Table of Contents | Issue 3, 2025 Special Topic: Wireless Computing Network Architecture and Key TechnologiesWireless Computing Network: Architecture and Key TechnologiesExploration of Integrated Wireless Computing Network DesignArchitecture and Key Technologies of Intelligent Wireless Computing Network Integration and Control SystemResearch and Prospects of Deterministic Technologies in Wireless Computing NetworksDistributed Communication and Computing Collaboration for AI Tasks in Wireless Computing NetworksCloud-Edge-Terminal Network Collaboration Empowering Resource Adaptation Technologies under Wireless ComputingResearch on Resource Allocation Mechanisms in Industrial Internet Based on Integrated Computing and SensingResearch on Low Latency and Low Power Drone Task Offloading and Trajectory Optimization Strategies Special Topic-9 [Wireless Computing Network Architecture and Key Technologies]
Design of a Multimodal Collaborative Inference System for Edge Computing
LI Wentao, WANG Xijun, CHEN Li
(School of Electronics and Information Engineering, Sun Yat-sen University, Guangzhou, Guangdong 510006, China)
AbstractEdge computing, as an emerging computing paradigm, offers advantages such as low latency, high reliability, and privacy protection by deploying computing resources and services close to data sources or users. However, it also faces challenges due to limited resources. To address the resource constraints of edge computing devices, a multimodal foundational model collaborative inference framework is proposed to enhance the performance and efficiency of intelligent voice interaction systems. By transferring the speech synthesis model from the terminal to the edge for inference and facilitating communication between the terminal and edge, collaborative inference is achieved. Experimental results demonstrate that this method significantly reduces system interaction latency and memory usage while ensuring model inference accuracy, providing new ideas and technical solutions for multimodal applications in edge computing environments.
KeywordsEdge Computing; Collaborative Inference; Multimodal Inference; Voice Cloning
doi:10.3969/j.issn.1006-1010.20250114-0005
Classification Number: TN929.5 Document Code: A
Article Number: 1006-1010(2025)03-0072-06
Citation Format: LI Wentao, WANG Xijun, CHEN Li. Design of a Multimodal Collaborative Inference System for Edge Computing[J]. Mobile Communications, 2025,49(3): 72-77.
LI Wentao, WANG Xijun, CHEN Li. Design of a Multimodal Collaborative Inference System for Edge Computing[J]. Mobile Communications, 2025,49(3): 72-77.

1 Introduction
In recent years, with the rapid development of artificial intelligence (AI) technologies and the widespread adoption of Internet of Things (IoT) devices, edge computing has gradually become an indispensable computing paradigm in intelligent systems. Compared to traditional cloud computing models, edge computing offers advantages such as low latency, high privacy protection, and strong real-time capabilities, making it promising for applications in intelligent voice interaction, autonomous driving, and intelligent monitoring.[1] However, edge computing devices (such as Jetson Orin Nano and other embedded development platforms) often face challenges due to limited resources, such as restricted computing power, memory capacity, and power consumption. These resource constraints make it exceptionally difficult to run complex deep learning models (especially multimodal models) on edge devices, affecting system performance and user experience.
Multimodal large models have become a core direction in modern AI research, capable of combining data from different modalities (such as text, images, etc.) for joint processing, playing a significant role in human-computer interaction. For instance, an intelligent voice interaction system typically consists of an Automatic Speech Recognition (ASR) model, a multimodal large model, and a Text-to-Speech (TTS) model, all of which require deep neural networks for efficient inference. However, running a complete multimodal system on edge devices presents two main issues: first, the large model size leads to excessive memory usage, severely limiting the system’s concurrency capabilities; second, the slow inference speed fails to meet real-time interaction demands. This resource bottleneck is particularly pronounced in edge computing scenarios, necessitating the search for effective solutions.
Currently, common methods to address this issue include transferring model inference tasks entirely to the cloud or optimizing the computational burden on edge devices through model compression and pruning techniques. However, relying entirely on cloud inference, while leveraging powerful computing capabilities, introduces problems such as increased data transmission latency, insufficient bandwidth, high energy consumption, and maintenance costs, along with significant privacy and security risks.[2-5] On the other hand, while model compression and pruning can reduce model complexity, they inevitably result in some loss of inference accuracy, making it difficult to meet the demands of high-quality interaction systems. Therefore, how to efficiently deploy multimodal foundational models in edge computing scenarios while balancing inference accuracy, real-time performance, and resource utilization has become a key research issue.
To address these challenges, researchers have proposed various collaborative inference techniques aimed at optimizing the model inference process through collaboration between terminals and edge devices or the cloud. For example, the Galaxy system achieves efficient inference of Transformer large language models through distributed collaboration among multiple edge devices; compared to baseline methods, latency is reduced by up to 46%, significantly lowering delay and resource consumption.[6] However, existing research primarily focuses on optimizing single-modal large models, and collaborative inference techniques for multimodal foundational models are still in the early exploratory stages. Particularly in resource-constrained edge computing scenarios, how to achieve efficient collaboration and resource optimization among the various modules of multimodal models remains under-researched.
In this context, this paper proposes a multimodal foundational model collaborative inference system designed for resource-constrained edge computing environments. Unlike existing research that focuses on optimizing single-modal models or theoretical discussions, the innovation of this study lies in constructing a systematic multimodal collaborative inference framework. This framework aims to resolve the conflict between resource constraints and performance demands faced by multimodal foundational model deployment in edge computing scenarios. This paper conducts an in-depth analysis of the characteristics of multimodal intelligent voice interaction systems and uses this as a case study to propose a task allocation strategy based on functional module decoupling. This strategy offloads the TTS module, which has relatively independent computational loads but is sensitive to terminal resources, to the edge side and designs a terminal-edge collaborative mechanism based on lightweight TCP (Transmission Control Protocol) port communication, achieving collaborative utilization of terminal and edge computing resources. Experimental results validate the effectiveness of this method, indicating that while ensuring multimodal model inference accuracy, it can significantly reduce the computational load and memory usage of terminal devices, enhancing the real-time interaction performance of multimodal applications on the edge side. The collaborative inference method proposed in this paper has a certain degree of universality and scalability, and its core ideas and technical solutions provide a systematic approach to optimizing complex multimodal systems in resource-constrained edge computing environments. This method is expected to be applied in various edge computing scenarios, including autonomous driving, intelligent monitoring, industrial quality inspection, and XR intelligent terminals, providing references for the design and deployment of future edge intelligent systems.
1 Collaborative Inference Framework
This paper designs a collaborative inference system architecture to optimize the performance of intelligent voice interaction systems, especially in scenarios with limited resources on edge devices. In this architecture, collaborative inference is employed, deploying the TTS module on the edge side for inference while the ASR module and multimodal large language model run on the terminal. The entire system establishes a TCP communication connection between the edge side and the terminal through a Wi-Fi network, enabling real-time data transmission between different devices. When a user inputs voice through the system, the ASR module first performs speech recognition on the terminal, converting the speech signal into text and passing the text result to the multimodal large language model. The multimodal large language model receives the text and combines it with extracted video frames for inference, sending the inference results via TCP protocol to the TTS module on the edge side to perform the inference task, converting the text into high-quality audio data output. The generated audio data stream is then sent back to the terminal through the same communication channel and played by the terminal, thus completing the voice interaction loop of the system.Figure 1 illustrates the collaborative inference architecture designed in this paper.
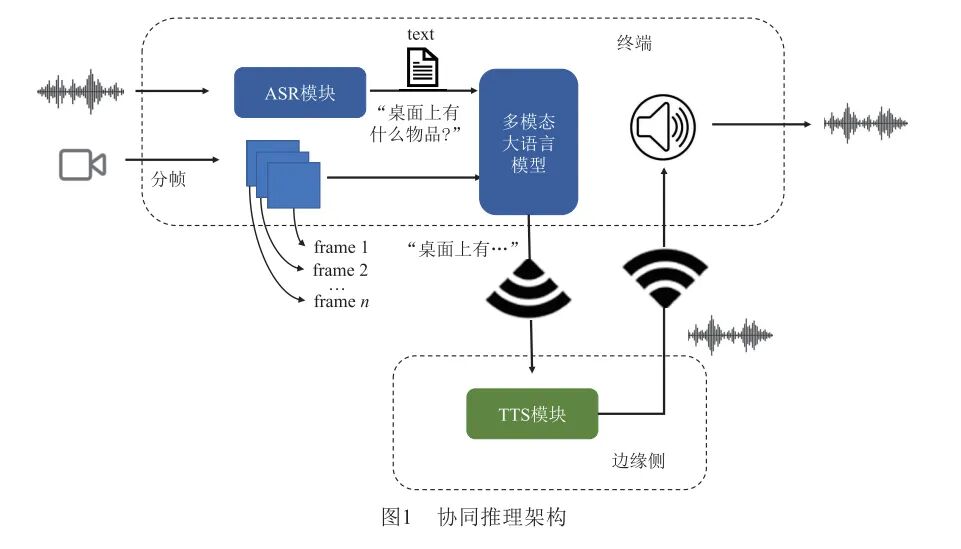
1.1 ASR Module
The ASR module is one of the core components of the intelligent voice interaction system, primarily responsible for converting user voice input into text information that the system can process, providing foundational data support for subsequent multimodal inference and speech synthesis. The performance of the ASR module directly affects the system’s ability to understand voice commands and its response speed. The ASR module needs to extract features from continuous speech signals, combining language models and acoustic models to accurately predict the sequence of words in the speech signal, thus generating semantically clear text results that conform to context.
The working principle of ASR can be divided into three main stages: speech signal preprocessing, feature extraction and decoding, and language model post-processing. First, the speech signal preprocessing stage mainly involves framing and windowing the continuous speech signal input by the user, dividing the long speech signal into short time segments (usually 20-30 ms) to capture the dynamic changes in speech characteristics. In the feature extraction stage, the framed signals undergo further processing to obtain spectrograms or other forms suitable for machine learning model input, such as the commonly used Mel Frequency Cepstral Coefficients (MFCC) or feature representations obtained from a trained neural network.[7] The aim of these feature extractions is to maximize the retention of semantic information in the speech while eliminating noise or irrelevant information.
In the feature decoding stage, ASR maps the speech features to basic speech units (such as phonemes or syllables) using acoustic models. Modern ASR systems typically employ deep learning techniques, particularly acoustic models based on Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), or Transformer architectures.[8-10] These models can effectively learn the complex mapping relationships between speech signals and semantics. For example, RNNs are suitable for handling dynamic characteristics in sequential data, while Transformer models can more efficiently capture long-term contextual information. Additionally, during the decoding process, language models are often combined to predict the most likely sequences of words, generating outputs that are more semantically logical.
Finally, in the language model post-processing stage, the ASR module combines the preliminary speech-to-text results with the language model to further optimize the semantic coherence of the text. The language model learns the probability distributions in language structures through statistical or neural network methods, helping the ASR module correct semantic deviations caused by ambiguous acoustic features or recognition errors. For instance, the language model can provide accurate contextual information support for distinguishing homophones or correcting grammatical errors in context.
1.2 Multimodal Large Language Model
Multimodal Large Language Models (MM-LLMs) are AI models capable of simultaneously processing and generating various modalities of data (such as text, images, speech, video, etc.). Unlike traditional single-modal models, multimodal models can integrate information from different modalities, achieving better performance on complex tasks through joint learning and shared representations. This model leverages the complementarity between modalities, allowing them to approach human-like multisensory interactions when understanding the world.
The core idea of multimodal large models lies in jointly modeling data from different modalities, primarily relying on deep learning techniques. Among them, the Transformer is currently one of the most commonly used frameworks, as it can effectively handle sequential data and long-distance dependencies. The model typically includes multiple modality-specific encoders, such as text encoders (like BERT[11]) and visual encoders (like ViT[12]), which map multimodal features to a shared semantic space through fusion modules, thereby achieving alignment and interaction between modalities.
Current multimodal large language models adopt a parallel framework[13]. For example, in LLAVA[14], multimodal data is sent to their respective modality encoders to obtain modality-specific encodings, which are then aligned to the text encoding of the large language model through their respective modality input projectors, and processed by the large language model to produce text outputs.
Multimodal large models have wide applications in many fields. For instance, text-to-image generation (such as OpenAI’s DALL·E[15]) can generate highly realistic images based on natural language descriptions; cross-modal retrieval (such as CLIP[16]) enables mutual searching between text and images; in video analysis, these models are used for tasks such as subtitle generation and event detection; in the medical field, multimodal models combining medical images and reports are used for assisting diagnosis. Additionally, these models have been successfully applied in entertainment, education, and intelligent assistant scenarios, where intelligent robots can understand user images and voice inputs and provide natural multimodal feedback.
1.3 TTS Module
TTS, or Text-to-Speech, is a technology that converts text information into speech signals. This technology enables computers to mimic human speech processes, outputting text in the form of speech. The basic framework of TTS models typically consists of two main modules: text analysis, feature generation, and speech generation. The primary task of the text analysis module is to convert raw written text into input representations suitable for generating speech. This process includes language normalization of the text (such as converting numbers and symbols into readable words), lexical analysis, syntactic analysis, and phonetic representation generation. The core goal of these steps is to map the input text to a sequence representation of speech features, such as phoneme sequences.
The feature generation stage transforms the results of text analysis into the features required for speech. Most modern TTS systems generate audio features such as Mel spectrograms, which contain frequency information of speech and serve as the basis for synthesizing speech. Additionally, many TTS models also generate phoneme-level features that determine the content and prosodic variations of speech, further enhancing the naturalness and accuracy of the synthesized speech.
Speech generation is the core task of TTS, converting features into actual speech waveforms. Traditional speech generation methods include concatenative synthesis and parametric synthesis, where concatenative synthesis generates speech by concatenating pre-recorded speech segments, while parametric synthesis generates speech by synthesizing parameters such as frequency and amplitude. However, these methods have limited flexibility and naturalness. Modern deep learning methods, especially neural network-based models like WaveNet[17] and Tacotron[18], have become mainstream in the TTS field. For instance, Tacotron first converts text input into Mel spectrograms and then uses vocoders (such as WaveNet or HiFi-GAN[19]) to convert the spectrograms into speech signals.
With continuous technological advancements, the main challenges faced by TTS models include how to express emotional and prosodic variations during speech generation, how to adapt to different speakers and language characteristics, and how to improve generation efficiency while ensuring high-quality speech. Modern TTS systems are increasingly focusing on capabilities in multilingual, cross-domain, and zero-shot learning, enabling training without large amounts of labeled data and generating natural, fluent speech in different contexts.
2 Collaborative Inference Demonstration System
2.1 Hardware Configuration
The hardware configuration of the system is shown in Figure 2. To deploy a complete intelligent voice interaction system on the terminal side and achieve low-latency inference, this paper selects the NVIDIA Jetson Orin Nano (8 GB version) as the terminal device, while a personal computer (PC) equipped with an RTX 3050 Ti graphics card (4 GB memory) serves as the collaborative computing platform on the edge side. The Jetson Orin Nano is a low-power device designed for edge computing, featuring a 1024-core NVIDIA Ampere architecture GPU with 32 Tensor Cores, 8 GB of built-in memory, and a computing power of 40 TOPS, capable of supporting deep learning inference tasks under limited hardware resources and further enhancing operational efficiency through optimization frameworks like NVIDIA TensorRT. The RTX 3050 Ti graphics card on the PC side has 2560 CUDA cores and 16.3 TFLOPS of floating-point computing performance, providing support for resource-intensive voice cloning tasks and further reducing collaborative inference latency.

The system’s audio input is captured through a USB microphone camera that supports 720p resolution and a frame rate of 25fps, equipped with a noise-canceling microphone to effectively reduce environmental noise interference with voice input, ensuring clarity of the input voice and providing high-quality audio data support for the ASR module. Meanwhile, the system’s output is played through an external USB sound card, fulfilling the complete loop requirement for voice interaction.
2.2 Model Selection
The model selection for the three modules in the system is listed in Table 1. To meet the characteristics of limited hardware resources in edge computing environments while balancing model inference accuracy and efficiency, the SenseVoice-Small model is chosen for the ASR module. It adopts a non-autoregressive end-to-end framework, achieving a word error rate (WER) of 10.78% on the CommonVoice_zh-CN dataset, outperforming Whisper-Large-V3’s 12.55%. Additionally, this model has extremely low inference latency, being 7 times faster than the Whisper-Small model and 17 times faster than the Whisper-Large model with a comparable number of parameters.[20] To further reduce memory usage and inference time, this paper employs the 8-bit quantized version of SenseVoice-Small, which is more suitable for inference on edge computing devices like the Jetson Orin Nano.
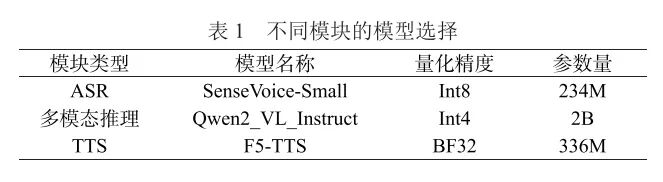
For the multimodal model part, the Qwen2-VL-2B-Instruct model is selected, which has the capability to handle multimodal tasks (such as text and image combined inference). The original model is large, but through Generalized Post-Training Quantization (GPTQ), it is quantized to an Int4 version, significantly compressing model parameters and reducing memory usage, allowing it to run smoothly on the 8 GB memory of the Jetson Orin Nano. Moreover, the quantized model shows a significant improvement in inference speed, with reduced inference latency, ensuring the feasibility of multimodal interaction on edge devices. Despite the quantization, it still performs excellently in terms of accuracy, achieving 87.21% accuracy on the DocVQA_VAL (Document Visual Question Answering Validation) dataset and 70.87% accuracy on the MMBench_DEV_EN (Multimodal Benchmark Development in English) dataset, essentially meeting the accuracy requirements for inference results in intelligent voice interaction systems.[21]
The speech synthesis module uses the F5-TTS model, which supports multilingual synthesis, including Chinese and English, based on a flow-matching non-autoregressive generation method combined with Diffusion Transformer (DiT) technology, enabling rapid generation of natural, fluent, and highly similar speech based on zero-shot learning without additional supervision, achieving a WER of only 1.56% on the Seed-TTS test-zh dataset.[22] At the same time, it has a low inference memory usage of only 1.5 GB, allowing for the generation of highly similar cloned audio with minimal memory usage, making it suitable for deployment on the terminal side.
3 Experimental Analysis
3.1 Experimental Setup
This paper designs a complete set of comparative experiments to verify the effectiveness of the collaborative inference architecture in optimizing the performance of intelligent voice interaction systems. Specifically, two system architectures are tested: one where the ASR module, multimodal reasoning module, and TTS module all run on the terminal in a local inference architecture, as shown in Figure 3; the other retains the ASR and multimodal reasoning modules on the terminal while transferring the TTS module to run on the edge side in a collaborative inference architecture. Under these two architectures, systematic tests and comparisons of the system’s memory usage and response time are conducted.

In the TTS inference part, it can be observed that when the multimodal model’s response results are too long, the inference latency of the TTS module significantly increases, affecting the user interaction experience. To avoid long waiting times caused by playing the entire paragraph after generation, this paper adopts a segmentation processing strategy, dividing the input text into multiple short segments and inputting them into the TTS model for inference segment by segment. With this strategy, the system can play the previous segment of audio while generating the next segment, achieving a streaming generation and playback effect. However, during the actual testing of this strategy, it was found that overly small segmentation lengths would cause pauses between the playback of adjacent audio segments, greatly affecting user experience. Therefore, it is necessary to reasonably control the text segmentation length so that the time required to generate the next segment of audio is strictly less than the playback time of the previous segment. To determine an appropriate segmentation length, the TTS module’s generation time was tested at different segmentation lengths on both the PC and Jetson Orin Nano development board. During the experiment, the text was divided into multiple segments of different lengths based on the number of characters, and the TTS inference time for each segment was recorded to obtain the minimum segmentation length that allows for streaming generation on different hardware devices. Additionally, when testing the TTS module, the F5-TTS model would uniformly read Arabic numerals in English, which does not meet the default requirements of the Chinese application scenario. To address this issue, text normalization techniques were employed. In text normalization, different regular expressions were used to extract Arabic numerals in various scenarios, such as dates, phone numbers, percentages, etc., and replace them with corresponding Chinese expressions, enabling the interaction system to generate speech that conforms to the usage scenario.
After completing the segmentation strategy tests, comprehensive performance comparison tests were further conducted under the two system architectures, recording memory usage and response latency for different system architectures. In the experiments testing response latency, the input text for the F5-TTS model was segmented according to the minimum segmentation length that can achieve streaming generation on different devices, using multiple sets of different user input texts to simulate the task processing flow in actual voice interaction scenarios, while recording the time from receiving user input to playing the first segment of audio as response latency.
3.2 Experimental Results and Analysis
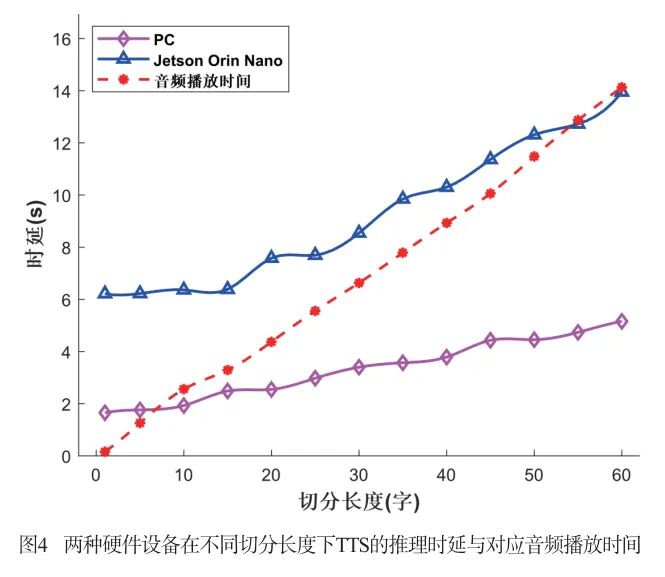
Figure 4 shows the inference latency of the F5-TTS model at different segmentation lengths on the two hardware devices, as well as the audio playback time corresponding to different segmentation lengths. The experimental results indicate a clear positive correlation between segmentation length and TTS inference latency, meaning that as the segmentation length increases, the time required for inference also increases. However, due to differences in hardware performance, the inference latency of the PC and Jetson Orin Nano exhibits significant differences at the same segmentation length. The latency curve of the PC is significantly lower than that of the Jetson Orin Nano, and the growth rate is relatively gentle. In contrast, the performance limitations of the Jetson Orin Nano are particularly evident. Not only is the inference time of the Jetson Orin Nano much higher than that of the PC at all segmentation lengths, but the increase in inference latency becomes steeper as the segmentation length increases. This indicates that the PC has stronger computing performance than the Jetson Orin Nano, capable of completing TTS inference tasks in a shorter time.
From the intersection point of the curves in the figure, it can be seen that the minimum segmentation length for streaming generation on the PC is 7, indicating that even with shorter segmentation lengths, the inference time of the PC can meet the requirements for streaming generation. In contrast, the minimum segmentation length for streaming generation on the Jetson Orin Nano is 54, meaning that only with larger segmentation lengths can its inference time be lower than the playback time of the previous audio segment, thus achieving seamless streaming generation, but this increases the overall response time of the system.
At the minimum segmentation length, tests were conducted on memory usage and system inference latency for the two different architectures, as shown in Table 2. Table 2 reflects that when only loading the model without inference, the memory usage of the two architectures is comparable; however, during inference, the memory usage of the Jetson Orin Nano is higher when inferring alone. The reason for this difference is that in the standalone inference architecture, the TTS module’s inference task requires a longer minimum segmentation length (54), directly leading to higher memory overhead.

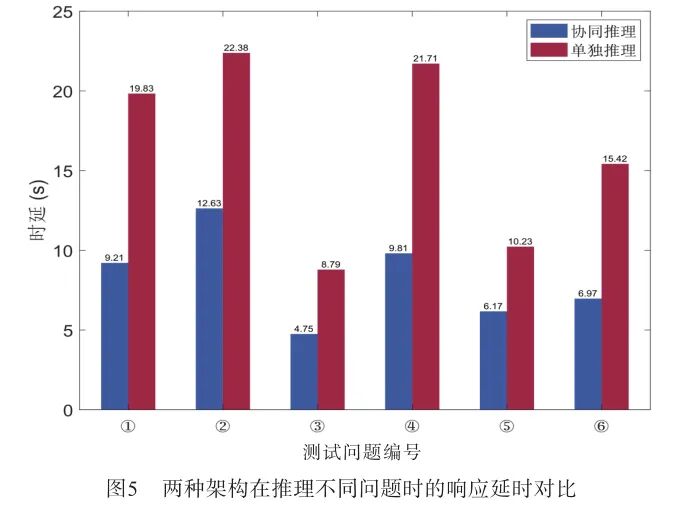
For convenience in recording, different questions used to test architecture performance were numbered, see Table 3.Figure 5 shows the response latency of the two different architectures when inferring different questions. From the bar chart, it is clear that the response latency of the collaborative inference architecture is significantly lower than that of the standalone inference architecture during the inference process of different questions. Regardless of the complexity of the questions, the response time of the collaborative inference remains at a low level, while the response time of the standalone inference architecture is significantly higher, and the gap widens as the complexity of the questions increases. This fully demonstrates the advantage of the collaborative inference architecture in reducing latency. Specifically, for the question “Why is the sky blue?”, the response time for collaborative inference is 9.21 seconds, while for standalone inference, it is 19.83 seconds, indicating that collaborative inference reduces latency by more than half. Similarly, for the question “Please describe the environment you see”, collaborative inference takes 12.63 seconds, while standalone inference takes as long as 22.38 seconds, further widening the gap. These questions are relatively complex, requiring comprehensive processing of multimodal inference and speech generation. The high latency of the standalone inference architecture indicates that the hardware resources of the Jetson Orin Nano are nearing their limits, while the collaborative inference architecture significantly alleviates the computational burden of inference tasks by offloading the TTS task to the PC side, enhancing overall response speed.

In summary, the collaborative inference architecture effectively alleviates the resource pressure on edge devices by offloading the computationally intensive TTS task from the Jetson Orin Nano to the PC side, demonstrating significant advantages in response latency without a noticeable increase in memory usage. Experimental results prove that the collaborative inference architecture significantly enhances the overall efficiency and user experience of the system, providing an effective solution for intelligent voice interaction systems in edge computing environments.
4 Conclusion
This paper proposes an optimization method for intelligent voice interaction systems based on collaborative inference, significantly reducing system response latency by migrating the TTS module from the Jetson Orin Nano development board to the PC side without increasing memory usage. Experimental results indicate that the collaborative inference architecture balances memory usage more evenly while effectively alleviating the resource bottlenecks of edge devices, achieving significant reductions in latency for complex tasks and maximizing the system’s real-time performance and interaction experience.
References:(Scroll to browse)
[1] Shi W, Cao J, Zhang Q, et al. Edge Computing: Vision and Challenges[J]. IEEE Internet of Things Journal, 2016,3: 637-646.
[2] Jin H, Jia L, Zhou Z. Boosting Edge Intelligence with Collaborative Cross-Edge Analytics[J]. IEEE Internet of Things Journal, 2020,8: 2444-2458.
[3] Xiao Y, Jia Y, Liu C, et al. Edge Computing Security: State of the Art and Challenges[J]. Proceedings of the IEEE, 2019,107: 1608-1631.
[4] Wang Y, Yang C, Lan S, et al. End-Edge-Cloud Collaborative Computing for Deep Learning: A Comprehensive Survey[J]. IEEE Communications Surveys & Tutorials, 2024,26: 2647-2683.
[5] Jiang X, Shokri-Ghadikolaei H, Fodor G, et al. Low-latency Networking: Where Latency Lurks and How to Tame It[J]. Proceedings of the IEEE, 2018,107: 280-306.
[6] Ye S, Du J, Zeng L, et al. Galaxy: A Resource-Efficient Collaborative Edge AI System for In-situ Transformer Inference[C]//IEEE Infocom 2024-IEEE Conference on Computer Communications. IEEE, 2024.
[7] Hinton G, Deng L, Yu D, et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: the Shared Views of Four Research Groups[J]. IEEE Signal Processing Magazine, 2012,29.
[8] Graves A, Mohamed A, Hinton G. Speech Recognition with Deep Recurrent Neural Networks[C]//2013 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2013.
[9] Dong L, Xu S, Xu B. Speech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition[C]//IEEE International Conference on Acoustics, Speech, and Signal Processing. IEEE, 2018: 5884-5888.
[10] Zhang Y, Chan W, Jaitly N. Very Deep Convolutional Networks for End-to-end Speech Recognition[C]//2017 IEEE International Conference on Acoustics, Speech And Signal Processing (ICASSP). IEEE, 2017.
[11] Devlin J, Chang M, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2019 Conference of The North American Chapter of The Association for Computational Linguistics: Human Language Technologies (NAACL HLT 2019). 2019.
[12] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale[J]. International Conference on Learning Representations, 2021.
[13] Zhang D, Yu Y, Dong J, et al. MM-LLMs: Recent Advances in MultiModal Large Language Models[J]. CoRR, 2024.
[14] Liu H, Li C, Wu Q, et al. Visual Instruction Tuning[J]. Advances In Neural Information Processing Systems 36 (NEURIPS 2023), 2023.
[15] Ramesh A, Pavlov M, Goh G, et al. Zero-Shot Text-to-Image Generation[J]. International Conference on Machine Learning, 2021: 8821-8831.
[16] Radford A, Kim J W, Hallacy C, et al. Learning Transferable Visual Models From Natural Language Supervision[J]. International Conference On Machine Learning, 2021,139: 8748-8763.
[17] van den Oord A R, Dieleman S, Zen H, et al. WaveNet: A Generative Model for Raw Audio[J]. SSW, 2016.
[18] Shen J, Pang R, Weiss R J, et al. Natural TTS Synthesis by Conditioning Wavenet on MEL Spectrogram Predictions[C]//2018 IEEE International Conference On Acoustics, Speech And Signal Processing(ICASSP). IEEE, 2018: 4779-4783.
[19] Kong J, Kim J, Bae J. HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis[C]//Advances In Neural Information Processing Systems 33, NEURIPS 2020. 2020: 33.
[20] An K, Chen Q, Deng C, et al. FunAudioLLM: Voice Understanding and Generation Foundation Models for Natural Interaction Between Humans and LLMs[J]. CoRR, 2024.
[21] Wang P, Bai S, Tan S, et al. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution[J]. CoRR, 2024.
[22] Chen Y, Niu Z, Ma Z, et al. F5-TTS: A Fairytaler That Fakes Fluent and Faithful Speech with Flow Matching[J]. CoRR, 2024. ★
Scan the QR code to read and download this paper 
★Original article published in Mobile Communications, Issue 3, 2025★
doi:10.3969/j.issn.1006-1010.20250114-0005
Classification Number: TN929.5 Document Code: A
Article Number: 1006-1010(2025)03-0072-06
Citation Format: LI Wentao, WANG Xijun, CHEN Li. Design of a Multimodal Collaborative Inference System for Edge Computing[J]. Mobile Communications, 2025,49(3): 72-77.
LI Wentao, WANG Xijun, CHEN Li. Design of a Multimodal Collaborative Inference System for Edge Computing[J]. Mobile Communications, 2025,49(3): 72-77.
Author InformationWANG Xijun:Associate Professor, PhD Supervisor, currently working at Sun Yat-sen University, engaged in research on edge intelligence theory and technology.
CHEN Li:Professor, PhD Supervisor, currently working at Sun Yat-sen University, engaged in research on error correction coding technology and its applications in digital communication systems.
LI Wentao:Undergraduate student at the School of Electronics and Information Engineering, Sun Yat-sen University, engaged in research on edge intelligence theory and technology.
Mobile CommunicationsSubmission Website:https://ydtx.cbpt.cnki.net★Previous Recommendations★

Table of Contents | Issue 3, 2025 Special Topic: Wireless Computing Network Architecture and Key Technologies
Table of Contents | Issue 4, 2025 Special Topic: Reconfigurable and Mobile New Antenna Technologies for 6G
Summary | 2025 Second Half Year Special Call for Papers Link
 #Scan to Follow Us#Mobile CommunicationsInterpreting Communication with Papers
#Scan to Follow Us#Mobile CommunicationsInterpreting Communication with Papers
The Mobile Communications magazine is supervised by China Electronics Technology Group Corporation and hosted by the Seventh Research Institute of China Electronics Technology Group Corporation. It is a “dual-effect journal” in the Chinese journal matrix, a high-quality electronic journal of the Ministry of Industry and Information Technology, a source journal for Chinese scientific and technological papers, and included in the high-quality scientific journal grading directory of the Information and Communication Society of China and the Electronic Society of China. Domestic continuous publication number: CN44-1301/TN, International continuous publication number: ISSN1006-1010, Postal distribution code: 46-181.
