0. Introduction There are two common ways to improve efficiency: one is to increase concurrency, and the other is to increase data throughput.In previous articles, we discussed multithreading concurrency, which is a common method for increasing concurrency; this article will introduce SIMD, which is related to increasing data throughput, allowing for the processing of more data at once and enhancing data-level parallelism. This article will cover the concept, principles, and usage of SIMD.1. Concept of SIMD SIMD (Single Instruction Multiple Data) allows a single instruction to perform operations on multiple data points, increasing the amount of data processed in a single operation compared to the previously common SISD (Single Instruction Single Data).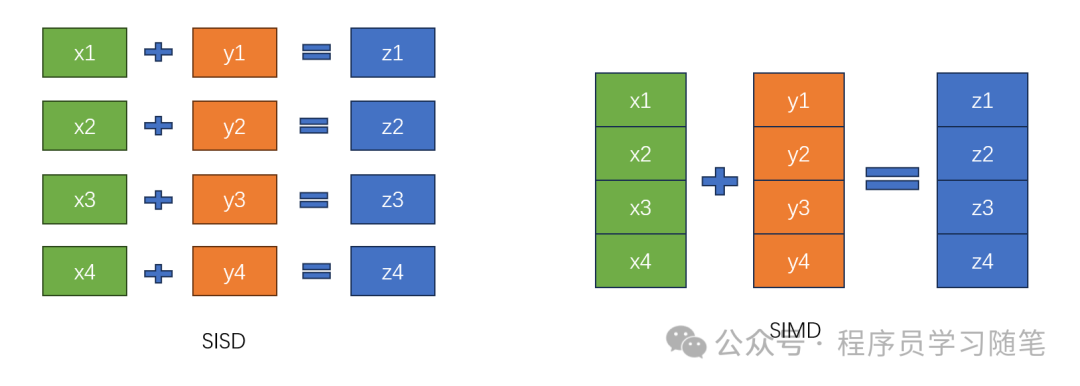 Next, let’s look at the development timeline of SIMD:1) In 1996, Intel first introduced the MMX (Multimedia Extensions) instruction set, using 64-bit registers to allow the CPU to process multiple sets of integer data simultaneously.2) In 1999, the Pentium III introduced SSE, which expanded the register width to 128 bits and supported parallel processing of floating-point numbers. Subsequent iterations like SSE2 and SSE3 continued to enhance the instruction set.3) In 2008, Intel and AMD jointly proposed the AVX (Advanced Vector Extensions) architecture, which was implemented in 2011 with the Sandy Bridge and Bulldozer architectures, expanding the register width to 256 bits. The VEX instruction prefix design made vector operations more flexible. In 2013, the AVX2 supported by the Haswell processor further strengthened integer data processing capabilities, while the AVX-512, which emerged in the same year, was implemented in the Xeon Phi 200 processor in 2016, achieving a breakthrough with 512-bit registers and becoming a core acceleration engine for high-density computing in data centers. The corresponding registers and bit widths are as follows:
Next, let’s look at the development timeline of SIMD:1) In 1996, Intel first introduced the MMX (Multimedia Extensions) instruction set, using 64-bit registers to allow the CPU to process multiple sets of integer data simultaneously.2) In 1999, the Pentium III introduced SSE, which expanded the register width to 128 bits and supported parallel processing of floating-point numbers. Subsequent iterations like SSE2 and SSE3 continued to enhance the instruction set.3) In 2008, Intel and AMD jointly proposed the AVX (Advanced Vector Extensions) architecture, which was implemented in 2011 with the Sandy Bridge and Bulldozer architectures, expanding the register width to 256 bits. The VEX instruction prefix design made vector operations more flexible. In 2013, the AVX2 supported by the Haswell processor further strengthened integer data processing capabilities, while the AVX-512, which emerged in the same year, was implemented in the Xeon Phi 200 processor in 2016, achieving a breakthrough with 512-bit registers and becoming a core acceleration engine for high-density computing in data centers. The corresponding registers and bit widths are as follows:
| Instruction Set | Registers | Floating Point Width | Integer Width |
|---|---|---|---|
| MMX | MM0~MM7 | 64 | |
| SSE | XMM0~XMM7 | 128 | |
| SSE2 | XMM0~XMM15 | 128 | 128 |
| AVX | YMM0~YMM15 | 256 | 128 |
| AVX2 | YMM0~YMM15 | 256 | 256 |
2. Principles of SIMD SIMD essentially uses special instruction sets and registers to pack multiple data points together and execute the same operation within a single CPU clock cycle. Its basic working mode is to utilize wider registers to process more data simultaneously. The basic vector registers and data layout are as follows:1) Register Width: For example, SSE (128 bits), AVX (256/512 bits), determines the amount of data that can be processed at once.2) Data Packing: Storing multiple data points of the same type (such as integers or floating-point numbers) consecutively to form a vector.3. Usage of SIMD3.1 Inline Assembly Inline assembly varies across different compilers. Here, we demonstrate SSE floating-point addition implemented in GCC style:
#include <stdio.h>
#include <stdlib.h>
int main() {
float left[4] = { 3, 6, 8, 10 };
float right[4] = { 4, 5, 5, 6 };
float res[4];
__asm__ __volatile__(
"movups %1, %%xmm0\n\t" // Move 128 bits of left memory into xmm0 register
"movups %2, %%xmm1\n\t" // Move 128 bits of right memory into xmm1 register
"mulps %%xmm1, %%xmm0\n\t" // Execute xmm0 * xmm1, result in xmm0
"movups %%xmm0, %0\n\t" // Move xmm0 data into memory pointed by res
: "=m"(res) // Output
: "m"(left), "m"(right) // Input
);
for(int i = 0; i < 4; i++)
printf("%.2f\n", res[i]);
return 0;
} Let’s briefly look at the instructions used, mainly movups and mulps.1) movups: move indicates moving; u indicates unaligned memory; if it is a, it indicates aligned memory; p indicates packed data, operating on 128-bit data; if it is s, it indicates scalar, operating only on the first data; s indicates single precision floating point, d indicates double precision floating point.2) mulps: mul indicates multiplication; p, s, and the meanings in movups are the same. Relevant inline assembly documentation can be referenced:1) GCC Inline Assembly Documentation:https://gcc.gnu.org/onlinedocs/gcc/Using-Assembly-Language-with-C.html2) MSVC Inline Assembly Guide:https://docs.microsoft.com/en-us/cpp/assembler/inline/inline-assembler?view=msvc-1703.2 Using Intrinsics Functions Intrinsics functions are provided by compiler vendors (such as Intel, GCC) and typically start with<span><span>_mm_</span></span>or<span><span>_mm256_</span></span>to directly map to specific SIMD instructions (for example,<span><span>_mm_add_ps</span></span>corresponds to the floating-point addition instruction of SSE). Here is a GCC implementation similar to the inline assembly above:
#include <stdio.h>
#include <stdlib.h>
#include <emmintrin.h>
int main() {
float left[4] = { 3, 6, 8, 10 };
float right[4] = { 4, 5, 5, 6 };
float res[4];
__m128 A = _mm_loadu_ps(left);
__m128 B = _mm_loadu_ps(right);
__m128 RES = _mm_mul_ps(A, B);
_mm_storeu_ps(res, RES);
for(int i = 0; i < 4; i++)
printf("%.2f\n", res[i]);
return 0;
}_mm indicates this is a 64-bit/128-bit instruction, while _mm256 and _mm512 indicate 256-bit or 512-bit instructions; _loadu indicates an unaligned load instruction, while those without the u suffix are aligned; _ps has the same meaning as the assembly instructions above.
1) Intel Instruction Set Reference:https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html3.3 Compiler Support and Automatic Code Optimization
Modern compilers (such as GCC, Clang, MSVC) support automatic vectorization, which can be enabled through optimization levels like<span><span>-O3</span></span>. For example:
- GCC: Use
<span><span>-march=native</span></span>to let the compiler automatically select the optimal SIMD instruction set. - Clang: Use
<span><span>-fvectorize</span></span>to force vectorization, and<span><span>-fvectorizer-verbose=1</span></span>to view vectorization logs. - If automatic optimization is not effective, manual optimization can be employed.
3.4 Performance Testing
#include <iostream>
#include <chrono>
#include <vector>
#include <cstdlib>
#include <xmmintrin.h> // Include SSE instruction set header
using namespace std;
using namespace std::chrono;
// Normal addition function
void normalAdd(const vector<float>& a, const vector<float>& b, vector<float>& result) {
for (size_t i = 0; i < a.size(); ++i) {
result[i] = a[i] + b[i];
}
}
// SIMD optimized addition function using SSE
void simdAdd(const vector<float>& a, const vector<float>& b, vector<float>& result) {
size_t i = 0;
const size_t sseWidth = 4; // SSE can process 4 single precision floats simultaneously
// Perform SIMD computation in groups of 4 elements
for (; i + sseWidth <= a.size(); i += sseWidth) {
__m128 va = _mm_loadu_ps(&a[i]);
__m128 vb = _mm_loadu_ps(&b[i]);
__m128 vresult = _mm_add_ps(va, vb);
_mm_storeu_ps(&result[i], vresult);
}
// Process remaining elements
for (; i < a.size(); ++i) {
result[i] = a[i] + b[i];
}
}
// Verify result correctness
bool verifyResult(const vector<float>& result, const vector<float>& expected) {
for (size_t i = 0; i < result.size(); ++i) {
if (abs(result[i] - expected[i]) > 1e-6) {
return false;
}
}
return true;
}
int main() {
const size_t size = 1000000; // 1 million elements
// Initialize vectors
vector<float> a(size);
vector<float> b(size);
vector<float> result_normal(size);
vector<float> result_simd(size);
// Use a fixed seed for reproducibility
srand(42);
// Fill with random data
for (size_t i = 0; i < size; ++i) {
a[i] = static_cast<float>(rand()) / RAND_MAX;
b[i] = static_cast<float>(rand()) / RAND_MAX;
}
// Test normal addition
auto start_normal = high_resolution_clock::now();
normalAdd(a, b, result_normal);
auto end_normal = high_resolution_clock::now();
auto duration_normal = duration_cast<milliseconds>(end_normal - start_normal).count();
// Test SIMD addition
auto start_simd = high_resolution_clock::now();
simdAdd(a, b, result_simd);
auto end_simd = high_resolution_clock::now();
auto duration_simd = duration_cast<milliseconds>(end_simd - start_simd).count();
// Verify results
bool isCorrect = verifyResult(result_simd, result_normal);
// Output results
cout << "Data set size: " << size << endl;
cout << "Time taken for normal addition: " << duration_normal << " milliseconds" << endl;
cout << "Time taken for SIMD addition: " << duration_simd << " milliseconds" << endl;
cout << "Speedup factor: " << static_cast<double>(duration_normal) / duration_simd << "x" << endl;
cout << "Result verification: " << (isCorrect ? "Correct" : "Incorrect") << endl;
return 0;
} The results are as follows: