
Background
People are increasingly accustomed to using true wireless stereo (TWS) earphones for making and receiving calls. Wireless earbuds are not only lightweight but also allow users to engage in other activities while keeping their hands free. Additionally, enabling Active Noise Cancellation (ANC) during remote meetings is becoming a common practice.
Currently, earphone microphones are usually positioned at a certain angle behind the mouth, while sound waves radiate forward when people speak. As a result, the pickup effect of earphone microphones is often not as ideal as that of mobile phone microphones (which can be placed closer to the mouth). Moreover, due to the limited battery capacity and processing power of earphones, users find it difficult to achieve the same call quality as with mobile phone microphones when using TWS earphones.
Combining AI Methods with Microphone Arrays
To compensate for the amplitude attenuation caused by the forward radiation of voice signals (especially high-frequency components, which provide clear sound quality), dual-microphone arrays are often used to form spatially directional beams to enhance gain in specific directions while eliminating interference noise from other directions.
Considering different wearing angles of users, beamforming is an adaptive estimation process. This means that if the surrounding environment is noisy, the estimation error will increase. Therefore, to avoid eliminating the user’s voice, only residual dynamic noise from similar directions can be retained.
The emergence of machine learning algorithms breaks this limitation. Deep neural networks have strong nonlinear modeling capabilities and good recognition performance against dynamic noise interference, differing from traditional methods that use statistical signal analysis to distinguish noise from speech. However, constrained by the resources of the computational platform, the robustness and generalization ability of neural network models may be reduced after network pruning and quantization, potentially insufficient to cover all usage scenarios.
Combining adaptive beamforming and machine learning methods can enhance noise reduction performance, allowing the solution to better adapt in noisy environments. At the same time, beamforming can spatially filter out interference noise from the surrounding environment, thereby improving the signal-to-noise ratio (SNR) of the neural network input signal. Therefore, resource-limited models can also operate stably.
See the comparison below:

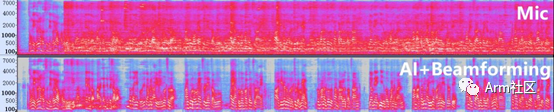
Figure 2: AI-Enhanced Dual-Microphone Solution
It can be seen that there are significant differences between Figure 2 and Figure 1. With the help of deep learning algorithms, we can more accurately distinguish between speech components and noise components, and supplement high-frequency harmonics to make the speech fuller and clearer.
Challenges of Deploying AI Voice Enhancement Technology at the Edge
There is a strong demand from headphone manufacturers to apply machine learning algorithms for voice enhancement. However, achieving AI voice enhancement on compact TWS earphones requires overcoming several major challenges.
First, AI algorithms require very complex computations, often involving a large number of matrix multiplications. During the architecture design phase, consideration must be given to how to maximize the efficiency of supported operators.
Secondly, while quantizing and pruning the model, it is essential to maintain the noise reduction performance and speech quality of the algorithm, adapting the neural network model to limited RAM memory.
Furthermore, the cost is high. Some products use dedicated digital signal processing (DSP) chips for AI voice enhancement processing. This configuration ensures sufficient performance for real-time processing of user speech. However, adding extra processing chips not only increases costs but also occupies valuable space on the earphones. Additionally, using a separate DSP increases system complexity, raising development investment.
Fourth, deploying real-time AI voice enhancement solutions on Bluetooth SoCs is more complex than running this process offline. System integration requires high investment and close cooperation between algorithm suppliers and chip manufacturers.
Finally, power management for terminal devices like TWS earphones is very strict. Adding or enhancing any functionality must meet power consumption requirements and not significantly impact battery life.
Solution: Arm Partners with Sound Plus Technology for Edge AI Voice Enhancement
Sound Plus Technology collaborates with Arm to optimize its AI voice enhancement algorithm (SVE-AI) for successful deployment on Arm’s Cortex-M4F and Cortex-M33 MCUs, achieving a balance between low power consumption and high performance.
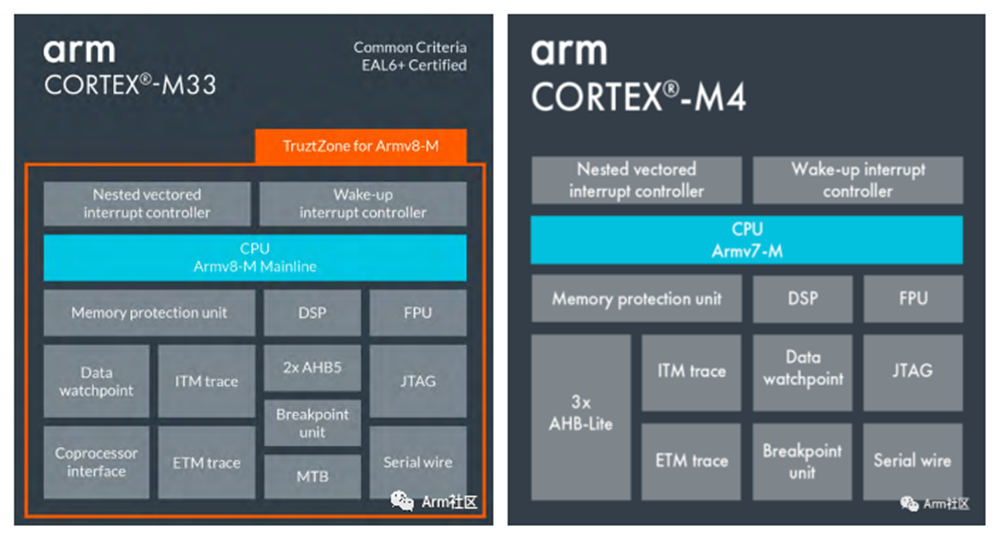
Figure 3: Arm Cortex-M33 and Arm Cortex-M4
Sound Plus Technology utilizes the instruction sets provided by Arm and integrates them with algorithm features to provide complete compatibility at the IP level. Even if hardware changes, as long as Arm IP and instruction sets are used, the SVE-AI solution provided by Sound Plus Technology can be deployed quickly. This greatly saves overall development time and effort, accelerating the product’s time to market.
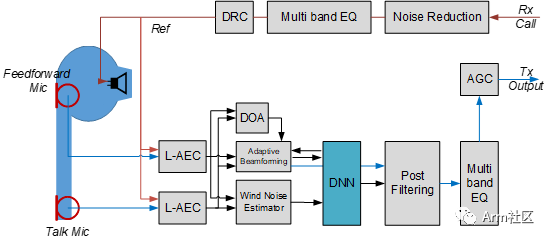
Figure 4: SVE-AI Dual-Microphone Solution Block Diagram
As shown in Figure 4, embedding the Deep Neural Network (DNN) module into the front-end solution plays a crucial role in the processing flow, improving the performance of each algorithm module. Some benefits include:
-
The DNN module provides more accurate sound wave arrival direction estimation performance, guiding beamforming.
-
The DNN module uses the processing results of beamforming and wind noise estimation as inputs to separate clear speech components and directional information.
-
The DNN module can also flexibly adjust the amount of noise reduction required for post-filtering.
In this collaboration, we first ensure that all computations are performed on the MCU to maintain system simplicity. Secondly, the AI voice enhancement model runs in real-time on the MCU. This step includes: model construction and adjustment, inference optimization, data compression (int8), and data flow management. Finally, Sound Plus Technology modifies the algorithm and processing flow on the MCU to fully utilize the resources provided by chips with different configurations, offering a range of voice enhancement models with different parameter sizes.
The SVE-AI solution has been adopted by mainstream mobile device brands and international audio brands for TWS earphone products, including those equipped with one to four microphones. The AI voice enhancement model effectively improves the speech quality of TWS earphones in dynamically interfering environments, achieving excellent S-MOS scores in objective tests and receiving positive feedback in subjective tests. Therefore, with the Arm MCU, TWS earphones can perform real-time dynamic noise suppression and high-quality voice enhancement at a sampling rate of 16KHz.
Looking to the Future
Sound Plus Technology is committed to continuous innovation and performance enhancement to expand its leading advantage in wearable device voice enhancement solutions. As Arm launches Cortex-M processors with strong AI computing capabilities, such as the Cortex-M55 and the new Ethos-U55 microNPU machine learning processor, Sound Plus Technology continues to collaborate with Arm to actively explore the advantages and performance improvements that larger-scale neural network models can bring at the edge.
We hope that the cooperation between Arm and Sound Plus Technology will help define the chipset specifications for wearable devices, wireless earphones, and mobile SoCs.
(The full text is reprinted from Arm Community)
About Sound Plus Technology
Sound Plus Technology was established in January 2018 and has successively passed the certification of high-tech enterprises in Zhongguancun and Beijing. Sound Plus Technology focuses on core communication acoustics technology, providing B-end customers with near-field, mid-field, and far-field voice interaction technology solutions in complex scenarios, as well as one-stop product solutions from chips, modules, PCBA to industrial design.
With over ten years of technical accumulation in the acoustic and speech fields by its founding team, its core technologies such as echo cancellation, noise suppression, sound source localization, reverberation elimination, beamforming, and voice wake-up have always been at the leading level in the industry. Partners include well-known companies such as Huawei, Xiaomi, OPPO, 1MORE, Goertek, Ecovacs, Harman, Anker, and dozens more. Over tens of millions of terminal devices have been authorized, providing leading solutions for communication products and smart wearable products like Huawei and Honor TWS earphones, Xiaomi TWS earphones, and Xiaomi outdoor Bluetooth speakers. In the future, Sound Plus Technology will also provide customers with various forms of products such as modules and chips, offering clearer, more comfortable, and freer user experiences for human-to-human communication and human-machine interaction, ultimately realizing the vision of complete human-machine integration.
To learn more, please visit the official website of Sound Plus Technology: http://www.soundiot.cn



