Fog Computing is a term created by Cisco, supported by the OpenFog Consortium, which was established in November 2015 by Arm, Cisco, Dell, Intel, Microsoft, and Princeton University’s Edge Lab. The mission statement (in part) is as follows:
Our work will define the architecture of distributed computing, networking, storage, control, and resources to support intelligence at the Internet of Things (IoT) edge, including self-aware machines, objects, devices, and smart objects. OpenFog members will also identify and develop new operational models. Ultimately, our work will contribute to the realization and advancement of the next generation of IoT.
Edge computing is driven by EdgeX Foundry, an open-source project hosted by the Linux Foundation. The goals of EdgeX Foundry include: building and promoting EdgeX as a universal platform for unified IoT edge computing; certifying EdgeX components to ensure interoperability and compatibility; providing tools for rapidly creating EdgeX-based IoT edge solutions, and collaborating with relevant open-source projects, standards organizations, and industry alliances.
According to EdgeX Foundry, “The best points of the project are edge nodes, such as embedded PCs, hubs, gateways, routers, and local servers, to address the key interoperability challenges of distributed IoT fog’s ‘north-south’ interactions.”
The Technical Steering Committee of EdgeX Foundry includes representatives from IOTech, ADI, Mainflux, Dell, the Linux Foundation, Samsung Electronics, VMware, and Canonical.
There are also two other industry organizations in this field: the Japan-focused EdgeCross Alliance, established in November 2017 by Omron Corporation, Advantech, NEC, IBM Japan, Oracle Japan, and Mitsubishi Electric; and the Industrial Internet Consortium, founded in 2014 by AT&T, Cisco, General Electric, Intel, and IBM.
The rapid development of IoT technology and the promotion of cloud services have made the cloud computing model inadequate for solving current problems. Therefore, a new computing model, edge computing (fog computing), is proposed. Edge computing refers to processing data at the edge of the network, which can reduce request response time, enhance battery life, minimize network bandwidth while ensuring data security and privacy. This article will introduce relevant concepts of edge computing through several cases, covering cloud offloading, smart homes, smart cities, and collaborative edge nodes to achieve edge computing. It is hoped that this article will inspire you and encourage more people to engage in edge computing research.
What is Edge Computing
Data generated at the network edge is gradually increasing. If we could process and analyze data at the edge nodes of the network, this computing model would be more efficient. Many new computing models are continuously being proposed because we find that with the development of IoT, cloud computing is not always that efficient. The following sections of the article will outline some reasons to demonstrate why edge computing can be more efficient and superior to cloud computing.
Let’s use a metaphor involving humans…
First, let’s visualize a diagram in our brain, which is a neural network diagram of the human brain. If you can’t envision it, just look at the image below:
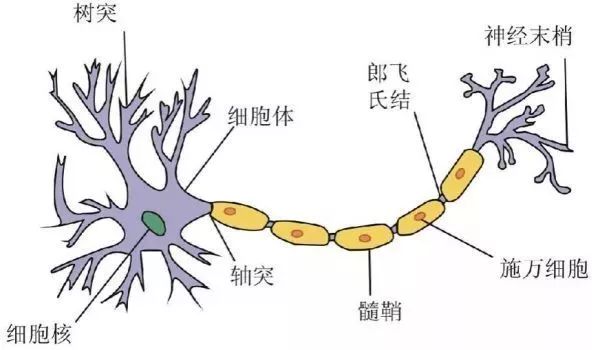
Consider cloud computing as the brain, while edge computing is like the neural tentacles outputted by the brain, connecting to various terminals to perform different actions.
If this still feels abstract, let’s try a less precise analogy.
Imagine your cloud brain as an octopus, the kind that can be eaten as sashimi.

As the most intelligent invertebrate in nature, the octopus possesses the ability of “conceptual thinking,” which is inseparable from its two powerful memory systems. One is the brain memory system, which contains 500 million neurons, and the other is the suckers on its eight tentacles. In other words, the octopus’s eight legs can think and solve problems.
The brain is indeed a great thing, and the octopus has several of them!
Back to the topic, cloud computing is like clouds in the sky, visible yet intangible, like the brain of the octopus, while edge computing resembles the small tentacles of the octopus, with each tentacle representing a small data center, close to the actual physical objects. Edge computing is closer to the device side, closer to the user.
In a way, cloud computing grasps the overall picture, while edge computing focuses more on local details. Therefore, the advantages of edge computing become evident.
Advantages of Edge Computing
1. Better Real-Time Processing
Due to the distributed and device-side proximity characteristics of edge computing, it has the advantage of real-time processing, thus better supporting local business real-time processing and execution.
2. High Efficiency
There’s no need to trouble the distant cloud for local matters; edge computing directly filters and analyzes the data from terminal devices, saving energy and time while enhancing efficiency.
3. Reduced Traffic and Low Bandwidth
Edge computing alleviates the pressure of data explosion and network traffic by processing data at edge nodes, reducing the data flow from devices to the cloud.
4. Intelligent and Energy Efficient
The combination of AI and edge computing not only involves computation but also exhibits significant intelligent characteristics. Additionally, the combination of cloud computing and edge computing results in costs that are only 39% of using cloud computing alone.
In the field of facial recognition, response time has been reduced from 900ms to 169ms.
After offloading some computational tasks from the cloud to the edge, the overall system’s energy consumption has decreased by 30%-40%.
Data integration and migration can save up to 20 times in time.
5. Privacy
The existing service provision method involves uploading mobile terminal user data to the cloud and utilizing the powerful processing capabilities of the cloud to handle tasks. During the data upload process, data can easily be collected by malicious actors. To ensure data privacy, we can take the following steps:
1. Process user data at the network edge, so that data is only stored, analyzed, and processed locally.
2. Set permissions for different applications to restrict access to private data.
3. The edge network is highly dynamic and requires effective tools to protect data during transmission across the network.
Applications of Edge Computing
Cloud Offloading
In traditional content delivery networks, data is cached at edge nodes. With the development of IoT, data production and consumption occur at edge nodes, meaning that edge nodes also need to undertake certain computational tasks. The process of offloading computing tasks from the cloud center to edge nodes is called cloud offloading.
For example, the development of mobile internet allows us to shop smoothly on mobile devices. Our shopping cart and related operations (adding, deleting, modifying, querying products) rely on uploading data to the cloud center. If we offload the relevant data and operations of the shopping cart to edge nodes, it will greatly improve response speed and enhance user experience by reducing latency and improving interaction quality between people and systems.
Video Analysis
With the increase of mobile devices and the deployment of cameras in cities, utilizing video for certain purposes has become an appropriate means. However, the cloud computing model is no longer suitable for such video processing because the massive data transmission over the network may cause congestion, and the privacy of video data is difficult to guarantee.
Therefore, edge computing is proposed, allowing the cloud center to offload relevant requests to each edge node, which then processes requests based on local video data and returns only relevant results to the cloud center. This not only reduces network traffic but also helps ensure user privacy to some extent.
For instance, if a child goes missing in a city, the cloud center can offload the request to find the child to each edge node, which processes the request using local data and returns whether the child has been found. Compared to uploading all video to the cloud and having the cloud solve it, this method can resolve the issue much faster.
Smart Homes
The development of IoT has made electronic devices in ordinary homes more lively. Simply connecting these devices to the internet is not enough; we need to better utilize the data generated by these electronic components to serve the current household better. Considering network bandwidth and data privacy protection, we need this data to circulate locally and be processed directly on-site. We need a gateway as an edge node to consume the data generated in the household. Additionally, since data can come from various sources (computers, smartphones, sensors, and any smart devices), we need to customize a special OS to merge and unify these abstract data.
Smart Cities
The original design intention of edge computing is to bring data closer to the data source, so edge computing has the following advantages in smart cities:
Massive Data Processing: In a densely populated city, vast amounts of data are generated at all times. If all this data is processed by the cloud center, it will lead to significant network burden and resource wastage. If this data can be processed locally, within the local area network where the data source is located, the network load will be greatly reduced, and data processing capabilities will be further improved.
Low Latency: In large cities, many services require real-time characteristics, which necessitates the fastest possible response speed. For example, in medical and public safety fields, edge computing will reduce the time data spends in transit across the network, simplify the network structure, and enable edge nodes to handle data analysis, diagnosis, and decision-making, thus improving user experience.
Location Awareness: For location-based applications, edge computing outperforms cloud computing. For instance, in navigation, terminal devices can process relevant location information and data at edge nodes based on their real-time location, allowing edge nodes to make judgments and decisions based on existing data. The network overhead during the entire process is minimized, and user requests receive rapid responses.
Edge Collaboration
Due to data privacy issues and the cost of transmitting data over the network, some data cannot be processed by the cloud center. However, sometimes this data requires collaboration across multiple departments to maximize its utility. Therefore, we propose the concept of edge collaboration, utilizing multiple edge nodes to create a virtual shared view of data, using a predefined public service interface to integrate this data. Additionally, through this data interface, we can develop applications to provide users with more complex services.
For example, during a flu outbreak, hospitals as edge nodes can share data with pharmacies, pharmaceutical companies, governments, and insurance industries, sharing information such as the current number of infected individuals, flu symptoms, and treatment costs. Pharmacies can adjust their procurement plans based on this information to balance inventory; pharmaceutical companies can prioritize the production of critical medications based on shared data; the government can raise the flu alert level in affected areas and take further actions to control the spread of the outbreak; and insurance companies can adjust the pricing of relevant insurance based on the severity of the flu. In summary, every node in the edge collaboration benefits from this data sharing.
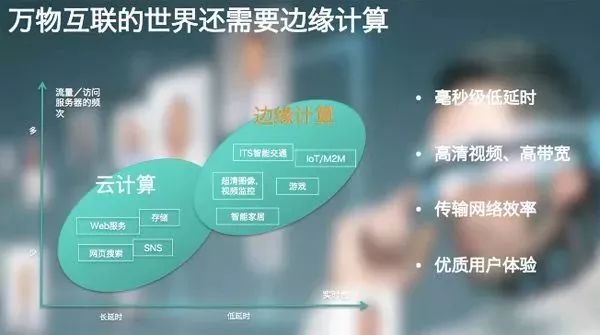
To give a somewhat unreasonable analogy, imagine that everyone had to go to the bank’s teller to deposit or withdraw money, causing long queues and traffic congestion, wasting time and energy. Now, with a self-service ATM at your doorstep, wouldn’t you no longer need to take a number and wait?
So, since edge computing is so powerful, why not just eliminate cloud computing? What’s its use?
Although more and more foundational tasks will be assigned to edge computing in the future, this only indicates that the devices at the edge will become more responsive, but it cannot be said that these tasks are entirely unrelated to the cloud; they exist to complement each other perfectly.

Edge computing and cloud computing work in synergy; they are mutually optimizing complements that jointly enable the digital transformation of industries. Cloud computing serves as a coordinator, responsible for big data analysis over long periods, and operates in areas such as periodic maintenance and business decision-making. Edge computing focuses on real-time, short-cycle data analysis, better supporting local business timely processing and execution. Edge computing is close to the device side and contributes to cloud data collection, supporting big data analysis for cloud applications. Cloud computing also outputs business rules based on big data analysis to the edge for execution and optimization.
To use another analogy, the headquarters is in Beijing, while branches are in Jiangsu, Guangdong, Shandong, etc. The actual work tasks in Jiangsu are executed by the supervisor of the Jiangsu branch, but the headquarters provides the overall work plan, coordinating the work planning for each region.
Therefore, whether it is cloud computing or edge computing, there is no situation where one completely replaces the other. Each excels in its own field, making the most of resources, using the most appropriate computation in the most suitable scenarios, or launching a two-pronged approach!
The so-called Internet of Everything extends along the time axis, with the largest network being the Internet of Things. Edge computing, therefore, involves computation, processing, optimization, and storage close to the edges of the IoT. With the development of the IoT, edge computing applications are also widespread, appearing in smart cities, smart homes, smart hospitals, online live streaming, smart parking, autonomous driving, drone applications, and smart manufacturing, among others. The moment when edge computing dominates the IoT is fast approaching.

Alibaba is always the number one active player, and Alibaba Cloud’s edge computing product Link Edge has been launched. It is said that with this product, developers can easily deploy Alibaba Cloud’s edge computing capabilities on various smart devices and computing nodes, such as in-vehicle central controls, industrial assembly line consoles, routers, etc. Additionally, the smart cloud lock based on biometric technology utilizes the local home gateway’s computing capabilities, achieving a no-delay experience, and can unlock even when the network is down, avoiding the embarrassment of being “locked out of your own home.” The collaborative computing of cloud and edge also enables scenario-based interactions; for instance, when you open the door, the living room lights automatically turn on to welcome you home.

Intel has already developed an early prototype of a software platform for managing environments in unmanned stores in the retail sector; in the industrial sector, Intel has preemptively created a more capable gateway platform that can be applied to more complex industrial automation scenarios in the future. It is evident that Intel is also striving to align with emerging technology trends such as IoT and edge computing.
Recently, Lenovo Group CEO Yang Yuanqing stated that they will fully embrace intelligence and focus on edge computing! What does the future hold with Lenovo in edge computing?
Of course, everything has its duality, and the development of edge computing also faces significant challenges.
Since cloud computing was proposed in 2005, it has gradually changed the way we live, learn, and work. Services provided by commonly used applications like Google and Facebook are typical representatives. Moreover, scalable infrastructure and processing engines supporting cloud services have also impacted our operational business models, such as Hadoop, Spark, etc.
The rapid development of IoT has ushered us into a post-cloud era, where a massive amount of data is generated in our daily lives. Cisco estimates that by 2019, nearly 50 billion things will be connected to the Internet. IoT applications may require extremely fast response times and data privacy. If we transmit the data generated by IoT to cloud computing centers, it will increase network load, potentially leading to congestion and certain data processing delays.
With the promotion of IoT and cloud services, we have hypothesized a new model for addressing issues: edge computing. Data is generated, processed, and analyzed at the edge of the network. The following articles will introduce why edge computing is necessary, relevant definitions, studies on cloud offloading and smart cities, and highlight programming, naming, data abstraction, service management, data privacy, and security under edge computing.
Opportunities and Challenges
The above outlines the potential and prospects of edge computing in addressing related issues, and the next section will analyze the opportunities and challenges that will arise during the implementation of edge computing.
Programming Feasibility
Programming on cloud computing platforms is very convenient because the cloud has specific compilation platforms, allowing most programs to run on the cloud. However, programming under edge computing faces a problem of platform heterogeneity; each network edge is different, potentially running on iOS, Android, or Linux, etc. Programming on different platforms varies significantly. Hence, we propose the concept of computational flow, which is a sequence of functions/computations along the data propagation path that can be specified by applications to determine where computations occur within the data propagation path. Computational flow can help users identify which functions/computations should be completed and how data propagates after computations occur at the edge.
Naming
Naming schemes are crucial for programming, addressing, object identification, and data communication. However, there is currently no effective data processing method in edge computing. Communication among objects in edge computing is diverse and can rely on Wi-Fi, Bluetooth, 2.4G, and other communication technologies. Therefore, relying solely on the TCP/IP protocol stack cannot satisfy the communication needs of these heterogeneous objects. The naming scheme in edge computing needs to address object mobility, dynamic network topologies, privacy and security protection, and scalability of objects. Traditional naming mechanisms like DNS (Domain Name System) and URI (Uniform Resource Identifier) do not effectively resolve the naming issues in dynamic edge networks. Currently proposed NDN (Named Data Networking) solutions for such problems also have certain limitations. In a relatively small network environment, we propose a solution as shown in Figure 3, where we describe an object’s time, location, and current tasks, creating a unified naming mechanism that simplifies management. Of course, as the environment scales to a city level, this naming mechanism may not be suitable and may require further discussion.
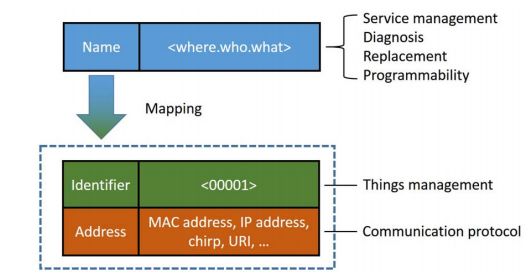
Figure 3 Naming Mechanism
Data Abstraction
In the IoT environment, a large amount of data is generated, and due to the heterogeneous nature of the IoT network, the generated data comes in various formats. Formatting diverse data types poses a challenge for edge computing. Additionally, most objects at the network edge only periodically collect data and send it to the gateway, where storage is limited and can only retain the latest data, leading to frequent data refreshes at edge nodes. Utilizing integrated data tables to store data of interest can be represented structurally as shown in Figure 4, using ID, time, name, data, etc.
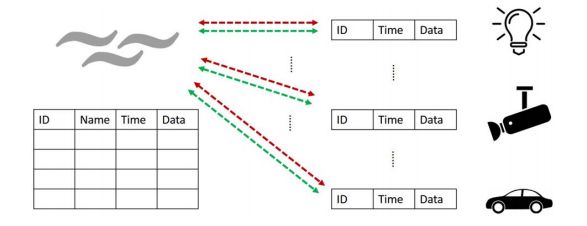
Figure 4 Corresponding Table Structure
If too much raw data is filtered out, it may lead to unreliable data reporting from edge nodes. Conversely, retaining excessive raw data creates new storage issues for edge nodes. Moreover, this data should be accessible for read and write operations by programs, but the heterogeneity of objects in the IoT complicates database read and write operations.
Service Management
We believe that service management at edge nodes should encompass the following four characteristics: differentiation, scalability, isolation, and reliability, to ensure an efficient and reliable system.
Differentiation: With the development of IoT, various services will emerge, and different services should have differentiated priorities. For example, critical services related to object determination and fault alerts should take precedence over other general services, while services concerning human health, such as heartbeat monitoring, should rank higher than entertainment-related services.
Scalability: The items in IoT are dynamic, and adding or removing an item from the IoT is not an easy task. Whether services can adapt to the addition or removal of a new node remains a challenge, which can be addressed through the highly scalable and flexible design of edge OS.
Isolation: Isolation means that different operations do not interfere with each other. For example, multiple applications can control the lighting in a home, and the data controlling the lights is shared. If one application fails to respond, other applications can still control the lights. In other words, these applications are independent of each other and do not affect one another; isolation also requires that user data and third-party applications be separated, meaning applications should not be able to track and record user data. To resolve this issue, a new method for application access to user data should be introduced.
Reliability: Reliability can be discussed from the perspectives of services, systems, and data.
From the service aspect, the loss of any node in the network topology may render services unavailable. If the edge system can detect high-risk nodes in advance, it can avoid such risks. A good implementation method is to use wireless sensor networks to monitor server clusters in real time.
From the system perspective, the edge operating system is a crucial component for maintaining the entire network topology. Nodes can communicate their status and diagnostic information with each other. This feature facilitates the deployment of fault detection, node replacement, and data verification at the system level.
From the data perspective, reliability refers to the dependability of data in sensing and communication. Nodes in the edge network may report information unreliably, for example, when sensors are low on power, which could lead to unreliable data transmission. To solve such issues, new protocols may need to be proposed to ensure reliability in data transmission within the IoT.
Optimization Indicators in Edge Computing
In edge computing, due to the numerous nodes and varying processing capabilities among them, selecting appropriate scheduling strategies among different nodes is crucial. The following discussion will focus on four optimization indicators: latency, bandwidth, energy consumption, and costs.
Latency: It is evident that cloud centers possess powerful processing capabilities, but network latency is not solely determined by processing power; it also depends on the time data spends in transit across the network. For example, in a smart city scenario, if information about a missing child is processed locally on a mobile phone and the result returned to the cloud, it can significantly speed up response time. However, this is relative, and we need to implement a logical judgment layer to determine which node is most suitable for processing the task. If the phone is busy playing games or handling other important tasks, it may not be ideal for processing this task, and it would be better to assign it to another layer.
Bandwidth: High bandwidth for data transmission means low latency, but high bandwidth also signifies significant resource wastage. Data processing at the edge can take two forms: data can be fully processed at the edge and then the results uploaded to the cloud, or data can be partially processed, with the remaining parts sent to the cloud for processing. Either of these methods can greatly improve the current state of network bandwidth, reduce data transmission across the network, and enhance user experience.
Energy Consumption: For a given task, it is essential to determine whether local computation saves resources or whether transmitting data to other nodes for processing is more resource-efficient. If the local node is idle, local computation is the most resource-saving option. If it is busy, assigning computational tasks to other nodes may be more suitable. Balancing the energy consumed during computation and the energy consumed during network transmission is very important. Generally, when the energy consumed for network transmission is significantly less than that consumed for local computation, we consider using edge computing to offload computational tasks to other idle nodes, helping to achieve load balancing and ensuring high performance for each node.
Costs: Current costs associated with edge computing include but are not limited to the construction and maintenance of edge nodes and the development of new models. By utilizing edge computing models, large service providers can achieve greater profits while handling the same workload.
Industry Leaders Are Busy:
Amazon AWS
At the 2016 re:Invent developer conference, Amazon launched AWS Greengrass, building on the company’s existing IoT and Lambda (serverless computing) products to extend AWS to intermittently connected edge devices.
“With AWS Greengrass, developers can directly add AWS Lambda functions to connected devices from the AWS management console, and devices can execute code locally, allowing them to respond to events and perform actions almost in real-time. AWS Greengrass also includes AWS IoT messaging and synchronization capabilities, enabling devices to send messages to other devices without connecting back to the cloud,” Amazon stated. “AWS Greengrass allows customers to flexibly let devices rely on the cloud when meaningful, perform tasks independently when meaningful, and communicate with each other when meaningful, all in a seamless environment.”
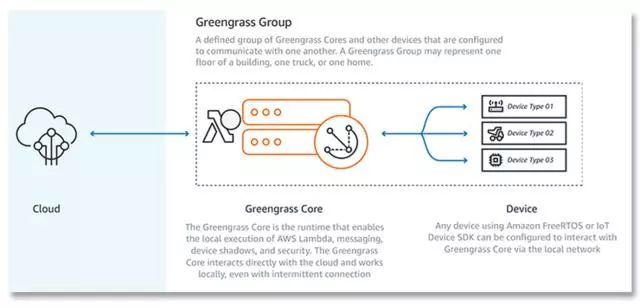
AWS-Greengrass
Of course, these are “smart” edge devices: Greengrass requires at least 1GHz of computing power (Arm or x86), 128MB of RAM, and additional resources for operating systems, message throughput, and AWS Lambda execution. According to Amazon, “Greengrass Core can run on various devices ranging from Raspberry Pi to server-grade equipment.”
Microsoft
Since June 2017, at Microsoft’s BUILD 2017 developer conference, Azure IoT Edge has been launched, allowing cloud workloads to be containerized and run locally on smart devices ranging from Raspberry Pi to industrial gateways.
Azure IoT Edge consists of three components: IoT Edge modules, IoT Edge runtime environment, and IoT Hub. IoT Edge modules are containers that run Azure services, third-party services, or custom code; they are deployed to IoT Edge devices and executed locally. The IoT Edge runtime environment runs on each IoT Edge device, managing the deployed modules, while the IoT Hub serves as the cloud-based interface for remote monitoring and management of IoT Edge devices.
Here’s how different Azure IoT Edge components work together:
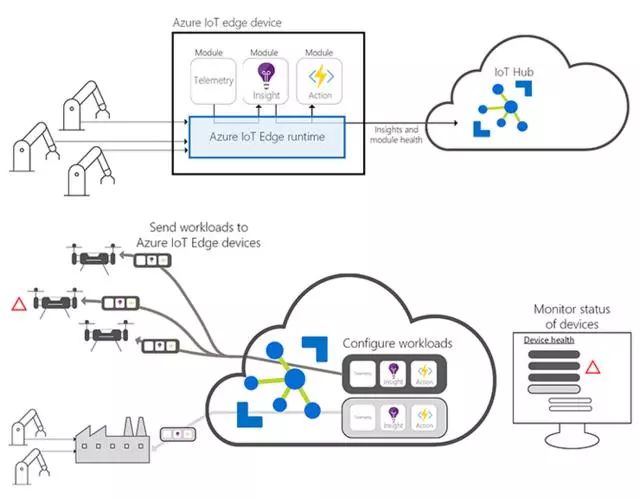
Azure-IOT-Edge
With its full launch, Microsoft has added new features to Azure IoT Edge, including: open-source support; backup configuration, security, and management services, and a simplified developer experience.
In July 2018, Google announced two products for large-scale development and deployment of smart connected devices: Edge TPU and Cloud IoT Edge. Edge TPU is a dedicated small ASIC chip designed to run TensorFlow Lite machine learning models on edge devices. Cloud IoT Edge is a software stack that extends Google’s cloud services to IoT gateways and edge devices.
Cloud IoT Edge has three main components: a runtime for gateway-level devices (with at least one CPU) for storage, transformation, processing, and extracting intelligence from edge data while interoperating with Google’s other cloud IoT platforms; Edge IoT Core runtime, which securely connects edge devices to the cloud; and Edge ML runtime, based on TensorFlow Lite, which performs machine learning inference using pre-trained models.
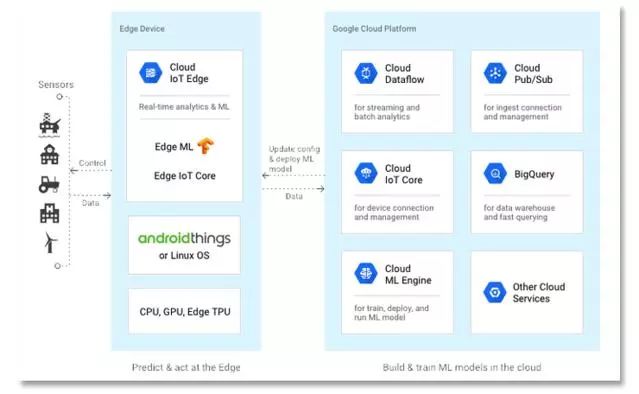
Google Cloud-IOT-Edge.
Both Edge TPU and Cloud IoT Edge are currently in alpha testing.
Conclusion
The development of IoT and the promotion of cloud computing have led to the emergence of edge computing models within the community. Processing data at edge nodes can improve response speed, reduce bandwidth, and ensure the privacy of user data. In this article, we have proposed potential applications of edge computing in future scenarios and discussed its prospects and challenges. We hope more colleagues will pay attention to this field in the future.
Related Reading:
AI + IoT (Artificial Intelligence + Internet of Things), what logic lies behind?
Google releases AI terminal chips; have domestic AI chip companies been left out?
The acceleration principle of AI chips
———————
Note: Adapted from Professor Shi Weisong’s paper “Edge Computing: Vision and Challenges”
Translator: CSDN Escape from Earth’s Little Daze