Skip to content

Against the backdrop of the rapid and stable development of the digital economy, cloud computing has become the cornerstone of enterprises’ digital transformation.
The application layer pursues more comprehensive, convenient, and faster services, which in turn drives the technology layer systems to become increasingly large, making it more challenging to maintain these systems. The occurrence of failures is inevitable, and ensuring continuous high availability and stability of business operations has become a challenge for everyone!
In terms of stability assurance capability construction, internet companies have conducted in-depth thinking and practice, from chaos engineering to observability, from end-to-end stress testing to multi-active applications. In contrast, most traditional domestic enterprises are still in the stage of transforming from mainframes to distributed systems and cloud-native architectures, with unclear paths and obstacles regarding stability assurance capability construction, and the technical value of stability assurance remains ambiguous.
In response to the challenges of reliability testing, chaos engineering offers some solutions. However, how can we use platform tools to practice reliability testing? To this end, Mr. Ye Qingshan, the product manager of PerfMa’s chaos engineering, will comprehensively demonstrate how to advance the stability capability construction of enterprise systems from the dimensions of reliability issue analysis, reliability testing schemes, finding the reliability denominator, constructing reliability test cases, and executing reliability test cases.
Reliability Issue Analysis
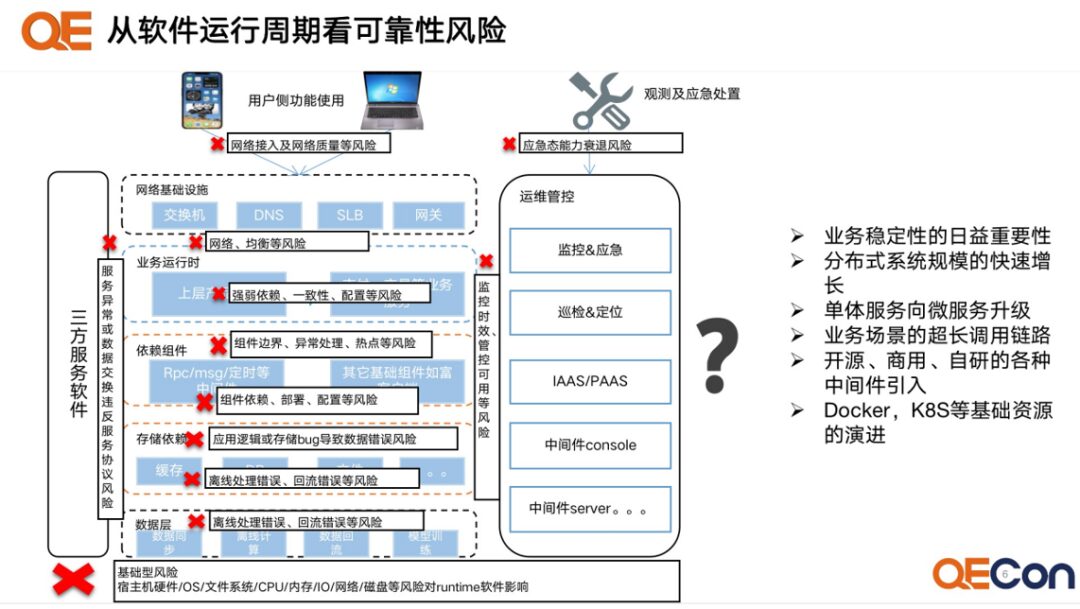
With the rapid development of the IT and internet industries, the complexity of software systems has gradually increased, and distributed technology architectures have become mainstream. Microservices, databases, caches, object storage, messages, and various distributed components create complex distributed systems. Large distributed systems may have thousands of nodes, and these nodes will inevitably encounter various failures such as hidden faults, network disconnections, and disk damage during long-term operation.
Distributed components generally design reliability related to faults through various methods such as primary-backup, clusters, mirroring, and sentinels to ensure the distributed reliability of the components. However, in actual deployment and operating environments, ensuring that these designs remain effective poses a significant testing challenge.
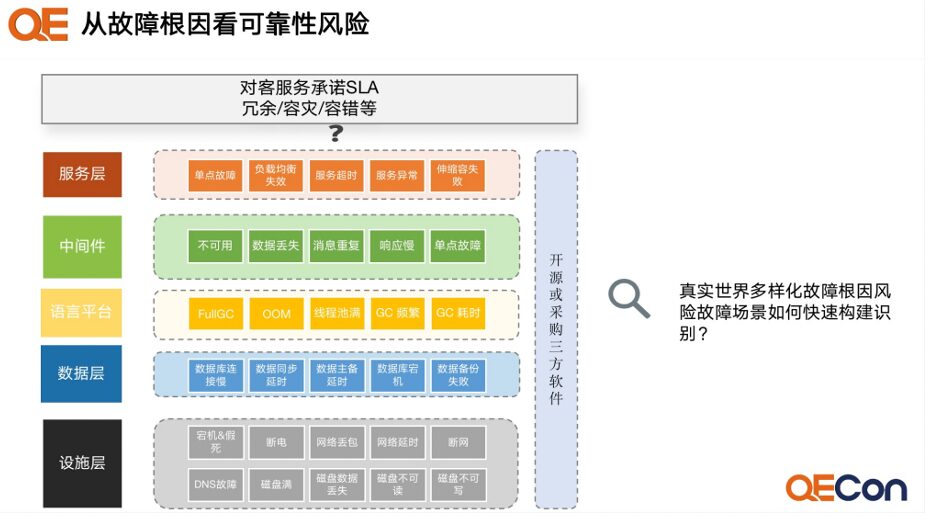
Fault Root Cause Classification
Currently, mainstream reliability analysis of distributed systems generally conducts layered analysis from the facility layer, data layer, operating system & language layer, middleware layer, to the service layer.
Reliability Testing Scheme
The reliability testing scheme consists of three major steps:
-
Conduct reliability risk analysis of the business system and build a risk scenario library.
-
Based on the risk scenarios, construct reliability test cases.
-
Execute reliability test cases based on chaos engineering.
Reliability Testing Goal: Improve SLA
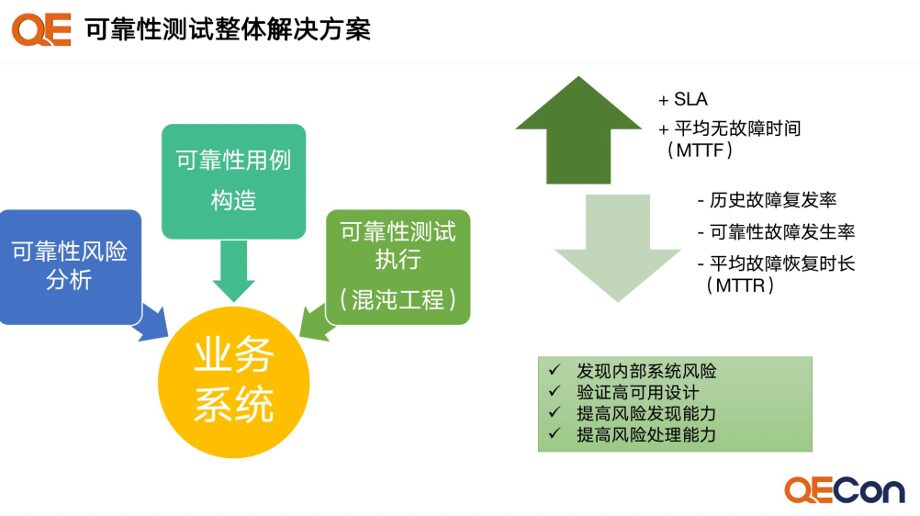 Reliability Testing Denominator
The following image shows a classification of risk scenarios. Generally, each middleware will have a corresponding type of risk scenario.
Moreover, when conducting risk analysis for our middleware, it will depend on its deployment architecture. Your primary-secondary deployment and cluster deployment, or your use of the sentinel mode, will lead to specific risk items derived from the entire risk scenario. Therefore, we have also roughly categorized different middleware with their respective risk libraries.
Reliability Testing Denominator
The following image shows a classification of risk scenarios. Generally, each middleware will have a corresponding type of risk scenario.
Moreover, when conducting risk analysis for our middleware, it will depend on its deployment architecture. Your primary-secondary deployment and cluster deployment, or your use of the sentinel mode, will lead to specific risk items derived from the entire risk scenario. Therefore, we have also roughly categorized different middleware with their respective risk libraries. 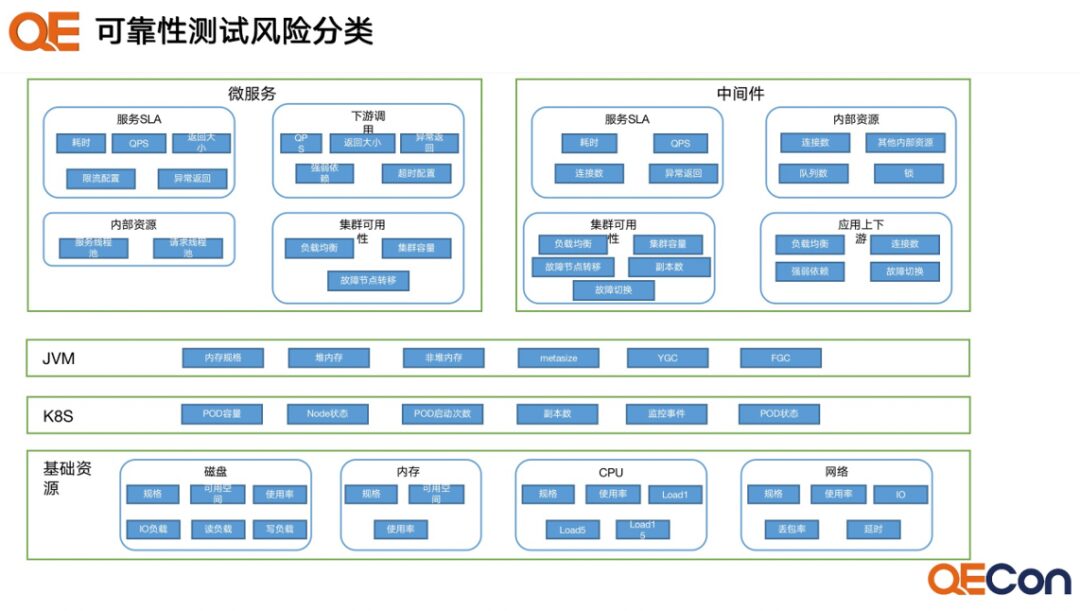
-
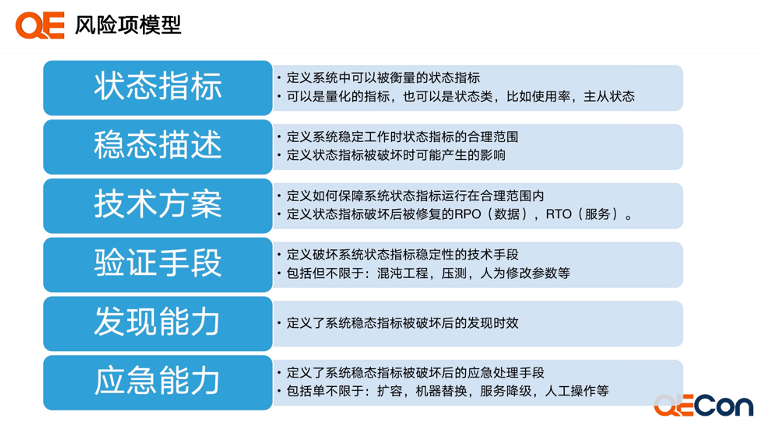
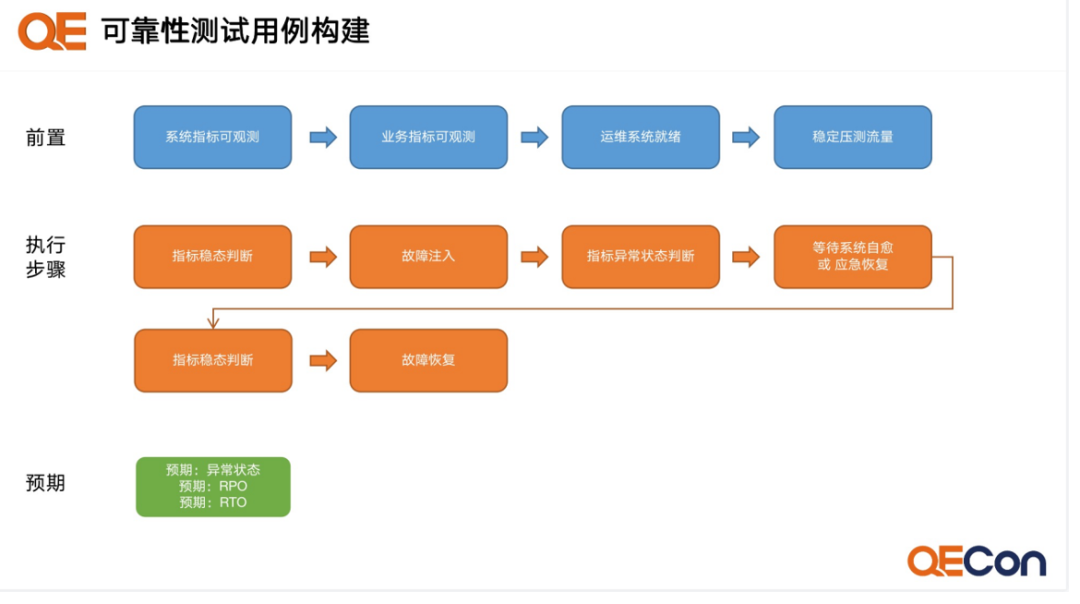
Define state indicators, which are measurable elements of a system that can ideally be quantified.
-
Normal operating state, as a description of steady state, we define what resources and indicators exist and what the range is. This includes what risks and failures may arise if this steady state is disrupted.
-
How we ensure the steady state, what range it should be in, and what technical means to use to guarantee its operation.
-
For the defined steady states, what are the technical verification methods, and how do we verify them? This involves how to disrupt this steady state, where chaos engineering is one method. As previously mentioned, stress testing or human-induced disruptions are also valid methods; as long as they can disrupt the steady state, they are acceptable.
-
Discovery capability, which is closely related to risk inspection and measurement capabilities.
-
Emergency capability, which may define some requirements for your self-healing ability.
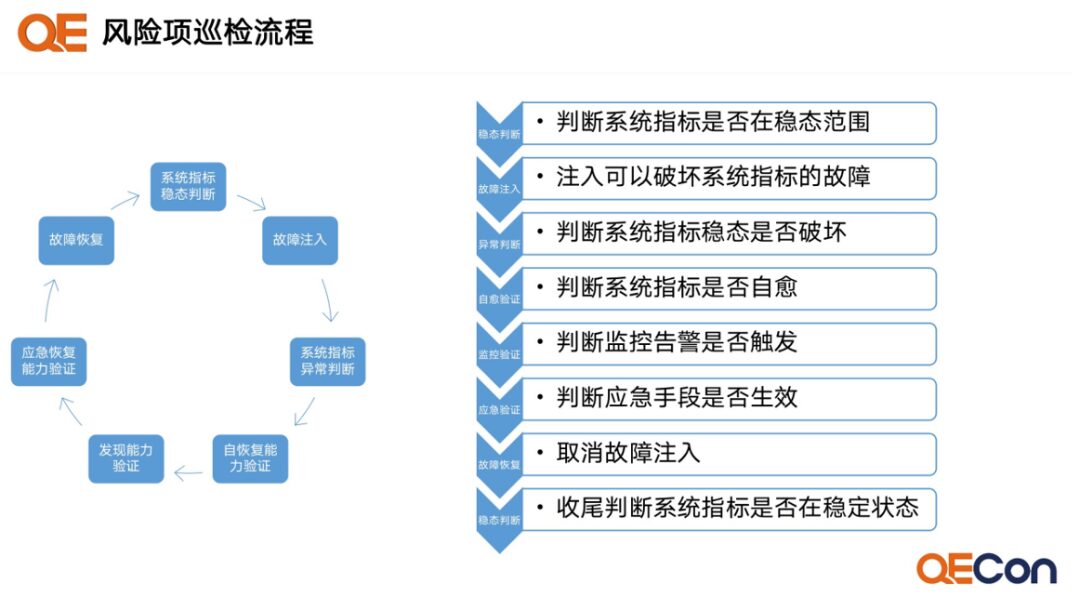
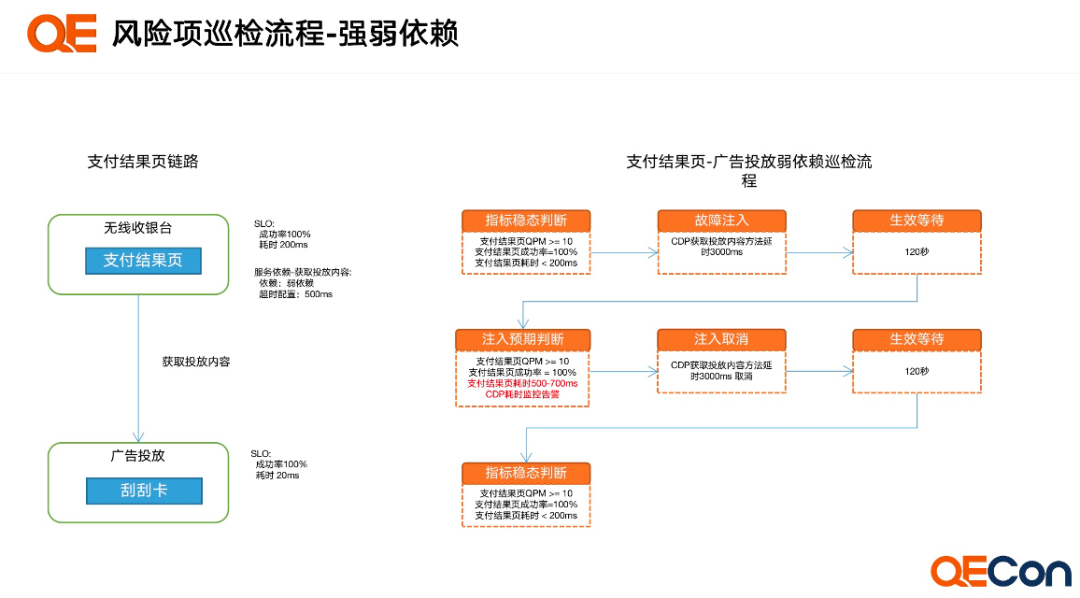
Risk Item Inspection Process
An Example of a Risk Item Inspection
Assuming that the payment results page has a weak dependency on advertising placement, after injecting faults into the downstream advertising placement service, the overall business success rate remains unchanged, while the time taken increases. The entire exercise process is as follows:
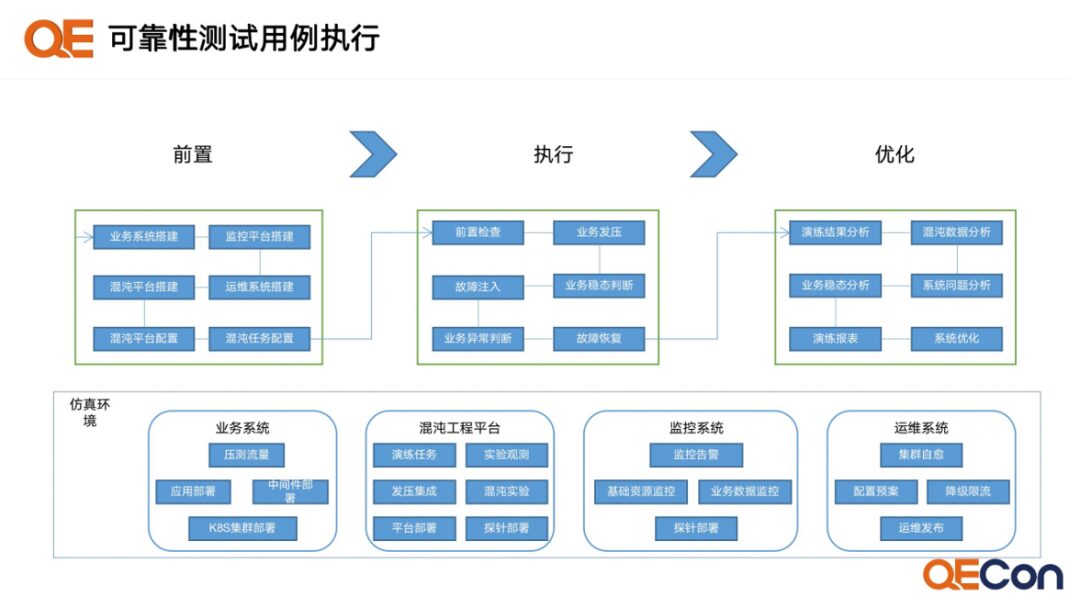
The simulation environment needs to have:
-
A business system with the same deployment architecture as the online environment.
-
A well-defined monitoring system.
-
An operations platform with emergency capabilities.
-
A chaos engineering platform with fault injection capabilities.
Specific execution steps:
Introduction to Chaos Engineering
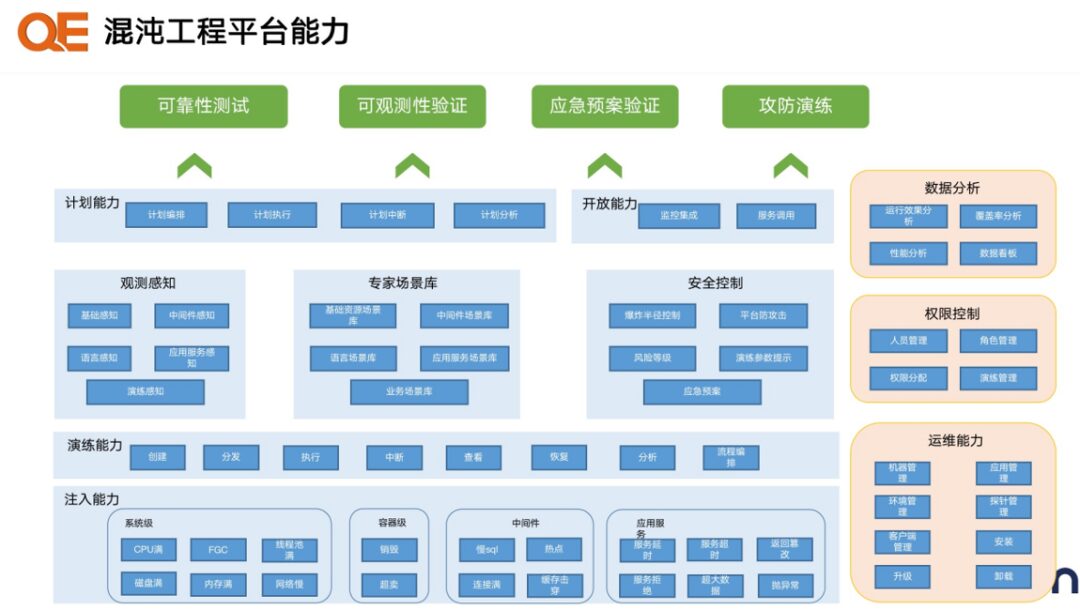
Capabilities of Chaos Engineering Platforms
-
The chaos engineering platform has rich fault injection capabilities.
-
The platform features expert scenarios, facilitating quick implementation by testing teams.
-
Applicable in various scenarios including reliability testing, emergency validation, and attack-defense drills.
Future Outlook for Reliability Testing
With the development of chaos engineering concepts in China, testing teams are gradually introducing and applying these concepts. However, the overall approach is still tool-oriented and lacks a systematic and comprehensive methodology. Looking ahead, future development can focus on the following aspects.
Establishment of Relevant Reliability Testing Systems
Based on chaos engineering reliability testing, from use case design, execution, fault injection, to test analysis, there is currently no industry-wide standard or specification. With the development of the industry, it is believed that relevant standards and specifications will emerge.
Construction of Reliability Testing Platforms
Compared to functional testing and performance testing, there are already many mature tool platforms available in the industry. Currently, there are also many chaos engineering tool platforms, but there is yet to be a reliability testing tool platform based on chaos engineering in the market. It is believed that in the near future, as reliability testing based on chaos engineering continues to be implemented, relevant tool platforms will inevitably emerge.
Frontend Reliability Testing
The mobile internet era has long arrived, but currently, mainstream chaos engineering is still focused on server-side applications. From a complete technical chain perspective, conducting reliability testing on the frontend is also a development direction.
-
How to Design Stability Scenarios for Performance Testing?
-
Principles and Practices of the Cloud-Native Chaos Engineering Platform Chaos Mesh
-
Insights from Alibaba Experts: Chaos Engineering Platform Practices in Cloud-Native Environments
-
In-Depth Interpretation of China’s First “Chaos Engineering Survey Report”
-
Open Source Solutions for Chaos Engineering Targeting Kubernetes