Source: Semiconductor Industry Observation

CPU Blueprint: ISA
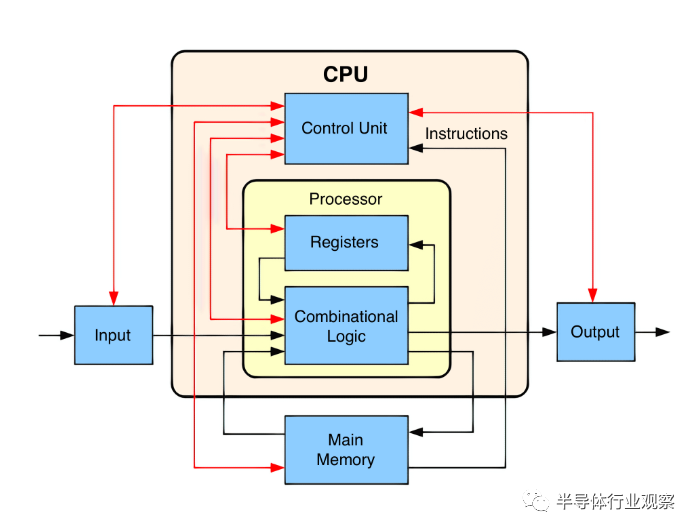
Control Unit and Data Path
Instruction Cycle – Fetch
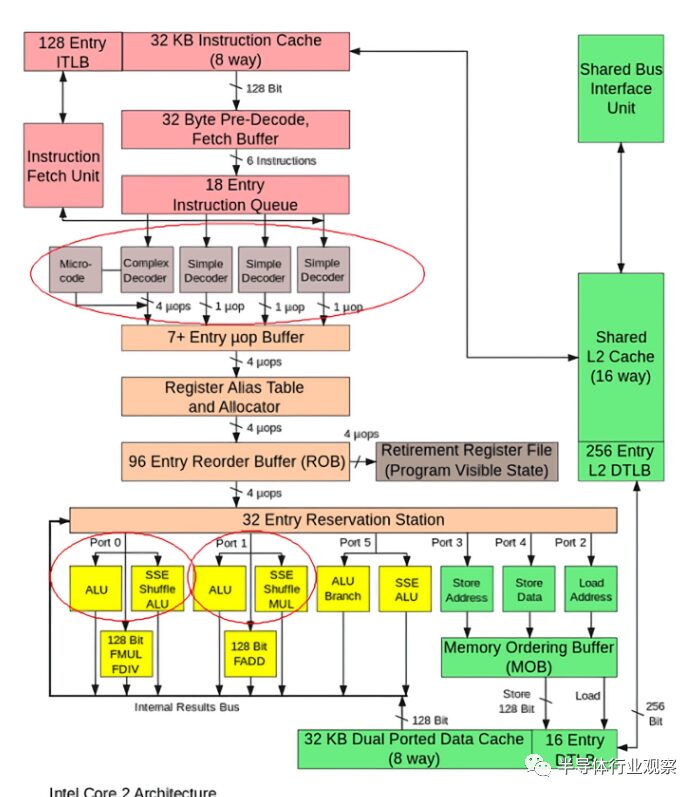
Instruction Cycle – Decode
Three Main Instruction Types
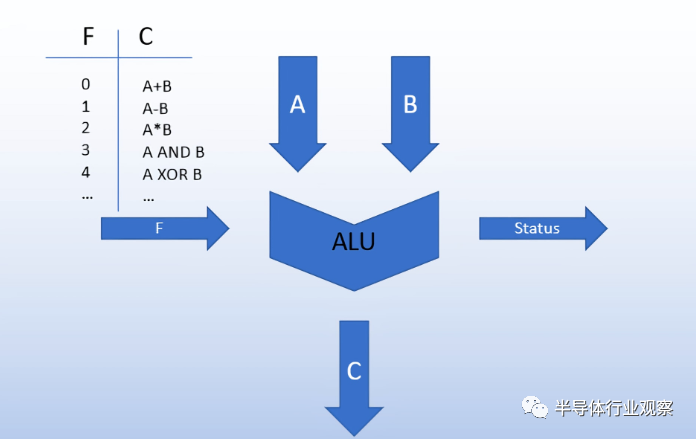
ALU
Memory Instructions and Hierarchy

Branch and Jump Instructions
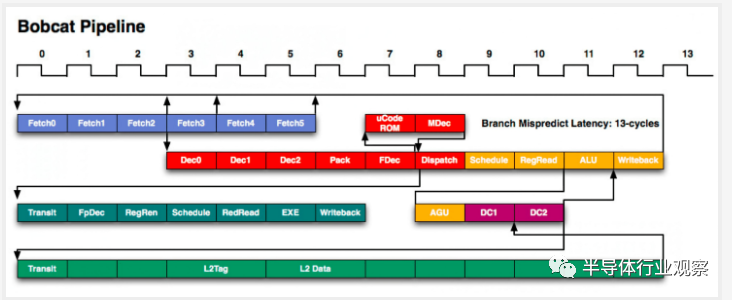
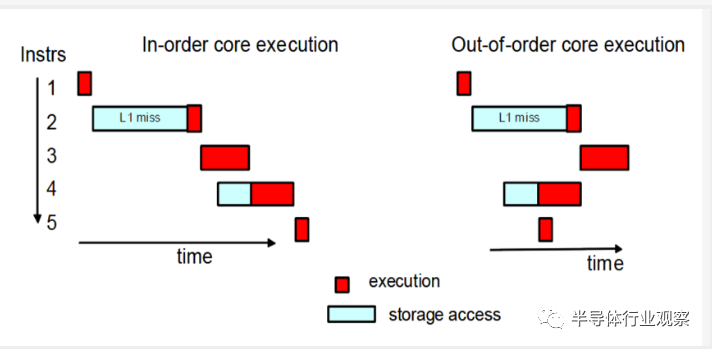
Out-of-Order Execution
Accelerators and the Future

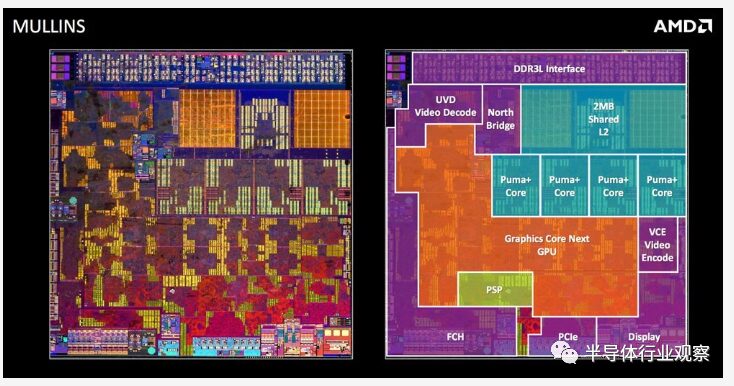
Moving to Multi-Core
Physical Design

Putting It All Together
Public Account ID:imecas_wx
