DeepSeek is here!
Recently, the rising star in the AI field, DeepSeek (Chinese name: 深度求索), has quickly gained popularity online due to its low-cost and high-performance AI model. Its core is a powerful language model capable of understanding natural language and generating high-quality text. Additionally, DeepSeek is freely available to developers worldwide, accelerating the spread of AI technology.

Performance Advantages of RK3588
The RK3588, as a high-performance AI chip, is manufactured using an 8nm LP process and features an octa-core processor, a quad-core GPU, and an NPU with 6 TOPS of computing power. Its strong performance and low power consumption characteristics make it very suitable for edge computing scenarios. >>>>【New Product Release】The RK3588 AI Mainboard from Xunwei

Can DeepSeek be Deployed on RK3588?
There are two methods to deploy DeepSeek on RK3588: using the Ollama tool and using Rockchip’s official RKLLM quantization deployment. Below, we will introduce these two deployment methods.
01- Deploying with the Ollama Tool
Ollama is an open-source large model service tool that supports the latest DeepSeek model, as well as Llama 3, Phi 3, Mistral, Gemma, and various other models. After installing the Ollama tool, you can deploy the 1.5 billion parameter DeepSeek-r1 model with the following command, as shown in the figure below:
ollama run deepseek-r1:1.5b
Next, you can start asking questions to the model, as shown in the figure below:
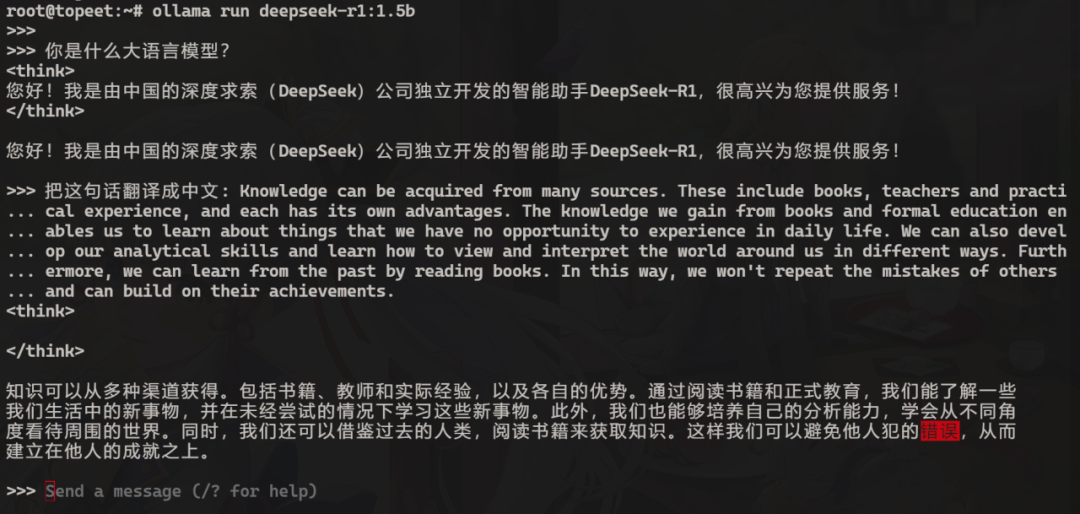 This is just running the1.5billion parameter model, so the responses may not be very accurate. If you want higher accuracy, you can switch to a model with larger parameters, but as the parameters increase, the response speed will also slow down. Additionally, the inference model deployed using the Ollama tool utilizes the CPU for computation, as shown in the figure below:
This is just running the1.5billion parameter model, so the responses may not be very accurate. If you want higher accuracy, you can switch to a model with larger parameters, but as the parameters increase, the response speed will also slow down. Additionally, the inference model deployed using the Ollama tool utilizes the CPU for computation, as shown in the figure below:
 As you can see, during the response process, the CPU load reached 100%, and the NPU was not utilized for acceleration. So how can we leverage the powerful NPU of the RK3588? This leads us to the second method using Rockchip’s RKLLM for quantization deployment.
As you can see, during the response process, the CPU load reached 100%, and the NPU was not utilized for acceleration. So how can we leverage the powerful NPU of the RK3588? This leads us to the second method using Rockchip’s RKLLM for quantization deployment.
02- Using RKLLM for Quantization Deployment
RKLLM-Toolkit is a development suite that provides users with the ability to perform quantization and conversion of large language models on their computers. Through the Python interface provided by this tool, the following functions can be easily accomplished:
1. Model Conversion: Supports the conversion of large language models in certain formats to RKLLM models, which can be loaded and used on the Rockchip NPU platform.2. Quantization Function: Supports the quantization of floating-point models to fixed-point models.
The RKLLM model converted from DeepSeek is shown in the figure below:

Then transfer it to the development board and run it using the corresponding executable file, as shown in the figure below:
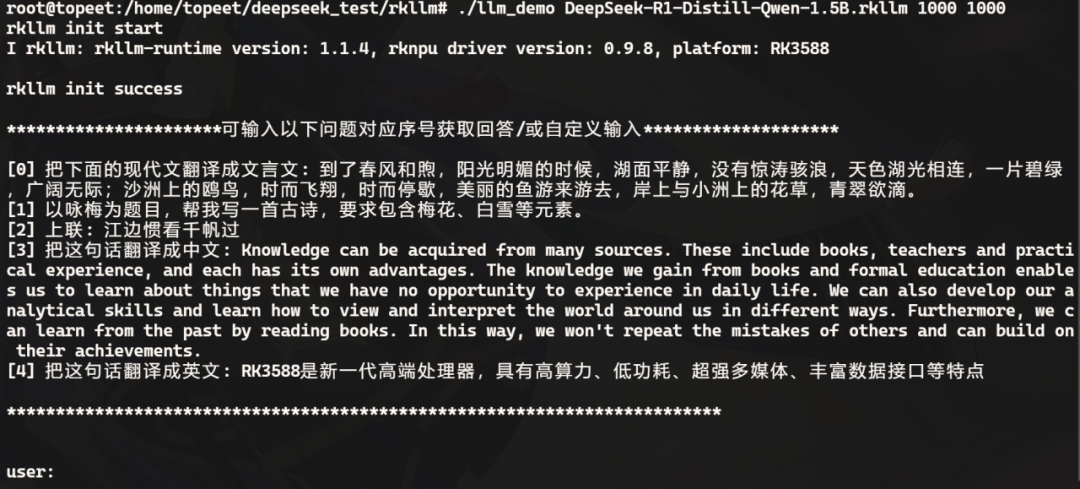
Next, you can ask questions to the model, and the response content is shown below:

During the response process, you can check the utilization rates of the CPU and NPU. You can see that the CPU usage has decreased, and three cores of the NPU are being utilized for accelerated inference:

Thus, the testing of the deployment inference of DeepSeek on RK3588 has been completed.
Deployment Video Showcase
-END-
