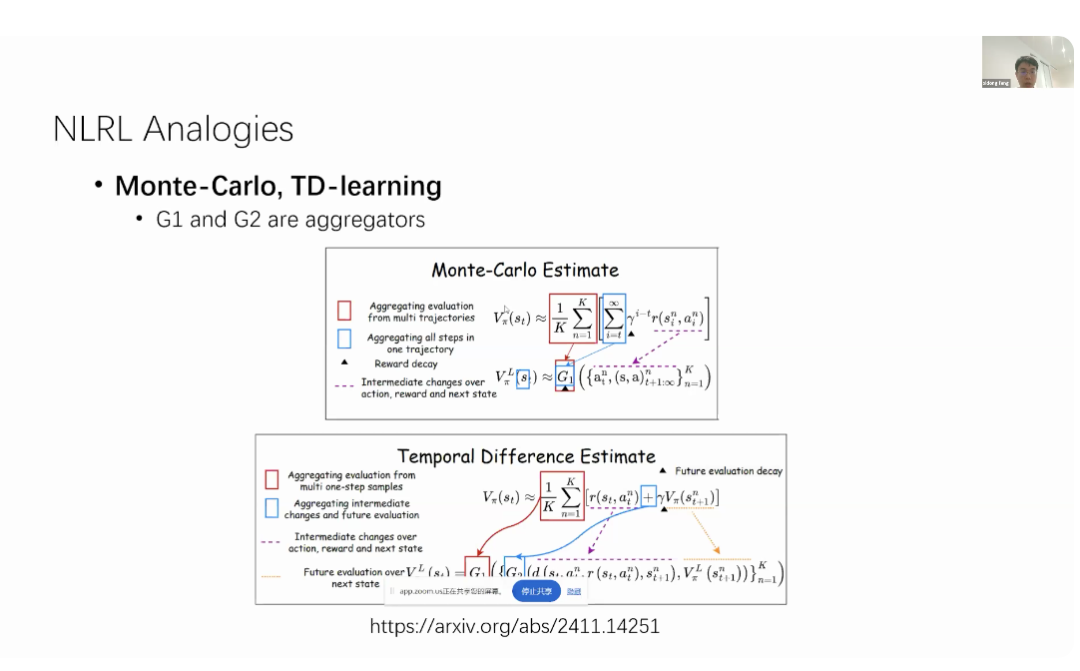 After explaining the concept, Xidong Feng also discussed the specific implementation of this method, providing several paths for utilizing large language models (LLMs) to achieve natural language reinforcement learning (NLRL).
After explaining the concept, Xidong Feng also discussed the specific implementation of this method, providing several paths for utilizing large language models (LLMs) to achieve natural language reinforcement learning (NLRL).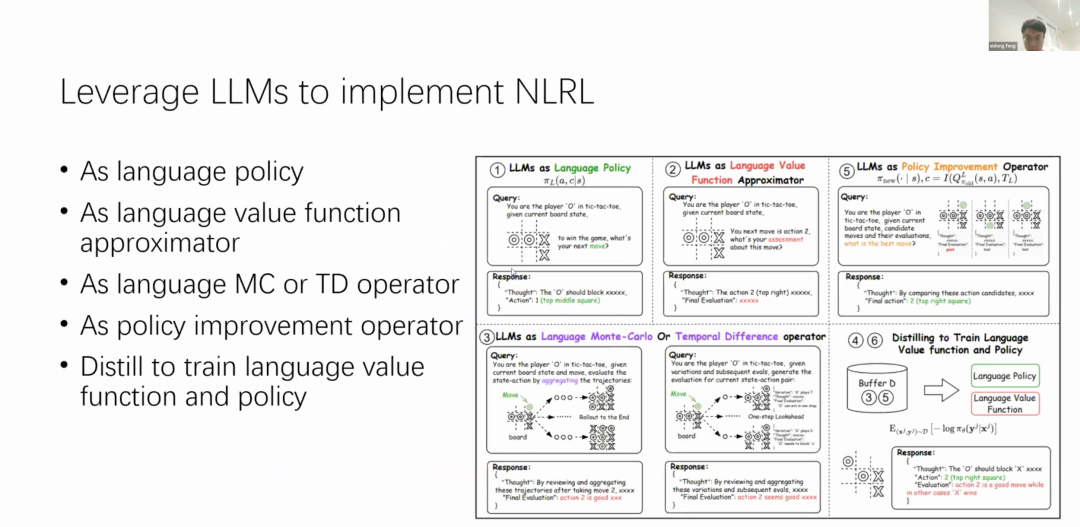 6Qwen’s Long Text Capability: Faster Speed, Lower CostLin Junyang from Alibaba Tongyi Qianwen delivered a talk titled “Qwen: Towards Generalist Models,” systematically introducing the technical and engineering progress of Tongyi Qianwen. Below are details about the data volume of the Tongyi Qianwen large model.In the Qwen2.5 version, the data volume expanded to 18T. But now we are considering training with more tokens, such as 30 trillion to 40 trillion tokens. This is just a huge number, but it is important for training large models, as it requires not only high-quality data but also a large amount of data. This is why we conduct multi-stage pre-training, as you need to train on a large amount of data. However, there is dirty data in the first stage, then higher quality, and then to even higher quality in different stages.
6Qwen’s Long Text Capability: Faster Speed, Lower CostLin Junyang from Alibaba Tongyi Qianwen delivered a talk titled “Qwen: Towards Generalist Models,” systematically introducing the technical and engineering progress of Tongyi Qianwen. Below are details about the data volume of the Tongyi Qianwen large model.In the Qwen2.5 version, the data volume expanded to 18T. But now we are considering training with more tokens, such as 30 trillion to 40 trillion tokens. This is just a huge number, but it is important for training large models, as it requires not only high-quality data but also a large amount of data. This is why we conduct multi-stage pre-training, as you need to train on a large amount of data. However, there is dirty data in the first stage, then higher quality, and then to even higher quality in different stages.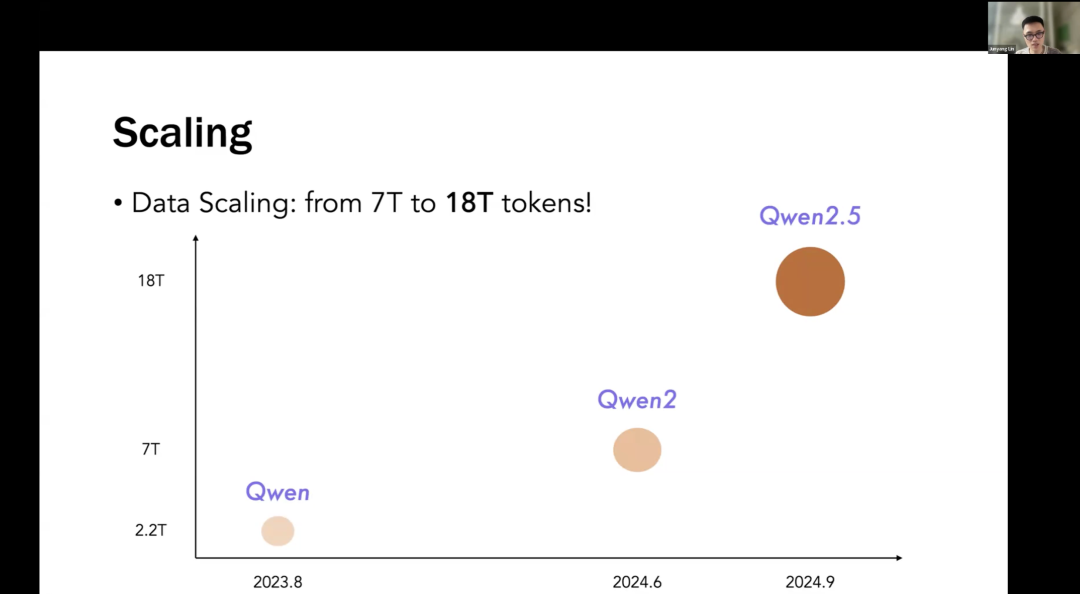 In terms of model scale, we have open-sourced seven different scales of models, ranging from 0.5B to 72B. Therefore, you can study scaling laws through these different scales of models. But currently, we are discussing dense models, and we are now considering MoE (Mixture of Experts) models, which are somewhat similar to dense models but have more technical details in training and memory models, but overall it still follows scaling laws.In scaling model size, it is not just about the size of the model itself but also the scale of activation parameters. There is also a scanning method, but the model size gating has proven to be very effective. There are many details in our open-source models that you can check out.
In terms of model scale, we have open-sourced seven different scales of models, ranging from 0.5B to 72B. Therefore, you can study scaling laws through these different scales of models. But currently, we are discussing dense models, and we are now considering MoE (Mixture of Experts) models, which are somewhat similar to dense models but have more technical details in training and memory models, but overall it still follows scaling laws.In scaling model size, it is not just about the size of the model itself but also the scale of activation parameters. There is also a scanning method, but the model size gating has proven to be very effective. There are many details in our open-source models that you can check out.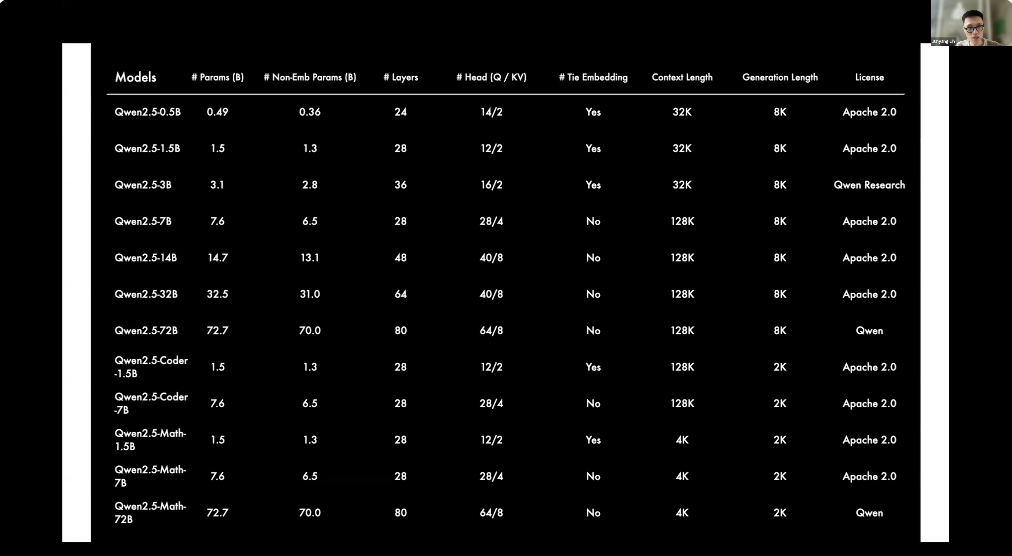 In terms of extending context length, this is also a problem we have been very concerned about before. The context length of models trained previously was 32K tokens and then extended to 128K tokens. Is it really that long? But you can even extend it to 10 million, which is also possible. Now people are considering moving towards infinite length, so they hope to achieve this using a traditional multi-head attention mechanism. Perhaps linear attention is the future direction, but we have not made significant breakthroughs in this area yet.However, we have some techniques to further extend it without further training. This is a technique that does not require training, called Trunk Attention, and you can check the technical report on Trunk Attention.Our team published a related paper at ICML, and another technical issue is in deployment. A model with 1 million context tokens is very difficult to deploy. Therefore, you need to use some techniques to introduce sparsity to speed up inference. You can see that previously generating a token took 5 minutes, but now it only takes 1 minute, which also means it will be cheaper because of the sparsity in the attention mechanism, but we found that performance did not decline, or in the context of 1 million tokens, we achieved a cost-effective expected performance.
In terms of extending context length, this is also a problem we have been very concerned about before. The context length of models trained previously was 32K tokens and then extended to 128K tokens. Is it really that long? But you can even extend it to 10 million, which is also possible. Now people are considering moving towards infinite length, so they hope to achieve this using a traditional multi-head attention mechanism. Perhaps linear attention is the future direction, but we have not made significant breakthroughs in this area yet.However, we have some techniques to further extend it without further training. This is a technique that does not require training, called Trunk Attention, and you can check the technical report on Trunk Attention.Our team published a related paper at ICML, and another technical issue is in deployment. A model with 1 million context tokens is very difficult to deploy. Therefore, you need to use some techniques to introduce sparsity to speed up inference. You can see that previously generating a token took 5 minutes, but now it only takes 1 minute, which also means it will be cheaper because of the sparsity in the attention mechanism, but we found that performance did not decline, or in the context of 1 million tokens, we achieved a cost-effective expected performance.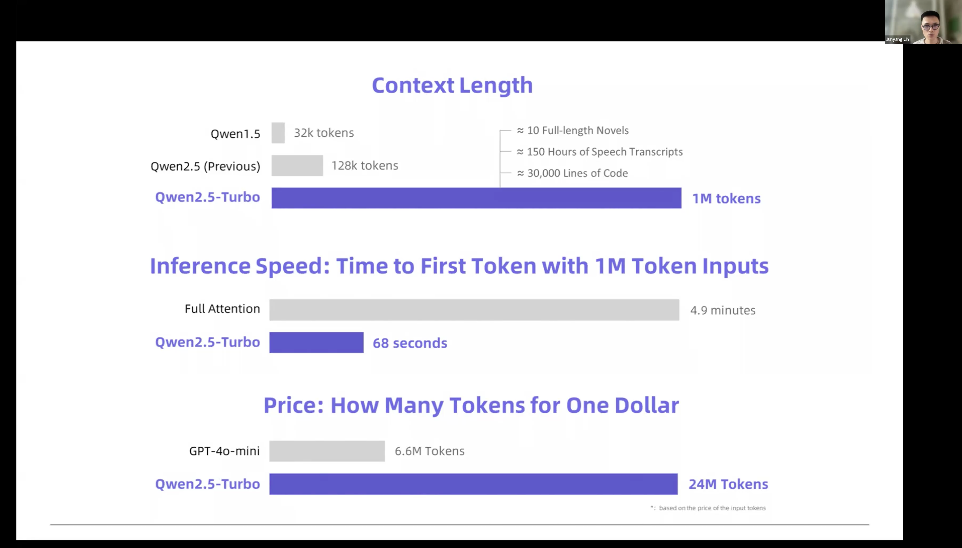 In addition to understanding long contexts, there is another extension, which is the ability to generate long contexts. Previously, we could generate 8K tokens, but you will find that this is still not enough. Because now we have long chain reasoning (Long Chain of Thought), it was previously insufficient to generate very, very long texts, but now the situation has changed significantly. Perhaps now it can generate text of about 12.8K tokens, which is actually achievable. For the current Qwen, it can actually generate about 32K tokens of text.
In addition to understanding long contexts, there is another extension, which is the ability to generate long contexts. Previously, we could generate 8K tokens, but you will find that this is still not enough. Because now we have long chain reasoning (Long Chain of Thought), it was previously insufficient to generate very, very long texts, but now the situation has changed significantly. Perhaps now it can generate text of about 12.8K tokens, which is actually achievable. For the current Qwen, it can actually generate about 32K tokens of text.
