01 Introduction to Fault Injection Methods
In critical scenarios related to functional safety, intensive testing activities are essential to ensure that new systems and built-in fault tolerance mechanisms operate as expected. Ensuring that the system operates normally in the event of a failure (Fail Operational) is a more complex issue than traditional testing content. The process of introducing faults into the system to evaluate its behavior and measure the efficiency of fault tolerance mechanisms (i.e., coverage and latency) is known as fault injection.
The development of fault injection methods has progressed in parallel with the advancement of digitalization.
Initially, digital systems only utilized simple hardware systems. Therefore, the first fault injection methods involved injecting physical faults into the target system hardware by assuming simple hardware fault models (such as bit flips or bit hangs) (e.g., using radiation, pin levels, power disturbances, etc.).
The increasing complexity of hardware has made the use of these physical methods quite difficult, if not impossible, leading to the popularity of a new fault injection method based on runtime simulation of hardware faults through software (Software Implemented Fault Injection, SWIFI).
As critical systems expand into other application areas, we see that the software components of these systems are becoming increasingly complex, which has become a significant cause of system failures. The first flight of the Ariane 5 rocket (June 4, 1996) is an example. During the test flight, the rocket deviated from its flight path and exploded less than a minute after takeoff, resulting in a loss of $500 million. The explosion was caused by erroneous data conversion in the software, from a 64-bit floating point to a 16-bit signed integer representation. This vulnerability stemmed from the reuse of software subsystems from previous missions without substantial retesting, as developers believed the task was compatible with the new system.
SWIFI tools are used to inject errors into program states (e.g., data and address registers, stack and heap memory) and program code (e.g., memory areas where code is stored before or during program execution). Unfortunately, in complex software-intensive systems, accurately simulating the effects of real software faults through SWIFI is not feasible. This is because the number of lines of code used in automobiles has exponentially increased from tens of thousands to hundreds of millions over the past thirty years.
Compared to the first fault injection method, using fault injection to simulate the effects of real software faults (i.e., bugs), known as Software Fault Injection (SFI), is a relatively new approach. In fact, software fault injection involves introducing small changes into the target program code, creating different versions of the program (each version with an injected software fault).
The ISO 26262 standard specifies the use of error detection and handling mechanisms in software, as well as verification through fault injection.
Software fault injection is a hypothetical experiment that can originate from any stage of the software development process, including requirements analysis, design, and coding activities. The goal is to execute the target under a given workload and insert faults into specific software components of the target system. The main objective is to observe the behavior of the system in the presence of injected faults, considering that these faults may reproduce reasonable failures that could affect the given software components during operation.
02 Key Characteristics of Fault Injection Methods
A fault is defined as the cause of an incorrect system state or assumption, referred to as an error. A fault occurs when an event provides erroneous service, i.e., when a user or external system perceives an erroneous state.
The accuracy of the results obtained from fault injection activities largely depends on several key characteristics of the experiment, namely:
Representativeness
This refers to the ability of the fault load and workload to represent the real faults and inputs that the system will experience during operation. Representativeness of faults can be achieved by defining a realistic fault model and accurately reproducing that fault model during the experiment.
Non-intrusiveness
This requires that the instrumentation used during the fault injection process (such as fault insertion and data collection) should not significantly alter the actual behavior of the system. For example, executing additional code to disrupt the software state may lead to intrusiveness.
Repeatability
This refers to the characteristic that ensures statistical equivalence of results when the same fault injection activity is executed multiple times in the same environment using the same program. Achieving this characteristic is not easy due to the many sources of uncertainty present in computer systems, such as thread scheduling and event timing.
Practicality
This refers to the effectiveness of fault injection in terms of cost and time. These factors include the time required to implement and set up the fault injection environment, the time to execute experiments, and the time to analyze results. This attribute requires that experiments be supported by automated tools to meet time and budget constraints.
Portability
This requires that fault injection techniques or tools can be easily applied to different systems for comparison. The portability of fault injection tools also refers to the ability of the tool to support multiple fault models and to be extended with new fault models.
03 Characteristics of Software Faults
Injecting software faults requires precise definitions of the faults to be injected, which in turn necessitates a clear understanding and description of software faults. This is not easy to achieve, as software faults are caused by human errors that occur during development, which manifest as erroneous instructions in the program affecting software artifacts.
To improve software reliability, several fault classification models have been proposed. Among these models, Orthogonal Defect Classification (ODC) is one of the most widely adopted models by researchers and practitioners and has been used in multiple studies to define fault models for software fault injection. ODC is a framework for classifying software faults with the aim of obtaining metrics and quantitative feedback on the software development process;
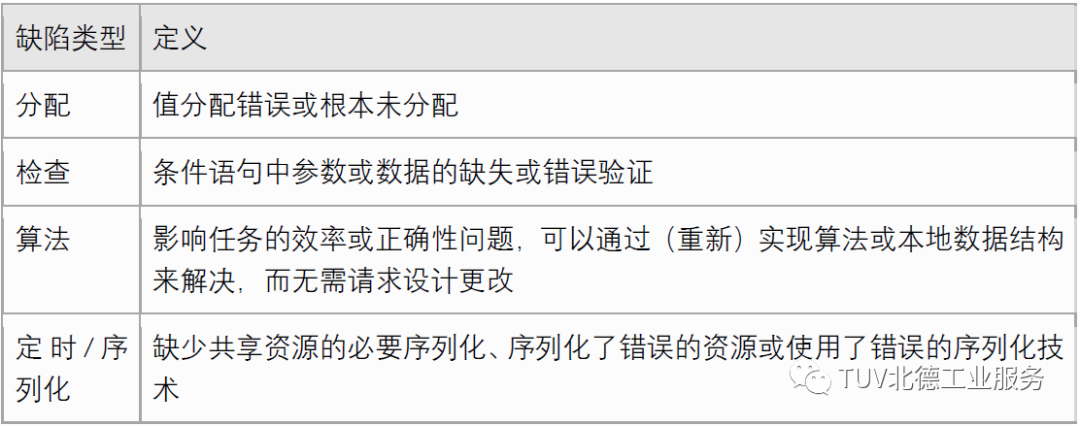

04 Software Fault Injection Techniques
Many SFI techniques and tools have been developed over the past 20 years. Here, we illustrate and discuss this work by distinguishing two basic approaches: injecting fault effects (also known as error injection), where errors are introduced by perturbing the system state, and injecting actual faults, where changes are made to the program code to simulate software faults. The following subsections review software fault injection techniques:
· Data error injection methods, which were the earliest, based on the hardware fault injection techniques that existed at the time;
· Interface error injection methods, aimed at testing the robustness of components interacting with other components;
· Injecting actual faults, which involves introducing small fault changes into the program code.
4.1 Data Error Injection
The early methods for injecting fault effects were developed in the context of studying hardware faults through SWIFI. SWIFI aims to reproduce the effects of hardware faults (such as CPU, bus, and memory faults) by interfering with the state of memory or hardware registers (i.e., errors). According to the following criteria, the SWIFI method replaces the contents of memory locations or registers with corrupted values:
· What to inject. The content of a single bit, byte, or word in a memory location or register has been corrupted. The types of errors are defined by analyzing errors caused by electrical or gate-level faults. Common types of errors include replacing bits with fixed values (stuck-at-0 and stuck-at-1 faults) or inverted values (bit flips).
· Where to inject. Due to the numerous memory locations, injecting errors into memory typically targets a subset of locations. Injection can focus on randomly selected locations within specific memory areas (e.g., stack, heap, global data) or user-selected locations (e.g., specific variables in memory). Errors injected into registers can target those registers that are accessible via software (e.g., data and address registers).
· When to inject. Error injection may be time or event-related. In the former case, errors are injected after a given experimental time, which is selected by the user or based on a probability distribution. In the latter case, errors are injected when specific events occur during execution, such as on the first access or every access to the target location. Three types of hardware faults can be simulated: transient faults (i.e., occasional faults), intermittent faults (i.e., repeated faults), and permanent faults.
It is worth noting that hardware errors injected by SWIFI tools can be injected into program states (e.g., data and address registers, stack and heap memory) and program code (e.g., memory areas where code is stored before or during program execution). This is an important distinction of software fault injection: corruption in program states is intended to reflect the effects of software faults, i.e., errors caused by the execution of erroneous programs, such as incorrect pointers, flags, or control flow, which SWIFI tools can directly introduce; in contrast, faults in program code are intended to reflect actual software faults in the code.
4.2 Interface Error Injection
Injecting errors at input parameters aims to simulate the effects of faults generated externally to the target, including the impact of software faults in external software components, and to assess the target’s ability to detect and handle corrupted inputs. Similarly, the corruption of output values is used to simulate the output of faulty components and can be used to evaluate the impact of faults on the rest of the system.
Faults in input parameters may reveal defects in the design and implementation of the target’s error detection and recovery mechanisms (e.g., input processing code). It is often adopted in robustness testing, which assesses the extent to which a system or component can operate correctly in the presence of invalid inputs or stressful environmental conditions. It should be noted that the goals of robustness testing and interface error injection differ from functional testing techniques, such as black-box testing: robustness testing aims to evaluate the robust behavior of software modules in the face of invalid inputs (e.g., avoiding process crashes or generating warning signals), which is unrelated to the functional correctness of the target.
Interface error injection can be performed in two ways. The first method is based on test drivers linked to the target component (e.g., programs using APIs exported by the target) and executes the program by submitting invalid inputs. This method is similar to unit testing, but in this case, the evaluation is of robustness rather than functional correctness. The second method involves intercepting and corrupting the interactions between the target and the rest of the system, i.e., triggering an interceptor program when calling the target component and modifying the original input to introduce corrupted input. In this case, the target component is tested in the context of the entire system integrating the target. This method is similar to SWIFI, as the original data flowing through the system (in this case, interface inputs) is replaced with corrupted data.
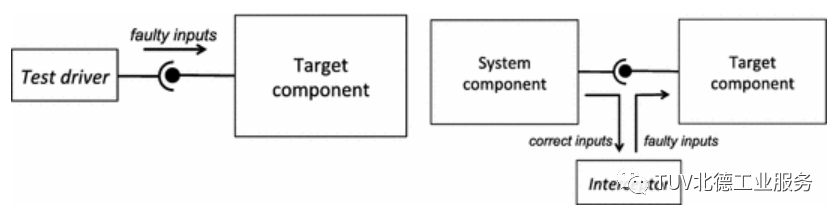
In interface error injection experiments, typically only one input parameter and one call are corrupted among several input parameters and several calls to the target API that occur during the experiment. Common methods for generating invalid input values include three:
· Fuzzing: The original value is replaced with a randomly generated value.
· Bit flipping: A corrupted value is generated by flipping one or more bits of the original value.
· Type-based injection: The original value is replaced with an invalid value selected based on the type of the corrupted input parameter, where the type is derived from the API exported by the target. This method defines a pool of invalid values for each data type, which are selected from the analysis of the type domain (e.g., for C pointers, “NULL”).
4.3 Injecting Code Changes
The previous subsections primarily discussed simulating software faults by injecting fault effects (i.e., errors) using the SWIFI method. A public issue with these methods is the representativeness of injected errors (such as bit flips), which may not necessarily match the errors produced by software faults.
To address the representativeness issue, recent research on SFI has focused on injecting errors into program code (i.e., code changes). Injecting code changes can simulate real software faults, as the injected faults produce errors and failures similar to those generated by actual software faults. Generally, errors can be injected into the code storage area or binary executable files of the process by applying SWIFI, but it is important to note that thorough testing of these programs requires injecting software faults within a limited scope, necessitating tools and techniques specifically designed for software fault injection.
05 Conclusion
When selecting methods for a system, the characteristics of the discussed fault injection methods should be considered.
Error injection is typically used to evaluate the robustness of individual components and improve error handling in specific parts of the code. The main reason is that error injection allows experimentation on specific parts of the system, as it can assess the impact of errors on specific component interfaces or program variables. In fact, error injection does not require waiting for errors to be generated and propagated to specific parts of the program state being evaluated. Furthermore, since error injection can be applied to individual components, it can be performed in the early stages of software verification.
In contrast, the purpose of injecting code changes is to evaluate the fault-tolerant system as a whole and to conduct quantitative assessments and comparisons between alternative design choices. Code changes are better suited for these goals because they are based on representative models of software faults and closely simulate the behavior of faulty software. This is an important requirement for quantitative assessment and comparison, as it considers the relative probabilities of fault occurrences to reflect the behavior exhibited by the system during operation. This makes injecting code changes more suitable for the later stages of software verification, when system components have already been integrated, and developers aim to assess the expected fault tolerance of the system during its operational lifetime (and derived metrics such as availability).