
Author: Shulan Technology
Source: www.jianshu.com/p/e47a766e03da
Introduction: As a developer, we often hear terms like HTTP protocol, TCP/IP protocol, UDP protocol, Socket, Socket long connection, Socket connection pool, etc. However, not everyone can clearly understand their relationships, differences, and principles. This article will start from the basics of network protocols and explain the relationship between them and Socket connection pools step by step.
Seven-Layer Network Model
Let’s start with the layered model of network communication: the seven-layer model, also known as the OSI (Open System Interconnection) model. From bottom to top, it is divided into: physical layer, data link layer, network layer, transport layer, session layer, presentation layer, and application layer. All communication-related aspects cannot be separated from it. The image below introduces some protocols and hardware corresponding to each layer.

From the above image, I know that the IP protocol corresponds to the network layer, the TCP and UDP protocols correspond to the transport layer, while the HTTP protocol corresponds to the application layer. The OSI model does not include Socket; so what is Socket? We will explain it in detail with code later.
TCP and UDP Connections
Regarding the transport layer, we may encounter TCP and UDP protocols more often. Some say TCP is secure, while UDP is not secure, and UDP transmission is faster than TCP. But why? Let’s first analyze the process of establishing a TCP connection and then explain the differences between UDP and TCP.
TCP’s Three-Way Handshake and Four-Way Teardown
We know that establishing a TCP connection requires three-way handshake, while disconnecting requires four-way teardown. What do the three-way handshake and four-way teardown do, and how are they carried out?
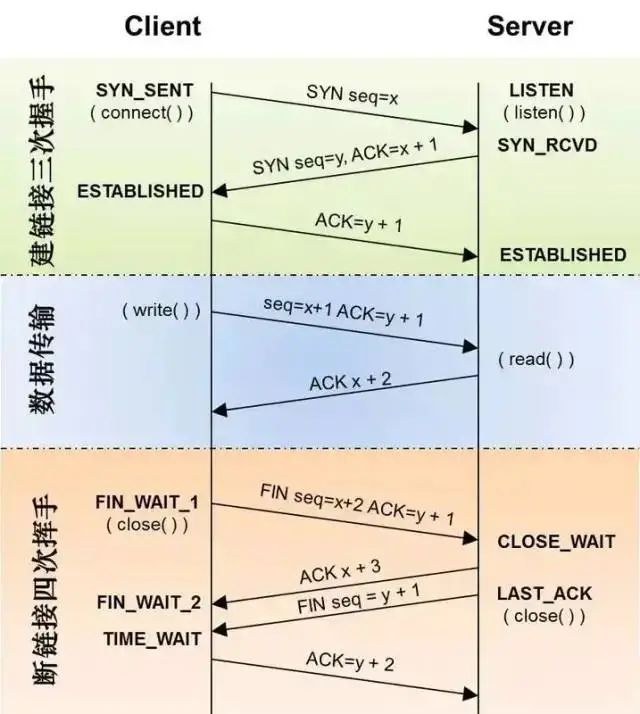
First Handshake: Establishing a connection. The client sends a connection request segment, setting SYN to 1 and the Sequence Number to x; then, the client enters the SYN_SEND state, waiting for the server’s confirmation;
Second Handshake: The server receives the client’s SYN segment and needs to confirm this SYN segment, setting the Acknowledgment Number to x+1 (Sequence Number + 1); at the same time, it must also send SYN request information, setting SYN to 1 and Sequence Number to y; the server combines all the above information into one segment (i.e., SYN+ACK segment) and sends it to the client, at which point the server enters the SYN_RECV state;
Third Handshake: The client receives the server’s SYN+ACK segment. It then sets the Acknowledgment Number to y+1 and sends an ACK segment to the server. After this segment is sent, both the client and server enter the ESTABLISHED state, completing the TCP three-way handshake.
After the three-way handshake is completed, the client and server can start transmitting data. This is the overall introduction to the TCP three-way handshake. When communication ends, the client and server disconnect, requiring four-way teardown confirmation.
First Teardown: Host 1 (which can be either the client or server) sets the Sequence Number and Acknowledgment Number and sends a FIN segment to Host 2; at this point, Host 1 enters the FIN_WAIT_1 state; this indicates that Host 1 has no data to send to Host 2;
Second Teardown: Host 2 receives the FIN segment sent by Host 1 and responds with an ACK segment, setting the Acknowledgment Number to the Sequence Number + 1; Host 1 enters the FIN_WAIT_2 state; Host 2 indicates to Host 1 that it “agrees” to the close request;
Third Teardown: Host 2 sends a FIN segment to Host 1, requesting to close the connection, and enters the LAST_ACK state;
Fourth Teardown: Host 1 receives the FIN segment sent by Host 2 and sends an ACK segment to Host 2, then Host 1 enters the TIME_WAIT state; after Host 2 receives Host 1’s ACK segment, it closes the connection; at this point, Host 1 waits for 2MSL, and if it does not receive a reply, it proves that the server has closed normally, then Host 1 can also close the connection.
We can see that establishing and closing a TCP request requires at least 7 communications, not including data communication, while UDP does not require three-way handshake and four-way teardown.
Differences Between TCP and UDP
-
TCP is connection-oriented. Although the insecure and unstable characteristics of the network mean that no number of handshakes can guarantee connection reliability, TCP’s three-way handshake at least ensures a minimum level of reliability (in fact, it guarantees reliability to a large extent). UDP, on the other hand, is connectionless; it does not establish a connection before transmitting data and does not send acknowledgment signals for received data. The sender does not know whether the data will be received correctly, and there is no need to retransmit, so UDP is a connectionless and unreliable data transmission protocol.
-
Due to the above characteristics, UDP has lower overhead and higher data transmission rates because it does not require confirmation of data transmission. Therefore, UDP has better real-time performance. Knowing the differences between TCP and UDP makes it easy to understand why file transfers using the TCP protocol in MSN are slower than those using UDP in QQ. However, this does not mean that QQ communication is insecure, as programmers can manually verify UDP data reception, such as numbering each data packet sent and having the receiver verify it. Even so, UDP achieves transmission efficiency that TCP cannot reach because it does not use a similar “three-way handshake” in its underlying protocol encapsulation.
Common Questions
We often hear some questions about the transport layer.
1. What is the maximum number of concurrent connections for a TCP server?
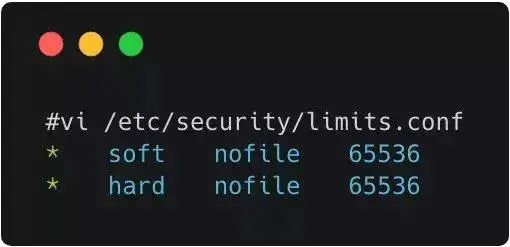
There is a misconception about the maximum number of concurrent connections for a TCP server: “Because the port number limit is 65535, the theoretical maximum number of concurrent connections for a TCP server is also 65535.” First, it is essential to understand the components of a TCP connection: client IP, client port, server IP, server port. Therefore, for a TCP server process, the number of clients it can connect to simultaneously is not limited by the available port number. Theoretically, a server’s port can establish connections equal to the number of global IPs multiplied by the number of ports per machine. The actual number of concurrent connections is limited by the number of open files in Linux, which can be configured to be very large, so it is ultimately limited by system performance. You can check the maximum number of file handles for services with #ulimit -n and modify it with ulimit -n xxx, where xxx is the desired number of open files. You can also modify system parameters:
2. Why does the TIME_WAIT state need to wait for 2MSL before returning to the CLOSED state?
This is because, although both parties agree to close the connection and the four handshake messages have been coordinated and sent, it appears that they can return to the CLOSED state directly (just like from SYN_SEND to ESTABLISH state); however, we must assume that the network is unreliable. You cannot guarantee that the last ACK message you send will be received by the other party. Therefore, the socket on the other party in the LAST_ACK state may resend the FIN message due to the timeout of not receiving the ACK message. Thus, the purpose of the TIME_WAIT state is to resend the potentially lost ACK message.
3. What problems can arise if the TIME_WAIT state needs to wait for 2MSL before returning to the CLOSED state?
After establishing a TCP connection, the party that actively closes the connection enters the TIME_WAIT state, which lasts for two MSL time periods, typically 1-4 minutes; Windows operating systems use 4 minutes. Generally, the client enters the TIME_WAIT state. A connection in the TIME_WAIT state occupies a local port. The maximum number of port numbers on a machine is 65536. If a stress test simulates thousands of client requests on the same machine and frequently establishes short connections with the server, this machine will generate about 4000 TIME_WAIT sockets, leading to “address already in use: connect” exceptions for subsequent short connections. If using Nginx as a reverse proxy, TIME_WAIT states must also be considered. If the system has a large number of TIME_WAIT connections, kernel parameters can be adjusted to resolve the issue.
Edit the file and add the following content:
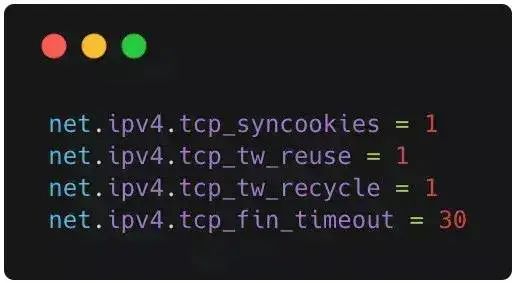
Then execute /sbin/sysctl -p to make the parameters take effect.
net.ipv4.tcp_syncookies = 1 means enabling SYN Cookies. When the SYN wait queue overflows, cookies are enabled to handle it, which can prevent a small number of SYN attacks. The default is 0, which means disabled;
net.ipv4.tcp_tw_reuse = 1 means enabling reuse. It allows TIME-WAIT sockets to be reused for new TCP connections; the default is 0, indicating disabled;
net.ipv4.tcp_tw_recycle = 1 means enabling fast recovery of TIME-WAIT sockets in TCP connections; the default is 0, indicating disabled.
net.ipv4.tcp_fin_timeout modifies the system’s default TIMEOUT time.
Socket Long Connection
A long connection refers to a TCP connection that can continuously send multiple data packets. During the duration of the TCP connection, if no data packets are sent, both parties need to send detection packets to maintain this connection (heartbeat packets), which generally need to be maintained online manually. A short connection refers to a situation where a TCP connection is established when there is data interaction, and after the data is sent, the TCP connection is disconnected. For example, HTTP connections are just connection, request, and close, which take a short time. If the server does not receive a request within a certain period, it can close the connection. In fact, a long connection is relative to a typical short connection, meaning that the client and server maintain a connection state for a long time.
The typical steps for short connection operations are:
Connect → Data Transmission → Close Connection;
While long connection typically involves:
Connect → Data Transmission → Maintain Connection (Heartbeat) → Data Transmission → Maintain Connection (Heartbeat) → … → Close Connection;
When to Use Long Connections vs. Short Connections?
Long connections are often used in scenarios where operations are frequent and point-to-point communication is required, and the number of connections cannot be too high. Each TCP connection requires three-way handshake, which takes time. If every operation involves connecting and then operating, the processing speed will significantly decrease. Therefore, after each operation, the connection is not closed, and during the next operation, data packets can be sent directly without establishing a TCP connection. For example, database connections use long connections; if short connections are frequently used for communication, it can cause Socket errors, and frequently creating Sockets also wastes resources.
What are Heartbeat Packets and Why are They Needed?
Heartbeat packets are user-defined command words that periodically notify the status of both the client and server to each other, sent at regular intervals, similar to a heartbeat, hence the name. Data reception and transmission in the network are implemented using Sockets. However, if the socket is already disconnected (for example, one party loses internet connection), there will definitely be issues when sending and receiving data. But how can we determine if this socket is still usable? This requires creating a heartbeat mechanism in the system. In fact, TCP already has a built-in heartbeat mechanism for us. If you set a heartbeat, TCP will send the specified number of heartbeats (for example, 2 times) within a certain time (for example, every 3 seconds), and this information will not affect your user-defined protocol. You can also define your own; the so-called “heartbeat” is to periodically send a user-defined structure (heartbeat packet or heartbeat frame) to let the other party know that you are “online” to ensure the validity of the link.
Implementation:
Server:
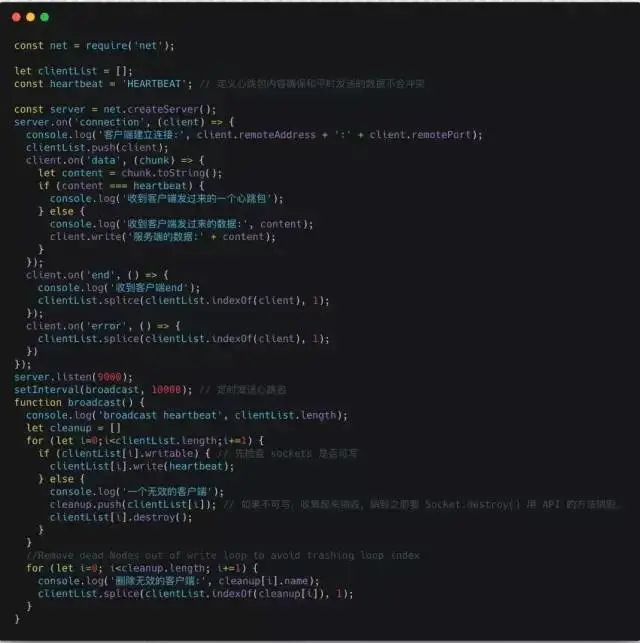
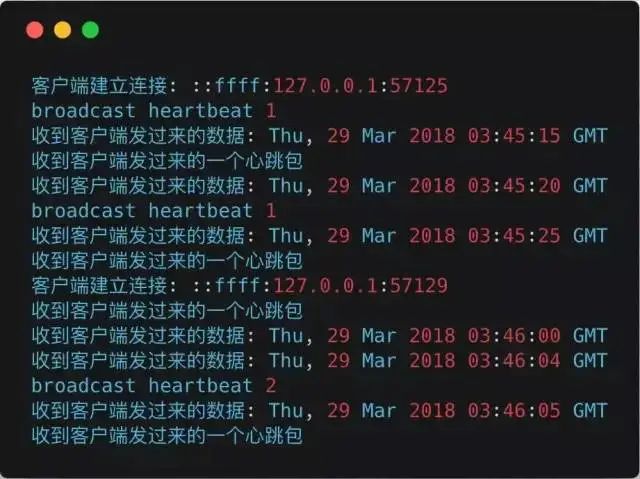
Server Output:
Client Code:
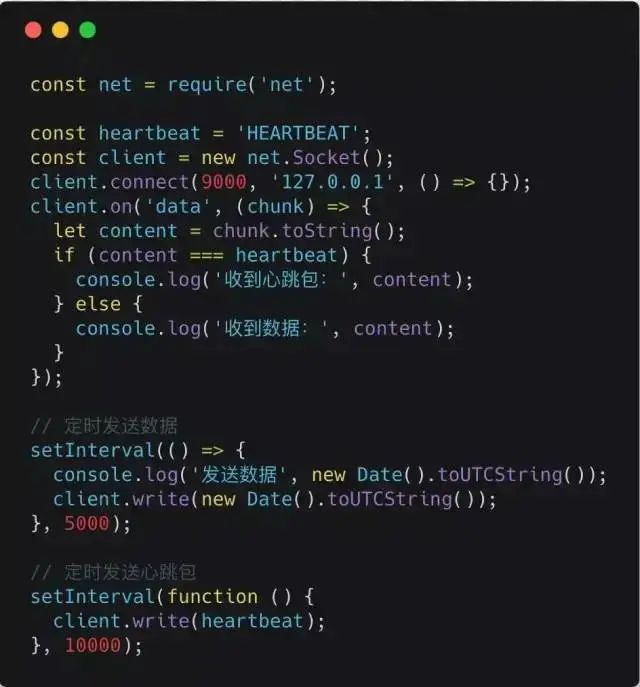
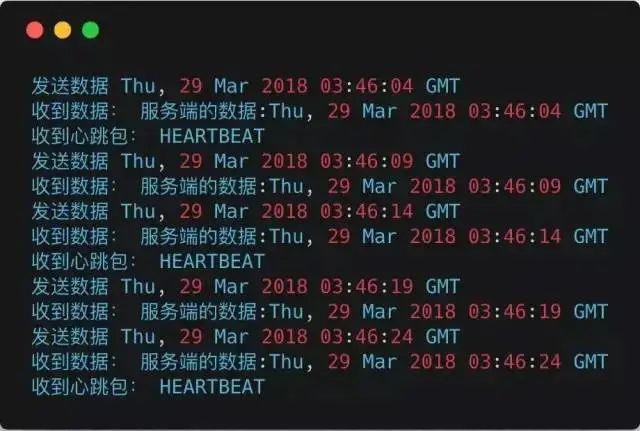
Client Output:
Defining Your Own Protocol
To make the transmitted data meaningful, it is necessary to use application layer protocols such as HTTP, MQTT, Dubbo, etc. Customizing your own application layer protocol based on TCP requires addressing several issues:
-
Definition and handling of heartbeat packet formats
-
Definition of the message header, which means you need to send a message header when sending data so that the message can parse the length of the data you are about to send
-
Format of the data packets you send, whether it is JSON or another serialization method
Now let’s define our own protocol and write services to call the client:
Define message header format: length:000000000xxxx; xxxx represents the length of the data, total length 20, the example is not rigorous.
Data serialization method: JSON.
Server:
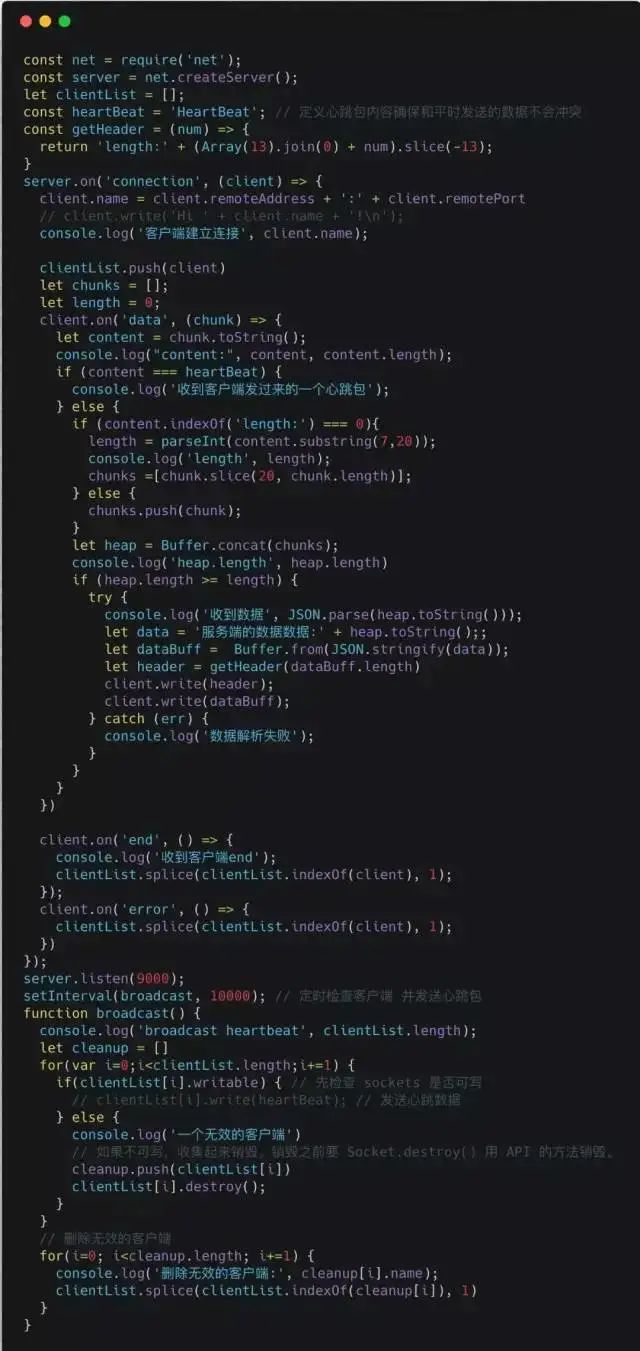
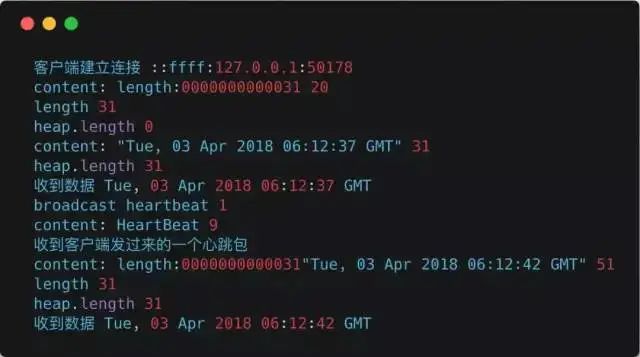
Log Output:
Client:
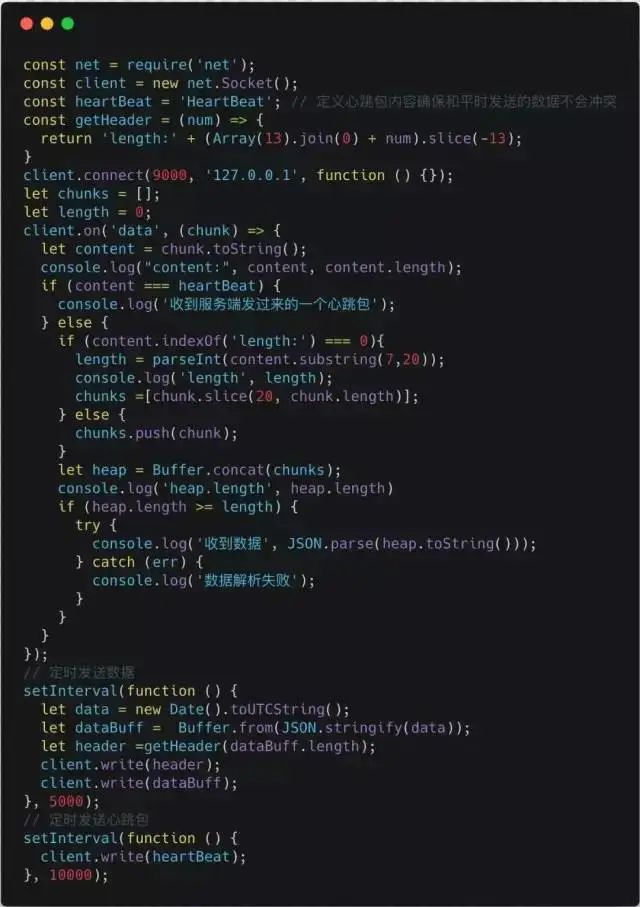
Log Output:
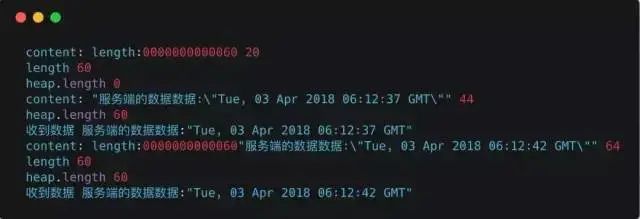
Here we can see that a client can handle a request well at the same time, but imagine a scenario where the same client makes multiple service requests simultaneously, sending multiple header data and content data. The data received by the server’s data event may be challenging to distinguish which data corresponds to which request. For example, if two header data arrive at the server simultaneously, the server may ignore one of them, and the subsequent content data may not necessarily correspond to this header. Therefore, to reuse long connections and handle server requests with high concurrency effectively, a connection pool is needed.
Socket Connection Pool
What is a Socket connection pool? The concept of a pool can be thought of as a collection of resources, so a Socket connection pool is a collection that maintains a certain number of Socket long connections. It can automatically detect the validity of Socket long connections, eliminate invalid connections, and supplement the number of long connections in the connection pool. From the code perspective, this function is generally implemented by a class, and a connection pool typically includes the following attributes:
-
A queue of idle available long connections
-
A queue of long connections that are currently running
-
A queue of requests waiting to acquire an idle long connection
-
The function to eliminate invalid long connections
-
The configuration of the number of long connection resources in the pool
-
The function to create new long connection resources
Scenario: When a request comes in, it first requests a long connection resource from the resource pool. If there is a long connection in the idle queue, it acquires that long connection Socket and moves it to the queue of currently running long connections. If there is no long connection in the idle queue, and the length of the running queue is less than the configured number of connection pool resources, a new long connection is created and added to the running queue. If the number of running connections is not less than the configured length of the resource pool, the request enters the waiting queue. When a running Socket completes a request, it is moved from the running queue to the idle queue and triggers the waiting request queue to acquire idle resources if there are any waiting requests.
Below is a brief introduction to a generic connection pool module in Node.js: generic-pool.
Main file directory structure:
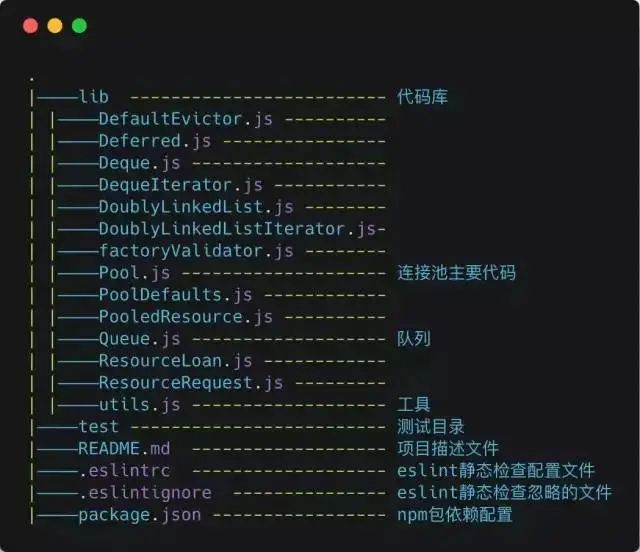
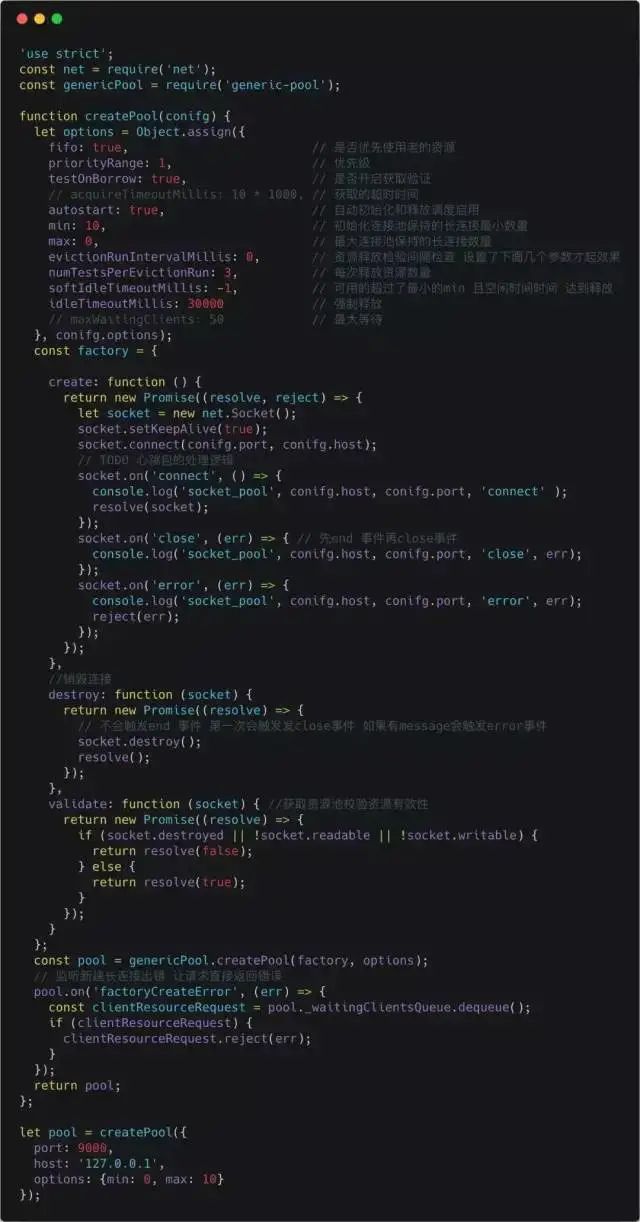
Initializing the Connection Pool
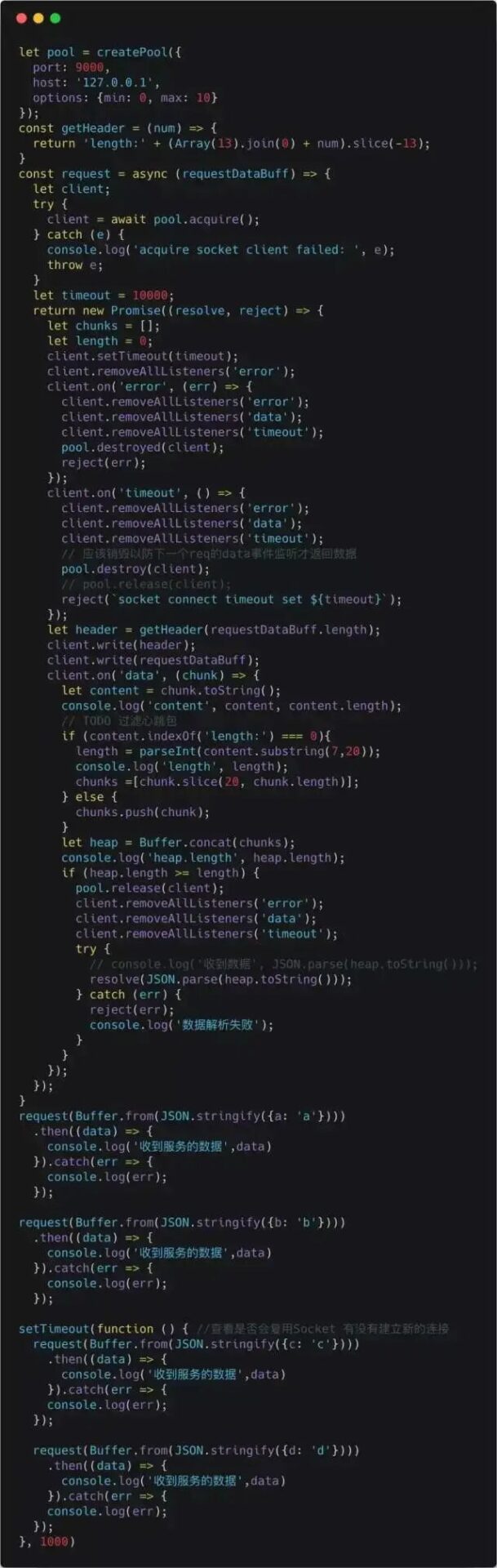
Using the Connection Pool
Below is the usage of the connection pool, and the protocol used is the one we previously defined.
Log Output:
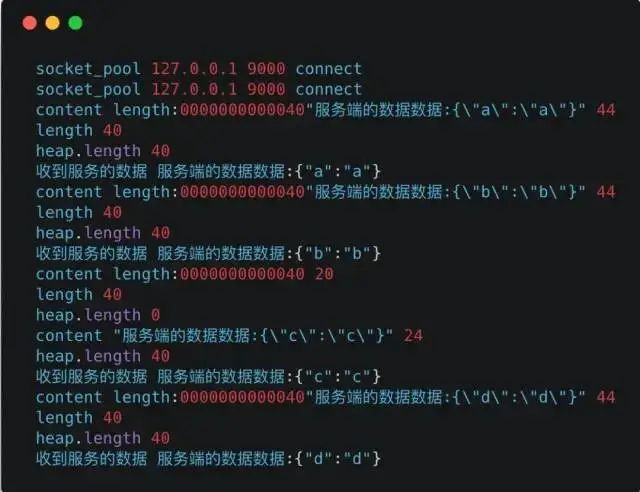
Here we see that the first two requests established new Socket connections socket_pool 127.0.0.1 9000 connect. After the timer ends, when two requests are initiated again, no new Socket connections are established; instead, they directly acquire Socket connection resources from the connection pool.
Source Code Analysis
The main code is located in the Pool.js constructor in the lib folder: lib/Pool.js
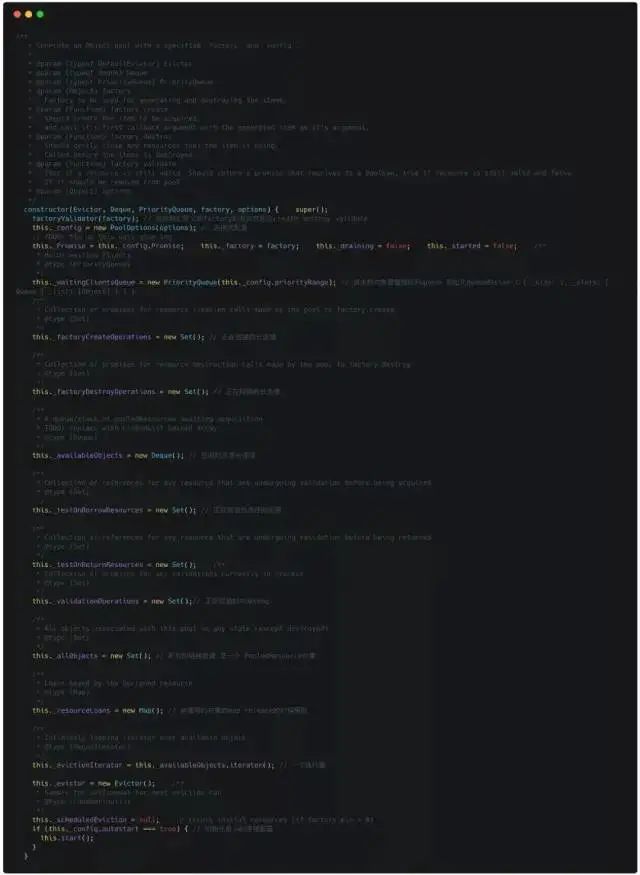
You can see that it includes the idle resource queue, the queue of resources being requested, the queue of requests waiting, etc.
Next, let’s look at the Pool.acquire method:
lib/Pool.js
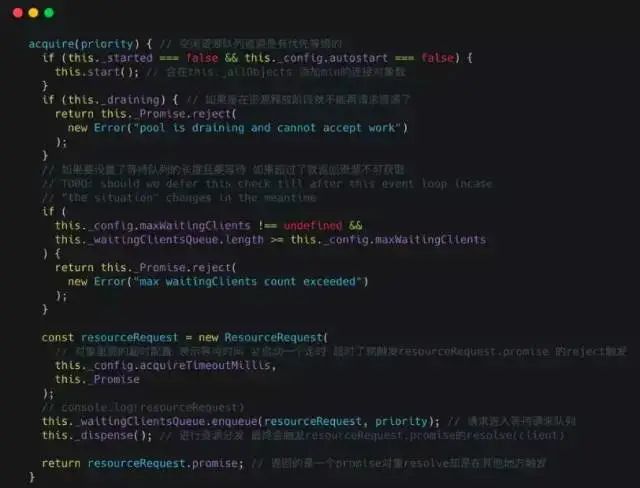
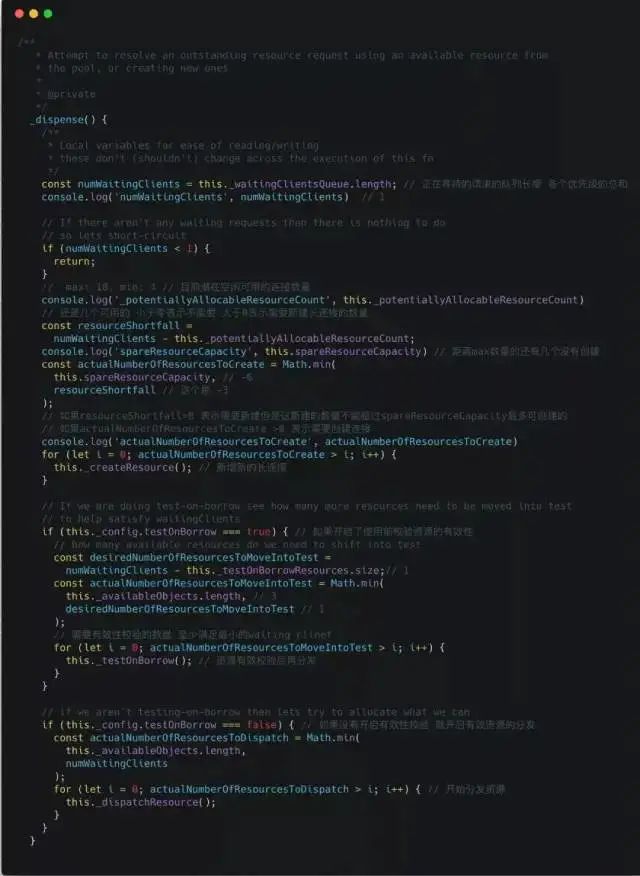
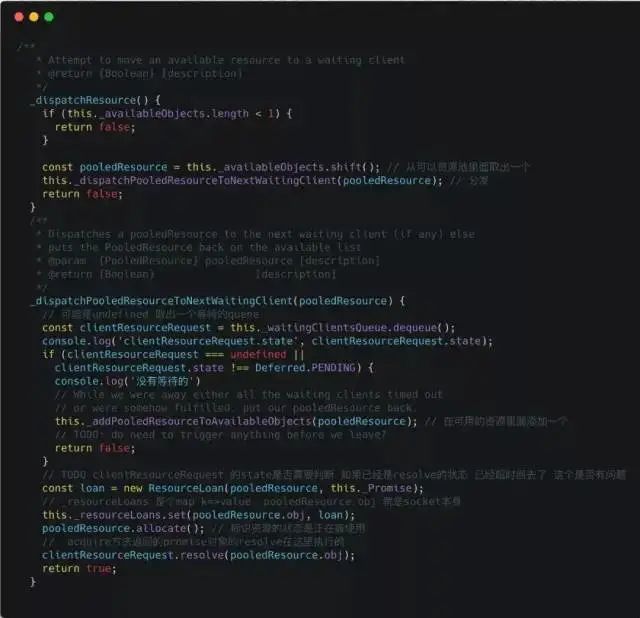
The above code continuously checks the situation until it ultimately acquires a long connection resource. For more code, everyone can explore further.