Article Overview
1. Background and Challenges
– Transformers are widely used in natural language processing, but the computational cost is high, making them unsuitable for mobile devices.
– Automated Neural Architecture Search (NAS) is effective but has huge search costs and environmental costs.
2. Lite Transformer Design
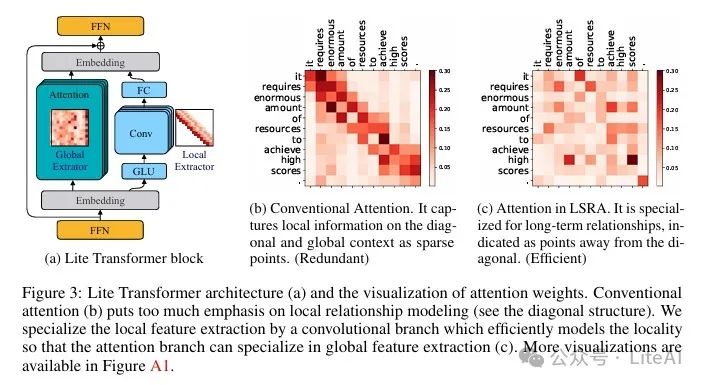
– Proposes a Long-Short Distance Attention (LSRA) mechanism that divides attention into global and local branches.
– The global branch uses the attention mechanism, while the local branch uses convolution to capture local dependencies.
3. Experiments and Results
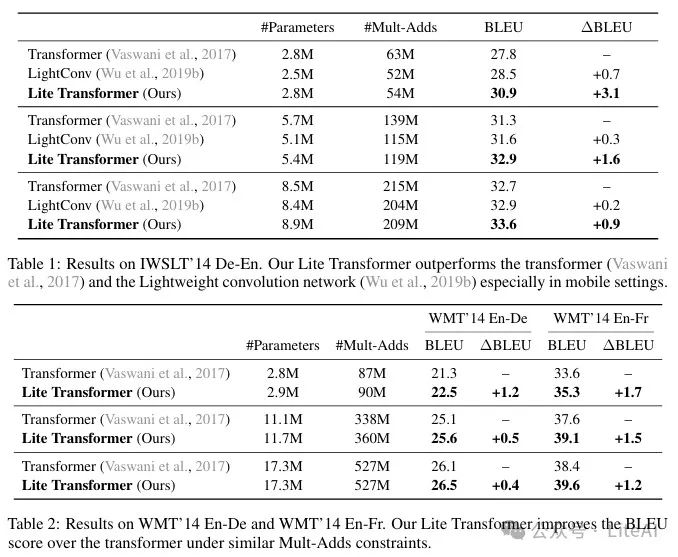
– In machine translation tasks, Lite Transformer exceeds Transformer by 1.2/1.7 BLEU under 500M/100M MACs constraints.
– In language modeling tasks, Lite Transformer reduces perplexity by 1.8 compared to Transformer under 500M MACs.
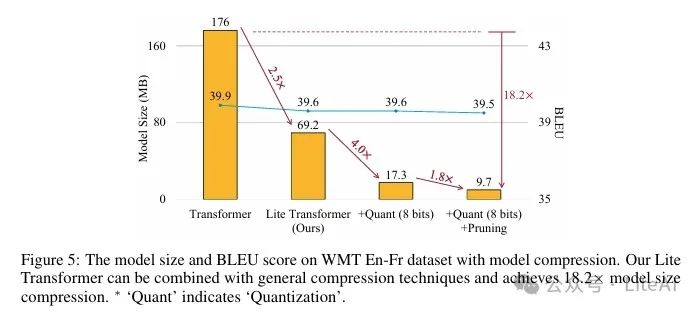
– Lite Transformer combines pruning and quantization, compressing the model size by 18.2 times.
4. Comparison with AutoML
– Lite Transformer outperforms AutoML-based Evolved Transformer by 0.5 BLEU in mobile settings.
– The design cost of Lite Transformer is significantly reduced, resulting in a 20,000 times reduction in CO₂ emissions.
5. Conclusion
– Lite Transformer significantly outperforms Transformer in multiple language tasks and is suitable for mobile devices.
– Demonstrates that manual design combined with domain knowledge is more effective than AutoML for specific tasks.

Article link: https://arxiv.org/pdf/2004.11886
Project link: https://github.com/mit-han-lab/lite-transformer
TL;DR
Article Method
Lite Transformer is an efficient natural language processing (NLP) architecture designed for mobile devices.
1. Long-Short Distance Attention (LSRA) Mechanism:
– The core of Lite Transformer is the Long-Short Distance Attention (LSRA) mechanism, which divides attention into global and local branches.
– The global branch focuses on modeling long-distance dependencies using standard attention mechanisms.
– The local branch focuses on modeling local dependencies using Convolutional Neural Networks (CNN).
3. Model Architecture:
– Lite Transformer is based on a sequence-to-sequence (seq2seq) learning architecture, consisting of an encoder and a decoder.
– The self-attention layers in the encoder and decoder are replaced with LSRA modules.
– The LSRA module consists of two branches: the attention branch and the convolution branch. The input is split into two parts along the channel dimension, fed into the two branches, and finally merged through a feedforward layer (FFN).
Experimental Results
1. Machine Translation Task:
– IWSLT 2014 German-English:
– Under the constraint of 100M Mult-Adds, Lite Transformer outperforms Transformer by 3.1 BLEU.
– WMT 2014 English-German:
– Under the constraint of 500M Mult-Adds, Lite Transformer outperforms Transformer by 0.4 BLEU.
– Under the constraint of 100M Mult-Adds, Lite Transformer outperforms Transformer by 1.2 BLEU.
– WMT 2014 English-French:
– Under the constraint of 500M Mult-Adds, Lite Transformer outperforms Transformer by 1.2 BLEU.
– Under the constraint of 100M Mult-Adds, Lite Transformer outperforms Transformer by 1.7 BLEU.
2. Abstractive Summarization Task:
– On the CNN-DailyMail dataset, Lite Transformer maintains similar F1-Rouge scores compared to Transformer while reducing computational load by 2.4 times and model size by 2.5 times.
3. Language Modeling Task:
– On the WIKITEXT-103 dataset, Lite Transformer reduces perplexity by 1.8 under the constraint of 500M MACs compared to Transformer.
4. Model Compression:
– Combining pruning and quantization techniques, Lite Transformer compresses its model size by 18.2 times.
5. Comparison with AutoML:
– In mobile settings, Lite Transformer outperforms AutoML-based Evolved Transformer by 0.5 BLEU, and the design cost is significantly reduced, leading to a 20,000 times reduction in CO₂ emissions.
Final Thoughts
Scan to add me, or add WeChat (ID: LiteAI01) for discussions on technology, career, and professional planning. Please note “Research direction + School/Region + Name”