
Original Author: Chaobowx
Editor’s Note
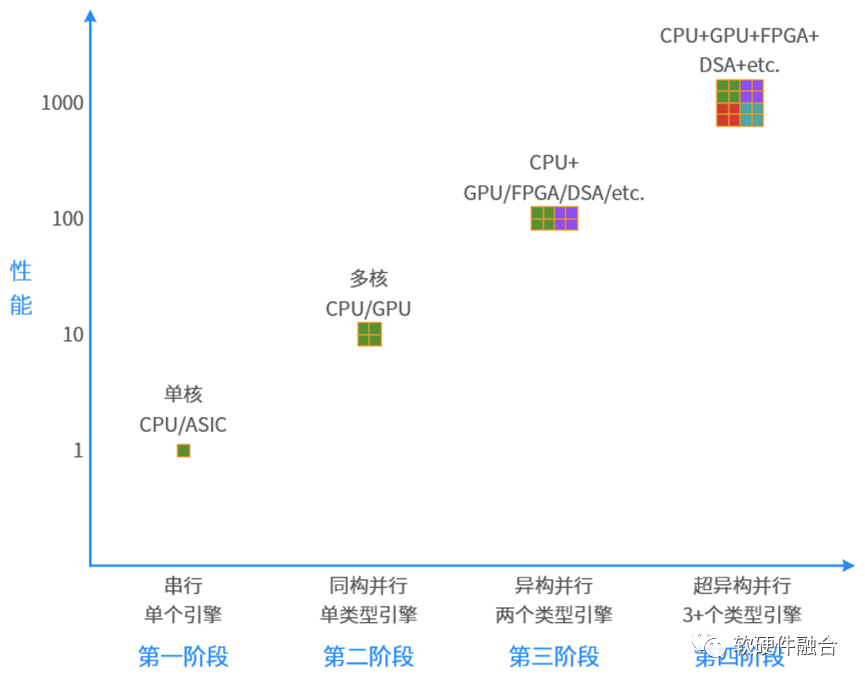
Reviewing the history of computer development, from serial to parallel, from homogeneous to heterogeneous, it will continue to evolve to ultra-heterogeneous:
-
First Stage: Serial Computing. Single-core CPUs and ASICs belong to serial computing.
-
Second Stage: Homogeneous Parallel Computing. Multi-core CPUs and GPUs with thousands of cores belong to homogeneous parallel computing.
-
Third Stage: Heterogeneous Parallel Computing. CPU+GPU, CPU+FPGA, CPU+DSA, and SoCs all belong to heterogeneous parallel computing. (SoCs are heterogeneous because the processing of all other engines is under the control of the CPU, making direct data communication between other engines difficult.)
-
In the future, we will move towards the fourth stage, ultra-heterogeneous parallel stage. This will involve the organic integration of numerous CPUs and xPUs to form ultra-heterogeneous systems.
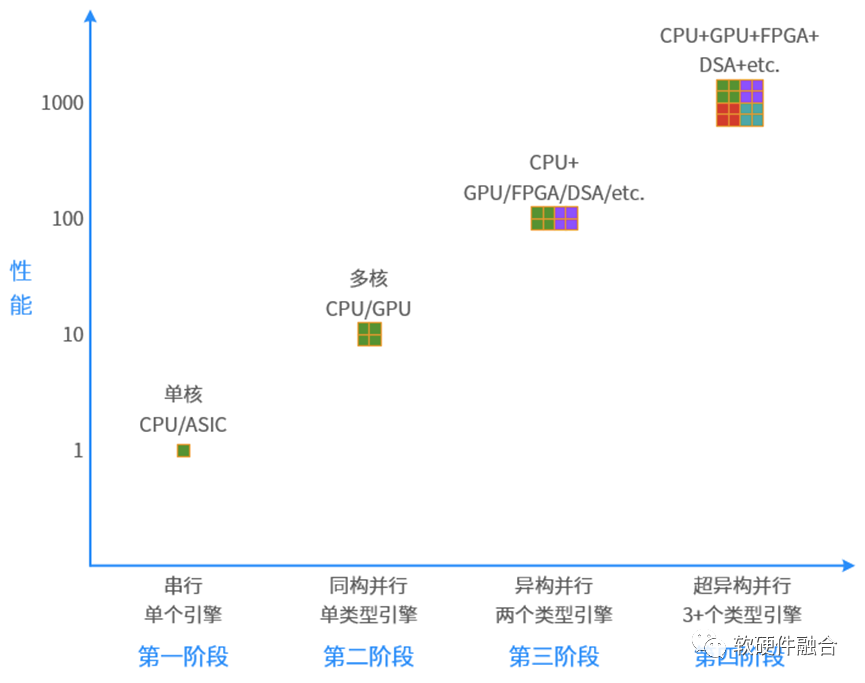
1 Review of History: From Serial to Parallel Computing
1.1 Serial Computing and Parallel Computing
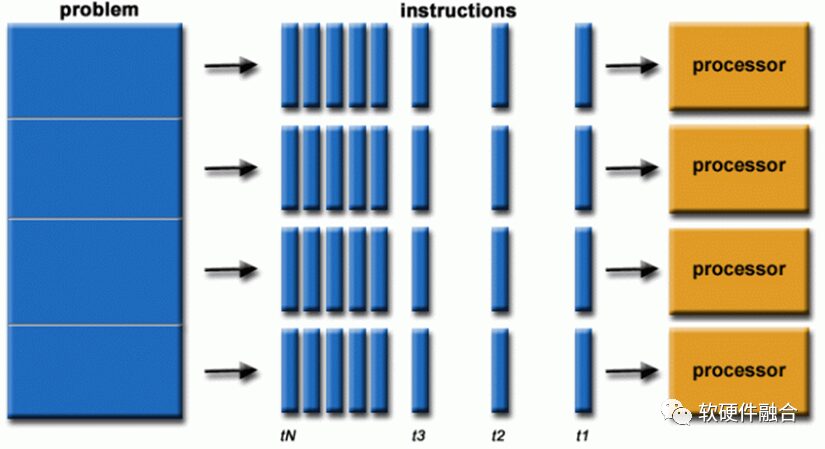
Software is generally written for serial computing:
-
A problem is decomposed into a set of instruction streams;
-
Executed on a single processor;
-
Instructions are executed sequentially (there may be non-dependent instruction reordering within the processor, but the macro effect remains the execution of a serial instruction stream).
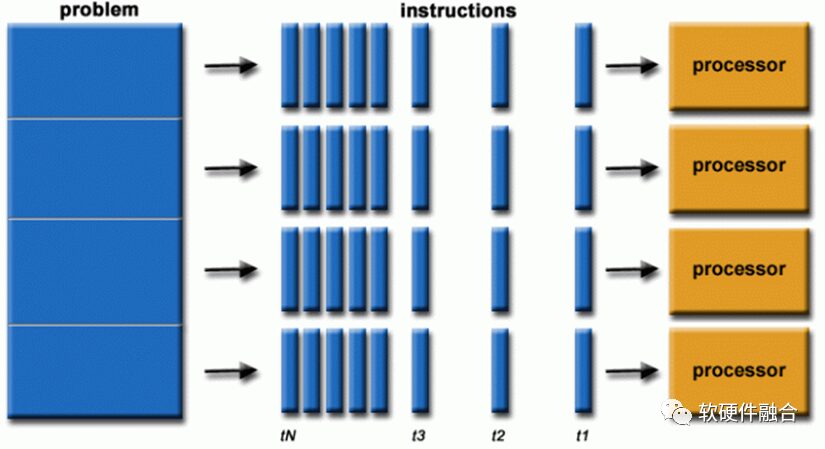
Parallel computing uses multiple computing resources simultaneously to solve a computational problem:
-
A problem is decomposed into parts that can be solved concurrently;
-
Each part is further decomposed into a series of instructions;
-
Instructions for each part are executed simultaneously on different processors;
-
A global control/coordination mechanism is required.
Computational problems should be able to: be decomposed into discrete tasks that can be solved concurrently; execute multiple program instructions at any time; and use multiple computing resources to solve problems in a shorter time than using a single resource.
Computational resources are typically: a single computer with multiple processors/cores; any number of such computers connected via a network (or bus).
1.2 Multi-Core CPUs and Many-Core GPUs
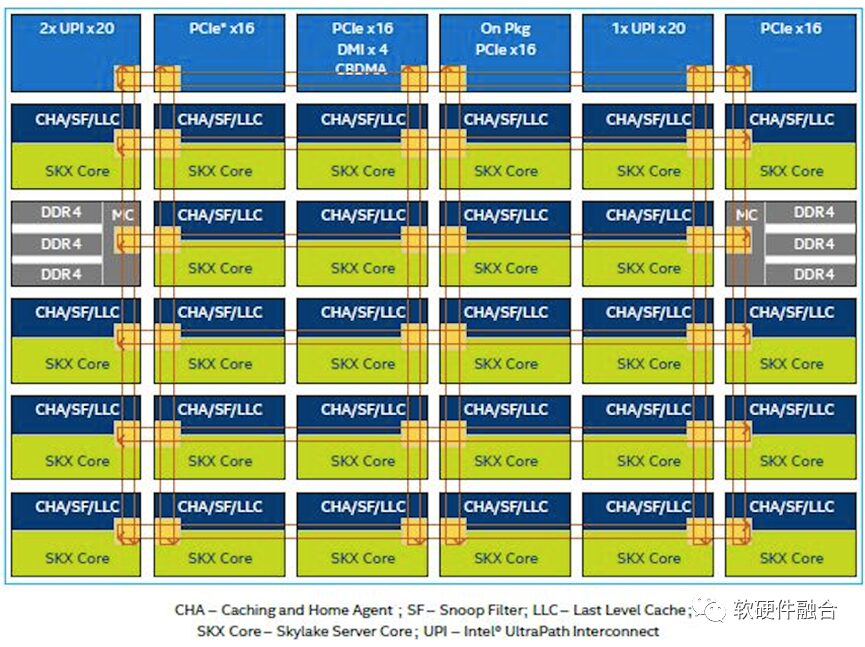
The above image shows the internal architecture of the Intel Xeon Skylake. This CPU consists of 28 CPU cores and represents homogeneous parallelism.
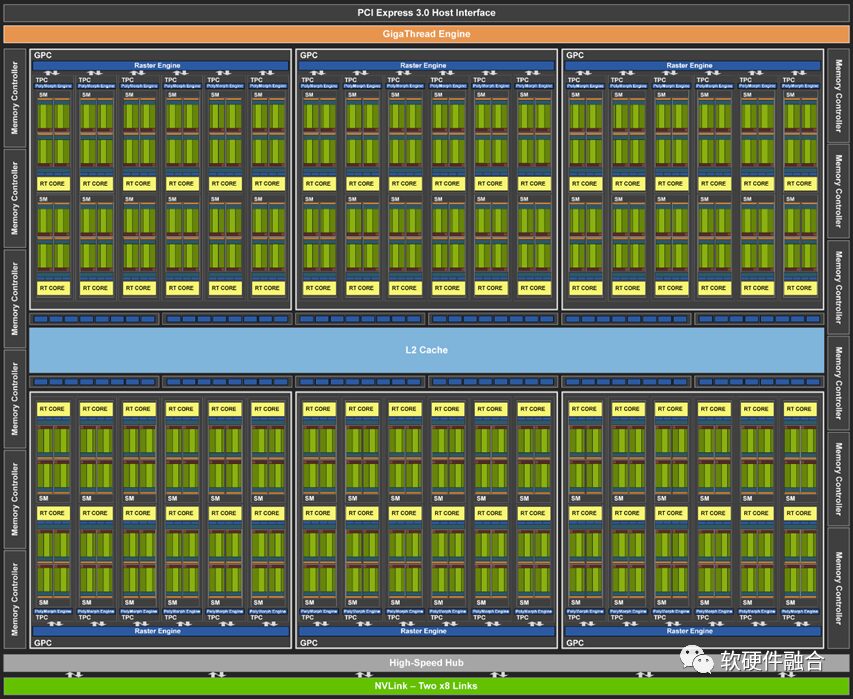
The above image shows the Turing architecture GPU released by NVIDIA. The core processing engine of this architecture consists of: 6 Graphics Processing Clusters (GPCs); each GPC has 6 Texture Processing Clusters (TPCs), totaling 36 TPCs; each TPC has 2 Streaming Multiprocessors (SMs), totaling 72 SMs. Each SM consists of 64 CUDA cores, 8 Tensor cores, 1 RT core, and 4 texture units.
Therefore, the Turing architecture GPU has a total of 4608 CUDA cores, 576 Tensor cores, 72 RT cores, and 288 texture units.
It should be noted that: GPUs are not Turing complete and cannot operate independently; they must work in conjunction with CPUs through a CPU+GPU heterogeneous approach.
2 From Homogeneous Parallelism to Heterogeneous Parallelism: The Booming Development of Heterogeneous Computing
2.1 Homogeneous Parallelism and Heterogeneous Parallelism

As mentioned in the previous section, because the CPU is Turing complete and can operate independently, there exist CPU chips composed of multi-core CPUs that represent homogeneous parallelism.
However, there are no parallel computing systems composed solely of other processing engines like GPUs, FPGAs, DSAs, or ASICs, as these engines are not Turing complete and exist as accelerators to the CPU. Therefore, the parallel computing systems of other processing engines are heterogeneous parallelism of the form CPU+xPU, which can be roughly divided into three categories:
-
CPU+GPU. CPU+GPU is currently the most popular heterogeneous computing system, widely used in HPC, graphics processing, and AI training/inference scenarios.
-
CPU+FPGA. Currently popular in data center FaaS services, utilizing the local programmability of FPGAs, developing runtime frameworks based on FPGAs, and constructing FPGA acceleration solutions for various application scenarios with third-party ISV support or self-research.
-
CPU+DSA. Google TPU is the first DSA architecture processor, with TPUv1 adopting an independent accelerator approach to achieve heterogeneous parallelism of CPU+DSA (TPU).
Additionally, it should be noted that due to the fixed functionality of ASICs, they lack a certain degree of flexible adaptability; thus, there is no heterogeneous computing of the form CPU+single ASIC. The CPU+ASIC form typically consists of CPU+multiple ASICs or exists as a logically independent heterogeneous subsystem within an SoC, requiring collaboration with other subsystems.

An SoC is essentially also heterogeneous parallelism; it can be seen as a system composed of various heterogeneous parallel subsystems such as CPU+GPU, CPU+ISP, and CPU+Modem.
Ultra-heterogeneous can also be seen as a new system organically composed of multiple logically independent heterogeneous subsystems, but SoCs and ultra-heterogeneous differ: the different modules of an SoC usually cannot communicate directly at a high level, but must do so indirectly through CPU scheduling. The differences between SoCs and ultra-heterogeneous will be discussed in detail in the ultra-heterogeneous section.
2.2 Heterogeneous Parallelism Based on CPU+GPU
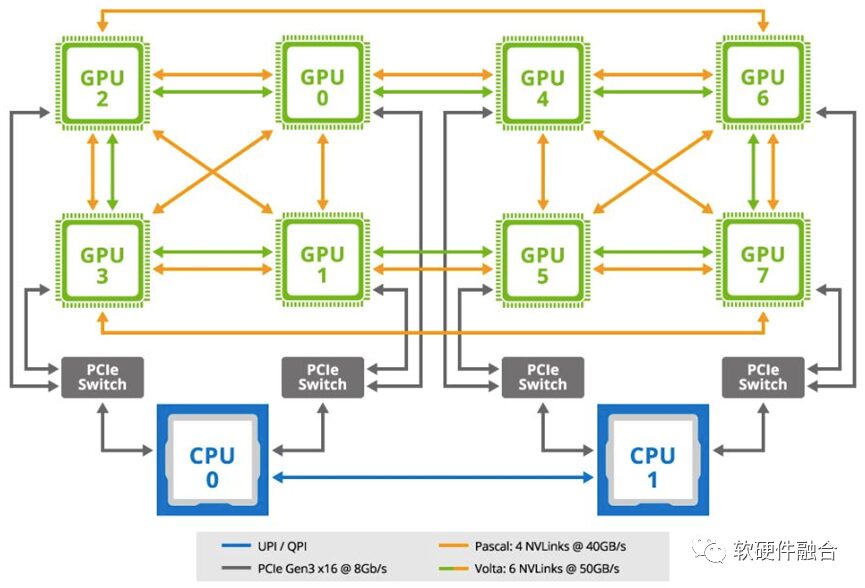
The image shows a typical GPU server motherboard topology used in machine learning scenarios, representing a typical SOB (System on Board). In this GPU server architecture, two general-purpose CPUs and eight GPU accelerator cards are connected through the motherboard. The two CPUs are connected via UPI/QPI; each CPU connects to a PCIe switch through two PCIe buses; each PCIe switch connects to two GPUs; additionally, the GPUs are interconnected through NVLink buses.
2.3 Heterogeneous Parallelism Based on CPU+DSA
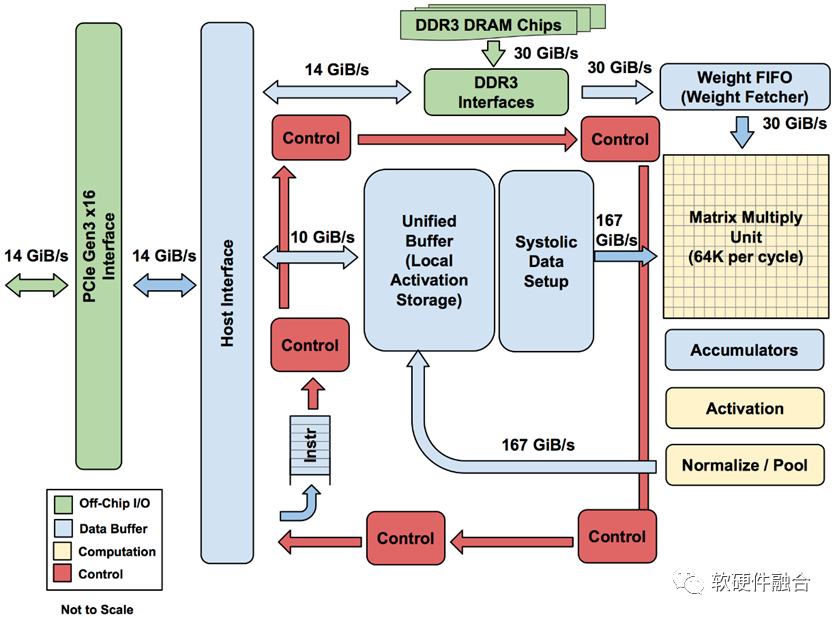
TPU is the first DSA architecture chip in the industry, and the image above shows the structural diagram of TPU v1. TPU v1 connects to the CPU via PCIe Gen3 x16 bus, sending instructions from the CPU to the TPU’s instruction buffer, with the CPU controlling the TPU’s operation; data interaction occurs between their memories, initiated by the CPU, with the TPU’s DMA executing the actual data transfer.
3 Evolving from Heterogeneous to Ultra-Heterogeneous
3.1 Common Challenges Faced by High-Performance Chips like CPU, GPU, DPU, and AI
In complex computing scenarios such as cloud computing, edge computing, and terminal supercomputers (e.g., autonomous driving), the requirements for chip programmability are very high, even surpassing performance requirements. If not for the failure of Moore’s Law based on CPUs, data centers would still be dominated by CPUs (although the performance efficiency of CPUs is the lowest).
Performance and flexible programmability are two very important factors affecting the large-scale deployment of high-performance chips. How to balance both, or even accommodate them, is an eternal topic in chip design.
High-performance chips like CPUs, GPUs, DPUs, and AI face common challenges, including:
-
The contradiction between performance and flexibility of single-type engines. CPUs are flexible but lack sufficient performance; ASICs have extreme performance but lack flexibility.
-
Business differences among different users and the iteration of user business. The current main approach is scene customization. Customizing through FPGAs is too small-scale, with high costs and power consumption; customizing chips leads to fragmented scenarios, making large-scale deployment difficult and hard to amortize costs.
-
Macro computing requires that chips can support large-scale deployment. Macro computing is proportional to the unit chip computing power and the scale of chip deployment. However, various performance enhancement solutions may sacrifice programmability, making it difficult for chips to achieve large-scale deployment, further affecting the growth of macro computing. A typical example is the current difficulty in the large-scale deployment of AI chips.
-
The one-time cost of chips is too high. Hundreds of millions in NRE costs require large-scale deployment of chips to amortize the one-time costs. This necessitates that chips be sufficiently “general-purpose” to be deployed in many scenarios.
-
The threshold for ecosystem building. Large chips require frameworks and ecosystems, which have high thresholds and require long-term accumulation, making it difficult for small companies to invest heavily over the long term.
-
Integration of computing platforms. The integration of cloud, network, edge, and terminal requires the construction of a unified hardware platform and system stack.
-
And so on.
3.2 Solutions: Connecting the Islands of Heterogeneous Computing to Form Ultra-Heterogeneous
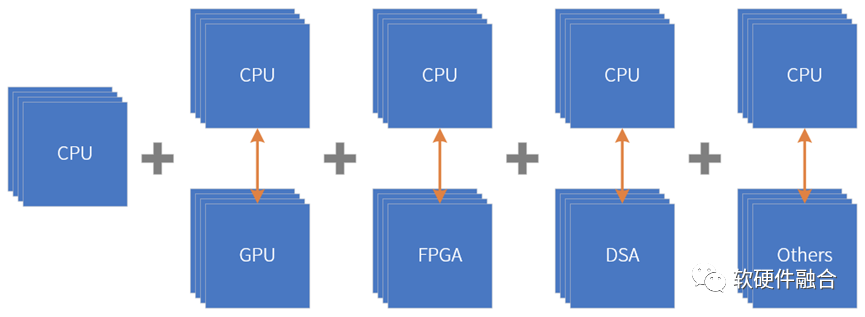
Ultra-heterogeneous can be seen as an organic combination of homogeneous parallelism of CPU+CPU and heterogeneous parallelism of CPU+other xPUs, forming a new super-large system.
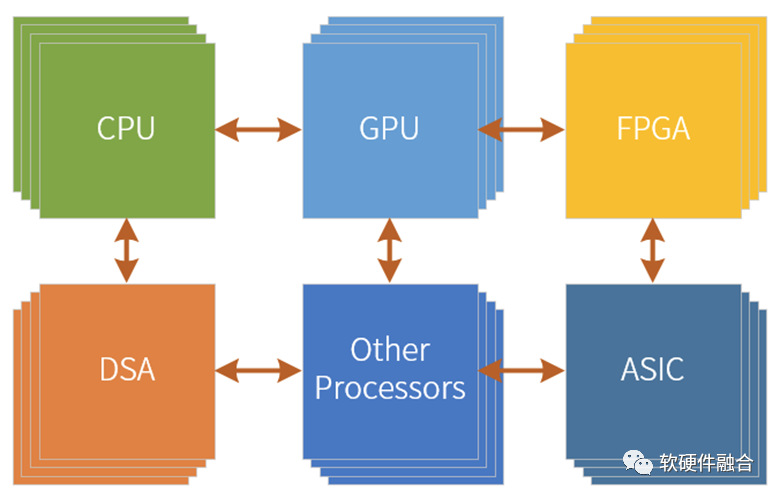
Ultra-heterogeneous is a new macro system organically composed of CPUs, GPUs, FPGAs, DSAs, ASICs, and various other acceleration engines.
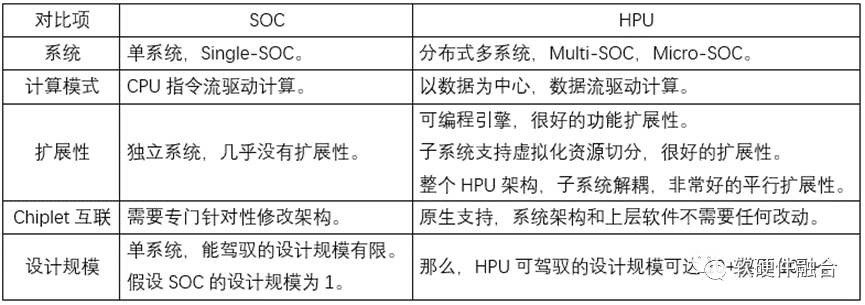
3.3 Differences Between Ultra-Heterogeneous and SoC
The ultra-heterogeneous processor (HPU) can be considered an SoC, but it differs significantly from traditional SoCs. If these differences are not recognized, the essence of HPU cannot be understood. The table below shows some typical comparative differences.
4 Why Now? (The Rise of Ultra-Heterogeneous Computing)
4.1 The Failure of Moore’s Law Based on CPU Triggers a Chain Reaction
Systems are becoming increasingly complex, requiring the selection of more flexible processors; meanwhile, performance challenges are growing, necessitating the choice of customized accelerated processors. This creates a contradiction that pulls at our various computing chip designs.The essence of the contradiction is that a single processor cannot balance performance and flexibility; even if we strive to achieve balance, it only addresses the symptoms, not the root cause.
CPUs are highly flexible and, when meeting performance requirements, are the optimal processors in complex computing scenarios such as cloud computing and edge computing. However, due to the performance bottlenecks of CPUs and the continuously rising demand for computing power, (from a computing perspective) CPUs are gradually becoming non-mainstream computing chips.
The heterogeneous computing of CPU+xPU, where the main computing power is completed by xPUs, thus determines the performance and flexibility characteristics of the entire heterogeneous computing system:
-
CPU+GPU heterogeneous computing. Although it can achieve an order of magnitude performance improvement (relative to CPUs) based on sufficient flexibility, computing efficiency still cannot be extreme.
-
CPU+DSA heterogeneous computing. Due to the lower flexibility of DSAs, they are unsuitable for application layer acceleration. A typical case is AI, where training and some inference are mainly completed by CPU+GPU, while DSA architecture AI chips have not yet been widely deployed.
4.2 Chiplet Technology Maturity: Quantitative Changes Trigger Qualitative Changes – Need for Architectural Innovation, Not Simple Integration
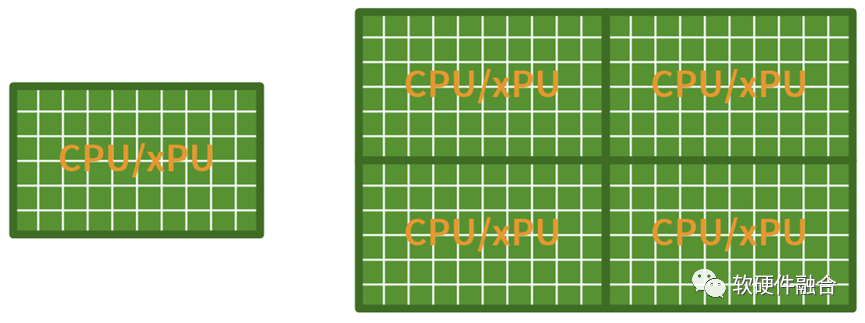
Assuming that without Chiplets, our CPU or xPU can integrate 50 cores, with Chiplet interconnection, we can combine 4 dies to achieve a single chip integration of 200 cores.
However, is the parallel expansion method shown in the image truly the value of Chiplets?
The conclusion is that such Chiplet integration is a waste!

Chiplets allow us to build super-large systems with a significant increase in scale at the chip level. This way, we can leverage some “characteristics” of large systems to further optimize. These characteristics include:
-
Complex systems consist of hierarchically segmented tasks;
-
Tasks at the infrastructure layer are relatively well-defined, suitable for DSA/ASIC. They can maximize performance while meeting the basic flexibility of tasks;
-
Tasks that cannot be accelerated in applications are the most uncertain, suitable for CPUs. The system complies with the 80/20 rule, where user-concerned applications only account for 20% of the entire system, while non-accelerable parts usually account for less than 10%. To provide users with an exceptional experience, these tasks are best executed on CPUs.
-
Tasks that can be accelerated in applications, due to the significant variation and iteration of application algorithms, are suitable for flexible acceleration engines like GPUs and FPGAs. They can provide sufficient programmability while also delivering the best possible performance.
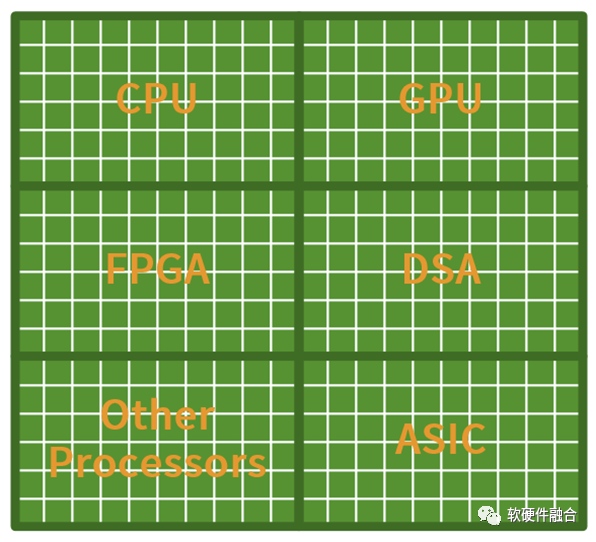
Thus, the entire system based on ultra-heterogeneous architecture:
-
From a macro perspective, 80% or even over 90% of computations are completed in DSA. Thus, the entire system approaches the extreme performance of DSA/ASIC;
-
The application parts that users are concerned about, which cannot be accelerated, still run on CPUs, meaning that what users see is still 100% CPU-level flexibility and programmability.
In other words, through the ultra-heterogeneous architecture, we can achieve extreme performance while maintaining extreme flexibility and programmability.
4.3 Ultra-Heterogeneous is Harder to Manage: Requires Innovative Concepts and Technologies
Programming heterogeneously is challenging; NVIDIA has spent years making CUDA programming friendly enough for developers, forming a healthy ecosystem.Ultra-heterogeneous is even more difficult: the difficulty of ultra-heterogeneous is not only reflected in programming but also in the design and implementation of processing engines, as well as in the integration of the entire system’s software and hardware capabilities.So, how can we better manage ultra-heterogeneous? After careful consideration, we approach it from the following aspects:
-
Performance and Flexibility. From a system perspective, as tasks sink from CPU to hardware acceleration, how to select the appropriate processing engine to achieve optimal performance while maintaining optimal flexibility. It is not just about balancing but also accommodating both.
-
Programming and Usability. The system gradually shifts from hardware-defined software to software-defined hardware. How to leverage these features, utilize existing software resources, and integrate with cloud services.
-
Products. User needs, in addition to the needs themselves, also need to consider the differences in different user demands and the long-term iterations of individual user needs. How to provide better products to users that meet both short-term and long-term needs. Teaching a man to fish is better than giving him a fish; how to provide users with a highly performant, completely programmable hardware platform without specific functions.
-
And so on.
Software and hardware integration provides a systematic concept, method, technology, and solution to address the above issues, offering a practical path to easily manage ultra-heterogeneous systems.
5 In the Future, All High-Performance Chips Will Be Ultra-Heterogeneous Chips
Raja Koduri, Senior Vice President and Head of Accelerated Computing Systems and Graphics at Intel, stated: To achieve the experiences depicted in “Avalanche” and “Ready Player One,” we need to increase current computing power by at least 1000 times. As applications continue to evolve, the fundamental contradiction between hardware performance improvement and software performance demand remains. It can be said that the demand for computing power is endless!
To ensure the maximization of macro computing power, on one hand, we must continuously improve performance, while on the other hand, we must ensure the flexibility and programmability of chips. Only through ultra-heterogeneous methods, categorizing tasks and selecting optimal engine solutions for each task characteristic can we achieve the utmost flexibility and programmability while also achieving the utmost performance. Thus, truly realizing the dual goals of performance and flexibility.
Solo operations lead to neglect; teamwork leads to mutual benefit.
In the future, only ultra-heterogeneous computing can ensure a significant increase in computing power without sacrificing flexibility and programmability. This will truly achieve a significant increase in macro computing power and better support the development of the digital economy.
References
https://hpc.llnl.gov/documentation/tutorials/introduction-parallel-computing-tutorial
(End of text)
Editor: Lu Dingci
