This article is a transcript of the second lesson in the autonomous driving series organized by Zhixiaodongxi. The session was led by Liu Guoqing, CEO of Minieye, with the theme “How to Break Through the Recognition Accuracy of ADAS Systems.” You can reply “autonomous driving” in the Zhixiaodongxi WeChat public account to obtain the complete course materials and audio.

Zhixiaodongxi (WeChat public account: chedongxi)
Introduction: The automotive industry is undergoing dramatic changes, and the wave of autonomous driving is coming. Will it be swallowed by the wave, or will it stand atop it? How to win the title of “Mother of Artificial Intelligence Projects” and use intelligence to replace manual control of vehicles? Starting from September 14, Zhixiaodongxi has launched a series of 9 autonomous driving courses. Nine practical mentors will provide over 810 minutes of systematic explanations and in-depth interactions, completing a professional breakdown of 33 knowledge points to help you build a knowledge barrier for future vehicles.
Reply “autonomous driving” in Zhixiaodongxi to get audio and materials for the series.
The second lesson of the Zhixiaodongxi autonomous driving series is presented by Liu Guoqing, CEO of Minieye, on the theme “How to Break Through the Recognition Accuracy of ADAS Systems.”
Take note! Here are the highlights! Zhixiaodongxi has specially extracted the most valuable insights from the course, sharing important trends and exciting viewpoints on ADAS as shared by Liu Guoqing.
Key Points Overview

1. ADAS and Its Recognition Capabilities:
1) Advanced Driver Assistance Systems (ADAS) is a broad concept that encompasses any function that enhances driving safety and comfort. This lesson focuses on the technical aspects, mainly concentrating on camera-based visual ADAS.
2) The working steps of ADAS (Advanced Driver Assistance Systems) are perception-decision-control. Perceiving the environment is the foundation for the entire system to function, and the sensors providing perception capabilities include LiDAR, millimeter-wave radar, and cameras. The image information obtained by cameras is large, with high resolution and multidimensional information, making camera-based visual perception ADAS have strong recognition capabilities.
3) The recognition capabilities of ADAS include target classification, target detection, target recognition, and semantic segmentation.
2. How to Improve the Recognition Accuracy of ADAS Systems:
1) The main methods for improving the recognition accuracy of ADAS are deep learning + big data. By using deep neural networks to train as many image data as possible, the recognition accuracy can be improved.
On one hand, deep learning does not require engineers to manually set recognition features, and the networks are transferable and reusable, lowering the barriers for visual recognition. On the other hand, the amount of training data is usually proportional to the recognition rate of the ADAS system. A large amount of data can also cover various peculiar scenarios (such as encountering a flock of sheep on the highway) to enhance recognition capabilities in special scenarios.
2) ADAS systems can also improve recognition accuracy by enhancing computing power and using multi-sensor fusion.
3. Future Development Trends of ADAS:
1) Deep learning not only empowers recognition capabilities but will also be used more for driving strategy formulation;
2) Computing hardware will develop rapidly, providing stronger computational support for ADAS;
3) The usage by end users, along with data collection and technological iterations, can form a closed loop, where the data uploaded by users will be used to update and enhance the capabilities of the ADAS system.
4) ADAS and autonomous driving share many underlying technological similarities, and in the future, ADAS will evolve towards autonomous driving.
Lecture Transcript

Liu Guoqing: Good evening, everyone. I am Liu Guoqing, the founder of Minieye. First, I would like to thank Zhixiaodongxi for providing such a great platform, and I also want to learn from everyone. Let me introduce our company—Minieye, founded in Singapore in 2013 and moved back to China the same year. We focus on visual perception technology and product development in vehicular environments, primarily involving driving assistance systems and visual perception modules.
Our vision is to reduce accidents by starting with technological products. Our headquarters is in Shenzhen, with two R&D centers in Nanjing and Beijing. Friends from all fields are welcome to come and exchange ideas with us.
Next, I will officially start today’s report. The theme of today’s presentation is “How to Break Through the Recognition Accuracy of ADAS.”
1. Basic Concepts

First, to better develop the following topics, I will briefly introduce some basic concepts related to the theme.
Broadly Defined ADAS

Advanced Driver Assistance Systems (ADAS) is a broad category that includes functions often mentioned, such as forward collision warning, lane keeping, reversing radar, as well as ABS, vehicle stability systems, even night vision, onboard navigation, and rain sensors, all of which fall under the ADAS category according to Wikipedia. Therefore, any function that enhances driving safety and comfort can be considered part of the driving assistance system.
Perception Technology-Based ADAS
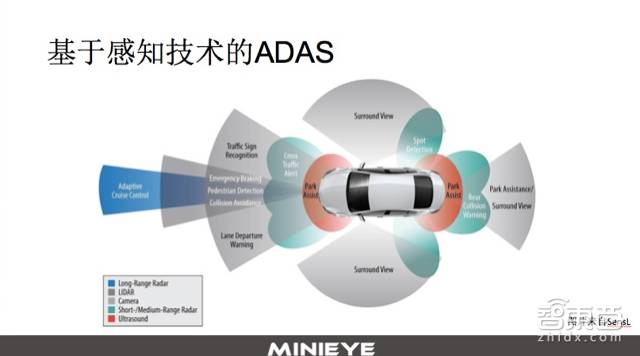
Today’s sharing focuses on a specific subfield—perception technology-based ADAS. In this PPT, we can see various sensors installed in vehicles, including long-range millimeter-wave radar, cameras, LiDAR, short-range radar, and ultrasonic radar. Based on these different sensors and the subsequent ECO, we can develop functions such as forward collision warning, adaptive cruise control, traffic sign recognition, and parking assistance.
These functions are based on perception technology, meaning that they perceive the traffic conditions around the vehicle through sensors and design application-level solutions based on the feedback from perception. This type of function is referred to as perception technology-based ADAS, which is also the theme we will discuss today.
Working Principle of ADAS
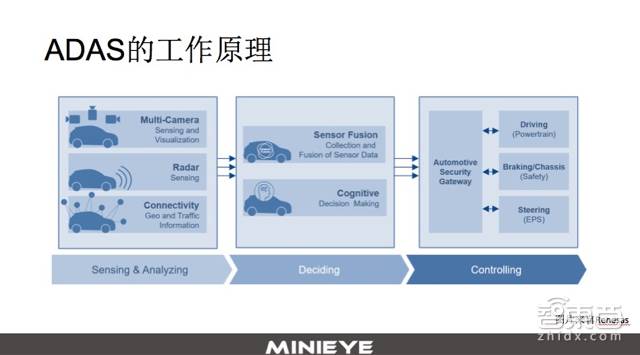
In the following report, unless otherwise noted, ADAS will refer to perception technology-based ADAS. The ADAS product consists of three parts: 1. The perception part, which obtains information about the surrounding environment, such as roads, vehicles, pedestrians, and signs; 2. The decision part, which, based on information from the perception part, can perform sensor-level fusion to make decisions about whether there is a danger and whether to brake, accelerate, or steer, and to what degree; 3. The control part, which, after making a decision, is responsible for control. For example, if the camera recognizes that a vehicle ahead is braking suddenly, and our relative speed is very high, based on this information, we may determine that a rear-end collision might occur in 1.3 seconds. In this case, we need to take braking action, and the perception system will transmit this braking signal to our braking system to complete the entire ADAS function. However, some ADAS do not include control modules; these ADAS may use other methods, such as audio warnings, vibrations, or displays to alert the driver to take action.
Vehicle-Based Perception System

From the previous PPT introduction, it can be seen that the perception module is the cornerstone of the entire ADAS structural system. If the accuracy of the perception part does not meet the requirements for productization, then the decision and control parts cannot be discussed. The vehicle-based perception system also consists of three parts: the first part is the sensors, whether they are cameras, LiDAR, millimeter-wave radar (24GHz or 77GHz), or ultrasonic radar, they are all sensors. When we obtain digitized data in a specific format through these sensors, we then need to recognize and understand this digital signal, identifying what is a person, what is a vehicle, and what is a curb; this recognition process requires support from signal processing-related software algorithms, so the second part of the perception system is software algorithms. Of course, having software requires running it on a hardware platform, so the third part is our hardware platform. Overall, the vehicle-based perception system is composed of our sensors, software algorithms, and hardware platform.
Sensors

The technical path of the perception system is determined by the type of sensors used. For example, our company uses cameras as sensors. Therefore, our entire algorithm is developed based on computer vision or visual perception as the core algorithm and technology. Leaving aside cost, from a technical perspective, different sensors each have their strengths and complement each other. For example, cameras have much higher resolution than other types of sensors and can perceive many details, making them very good at qualitative tasks. The higher the level of autonomous driving, the greater the requirements for detail. For LiDAR, its quantitative capabilities are excellent, achieving very high precision. Millimeter-wave radar excels in handling various road conditions and adverse weather, so different sensors actually complement each other.
In such a multi-sensor fusion perception system, cameras and the visual perception technology that supports them play an indispensable role. High resolution gives them a significant advantage, with cameras obtaining about 50 megabytes of information per second, while the precision of LiDAR or millimeter-wave radar is generally in the low megabyte range. This means we can obtain more driving environment details from more information.
Another point is the multidimensionality of camera information. Cameras can obtain not only contour and shape information but also rich texture information, color information, grayscale information, etc., which are not available from other sensors. Therefore, from these two points, cameras have a unique position in the multi-sensor fusion perception system.
2. Classification of Recognition Tasks

This section will return to recognition itself. Since the theme is to improve the recognition accuracy of ADAS, we must first clarify two things: one is the recognition task itself, and the other is recognition accuracy. Chinese is a very powerful language. When we talk about image recognition in Chinese, it actually encompasses four aspects from a technical perspective.
Target Classification

First, for an image, we automatically identify whether there are cars, people, and traffic lights in the image. Then we label the image, which we call tagging; this task is called target classification (classification).
Target Detection

We can go a step further; not only do we need to know that there is a car in the image, but we also need to know the car’s position in the image. We will use a box to mark it. This task is called target detection (detection). For example, in our smartphones or cameras, when taking a photo, they will automatically mark the faces within the view; this module is essentially a face detection process.
Target Recognition

Moreover, besides recognizing where there are cars, people, and faces in the image, we can go further. For example, if I find a face, I can identify who it is, whether it is the Mona Lisa or Mr. Bean. This task is called target recognition (recognition). Face recognition has become very common in our lives.
Semantic Segmentation

We can also go further to obtain more details. For example, we want to know which pixel in the entire image belongs to which target? Is it a car, a person, or a bicycle? Is it a motor vehicle lane, a non-motor vehicle lane, or a curb? Is it a traffic light or a sign? This task is called semantic segmentation (Pixel Labeling).
Thus, whenever we mention image recognition, it can cover a vast range; it can be target detection, target classification, or semantic segmentation. This is a relatively large field, and each sub-task within it plays a very important role in developing ADAS.
Visualizing Recognition Accuracy
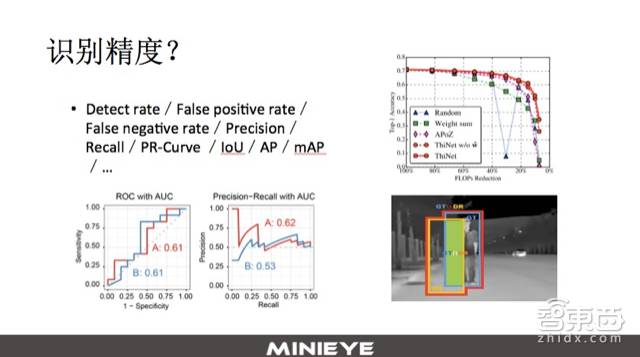
The theme of today is to break through the recognition accuracy of ADAS, and as mentioned earlier, the recognition task itself has many different specific directions, so the concept of recognition accuracy is very abstract and broad. Sometimes when I attend forums, meetings, or face clients, I am often asked, “Hey, how accurate is your algorithm?” At that moment, I often do not know how to respond because, from a technical perspective, this question is very vague.
In reality, for each different sub-recognition problem, whether it is target detection, target classification, target recognition, or semantic segmentation, they all have different evaluation systems or standards to measure the performance of their algorithms. For example, the PPT includes metrics like Detect rate, False positive rate, Precision, recall, and even some curves like PR-Curve. For detection tasks, we also use metrics like IoU, AP, and mAP to evaluate the quality of our algorithms.
This page of the PPT is not meant to give everyone a clear understanding of the entire evaluation system in a short time, which is unnecessary because it is too specialized; it is just to let everyone know that when we talk about target image recognition and recognition accuracy, there are many concrete aspects involved.
3. How to Improve Recognition Accuracy

The previous sections were groundwork for today’s theme, and this part is the main focus of today. I will share from our perspective, based on over four years of experience in this field, what points are helpful for improving the recognition accuracy of ADAS.
Challenges to Improve Recognition Accuracy: Uncontrollable Traffic Environment

To solve this problem, we must first understand what our greatest enemy is. From my personal perspective, the core challenge in improving the recognition accuracy of ADAS systems is the uncontrollable nature of the traffic environment.


Currently, the autonomous driving industry has seen earlier implementations in controlled environments. However, in the ADAS industry, we must face a demand—driving assistance under all weather conditions.

Thus, for ADAS products, we need to perform well not only under good conditions on highways (in fact, under these relatively simple conditions, current recognition technology can already meet the perception needs of ADAS very well) but also under more complex conditions, such as in congested urban environments. In these cases, we must deal with severe occlusions, and numerous traffic targets that do not move in an orderly manner, such as non-motor vehicles going against traffic in motor vehicle lanes. The rapid updates of domestic traffic infrastructure mean that sometimes marking lines, lane markings, or various signs may have iterative issues; for example, if there are red and white markings in the image, which one should I follow? It can be difficult even for a human to judge, let alone for a computer to make an automatic judgment.

We also need to consider special scenarios (corner cases); the terrifying aspect of special scenarios is that they are unpredictable. Before encountering them, you cannot imagine what kind of scenario you might face. This photo was taken last month during a business trip in Xinjiang, where we suddenly encountered a flock of sheep on a provincial road, completely blocking the road, and they slowly passed by my car on both sides, taking nearly 10 minutes. Later, I asked the shepherd, and he said there were 2,600 sheep in total.
Therefore, I believe that the key to improving the recognition accuracy of ADAS is how to maintain high-quality recognition accuracy under complex working conditions.
The Role of Deep Learning and Big Data in Improving ADAS Recognition Accuracy

From our past experiences, deep learning and big data are two important tools that help us improve ADAS recognition accuracy under complex conditions. Next, I will report on these two aspects.

Friends participating in today’s activity should be familiar with the concept of deep learning (Deep Learning), as it has been very popular in recent years. I believe that one of the important drivers of this wave of artificial intelligence is the evolution of deep learning technology.

There is an interesting image on the internet showing the different perceptions of graduate students engaged in deep learning research. We can see that professionals in artificial intelligence, especially those engaged in deep learning, have a very impressive image in people’s minds. For deep learning, people feel an inexplicable awe. In fact, this field indeed gathers a group of very talented individuals. This reminds me of the early 20th century when the quantum theory was established; a similar situation occurred during that relatively short period of time, where a series of beautiful theories were proposed, of course, with much debate, splitting into two factions. Just as deep learning is rapidly developing, there are many players involved, including software and hardware companies, startups, or research institutions.

This image is from a famous conference in the last century, the fifth Solvay Conference. This photo is also quite famous, gathering a group of big names, such as Einstein, Bohr, Born, Schrödinger, Curie, Dirac, De Broglie, Planck, among others. Thus, it is said that this photo gathered two-thirds of the world’s wisdom at that time. Similarly, in today’s deep learning era, a large number of brilliant minds, excellent scientists, and engineers are engaged in deep learning, whether in theoretical research, experiments, or related R&D work.

In academia, there is a well-known website called arxiv.org (an online database for preprints of scientific literature). When I was doing my PhD, it wasn’t that popular. But now we can see that on September 14, 18 new papers were published in the field of computer vision, with nearly 70% of them related to deep learning. Why are so many people eager to publish their work on arxiv before formal submission? Because there are a lot of talents working on similar research in every direction, and it is possible that a model you spent six months developing may have already been posted by someone else just before submission. The same goes for the industry; you may spend three to six months developing something, and during the productization process, you find that the same technology has already been launched by your competitors. This is quite normal. Therefore, for practitioners in artificial intelligence, especially in deep learning, this era is both the best of times and the worst of times.
Review of Deep Learning History

Next, I will briefly review the development history of deep learning. Deep learning can be traced back to the 1940s, proposed by a psychologist and a mathematical logician, who first introduced neural networks as a theoretical computer model; this was a long time ago.
In 1957, Frank Rosenblatt, a professor at Cornell University, proposed the perceptron, inspired by the transmission from dendrites to axons, using this approach for mathematical modeling. From today’s perspective, the perceptron is actually a binary classification learning algorithm, serving as a linear classifier; this single-layer perceptron can indeed be seen as the simplest neural network. However, the learning algorithm of the perceptron cannot solve non-linear problems and cannot converge; a famous example is the XOR problem.

Because of this, it was declared dead by Marvin Minsky, the father of artificial intelligence and a famous MIT AI laboratory founder and Turing Award winner. In the 1960s, he condemned neural networks, mainly based on the theory that this technology could not solve even the simplest XOR problem, rendering it worthless. Because of Minsky’s statement, neural networks entered their first winter.
In 1980, Japan’s Fukushima proposed a new perceptron, and shortly after, the deep learning giant Hinton published a famous backpropagation algorithm in Nature. Hinton’s work provided a backpropagation algorithm suitable for multilayer perceptrons and used the sigmoid function for non-linear mapping, effectively solving the non-linear classification problem.

Following Hinton, another deep learning giant, Yann LeCun, also emerged. In 1989, he proposed the pioneering work of convolutional neural networks, which used a 5×5 convolution box; this CNN prototype was used for handwritten digit recognition and was successfully applied by the U.S. Postal Service for automatic recognition of postal codes.
Although early deep neural network work achieved good results in specific applications, it still had some significant flaws. There are two major issues. The first is the non-convex problem; since it is non-convex, the issue is that it may converge to a local optimum but could be a poor result globally. The second issue is the gradient vanishing problem of the backpropagation algorithm; during the backpropagation of gradients, due to the saturation characteristics of the sigmoid function, the gradients that are backpropagated are very small, leading to almost zero error propagation in the forward direction. Therefore, it cannot ensure effective learning of all parameters throughout the process. Because of these two points, deep learning entered its second winter around 2000, lasting until 2006.
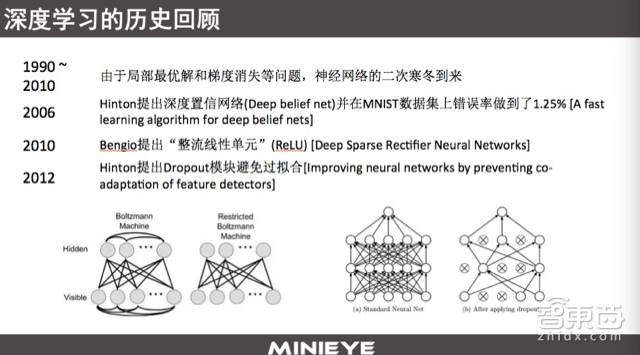
Many people believe that 2006 is the birth year of deep learning because that year Hinton proposed a method to effectively solve the gradient vanishing problem through unsupervised training and fine-tuning. By 2010, a new breakthrough technology was proposed based on rectified linear units, which effectively mitigated the gradient vanishing problem.

In 2012, deep learning entered an explosive period, with its turning point being Hinton’s participation in the ImageNet image recognition competition in 2012 to demonstrate the power of deep learning. The dataset of this competition contained over a million images, and Hinton and his team built AlexNet based on convolutional neural networks. Not only did they win first place, but they also had a crushing advantage in the Error rate metric. From the table, we can see that the Error rate of deep learning in 2012 was 0.15, while the second place was 0.26, giving a 10-point lead. From 2012 to 2017, deep learning dominated the ImageNet competition, with the Error rate dropping from 0.15 to 0.02. In the lower right corner of the image, we can see that the architecture of deep neural networks has become increasingly deeper, from the initial 8 layers, 19 layers, 22 layers to over 150 layers.
Comparison of Deep Learning and Traditional Methods
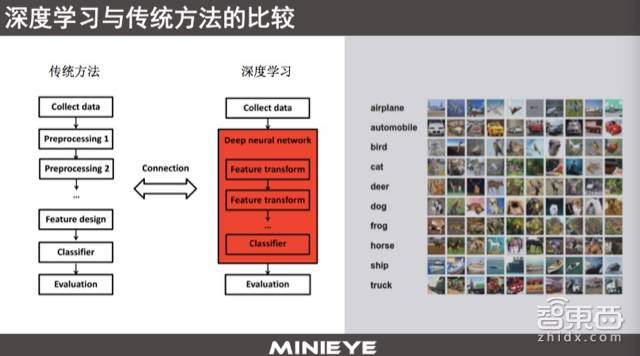
From an architectural perspective, deep learning and traditional machine learning methods have significant differences. In traditional methods, the model architecture requires a higher level of frontier knowledge; for instance, if I have a million such data, I need to preprocess the data based on experience, then design features according to the actual application scenario and requirements. However, there is still no universal feature that can work for various tasks, whether for target detection, recognition, or for humans and vehicles. Different features are required for face and body recognition. The design of these features needs engineers or scientists to rely on experience and understanding of the problem.
From this perspective, traditional methods impose higher requirements on developers, making the threshold higher. Deep learning simplifies the entire process. At this point, developers may focus more on designing network structures; with data and network structures, the selection and extraction of features, as well as the choice of classifiers, are all accomplished automatically by the network structure based on the data. Therefore, in this regard, deep learning lowers the barriers for visual perception and image processing to some extent.
Through neural networks, we can abstract from the pixel level of images, extracting high-frequency and low-frequency features further up to features describing cars, people, or signs, and this is a bottom-up abstraction process that does not require human involvement; once you design a network structure, the entire process is automated. Thus, some voices in academia regard deep learning as a form of feature learning.
Deep learning also has an advantage over traditional methods in terms of transfer learning and feature reuse. When we implement specific applications based on deep learning, we can use a backbone network, typically based on ImageNet, which has a very large dataset of millions of images. After obtaining a backbone network, we can fine-tune it based on this backbone network and the specific application data; generally, our fine-tuning will increase by 5-10 megabytes, while our backbone network usually has hundreds of megabytes, or even over a thousand megabytes, showing that many aspects can be reused based on the deep learning architecture.
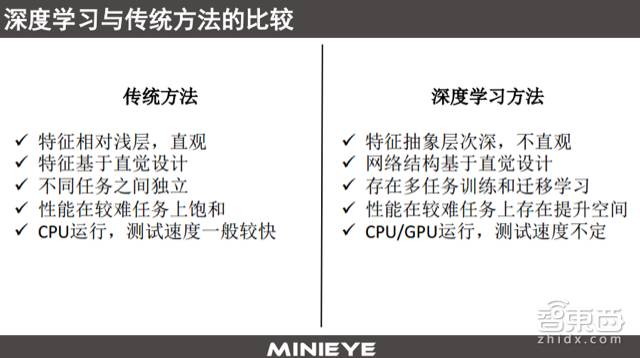
To summarize, traditional methods have relatively shallow features that have good physical meanings because they are designed based on intuition. There is a strong independence between different tasks; for instance, a model or algorithm designed for cars cannot be directly applied to face or body recognition. In terms of performance, they can perform well in some practical tasks, but for more complex and challenging tasks, they may become saturated; however, their advantage is that the complexity of the algorithms is lower, allowing them to run quickly on existing ARM architecture platforms.
In contrast, deep learning features are deep and more abstract. This is because they are not artificially designed but learned directly, which can yield excellent results, but it is unclear why they work well. The entire network structure is directly designed by engineers, and as mentioned earlier, it can perform multi-task training and transfer learning. For challenging tasks like ImageNet, traditional perception Error Rate metrics can only achieve 0.15, while deep learning can reduce it to 0.02.

Here are some related materials; if you are interested in deep learning, you can further explore.
Application Examples Based on Deep Learning
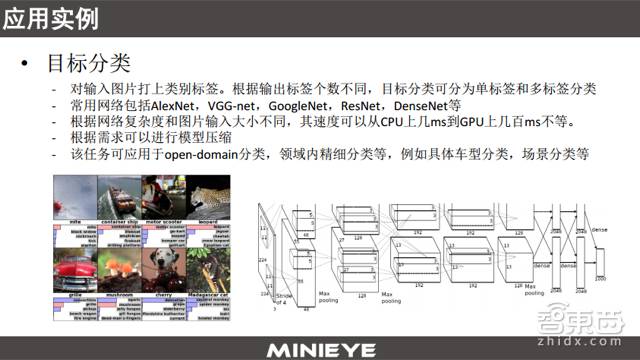



Based on deep learning, there are many applications in the field of image recognition. You can take a simple look at the images above, such as Alex-net and GoogleNet in target classification. It can also be used for target detection, with algorithms like Fast-RCNN, Faster-RCNN, SSD, etc., which are all effective algorithms. Of course, there are also many applications in face detection, recognition, and verification, as well as in semantic segmentation, which can be divided into general semantic segmentation and instance-aware segmentation, and in image processing, such as image denoising, edge extraction, and image enhancement.
How to Improve ADAS Recognition Accuracy Under Complex Conditions

In addition to deep learning, another aspect that significantly contributes to improving recognition accuracy is data. In the past, there was a saying in academia: “Data is King.”

The reason we need more data is that, as mentioned earlier, the working conditions of ADAS are very complex, and the targets may have different postures—some may be crouching, others sideways, bending down to pick something up, or sitting. It may need to deal with different occlusions; for instance, if a person ahead is holding an umbrella, you cannot just ignore them and drive past. Various lighting and weather conditions significantly affect imaging, and the data presented under these relatively harsh conditions must maintain an acceptable accuracy level from the corresponding perception system.




In some relatively backward areas of China, where regulations are not as strict, you may encounter very rare situations on highways, provincial roads, or rural areas, which we call atypical situations that need to be addressed. Through large-scale data collection and labeling, we can significantly enhance the adaptability and accuracy of ADAS recognition technology. Therefore, we have many vehicles collecting data outside every day, and upon collection, the data undergoes filtering, cleaning, and labeling. Currently, for deep learning and traditional perception algorithms, we mainly still use a supervised learning mechanism, providing standard answers for these images based on your needs, allowing the algorithms to iterate and become smarter.

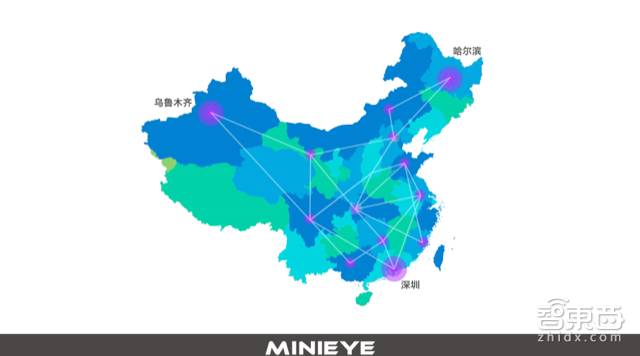
In terms of data collection, for example, we now collect data from the north to Harbin, south to Shenzhen, and west to Urumqi. Every day, we collect data from nearly 18,000 kilometers of mileage. The reason for such extensive data collection is to ensure that our database covers as many working conditions as possible. This guarantees that data under different conditions has sufficient volume to support our algorithm’s learning.
Such a large volume of data needs to be labeled; of course, the traditional method is manual labeling, which remains a very important approach. Additionally, there are methods to enhance labeling efficiency, which we call automatic labeling. We use the DDT method to automatically label the targets we are concerned about at the pixel level in images, which helps reduce labor costs while improving efficiency.

Other Methods to Improve ADAS Recognition Accuracy
So far, I have shared from the perspectives of deep learning and big data, combined with our past experiences. However, there are other methods that can also benefit accuracy improvement.
For example, enhancing computing power, whether for deep learning or traditional perception algorithms, places high demands on the computational resources and capabilities of our computing platforms. When we have stronger computational support, we can use deeper network structures and more complex deep learning methods to improve our recognition accuracy.
Similarly, we can also enhance recognition accuracy through multi-sensor fusion, combining visual data with millimeter-wave radar, LiDAR, and even high-precision maps to improve reliability and recognition accuracy of our ADAS under complex conditions; this is also a very effective method.
In summary, there are many methods to try for improving ADAS recognition accuracy. Each method requires extensive effort and many detailed tasks, which may be a difference between product and service work, necessitating a more systematic approach to problem-solving.
4. Future Development Trends of ADAS
Finally, I would like to share my personal views on the future development trends of ADAS.

First, I believe that deep learning technology will play a greater role not only in ADAS but also in autonomous driving, potentially not only in recognition but also in strategic aspects.
The second point is the rapid development of computing power. Whether we are working on ADAS, autonomous driving, or other artificial intelligence industrial applications, this is a particularly helpful development. Over the past five years, artificial intelligence has developed rapidly, largely due to significant investments from major companies like NVIDIA and Intel in enhancing our computing platform’s computational capabilities. This year, computational power has increased more than tenfold compared to last year, which was unimaginable in the past. The rapid development of computing power is not just a trend; it is also an opportunity for our ADAS and intelligent driving.
The third point is that the usage by end users, along with data collection and technology iterations, can form a closed loop. Currently, related technologies for autonomous driving have not been widely popularized, and the few users who have installed ADAS or autonomous driving terminal devices are essentially offline devices that do not transmit collected data. However, the requirements for data for technological iterations, whether for driving behavior or traffic environment data, are significant, and this data is very meaningful for improving our technology and enhancing ADAS recognition accuracy. I believe that in the future, this will be connected; once I create something and install it for users, the data accumulated during their use can be transmitted back. Based on these user data, we can better iterate algorithms to provide better functionality, and then send this functionality back to my data through OTA, thus forming a closed loop. I believe this connection can be established in the future.
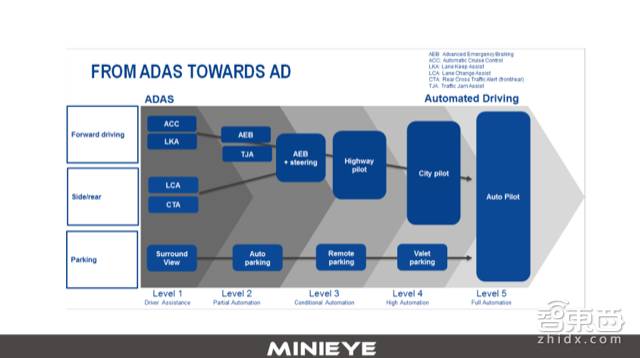
There are some issues that cannot be avoided, such as data ownership and information security issues during the OTA process. From an industrial perspective, I prefer a diagram that illustrates the transition: FROM ADAS TOWARDS AD, indicating the transition from ADAS to autonomous driving. I firmly believe that the future of autonomous driving is an inevitable trend. The reason is simple: autonomous driving is the ideal way to simultaneously address traffic efficiency and safety. Therefore, I believe a crucial direction for the future of ADAS is to gradually evolve towards higher levels of autonomous driving. Of course, the technologies used in ADAS and autonomous driving differ to some extent, but we must acknowledge that many core technologies, such as visual perception, multi-sensor fusion, and underlying control technologies, are very similar.
Alright, my sharing ends here today. Thank you all.
Q&A Transcript

Question
Song Hailong – BAIC New Energy – Test Engineer
1. The relationship between the curvature radius range of the circular test track, maximum speed, and the actual precision of the ADAS system;
2. Regarding the false alarm rate, three aspects: one is driving in a straight lane with vehicles in the adjacent lane possibly causing false alarms; second, driving on a circular track where adjacent vehicles may cause false alarms; third, what false alarm rate is acceptable for mass production vehicles?
3. Is it sufficient to test AEB and FCW according to national standards to be officially announced, and what are the differences between national and European standards? Are there requirements for ADAS systems under national and European standards?
Liu Guoqing:
1. Different curvature radius tests are covered in ISO and JTT883. The difficulty of actual vehicle testing in this area is that the requirements for equipment are relatively high. Currently, quantitative tests are mainly conducted in controlled environments, so the difficulty is not high. We will also conduct road tests under various working conditions, but quantitative assessments are challenging; we will consider using more precise (but very expensive) testing equipment for assistance.
2. The situation of “driving in a straight lane with vehicles in the adjacent lane possibly causing false alarms” needs to be tested, and “driving on a circular track with adjacent vehicles possibly causing false alarms” also needs to be tested. These scenarios impact user experience significantly. However, such scenarios require high accuracy for lane recognition and self-motion estimation. Regarding the question of what false alarm rate is acceptable for mass production vehicles, different manufacturers have different standards.
3. There is not much difference between national standards, European standards, and ISO; there are some differences in test cases, and all of these can be downloaded online. I recommend studying them carefully; if you can’t find them, feel free to ask me, and I can send them to you.
New Series Course Coming Soon

Zhixiaodongxi, along with the course, continues to open applications for the “Autonomous Driving” community, which is still booming. Currently, the community has gathered hundreds of automotive companies and brands, including BAIC, SAIC, GAC, FAW, Hyundai, Ford, BYD, Geely, NIO, Chehejia, and hundreds of parts suppliers like Bosch, Continental, ZF, Hyundai Mobis, Lear, as well as over a thousand technical, business, research personnel, and entrepreneurs from over a hundred autonomous driving and intelligent driving technology R&D companies like Waymo, Baidu, Uber, Didi, NVIDIA, Intel. You can add Xiaoka WeChat (zhidxcdx) to apply.
Reply “autonomous driving” in Zhixiaodongxi to get audio and materials for the series.
#Bulletin# Following the public classes of DJI, Amazon, NVIDIA, JD, and UBTECH, the Gaode public class hosted by Zhixiaodongxi will be held this Saturday at 8 PM in the “Autonomous Driving” community for free. The head of the Gaode high-precision map team, Gu Xiaofeng, will give a lecture on “The Application of High-Precision Maps in Autonomous Driving.” Long press the QR code to apply to join the group and listen to the lecture together.

Join the Community
The three major travel industry communities of Zhixiaodongxi are now open for admission!
① Autonomous Driving ② New Energy ③ Shared Mobility
To join the group, please add the assistant’s WeChat chedx001
Extended Reading
Click the image/text below for direct reading
Travel Map
Li Bin | Liu Chuanzi | Baidu | Alibaba | Tencent | Foxconn | Gaode
In-Depth Features
Smart Rearview Mirror | Shared Bike Feast
New Car-Making Movement | Chinese Community of Silicon Valley Autonomous Driving | Car-Sharing
New Car-Making Movement
FMC | Youxia Automobile | Kaiyun Automobile | Qiantou Automobile | Weima Automobile | NIO Automobile
Autonomous Driving
Baidu | Zhixingzhe | Pony.ai | Vector.ai | Hesai
Chip Giants | NVIDIA | Intel | Chinese Community of Silicon Valley Autonomous Driving
Zhiche Road
Benz | BMW | Volkswagen | General Motors | Ford | Fiat Chrysler
Toyota | Honda | Renault-Nissan | Hyundai-Kia | Peugeot-Citroën | Volvo
Shared Mobility
Shared Electric Scooters | EZZY | The Death of Didi Express | The Dilemma of Yidao | Uber
Cutting-Edge Products
“Furious 8” | Audi A8 | Flying Cars | Hydrogen Fuel Vehicles | Tesla Model 3
