Optimizing Cross-Architecture Programming Model Adaptation in SIMD-to-RVV Dynamic Binary Translation
-
Lai Yuanming1, 2, Li Yalong1, 3 , Hu Hanzhi1, 2,
-
Xie Mengyao1, 2, Wang Zhe1, 2, Wu Chenggang1, 2
1. National Key Laboratory of Processor Chips (Institute of Computing Technology, Chinese Academy of Sciences)
2. University of Chinese Academy of Sciences
3. Advanced Technology Research Institute, Zhengzhou University
 Abstract
Abstract
RISC-V has achieved significant success in the embedded field due to its open-source and modular design features, and is gradually expanding into the high-performance computing (HPC) domain. RISC-V hardware aimed at HPC, such as the Sophon SG2042 multi-core processor, has demonstrated performance levels comparable to x86/ARM products. However, the incomplete software ecosystem is one of the biggest obstacles to its development. We have developed a process-level dynamic binary translator (DBT) called RVBT, which is used to port the mature x86 software ecosystem to the RISC-V platform, accelerating the application of RISC-V in the HPC field. Given that HPC programs widely rely on SIMD instructions, we focus on addressing the significant performance bottlenecks in translation caused by the differences in programming models between SIMD and RVV. We propose three innovative optimization schemes. x86 SIMD hard-codes data types into the opcode, while RVV requires dynamic configuration of the vtype and mask registers, leading to a large number of redundant operations during direct translation, severely reducing translation efficiency. By fully utilizing the locality of program data types, our optimization schemes can eliminate redundant settings caused by cross-architecture adaptation of programming models, mix floating-point and vector extensions to translate SIMD instructions, and synchronize data as needed, significantly improving the translation efficiency of SIMD instructions. The three optimization schemes are general and also applicable to the translation of SIMD to RVV on ARM platforms. Experiments show that using SPEC CPU 2006 as the test set, the average dynamic elimination rates for the csrr, vsetvl, and vsetvli instructions reached 100%, 100%, and 56.31%, respectively. In the floating-point test set, the average dynamic elimination rate for mask setting operations reached 74.66%, and the average dynamic synchronization rate for data was 67.35%. The optimized RVBT achieved an average execution efficiency of 47.39% and 40.06% on integer and floating-point test sets, respectively, with acceleration ratios of 1.21 and 8.31 compared to before optimization, far exceeding QEMU’s 18.84% and 4.81%, demonstrating its potential for application in certain HPC scenarios.
Keywords: Binary Translation / RISC-V Vector Extension / x86 SIMD / Cross-Architecture Programming Model Adaptation / Floating-Point Computation / Elimination of Redundant Settings / Mixed Translation

The promotion of RISC-V in the HPC field faces significant software ecosystem bottlenecks. Although mainstream Linux distributions (such as Ubuntu, Fedora, etc.) and domestic operating systems (such as Kylin, Euler, Longxin, etc.) have provided basic support, there is still a significant lag in adapting key application layers (such as Docker, Kubernetes) and foundational software (such as MongoDB, TiDB). Support for compilers and commonly used office software has also taken a long time, necessitating rapid improvement solutions for the software ecosystem.
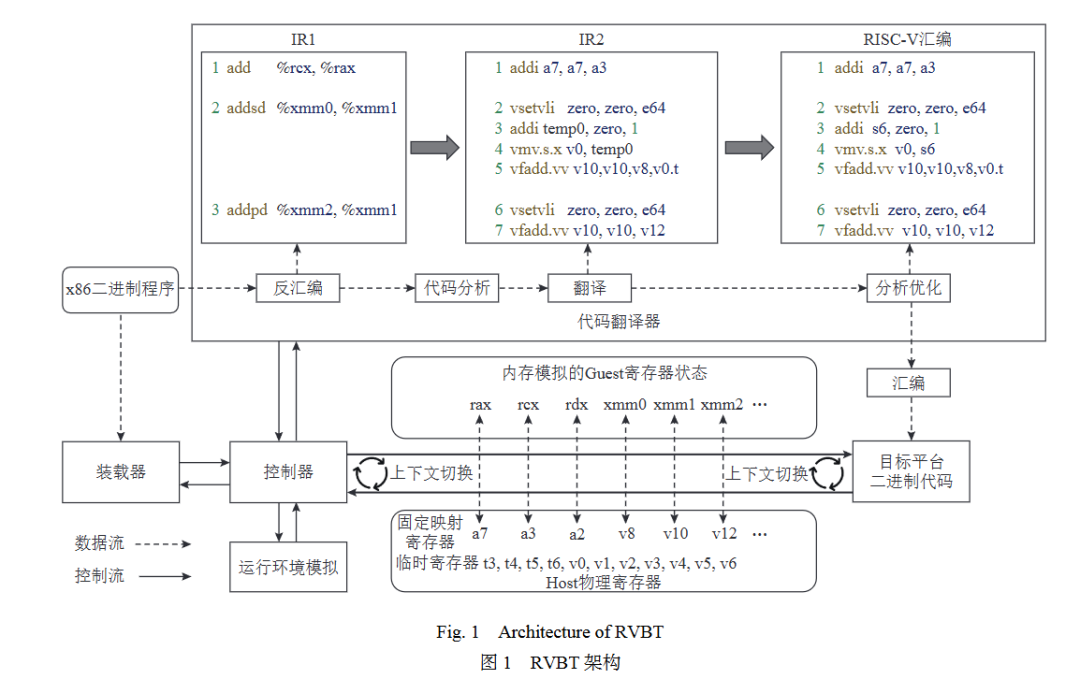
Dynamic binary translation (DBT) technology provides a new approach to break this deadlock, enabling the rapid porting of the rich software ecosystem from x86/ARM to the RISC-V platform. To this end, we developed the process-level binary translator RVBT, which can translate x86 applications to execute on the RISC-V platform. RVBT achieves an average execution efficiency of 39.04% when translating the integer test set of SPEC CPU 2006, significantly outperforming QEMU’s 18.84%. However, it only reaches 4.82% of local execution efficiency on the floating-point test set, which is comparable to QEMU but 8.10 times lower than its performance on the integer test set. Analysis reveals that the floating-point test set heavily utilizes SIMD (single instruction multiple data) instructions, and the code generated by RVBT for translating SIMD instructions has low execution efficiency, which is the main performance bottleneck. RVBT uses the RISC-V RVV extension to translate SIMD instructions. Both RVV and SIMD have data-level parallel capabilities, which are expected to enable efficient translation. Upon further analysis of this counterintuitive phenomenon, we observed three key points:
1)There are significant differences in programming models between SIMD and RVV extensions. The former encodes the data bit width and the number of data elements in the opcode, while the latter dynamically configures them through the vector type register (vtype) and mask register. The overhead of frequently setting data types is substantial and is a key reason for the underperformance of translation execution.
2)x86 uses SIMD instructions and registers to perform scalar floating-point operations, while RISC-V uses independent floating-point extensions, which is more efficient than using RVV. RVBT translates SIMD instructions into RVV instructions, meaning that scalar floating-point operations on x86 are implemented using RVV instructions on the RISC-V platform. This is another key reason for the underperformance of translation execution.
3)The locality of data types operated on by code has not been effectively utilized. Adjacent SIMD instructions often process the same data types, and the vtype and mask settings used when translating these SIMD instructions are the same. Leveraging this characteristic can lead to the design of optimization schemes for RVBT, improving the quality and execution efficiency of the translated code.
Based on the above three observations, this paper focuses on the performance bottleneck of translating SIMD instructions from the x86 platform to execute on the RISC-V platform, proposing three innovative optimization schemes: SetVType, SetMask, and SD2Float. This paper provides an efficient binary compatibility solution for the construction of the RISC-V software ecosystem, which has significant practical value for promoting the application and development of the RISC-V open-source architecture in the HPC field. The specific contributions are as follows:
1)We proposed the SetVType and SetMask optimization schemes to eliminate redundant vtype and mask setting operations when translating SIMD instructions into RVV instructions, reducing the performance overhead caused by the significant differences in programming models between SIMD and RVV, and significantly improving the quality of native code and the efficiency of translation execution.
2)We proposed the SD2Float optimization scheme, which uses more efficient floating-point instructions on the RISC-V platform to translate scalar double-precision floating-point operations in SIMD instructions, using RVV to translate other floating-point operations, and achieving on-demand data synchronization between floating-point registers and vector registers through static analysis. This mixed translation scheme enhances the efficiency of translating floating-point operations.
3)We implemented three optimizations from x86-64 as the source platform to RISC-V-64 as the target platform, addressing multiple technical challenges, and experimentally verified that these optimizations can significantly improve the translation execution efficiency of SIMD instructions, especially for floating-point operations.
4)The three proposed optimizations are general in the context of translating SIMD instructions into RISC-V RVV instructions. They are applicable not only to the translation from x86 to RISC-V platforms but also to the translation from ARM and other platforms to RISC-V.
 Conclusion and Outlook
Conclusion and Outlook
This paper addresses the programming model adaptation issues faced by cross-architecture translation of SIMD instructions to vector instructions, proposing three optimization schemes based on the locality characteristics of programs, and implementing them in the dynamic binary translator from x86 to RISC-V platforms. These three optimization schemes are architecture-independent and possess cross-architecture adaptability. Different architecture processors have significant differences in their SIMD extensions. In cross-architecture binary translation, if the SIMD extension of the source platform hard-codes the data element types and counts of its instruction operations into the instruction opcode, and the vector extension of the target platform dynamically configures its instruction operations’ data element types and counts, then the SetVType and SetMask optimizations proposed in this paper are applicable. If scalar floating-point operations and SIMD operations share a set of registers on the source platform, while the target platform uses two sets of independent registers, then the SD2Float optimization proposed in this paper is applicable. Translating ARM platform’s NEON instructions to RISC-V vector instructions is a typical example where the three optimization schemes proposed in this paper can be applied.
QEMU uses scalar instructions of the target platform to simulate SIMD instructions of the source platform. Related research has already added vector TCG-IR in QEMU to utilize the single instruction multiple data hardware resources on the target platform, thereby improving translation performance. The three optimization schemes proposed in this paper are orthogonal to these research solutions. If the source and target platforms for translation meet the conditions for applying the optimizations proposed in this paper, then these optimization schemes can be applied to QEMU. Other binary translators that translate source platform SIMD instructions to target platform vector instructions can also utilize the optimization schemes proposed in this paper.
Citation Format
Lai Yuanming, Li Yalong, Hu Hanzhi, Xie Mengyao, Wang Zhe, Wu Chenggang. Optimizing Cross-Architecture Programming Model Adaptation in SIMD-to-RVV Dynamic Binary Translation[J]. Journal of Computer Research and Development, 2025, 62(6): 1469-1491. DOI: 10.7544/issn1000-1239.202550135
Lai Yuanming, Li Yalong, Hu Hanzhi, Xie Mengyao, Wang Zhe, Wu Chenggang. Optimizing Cross-Architecture Programming Model Adaptation in SIMD-to-RVV Dynamic Binary Translation[J]. Journal of Computer Research and Development, 2025, 62(6): 1469-1491. DOI: 10.7544/issn1000-1239.202550135

Scan to access the full text
 2024 Paper Collection SeriesCollection | Software Technology Related Papers Published in Journal of Computer Research and Development 2024Collection | Network and Communication Related Papers Published in Journal of Computer Research and Development 2024Collection | Security and Privacy Protection Related Papers Published in Journal of Computer Research and Development 2024Collection | Architecture Related Papers Published in Journal of Computer Research and Development 2024Collection | Artificial Intelligence Related Papers Published in Journal of Computer Research and Development 2024Collection | Review Papers Published in Journal of Computer Research and Development 20242025 DirectoryDirectory | Journal of Computer Research and Development 2025 Issue 1 (Vote for Your Most Interested Papers)Directory | Journal of Computer Research and Development 2025 Issue 2 (Vote for Your Most Interested Papers)Directory | Journal of Computer Research and Development 2025 Issue 3 (Vote for Your Most Interested Papers)Directory | Journal of Computer Research and Development 2025 Issue 4 (Vote for Your Most Interested Papers)Directory | Journal of Computer Research and Development 2025 Issue 5 (Vote for Your Most Interested Papers)Directory | Journal of Computer Research and Development 2025 Issue 6 (Vote for Your Most Interested Papers)
2024 Paper Collection SeriesCollection | Software Technology Related Papers Published in Journal of Computer Research and Development 2024Collection | Network and Communication Related Papers Published in Journal of Computer Research and Development 2024Collection | Security and Privacy Protection Related Papers Published in Journal of Computer Research and Development 2024Collection | Architecture Related Papers Published in Journal of Computer Research and Development 2024Collection | Artificial Intelligence Related Papers Published in Journal of Computer Research and Development 2024Collection | Review Papers Published in Journal of Computer Research and Development 20242025 DirectoryDirectory | Journal of Computer Research and Development 2025 Issue 1 (Vote for Your Most Interested Papers)Directory | Journal of Computer Research and Development 2025 Issue 2 (Vote for Your Most Interested Papers)Directory | Journal of Computer Research and Development 2025 Issue 3 (Vote for Your Most Interested Papers)Directory | Journal of Computer Research and Development 2025 Issue 4 (Vote for Your Most Interested Papers)Directory | Journal of Computer Research and Development 2025 Issue 5 (Vote for Your Most Interested Papers)Directory | Journal of Computer Research and Development 2025 Issue 6 (Vote for Your Most Interested Papers)
Sharing is Caring, give a

Little Red Heart Let’s watch together