In the field of artificial intelligence and natural language processing, utilizing powerful tools and frameworks to interact with locally deployed models is a common and important task. Today, I will share how to use the LangChain framework to access models deployed locally on the RK3588.
Background Knowledge
Introduction to LangChain
LangChain is a powerful Python framework that simplifies the interaction process with large language models (LLMs). With LangChain, we can easily build complex applications such as chatbots, text generators, and more. It provides a rich set of tools and components, including prompt templates, output parsers, and chains, allowing us to leverage the capabilities of large language models more efficiently.

RK3588 Platform
The RK3588 is a high-performance ARM architecture chip with powerful computing capabilities and a rich set of interfaces. When deploying models locally, the RK3588 can provide sufficient computational resources to support the inference process of the models, enabling fast and efficient responses.
Code Implementation
1. Import Necessary Libraries
import os
import requests
from langchain.llms.base import LLM
from typing import Optional, List, Mapping, Any
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain.agents import initialize_agent
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.chains import SimpleSequentialChainIn this code snippet, we import several libraries, including <span>requests</span> for network requests and various classes and functions related to LangChain. These libraries will help us build the interaction logic with the local model.
2. Custom LLM Class
class RK_LLM(LLM):
api_key: str
api_url: str = "http://192.168.1.211:8080/rkllm_chat"
@property
def _llm_type(self) -> str:
return "rk_llm"
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
payload = {
"messages": [
{
"role": "user",
"content": prompt
}
],
"model": "Qwen/Qwen2-7B-Instruct" # Choose an appropriate model based on actual conditions
}
if stop:
payload["stop"] = stop
response = requests.post(self.api_url, headers=headers, json=payload)
response.raise_for_status()
result = response.json()
return result["choices"][0]["message"]["content"]
@property
def _identifying_params(self) -> Mapping[str, Any]:
return {
"api_url": self.api_url
}We define a class named <span>RK_LLM</span> that inherits from the <span>LLM</span> class. This class encapsulates the interaction logic with the local model, including sending requests and processing responses. The <span>_call</span> method is the core method responsible for constructing the request headers and body, and sending a POST request to the local model’s API address.
3. Main Program Section
if __name__ == "__main__":
api_key = "sk-your-key" # Not used
if api_key is None:
raise ValueError("Please set the API_KEY environment variable.")
llm = RK_LLM(api_key=api_key)
prompt = ChatPromptTemplate.from_template("Write a short article based on the following topic: {topic}")
output_parser = StrOutputParser()
chain = prompt | llm | output_parser
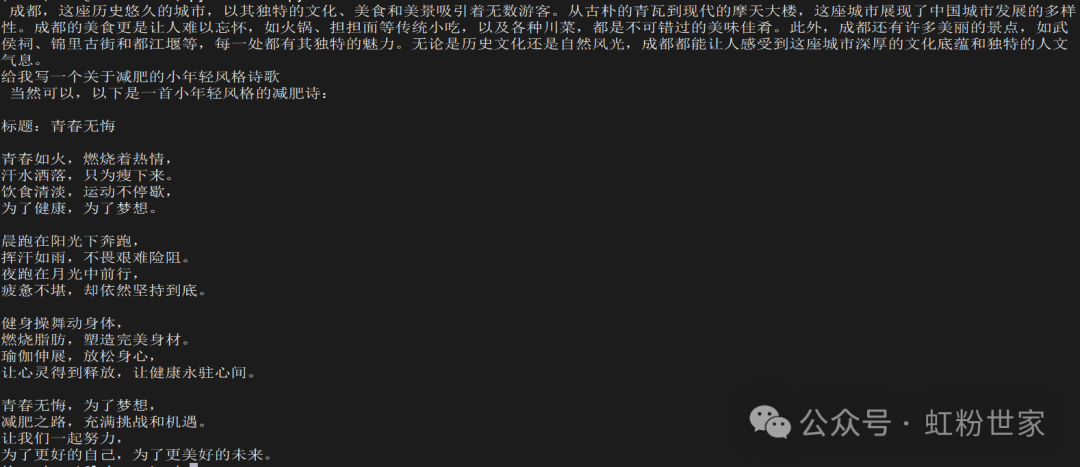
result = chain.invoke({"topic": "Chengdu"})
print(result)
from langchain.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template("Write a {adjective} poem about {content}")
prompt = prompt_template.format(adjective="youthful style", content="weight loss")
print(prompt)
chain = prompt_template | llm | output_parser
result = chain.invoke({"adjective": "youthful style", "content": "weight loss"})
print(result)In the main program, we first check if the <span>API_KEY</span> is set, then create an instance of the <span>RK_LLM</span> class. Next, we use <span>ChatPromptTemplate</span> and <span>PromptTemplate</span> to define prompt templates and use <span>StrOutputParser</span> to parse the model’s output. By combining the prompt templates, LLM instance, and output parser into a chain, we can conveniently call the model for text generation.
Running
Start LLM
$ python flask_server.py --rkllm_model_path /home/cat/qwen1.5b.rkllm --target_platform rk3588
NPU available frequencies: 300000000 400000000 500000000 600000000 700000000 800000000 900000000 1000000000
Fix NPU max frequency: 1000000000
CPU available frequencies: 408000 600000 816000 1008000 1200000 1416000 1608000 1800000
Fix CPU max frequency: 1800000
GPU available frequencies: 1000000000 900000000 800000000 700000000 600000000 500000000 400000000 300000000
Fix GPU max frequency: 1000000000
DDR available frequencies: 528000000 1068000000 1560000000
Fix DDR max frequency: 1560000000
=========init....===========
I rkllm: rkllm-runtime version: 1.1.4, rknpu driver version: 0.9.8, platform: RK3588
RKLLM Model has been initialized successfully!
==============================
* Serving Flask app 'flask_server'
* Debug mode: off
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:8080
* Running on http://192.168.1.211:8080
Press CTRL+C to quitExecution Result
Conclusion
Through the above steps, we successfully accessed the locally deployed model on the RK3588 using the LangChain framework. This method not only simplifies the interaction process with the model but also provides greater flexibility and scalability. In practical applications, we can adjust the prompt templates and model parameters as needed to achieve better generation results.