 Click the blue text to follow us
Click the blue text to follow us
In Greek mythology, Chimera is a gigantic fire-breathing hybrid creature composed of parts from different animals; it is now used to describe anything imaginative, incredible, or dazzling. Recently, I encountered the Chimera GPNPU (General Purpose Neural Processing Unit) from Quadric, and it truly lives up to its name.
Quadric was founded in 2017, initially planning to provide inference edge chips based on its new Chimera GPNPU architecture (chips for IoT “edge” inference applications). Their first chip was quickly validated, and some early users are already experimenting with it. However, Quadric recently decided to license the Chimera GPNPU as IP, showcasing their technology to a broader customer base.
The following diagram illustrates a simplified schematic of facial recognition and authentication using the Chimera GPNPU, which serves as our entry point to explore why the Chimera GPNPU is so “imaginative” and “dazzling”.
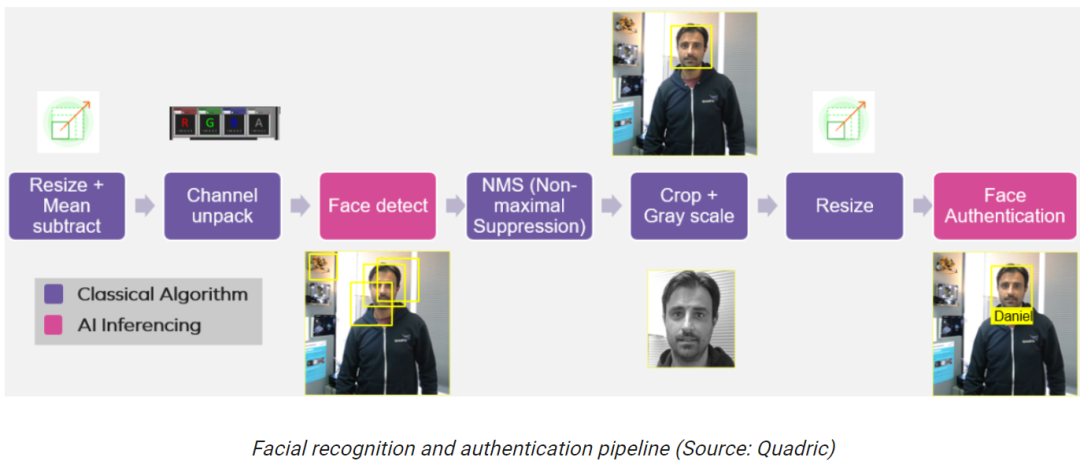
Assuming all these functions are implemented in a smart camera SoC, a camera/sensor provides a video stream to the first functional block on the left. This application is likely to be used in future generations of doorbell cameras.
Observe the two pink functional blocks labeled “Face Detect” and “Face Authentication”, which are implemented through AI/machine learning (AI/ML) inference. Over the past few years, this type of inference has developed rapidly, transitioning from academic research to early deployments, and has now become an essential element in software development.
Considering inference (based on visual, audio, etc.) as one of the building blocks for creating applications, we can think of this as “Software 2.0”. However, implementing this is not easy, and the traditional way SoC addresses the challenges of Software 2.0 is shown in (a).
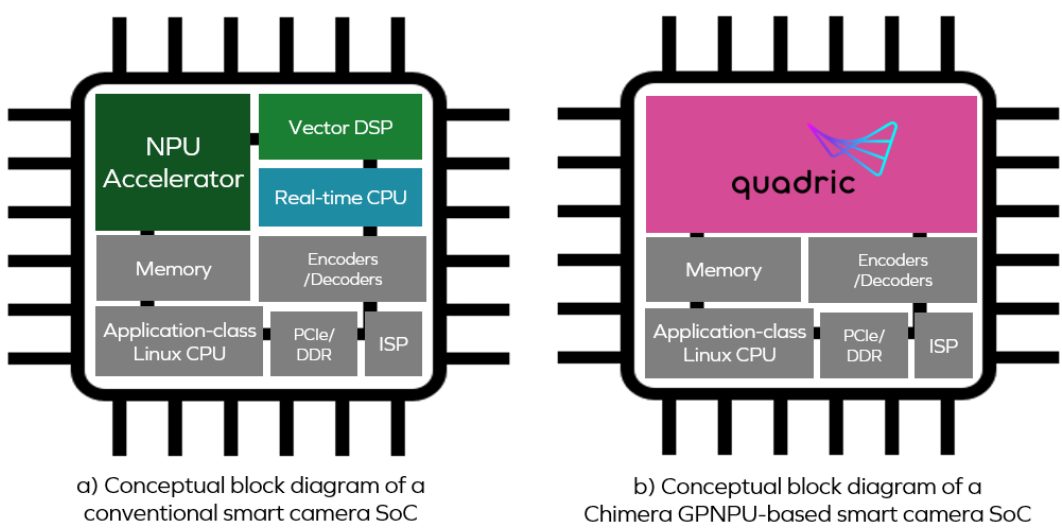
From the diagram in (a), we can see that the neural processing unit (NPU), vector digital signal processor (DSP), and real-time central processing unit (CPU) are three independent cores. To achieve the facial recognition and authentication process mentioned earlier, using conventional methods, the processing related to the first two functional blocks (Resize and Channel unpack) would be executed on the DSP core.
Then, the data generated by the DSP will be sent to the NPU core to run the neural network “Face Detect” model; the output from the NPU is then sent to the CPU core, which will run an “NMS” algorithm to determine which algorithm performs best.
Subsequently, the DSP will perform additional tasks on the image using the bounding boxes identified by the CPU, such as “Crop + Gray Scale” and “Resize”. Finally, this data will be sent to the NPU core to run the “Face Authenticate” model.
After implementing the above method, we may find that the desired throughput is not achieved. How can we identify where the performance bottleneck lies? Additionally, how much power is consumed during data exchange between the three cores?
The real potential issue is that having three independent processing cores complicates the entire design process. For instance, hardware designers must decide how much memory to allocate for each core and how large the buffers need to be between functional blocks. Meanwhile, software developers need to determine how to partition algorithms across the cores. This is painful because programmers are often reluctant to spend a lot of time considering the hardware details of the target platform they are working on.
Another issue is that ML models are rapidly evolving, and no one knows what ML models will look like in the coming years.
All these problems can lead to ML deployments not accelerating as quickly as possible, as developing for this type of conventional target platform is a very painful process in terms of programming, debugging, and performance tuning.
Returning to the Chimera GPNPU, it is represented by the pink area in the previous diagram (b). The GPNPU combines the attributes of DSP, CPU, and NPU into a single core, functioning as a traditional CPU/DSP combination that can run C/C++ code, featuring a complete 32-bit scalar + vector instruction set architecture (ISA), while also serving as an NN graph processor capable of running 8-bit inference-optimized ML code. This approach uniquely addresses the challenges of signal transmission by running two types of code on the same engine.
We can consider the Chimera GPNPU as a hybrid of the classic von Neumann RISC machine and a compressed array/2D matrix architecture.
One key advantage of the Chimera GPNPU is its ability to adapt to the evolving and increasingly complex ML networks. As things become more complex, more conditional control flows need to be implemented in the NN architecture, which can include CNN, RNN, DNN, etc. Traditional NPUs are typically hardwired accelerators that cannot execute conditionally. For example, a dedicated accelerator cannot pause at a certain point in layer 14 to check conditions or intermediate results, then branch and perform various control flow tasks. In these cases, data must be moved back and forth between the NPU and CPU, which impacts performance and power consumption. However, with a Chimera GPNPU, we can switch back and forth between NN and control code on a clock basis.
There is much more to discuss, such as the Chimera GPNPU‘s excellent performance in executing convolution layers (the core of CNN) and their TOPS (trillions of operations per second) ratings, which excite me greatly. I will not elaborate further here; interested readers can consult Quadric.
Finally, I would like to quickly outline the Quadric software development kit (SDK), as shown below.
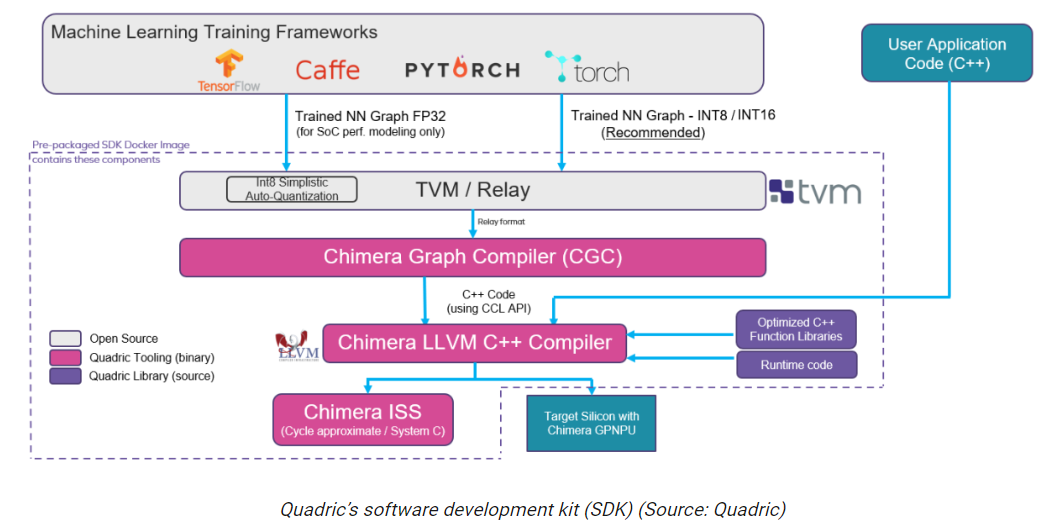
Ultimately, everything is driven by software. Trained neural network graphs/models generated using frameworks like TensorFlow, PyTorch, and Caffe are sent to Apache TVM (an open-source machine learning compiler framework for CPU, GPU, and ML accelerators), generating a Relay output (Relay is the high-level intermediate representation of the TVM framework).
The transformation and optimization of the relay representation are performed by Chimera CGC, which converts the transformed and optimized neural network into C++ code. The Chimera LLVM C++ Compiler merges this code with the developer’s C++ application code, resulting in an executable file that runs on the target silicon/SoC within the Chimera GPNPU.
Note that the Quadric SDK is delivered as a pre-packaged Docker image, which users can download and run on their systems. Quadric will soon host this SDK on Amazon Web Services (AWS), allowing users to access it through their web browsers.
What particularly interests me is that Quadric‘s team is developing a graphical user interface (GUI) that will allow developers to drag and drop pipeline building blocks containing CPU/DSP code and NPU models, stitching them together and compiling everything into a Chimera GPNPU image. This no-code development approach will enable a large number of developers to create chips containing Chimera GPNPU.
Original link:
https://www.eejournal.com/article/chimera-gpnpu-blends-cpu-dsp-and-npu-into-new-category-of-hybrid-processor
|
High-end WeChat Group Introduction |
|
|
Venture Capital Group |
AI, IoT, chip founders, investors, analysts, brokers |
|
Flash Memory Group |
Covering over 5000 global Chinese flash and storage chip elites |
|
Cloud Computing Group |
Discussions on all-flash, software-defined storage SDS, hyper-converged public and private clouds |
|
AI Chip Group |
Discussions on AI chips and heterogeneous computing with GPU, FPGA, CPU |
|
5G Group |
Discussions on IoT and 5G chips |
|
Third Generation Semiconductor Group |
Discussions on compound semiconductors like GaN and SiC |
|
Storage Chip Group |
Discussions on various storage media and controllers like DRAM, NAND, 3D XPoint |
|
Automotive Electronics Group |
Discussions on MCU, power supplies, sensors, etc. |
|
Optoelectronic Devices Group |
Discussions on optoelectronic devices like optical communication, lasers, ToF, AR, VCSEL |
|
Channel Group |
Storage and chip product quotes, market trends, channels, supply chains |

< Long press to recognize the QR code to add friends >
Join the above group chat
 Long press and follow
Long press and follow
Leading you into the new era of information revolution of storage, intelligence, and interconnectivity

WeChat ID: SSDFans