Introduction: Previously, we introduced the MME extension of T-head’s Xuantie (Matrix Multiply Extension). We also discussed several directions of RISC-V in Matrix extensions in the article “From Vector to Matrix: The Future of RISC-V Matrix Extensions.” After several months of development, what is the current status of the RISC-V Matrix standardization process?Current Status: Just two weeks ago, the Matrix TG had an intense discussion regarding standardization issues.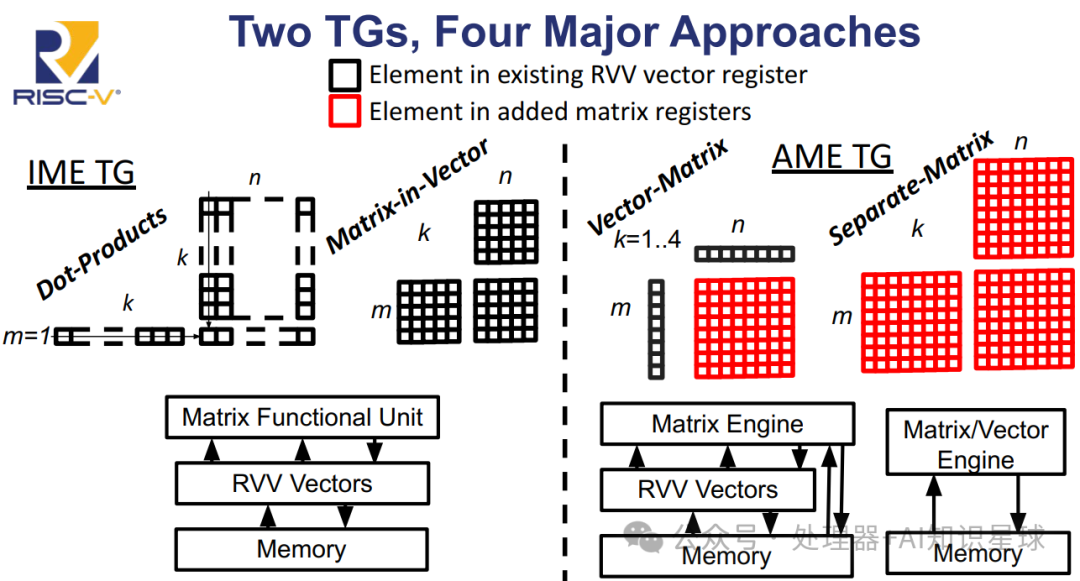 First, let’s discuss the current status of the RVI Matrix standard. As shown in the image above, there are two working groups (IME and AME) with four main directions:IME Dot-Products: A compact and efficient extension for small vector lengths (VLEN <= 2K), which meets some DSP requirements but cannot scale performance with larger vector lengths.IME Matrix-in-Vector: As the name suggests, it uses Vector to perform matrix operations, allowing for greater throughput than dot products. However, it only makes sense under the design point of a vector-matrix engine, without introducing new Matrix registers or states; the Matrix operates more like “behind the scenes.” AME Vector-Matrix: For application processors that already have the RVV extension, this approach aims to maintain the vector ISA and memory model while only adding Matrix registers to store the results of matrix multiplication.AME Separate-Matrix: Completely decouples Vector and Matrix, used for unconstrained matrix and vector designs in embedded/device/accelerator use cases.Next Steps: A member vote will be conducted on each proposal, and the results will serve as an important reference. I believe that in the current high-performance and AI fields, Scale, Vector, Matrix, and some specialized functional computations will be utilized in various specific application scenarios. The different implementations of Matrix indeed have their own advantages and disadvantages, and the existence of these four directions illustrates this point.Even though there are two task groups working on two different standards, it is likely that only one standard (or possibly none) will dominate. Compared to IME, AME is relatively “register expensive” (adding extra architectural state for matrices), but in return, it offers higher throughput. Therefore, the trade-off between AME and IME remains a concern.In summary, although currently, solutions like Apple AMX and ARM SME may lead in matrix acceleration, with the advancement of RISC-V technology and the efforts of the community, it is gradually becoming a strong competitor, showcasing tremendous potential in the general computing field.Let us continue to pay attention to future developments.Related Reading:From Vector to Matrix: The Future of RISC-V Matrix ExtensionsXuantie Matrix Multiply ExtensionFeel free to follow our public account for the latest updates.
First, let’s discuss the current status of the RVI Matrix standard. As shown in the image above, there are two working groups (IME and AME) with four main directions:IME Dot-Products: A compact and efficient extension for small vector lengths (VLEN <= 2K), which meets some DSP requirements but cannot scale performance with larger vector lengths.IME Matrix-in-Vector: As the name suggests, it uses Vector to perform matrix operations, allowing for greater throughput than dot products. However, it only makes sense under the design point of a vector-matrix engine, without introducing new Matrix registers or states; the Matrix operates more like “behind the scenes.” AME Vector-Matrix: For application processors that already have the RVV extension, this approach aims to maintain the vector ISA and memory model while only adding Matrix registers to store the results of matrix multiplication.AME Separate-Matrix: Completely decouples Vector and Matrix, used for unconstrained matrix and vector designs in embedded/device/accelerator use cases.Next Steps: A member vote will be conducted on each proposal, and the results will serve as an important reference. I believe that in the current high-performance and AI fields, Scale, Vector, Matrix, and some specialized functional computations will be utilized in various specific application scenarios. The different implementations of Matrix indeed have their own advantages and disadvantages, and the existence of these four directions illustrates this point.Even though there are two task groups working on two different standards, it is likely that only one standard (or possibly none) will dominate. Compared to IME, AME is relatively “register expensive” (adding extra architectural state for matrices), but in return, it offers higher throughput. Therefore, the trade-off between AME and IME remains a concern.In summary, although currently, solutions like Apple AMX and ARM SME may lead in matrix acceleration, with the advancement of RISC-V technology and the efforts of the community, it is gradually becoming a strong competitor, showcasing tremendous potential in the general computing field.Let us continue to pay attention to future developments.Related Reading:From Vector to Matrix: The Future of RISC-V Matrix ExtensionsXuantie Matrix Multiply ExtensionFeel free to follow our public account for the latest updates.