Produced by Big Data Digest
Compiled by: Javen, Hu Jia, Yun Zhou
Insufficient memory is a common issue encountered during project development. My team and I faced this problem in a previous project where we needed to store and process a fairly large dynamic list. Testers often complained to me about memory shortages. However, in the end, we solved this problem by adding a single line of code.
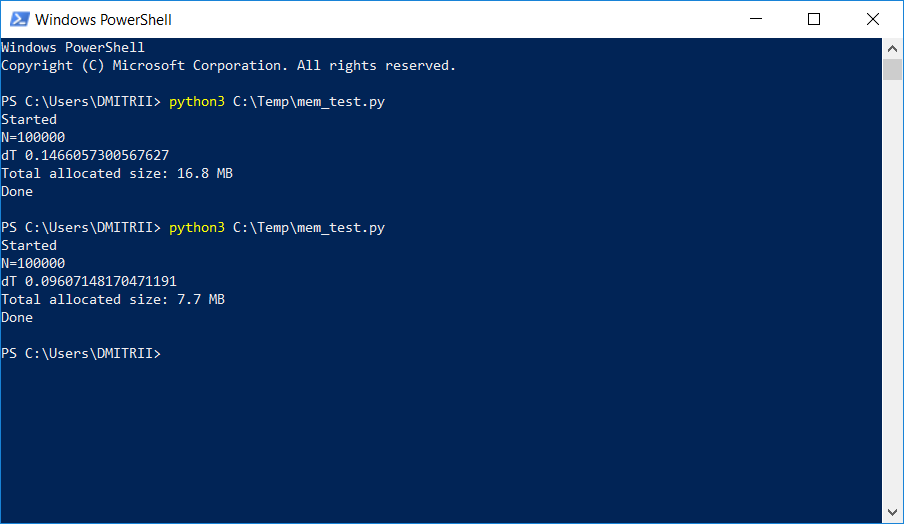
The result is shown in the image below:
I will explain how it works below.
Let’s take a simple “learning” example – creating a DataItem class that defines some personal information attributes, such as name, age, and address.
class DataItem(object):
def __init__(self, name, age, address):
self.name = name
self.age = age
self.address = address
Quick Test – How much memory does such an object occupy?
First, let’s try the following test:
d1 = DataItem("Alex", 42, "-")
print ("sys.getsizeof(d1):", sys.getsizeof(d1))
The answer is 56 bytes. It seems quite small, and the result is satisfactory.
However, let’s check another object with more data:
d2 = DataItem("Boris", 24, "In the middle of nowhere")
print ("sys.getsizeof(d2):", sys.getsizeof(d2))
The answer is still 56. This makes it clear that this result is not entirely accurate.
Our intuition is correct; the problem is not that simple. Python is a very flexible language with dynamic typing, and it stores a lot of extra data while working. This extra data itself occupies a lot of memory.
For example, sys.getsizeof(” “) returns 33, that’s right, each empty line takes up to 33 bytes! And sys.getsizeof(1) will return 24 bytes for this number (I suggest C programmers stop reading now to avoid losing faith in the beauty of Python).
For more complex elements, such as dictionaries, sys.getsizeof(dict()) returns 272 bytes, and that’s just for an empty dictionary. I’ll stop the examples here, but the facts are clear, not to mention that RAM manufacturers need to sell their chips.
Now, let’s return to our DataItem class and the “quick test” question.
How much memory does this class actually occupy?
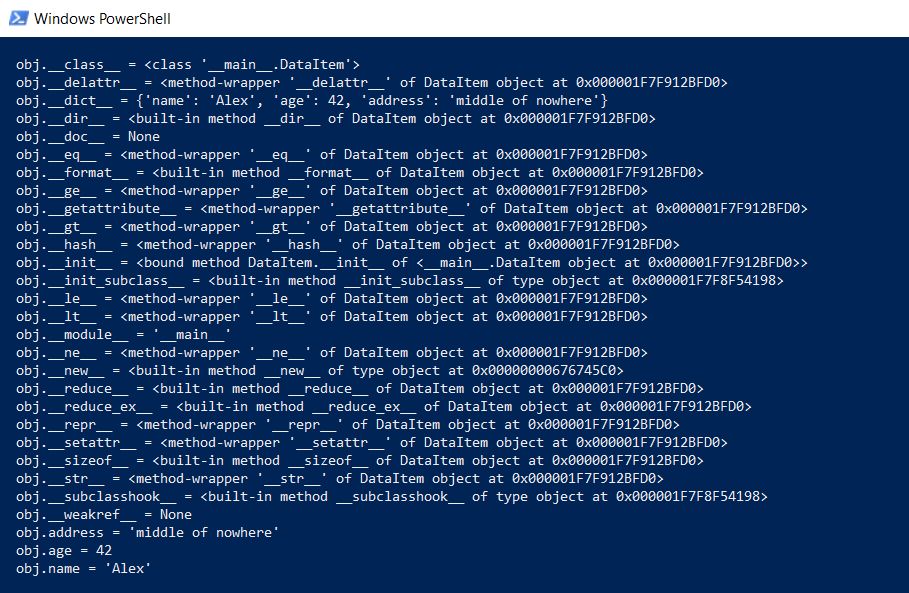
First, we will output the entire content of the class at a lower level:
def dump(obj):
for attr in dir(obj):
print(" obj.%s = %r" % (attr, getattr(obj, attr)))
This function will display the hidden content under the “invisibility cloak” so that all Python functions (types, inheritance, and other packages) can run.
The results are impressive:
How much memory does it occupy in total?
On GitHub, there is a function that can calculate the actual size by recursively calling getsizeof on all objects.
def get_size(obj, seen=None):
# From https://goshippo.com/blog/measure-real-size-any-python-object/
# Recursively finds size of objects
size = sys.getsizeof(obj)
if seen is None:
seen = set()
obj_id = id(obj)
if obj_id in seen:
return 0
# Important mark as seen *before* entering recursion to gracefully handle
# self-referential objects
seen.add(obj_id)
if isinstance(obj, dict):
size += sum([get_size(v, seen) for v in obj.values()])
size += sum([get_size(k, seen) for k in obj.keys()])
elif hasattr(obj, '__dict__'):
size += get_size(obj.__dict__, seen)
elif hasattr(obj, '__iter__') and not isinstance(obj, (str, bytes, bytearray)):
size += sum([get_size(i, seen) for i in obj])
return size
Let’s try it:
d1 = DataItem("Alex", 42, "-")
print ("get_size(d1):", get_size(d1))
d2 = DataItem("Boris", 24, "In the middle of nowhere")
print ("get_size(d2):", get_size(d2))
We get 460 and 484 bytes respectively, which seems much closer to the truth.
Using this function, we can conduct a series of experiments. For example, I want to know how much space the data will occupy if DataItem is placed in a list.
get_size([d1]) returns 532 bytes, clearly, this is the “original” 460 plus some overhead. However, get_size([d1, d2]) returns 863 bytes—less than 460 + 484. The result of get_size([d1, d2, d1]) is even more interesting, producing 871 bytes, just a little more, indicating that Python is smart enough not to allocate memory for the same object again.
Now let’s look at the second part of the question.
Is it possible to reduce memory consumption?
The answer is yes. Python is an interpreter, and we can extend our classes at any time, for example, by adding a new field:
d1 = DataItem("Alex", 42, "-")
print ("get_size(d1):", get_size(d1))
d1.weight = 66
print ("get_size(d1):", get_size(d1))
This is a great feature, but if we don’t need this functionality, we can force the interpreter to use the __slots__ directive to specify the list of class attributes:
class DataItem(object):
__slots__ = ['name', 'age', 'address']
def __init__(self, name, age, address):
self.name = name
self.age = age
self.address = address
For more information, refer to the section on “__dict__ and __weakref__ in the documentation. The space saved by using __dict__ can be significant.”
After trying, we found that get_size(d1) returns 64 bytes, which is about 7 times less than 460. As a bonus, the object creation speed increased by about 20% (see the first screenshot of the article).
Using such a large memory gain does not incur other overhead costs. Just create an array of 100,000 elements and check the memory consumption:
data = []
for p in range(100000):
data.append(DataItem("Alex", 42, "middle of nowhere"))
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')
total = sum(stat.size for stat in top_stats)
print("Total allocated size: %.1f MB" % (total / (1024*1024)))
Without __slots__, the result is 16.8MB, while with __slots__ it is 6.9MB. Of course, it’s not 7 times, but considering the code change is minimal, the performance is still excellent.
Now let’s discuss the drawbacks of this approach. Activating __slots__ prohibits the creation of all other elements, including __dict__, which means, for example, that the following code to convert the structure to JSON will not work:
def toJSON(self):
return json.dumps(self.__dict__)
But this can also be easily resolved by programmatically generating your dict, iterating through all elements in the loop:
def toJSON(self):
data = dict()
for var in self.__slots__:
data[var] = getattr(self, var)
return json.dumps(data)
It is also impossible to dynamically add new variables to the class, but in our project, this is not necessary.
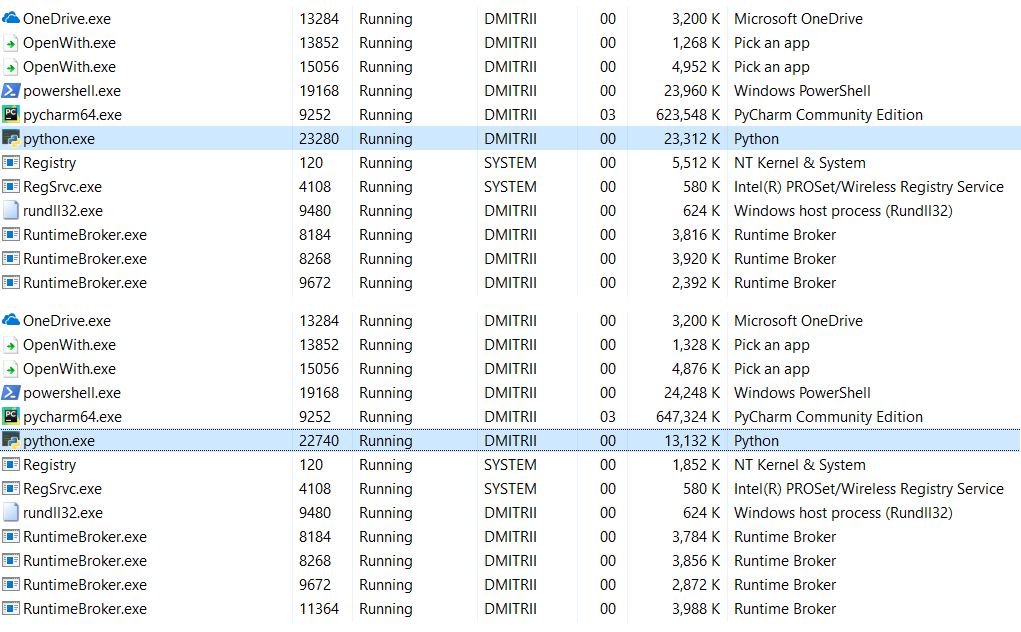
Here is one last quick test. Let’s see how much memory the entire program requires. Add an infinite loop at the end of the program to keep it running and check the memory consumption in the Windows Task Manager.
Without __slots__
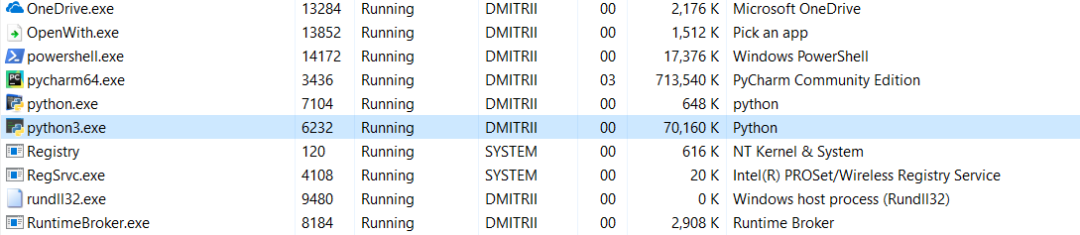
69MB reduced to 27MB… Well, we saved memory after all. This is a good result for just adding one line of code.
Note: The tracemalloc debugging library uses a lot of extra memory. Obviously, it adds extra elements for each created object. If you turn it off, the total memory consumption will be much less, as shown in the screenshots with two options:
How to Save More Memory?
You can use the numpy library, which allows you to create structures in a C-style, but in this project, it requires deeper code improvements, so for me, the first method is sufficient.
Strangely, the use of __slots__ has never been analyzed in detail on Habré, and I hope this article can fill that gap.
Conclusion
This article may seem like an anti-Python advertisement, but it is not at all. Python is very reliable (to “remove” a program in Python, you have to work very hard), and it is a language that is easy to read and convenient to write. In many cases, these advantages far outweigh the disadvantages, but if you need to maximize performance and efficiency, you can write code using the numpy library like C++, which can handle data very quickly and efficiently.
Finally, happy coding!
Related report:
https://medium.com/@alexmaisiura/python-how-to-reduce-memory-consumption-by-half-by-adding-just-one-line-of-code-56be6443d524
[Today’s Machine Learning Concept]
Have a Great Definition

Volunteer Introduction
Reply with “Volunteer” to join us