

Click the blue text above to follow us

📋📋📋 The contents of this article are as follows: 🎁🎁🎁
Contents
💥1 Overview
📚2 Results
🎉3 References
🌈4 MATLAB Code and Article



1 Overview
References:

Analyzing images obtained from a single source using different camera settings or spectral bands (whether from one or multiple sensors) is very challenging. To address this issue, a single image is often created by combining images to include all unique information from each source image, a process known as image fusion. This paper proposes a simple and efficient pixel-based image fusion method that utilizes Gaussian filtering to weight the edge information of each pixel in all source images, proportional to the distance from adjacent images. The proposed Gaussian of Differences (GD) method is evaluated using multi-modal medical images, multi-sensor visible and infrared images, multi-focus images, and multi-exposure images, and compared with existing state-of-the-art fusion methods using objective fusion quality metrics. The GD method’s parameters are further enhanced by adopting a Pattern Search (PS) algorithm, forming an adaptive optimization strategy. Extensive experiments show that the proposed GD fusion method ranks better than other methods on average in terms of objective quality metrics and CPU time consumption.
The goal of image fusion is to combine complementary information from multiple source images into a unified image [1,2,3,4]. In multi-modal medical image fusion, two or more images from different imaging modalities are combined [5]. Magnetic Resonance (MR) and Computed Tomography (CT) are two different medical imaging modalities with complementary advantages and disadvantages. CT images have high spatial resolution, making bones more visible, while MR images have high contrast resolution, allowing for the display of soft tissues such as organs [6]. Visible and infrared image fusion is a computational technique that combines information from infrared and visible spectrum images to enhance object visibility and improve image contrast, particularly for enhancing night vision, remote sensing, and panchromatic sharpening [7,8,9,10,11,12]. Multi-exposure image fusion involves integrating multiple images captured at different exposure levels to generate a High Dynamic Range (HDR) image. HDR images retain details in both dark and bright areas, thereby improving image quality, enhancing visual fidelity, and improving image analysis in computer vision tasks [13,14]. Multi-focus image fusion combines multiple images with different focal levels into a single composite image [15,16,17,18,19]. This enhances overall clarity, depth of field, and visual perception [20]. These advantages enable more accurate analysis and interpretation of fused images in computer vision applications. The image fusion methods in the literature can be broadly classified into two categories: pixel domain and transform domain [21]. Pixel domain (or spatial domain) techniques directly combine the gray or color pixel values of the source images. A well-known example of this technique is the arithmetic mean of the source images. The arithmetic mean can be used to combine multi-sensor and multi-focus images, but the major drawback of this method is the reduction of image contrast [22]. The fundamental idea of multi-scale, transform-based image fusion methods is to apply multi-resolution decomposition to each source image, combine the decomposition results with various rules to create a unified representation, and finally apply inverse multi-resolution transformation [23]. Notable examples of these methods include Principal Component Analysis (PCA), Discrete Wavelet Transform (DWT), Laplacian Pyramid (LP), and other pyramid-based transforms [24]. In recent years, several image fusion algorithms based on machine learning and deep learning methods have been proposed [3,25,26,27,28]. These methods are robust and exhibit excellent performance. However, the training phase requires powerful high-performance computing systems and a large amount of input training data. Additionally, trained models can be very time-consuming for real-time applications [29]. Pixel-level, feature-level, and decision-level are three levels at which image fusion can be performed. Pixel-level fusion directly integrates the raw data of the source images, producing a fused image that is more informative for both computer processing and human visual perception. Compared to other fusion methods, this approach aims to improve the visual quality and computational efficiency of the fused image. Li et al. proposed a pixel-based method that calculates the pixel visibility of each pixel in the source images [30]. Yang and Li proposed a multi-focus image fusion method based on spatial frequency and morphological operators [31]. Typically, in pixel-level image fusion, weights are determined based on the activity levels of various pixels [32]. In these studies, neural networks [33] and support vector machines [34] are used to select pixels with the most significant activity, using wavelet coefficients as input features. Ludusan and Lavialle proposed a variational pixel image fusion method based on error estimation theory and partial differential equations to mitigate image noise [35]. In [36], a multi-exposure image fusion technique is introduced, which involves two main stages: computing image features, including local contrast, brightness, and color differences to generate a weight map, and further refining it using recursive filtering. Subsequently, the fused image is formed by using a weighted combination of the source images based on these refined weight maps. In addition to the many available pixel-level methods, region-based spatial methods using blocks [37] or adaptive regions [38,39] have been proposed to outperform existing methods. Within the framework of image fusion algorithms based on Anisotropic Diffusion Filtering (ADF), weight maps are formed through image smoothing, employing edge-preserving methods. These weight maps are post-processed before applying fusion rules, ultimately achieving the final output [40]. Kumar introduced a Cross-Binary Filter (CBF) method that considers the gray similarity and geometric proximity of adjacent pixels without anti-aliasing. The weights calculated from detailed images extracted from the source images using the CBF method are combined based on weighted averages [41]. The Fourth-Order Partial Differential Equation (FDPE) method first applies differential equations to each source image to obtain approximate images. Then, PCA is used to obtain the optimal weights for detailed images, which are combined to obtain the final detailed image. The final approximation of the image is derived by performing averaging operations on the set of approximate images. Subsequently, the fused image is calculated by merging the final approximation with the detailed image [42]. The Contextual Enhancement (GFCE) method preserves details in the visible input images and the background scene. Therefore, it can successfully transfer important infrared information to the composite image [43]. The Gradient Transfer Fusion (GTF) method based on gradient transmission and total variation (TV) minimization attempts to maintain both appearance information and thermal radiation [44]. The Hybrid Multi-Scale Decomposition (HMSD) method uses a combination of bilateral filters and general Gaussian methods to decompose source images into very distant texture details and edge features. This shift allows us to better capture important, very sensitive infrared spectral features and separate fine texture details from large edges [45]. The Infrared Feature Extraction and Visual Information Preservation (IFEVIP) method provides a simple, fast, yet effective fusion of infrared and visible light images. First, the infrared background is reconstructed using quadtree decomposition and Bezier interpolation; subsequently, bright infrared features are extracted by subtracting the reconstructed background from the infrared image, followed by a refinement process to reduce redundant background information [46]. The Multi-Resolution Singular Value Decomposition (MSVD) method is an image fusion technique based on a process similar to wavelet transform, involving the independent filtering of signals using low-pass and high-pass finite impulse response (FIR) filters, and then extracting the output of each filter twice for the first level of decomposition [47]. The VSMWLS method aims to enhance the transmission of important visual details while minimizing the inclusion of irrelevant infrared (IR) details or noise in the merged image, representing a multi-scale fusion technique that combines Visual Saliency Map (VSM) and Weighted Least Squares (WLS) optimization [48]. Liu et al. proposed a method based on Deep Convolutional Neural Networks (CNN) for infrared-visible image fusion [49] and multi-focus image fusion [50]. They successfully utilized Siamese Convolutional Networks to integrate pixel activity information from two source images, constructing weight maps and addressing the critical issues of activity level measurement and weight allocation in image fusion [49]. On the other hand, since focus estimation and image fusion are two distinct problems, traditional image fusion techniques sometimes struggle to perform satisfactorily. Liu et al. proposed a deep learning method that avoids the need for separate focus estimation by learning the direct mapping between source images and focus maps [50].


2 Results
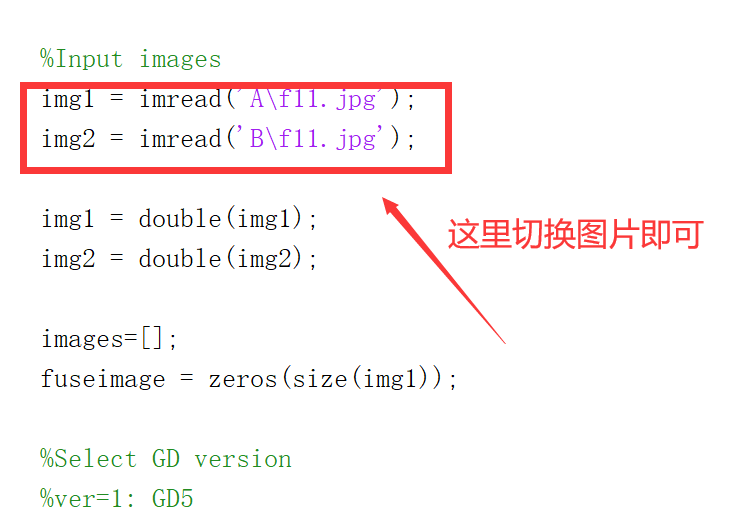
%Gaussian of differences: a simple and efficient general image fusion method
function fuseimage = GD(images, ver) %ver=1: GD5 %ver=2: GD10 %ver=3: GD15 %ver=4: GDPSQABF %ver=5: GDPSQCD %ver=6: GDPSQCV
if ver == 1
k = 5;
fuseimage = mfiltw(images, k);
elseif ver == 2
k = 10;
fuseimage = mfiltw(images, k);
elseif ver == 3
k = 15;
fuseimage = mfiltw(images, k);
elseif ver == 4
fitmetric = "Qabf";
[fuseimage] = mfiltw_opt(images, fitmetric);
elseif ver == 5
fitmetric = "Qcb";
[fuseimage] = mfiltw_opt(images, fitmetric);
elseif ver == 6
fitmetric = "Qcv";
[fuseimage] = mfiltw_opt(images, fitmetric);
end

3References
Some content in this article is sourced from the internet, and references will be noted or cited as references. If there are any inaccuracies, please feel free to contact us for removal.




4 MATLAB Code and Article
Lychee Research Society


